

Autor

TL;DR
Das Feedback der Kunden zu verstehen und zu wissen, wo Ihre Stärken und Schwächen liegen, ist der Schlüssel für jedes Unternehmen. Heutzutage haben Unternehmen Zugang zu einer Vielzahl von Informationen, die ihnen diese Erkenntnisse liefern können: Website-Bewertungen, Chat-Interaktionen, Gesprächsprotokolle, Kommentare in den sozialen Medien...
In diesem Artikel erfahren Sie, wie Sie schnell Erkenntnisse aus textuellen data gewinnen können, und zwar am Beispiel von Kundenrezensionen. Wir werden 3 verschiedene Ansätze vorstellen:
vordefinierte Geschäftsthemen
(Themenmodellierung könnte eine vierte Option sein, um weiter zu gehen)
Bitte beachten Sie, dass das data hinter diesem Artikel künstlich erzeugt wurde, um die Vertraulichkeit unseres ursprünglichen Projekts zu gewährleisten.

Analyse der Kundenrezensionen
Wir versuchen, aus den Bewertungen unserer Produkte Erkenntnisse zu gewinnen, um zu verstehen, was ihre Hauptprobleme / Hauptstärken sind. Bei den Produkten handelt es sich um Kamerageräte und Zubehör mit Bewertungen von 1 (schlecht) bis 5 (ausgezeichnet).
Wir werden hier drei verschiedene Ansätze verwenden, um Erkenntnisse aus unserem data zu gewinnen.
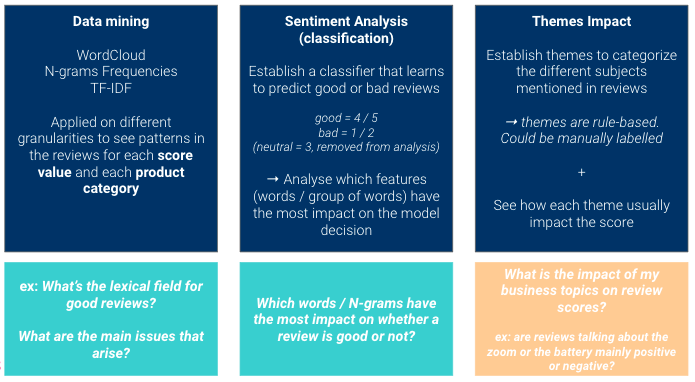
Es geht darum, komplementäre Ansichten zu haben:
Verschaffen Sie sich einen Überblick über die data, die Sie gesammelt haben
Wenn Sie ein neues data-Projekt beginnen, besteht der erste Schritt immer darin, sich einen Überblick über das vorhandene data zu verschaffen (ist es unausgewogen? gibt es genug data? gibt es viele fehlende Werte?).
Wie viele Bewertungen habe ich für jede Produktkategorie?
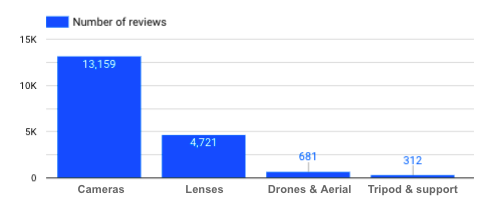
Anzahl der Bewertungen pro Produktkategorie
→ Die Tatsache, dass es nicht so viele Stativ-Bewertungen gibt, sollte berücksichtigt werden, wenn wir die Bewertungen für diese spezielle Produktkategorie analysieren. Je mehr data wir haben, desto besser, damit wir unvoreingenommene und relevante Schlussfolgerungen ziehen können.
Wie viele Bewertungen habe ich für jede Bewertung?
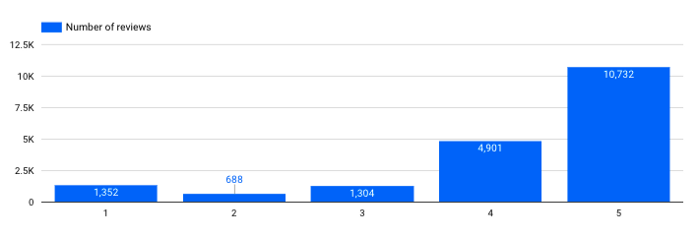
Anzahl der Bewertungen pro Punktzahl
→ Das ist wichtig. Wir sehen, dass unser dataset ziemlich unausgewogen ist. Wir haben viel mehr positive als negative Bewertungen. Diese Art von Information muss berücksichtigt werden, wenn Sie spezielle Modelle trainieren (z.B. ein Klassifizierungsmodell für die Stimmungsanalyse).
Wie ist die Verteilung der Bewertungen in den einzelnen Kategorien?
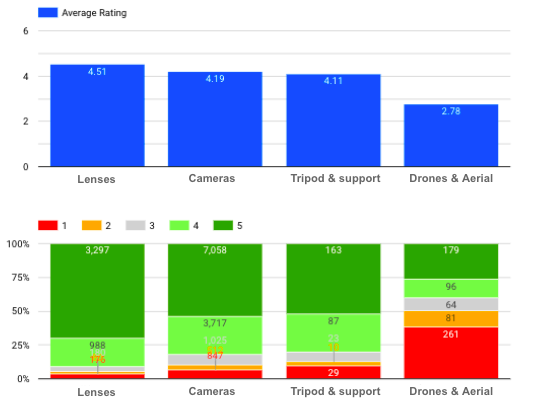
Durchschnittliche Bewertung und Verteilung der einzelnen Produktkategorien
Wir sehen hier, dass Objektive die höchste Durchschnittsbewertung haben, während es viele negative Bewertungen (vor allem mit einer Bewertung von 1) für Drohnen und Luftaufnahmen gibt.
NLP nutzen, um die Sorgen Ihrer Kunden zu verstehen
Um zu verstehen, was es mit den Bewertungen auf sich hat, werden wir die verschiedenen, bereits erwähnten NLP-Ansätze anwenden.
Data Reinigung
Bevor wir etwas anderes tun, müssen wir den Text data bereinigen, um ihn für die verschiedenen NLP-Methoden nutzbar zu machen (dieser Schritt ist nicht immer erforderlich, je nachdem, welche Algorithmen Sie verwenden möchten).
Wir haben standardmäßige Vorverarbeitungsfunktionen angewandt, die für unsere data relevant waren (Entfernen von HTML, Interpunktion, Telefonnummern, ...), und wir haben eine benutzerdefinierte Liste von Stoppwörtern implementiert, die wir aus den Bewertungen entfernen (das Wort “Kamera” bringt beispielsweise nicht so viele Informationen für unsere Analyse).
Eine Vielzahl dieser Funktionen finden Sie in unserem NLPVortext Github-Repository.
Erkenntnisse in wenigen Zeilen Code gewinnen
Jetzt haben wir für jede Bewertung:
Wir können damit beginnen, unsere häufigsten Wörter (einzelne Wörter, Bi-Gramme, Tri-Gramme...) zu betrachten. Das ist eine einfache Analyse, die Ihnen aber einen unmittelbaren Überblick über die wichtigsten Themen für jede Bewertung und Kategorie gibt.
from collections import Zähler
import matplotlib.pyplot as plt
Wortcloud importieren
plt.rcParams[“figure.figsize”] = [16, 9]
def create_ngrams(token_list, nb_elements):
“””
N-Gramme für eine Liste von Token erstellen
Parameter
----
token_list : Liste
Liste von Zeichenketten
nb_elements :
Anzahl der Elemente in dem n-Gramm
Liefert
---
Generator
Generator für alle n-Gramme
“””
ngrams = zip(*[token_list[index_token:] for index_token in range(nb_elements)])
return (” “.join(ngram) for ngram in ngrams)
def frequent_words(list_words, ngrams_number=1, number_top_words=10):
“””
N-Gramme für eine Liste von Token erstellen
Parameter
----
ngrams_number : int
number_top_words : int
Ausgabe data Rahmenlänge
Liefert
---
DataFrame
Dataframe mit den Entitäten und ihren Frequenzen.
“””
frequent = []
if ngrams_number == 1:
passieren
elif ngrams_number >= 2:
list_words = create_ngrams(list_words, ngrams_number)
sonst:
raise ValueError(“Anzahl der n-Gramme sollte >= 1 sein”)
Zähler = Zähler(Liste_Wörter)
frequent = counter.most_common(number_top_words)
häufig zurückkehren
def make_word_cloud(text_oder_zähler, stop_words=None):
if isinstance(text_oder_zähler, str):
word_cloud = wordcloud.WordCloud(stopwords=stop_words).generate(text_oder_zähler)
sonst:
wenn stop_words nicht None ist:
text_oder_zähler = Zähler(wort für wort in text_oder_zähler wenn wort nicht in stop_wörter)
word_cloud = wordcloud.WordCloud(stopwords=stop_words).generate_from_frequencies(text_or_counter)
plt.imshow(wort_cloud)
plt.axis(“aus”)
plt.show()
WordCloud
Mithilfe dieser Funktionen können wir ganz einfach eine Wortwolke der häufigsten Wörter anzeigen, indem wir Bewertungen für Kameras mit einer Punktzahl zwischen 1 und 2 verwenden:

Zeigen Sie dann eine ähnliche Wortwolke mit Bewertungen für Kameras mit einer Punktzahl zwischen 4 und 5 an:
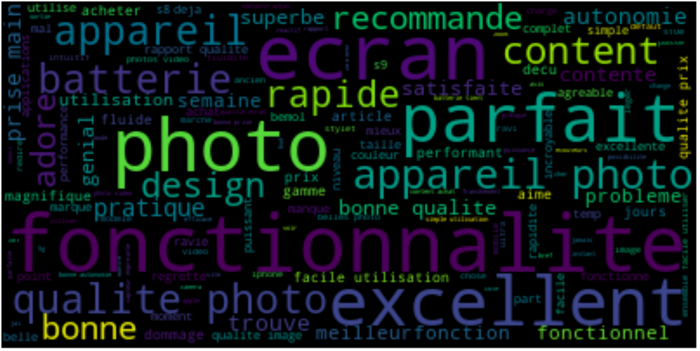
Wir können die wichtigsten Punkte, die in beiden Fällen angesprochen werden, leicht identifizieren.
Wir könnten diese Übung für jedes Produkt unseres Unternehmens durchführen, um die Besonderheiten der einzelnen Produkte zu erkennen und Schlussfolgerungen auf einer detaillierteren Ebene ziehen zu können.
N-Gramme Anzahl
Wir können auch die häufige_Wörter Funktion, um die häufigsten Wörter, Bi-Gramme oder Tri-Gramme anzuzeigen:

Wenn Sie noch weiter gehen möchten, könnten Sie eine Funktion einrichten, die die mit einem Schlüsselwort verknüpften Bewertungen anzeigt, um die für Sie interessanten N-Gramme zu vergrößern. Sie könnten sich auch die n-Gramme mit den höchsten/niedrigsten TF-IDF (leicht zu berechnen mit dem sklearn Bibliothek), da Sie damit wichtige Wörter auf der Grundlage einer anderen Metrik als einem einfachen Häufigkeitszähler erkennen können.
Stimmungsanalyse
Als Nächstes gehen wir zu einem Ansatz der Stimmungsanalyse über. Normalerweise wird er verwendet, um vorherzusagen, ob ein Text positiv oder negativ ist. In unserem Fall haben wir diese Information bereits (die Punktzahl zwischen 1 und 5 gibt uns die Stimmung hinter der Bewertung an). Wenn wir jedoch ein Modell zur Vorhersage dieser Bewertung trainieren, können wir herausfinden, welche Wörter (Merkmale) für die Kunden entscheidend sind.
Was wir tun können, ist einen Sentiment-Analyse-Klassifikator auf diese data trainieren, und verwenden Sie dann Bibliotheken wie SHAP oder LIME, um die mit den Merkmalen (= Worte) den größten Einfluss haben ob eine Bewertung als positiv oder negativ eingestuft wird.
Klassifikator
Um einen Klassifikator zu trainieren, können Sie eine Vielzahl von Algorithmen verwenden, von der klassischen sklearn LogisticRegression bis hin zu ULM-fit Modellen (siehe dieses Notizbuch um ein französisches ULM-Fit-Modell zu trainieren, und dieser Artikel um mehr über ULM-fit zu erfahren) oder den von Uber entwickelten Ludwig-Klassifikator.
Vielleicht möchten Sie zunächst mit einem einfachen Programm beginnen, um zu sehen, ob es Ihren Bedürfnissen entspricht, bevor Sie komplexere Algorithmen einsetzen.
Berücksichtigen Sie, dass Ihr dataset wahrscheinlich unausgewogen ist (mehr positive als negative Bewertungen, in unserem Fall).
Bedeutung der Funktion
Sobald Ihr Klassifikator implementiert ist, können Sie zum wichtigsten Schritt übergehen: der Gewinnung von Erkenntnissen aus der Bedeutung der Merkmale.
Im folgenden Beispiel wenden wir SHAP auf unser Modell (hier eine einfache sklearn LogisticRegression) an:

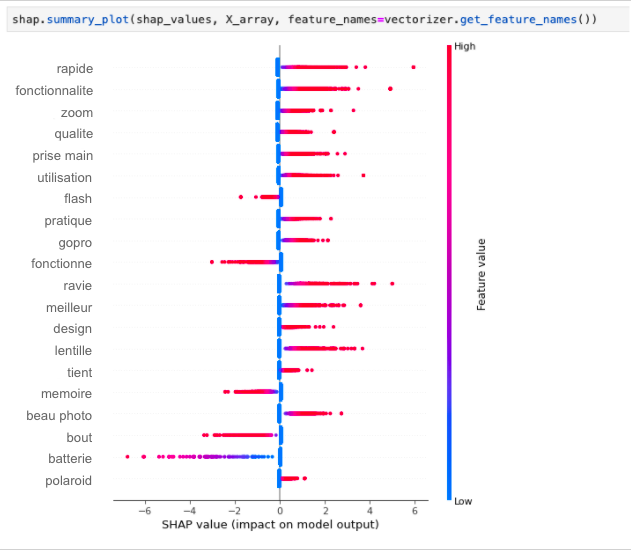
Wir können hier sehen, dass die Funktionen, die Fotoqualität und die Zoomfunktionen einen wirklich positiven Einfluss auf die Zufriedenheit unserer Kunden haben, während der Blitz, die Speicherkarte oder die Batterien einen wirklich negativen Einfluss haben, wenn sie in einer Bewertung erwähnt werden.
Wörter wie “exzellent”, “perfekt” oder “schlecht” wurden aus dieser Analyse (vor dem Training des Klassifikators) entfernt, da sie als die wichtigsten Merkmale angesehen werden, während wir uns in unserem Fall darauf konzentrieren wollen, Erkenntnisse über unsere Produkte zu gewinnen und nicht wirklich die Leistung unseres Klassifikators verbessern wollen.
Siehe dieses Notizbuch für ein Beispiel, wie Sie SHAP mit einem öffentlichen dataset verwenden können.
Auswirkungen der Geschäftsthemen
Unser dritter Ansatz unterscheidet sich etwas von den vorherigen, da er von geschäftsbezogenen Themen ausgeht, die von jemandem ausgewählt wurden, der sich mit den Produkten auskennt.
Es geht darum, zu analysieren, wie sich vordefinierte Geschäftsthemen auf die Produktbewertungen auswirken, um zu verstehen, ob sie eine Quelle der Stärke oder ein zu lösendes Problem darstellen.
Themen bestimmen
Der erste Schritt ist die Klassifizierung der Rezensionen in die thematischen Kategorien. Entweder, indem Sie Ihr dataset manuell beschriften (dann können Sie einen Klassifikator trainieren, wenn Sie neue Rezensionen automatisch in Themen einordnen möchten), oder mit einem regelbasierten Modell.
In unserem Fall haben wir ein regelbasiertes Modell verwendet, weil es bereits mit geringem Aufwand gute Ergebnisse liefern kann (z.B. wenn Sie sich für die Qualität Ihrer Objektive oder Ihren Kundendienst interessieren, können Sie ganz einfach Regeln aufstellen, die bestimmen, ob diese in einer Bewertung erwähnt werden oder nicht).
Thema Auswirkungen
In einem zweiten Schritt können Sie Ihren globalen Durchschnittswert und dann den Durchschnittswert der Bewertungen zu einem bestimmten Thema berechnen.
Wenn Sie beide Werte subtrahieren, können Sie den Einfluss Ihres Themas auf Ihren Gesamtwert ableiten.
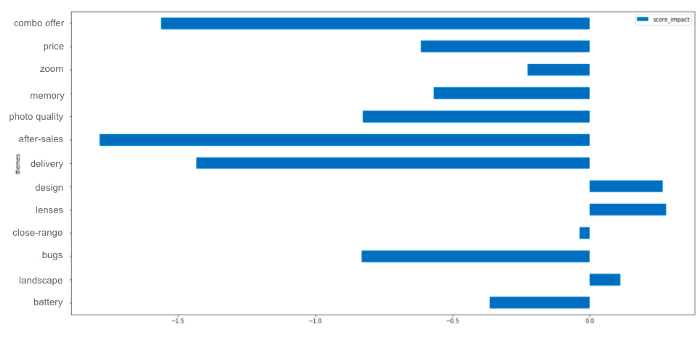
Wir sollten uns hier Sorgen um unseren Kundendienst machen, denn er wird oft negativ erwähnt (obwohl das auch daran liegen könnte, dass die Leute, die sich an den Kundendienst wenden, oft schon ein Problem hatten. Deshalb sollten Sie sich die Bewertungen, in denen dieses Thema erwähnt wird, im Detail ansehen, um wirklich zu verstehen, warum es angesprochen wurde).
→ Auch hier sind betriebswirtschaftliche Kenntnisse unerlässlich, um Ihre Ergebnisse sinnvoll zu nutzen.
Andererseits ist die Erwähnung unserer Designs oder Objektive oft mit einer Bewertung mit hoher Punktzahl verbunden, was bedeuten könnte, dass dies eine unserer Stärken ist.
Siehe dieser Artikel für weitere alternative Visualisierungen zu Wordcloud.
Um weiter zu gehen
Wir könnten noch weiter gehen und versuchen, Themen in unseren Bewertungen zu erkennen: Sie könnten die Top2Vec-Bibliothek verwenden, um Themen zu extrahieren und die Korrelation zwischen Themen und Bewertungen zu sehen (jede Bibliothek zur Themenmodellierung wird funktionieren, aber Top2Vec hat den Vorteil, hervorragende Ergebnisse zu liefern, ohne dass eine Vorverarbeitung oder eine vordefinierte Anzahl von Themen erforderlich ist).
Dieser Artikel hat gezeigt, wie Sie mit einer pragmatischen und einfachen Analyse Einblicke in Ihre Kunden gewinnen können. data. Vielen Dank für die Lektüre und zögern Sie nicht, sich zu melden, wenn Sie einen Kommentar zu diesem Thema haben! Sie können unseren Blog besuchen Hier um mehr über unsere Projekte zum maschinellen Lernen zu erfahren.
