
Author

5 tips to better take promotional data into account
TL;DR
In this following article of a large series of posts dedicated to demand forecasting, we will focus on how to model promotions, a key driver in sales forecasting, looking at what a typical promo dataset looks like, how features should be crafted, with a step-by-step example in Python, and how complex promotional granularity can be dealt with.
Context
When forecasting demand as retailers, we often can leverage several useful data sources such as historical sell-in, product and customer hierarchies, holidays, sell-out and promotions. It is important to pay particular attention to the latter as, in real life, promotional activity is often much more than just a dummy flag you should add as a feature to your model. It is a real complex business mechanism which can yield additional performance to your model if processed well.
Tips 1: Understanding promotions referentials
Sales dataset often do not include promo data. You need to plug in a specific referential into your training data. Promotional data often come as a set of columns, in the format of a promotion plan with promotion characteristics such as:
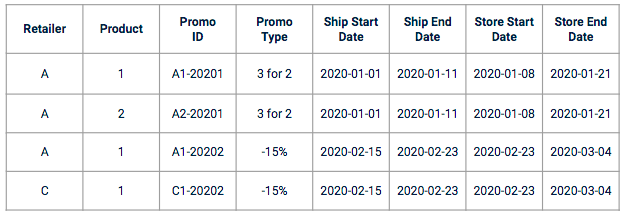
Example of promotion data
Before starting the feature engineering and modeling parts, it is recommended to perform interviews with the business owners in order to understand how promotion are created and handled. Let’s take the example of dates. In the case of a sell-in prediction, a promotion will be associated with several dates:
It is really important to understand which dates impact the most the target variable and to check with the business owners if there are any specificities to take into account (e.g. if some retailers may apply the promotions before or after the official start and end dates).
Performing Exploratory Data Analysis (EDA) can help you understand the fluctuations and the impact promotions can have on the target variable. For example, below one can see that a particular type of promotion has a greater impact than others.
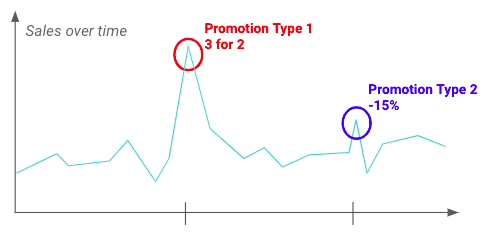
Example of the impact of two different promotions on the sales of a given product
EDA can also be performed to validate insights previously highlighted by business teams. Below, it seems retailers are starting promotions well before the official start date.
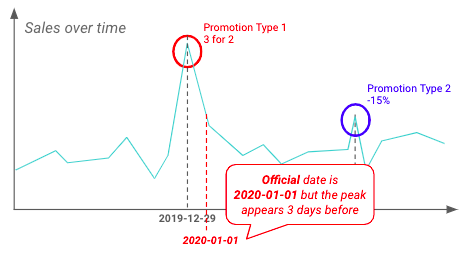
Example of difference between official and real start date of promotions
After the exploration, we need to process the raw promotion data in order for it to be used. The dates have first to be expanded and processed in order to have a continuous timeline. Some of them may need to be shifted based on what was found during the exploration and business interview phases.
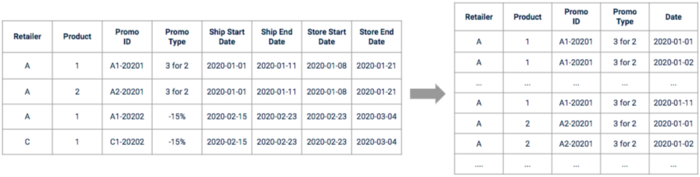
Illustration of promotion data before and after preprocessing
Tips 2: Choosing the right granularity
As your EDA will show, promotions impacts differ greatly across products, retailers (or stores if you’re working with sell-out data), types of promotions. Ideally, you’d like to be as much precise as possible and keep a SKU x retailer x promotion type granularity.
For example, you may have two different geographic granularity: retailer and warehouse (i.e. a warehouse contains severals retailers). By plotting your time-series at each granularity, you may find out that the impact of promotion is really visible at retailer level but seems smoothed for warehouses. This can be explained by the fact that not all retailers of a the warehouse are impacted by the promotion in the same way. Therefore in that example, it is preferable to work at the retailer granularity.
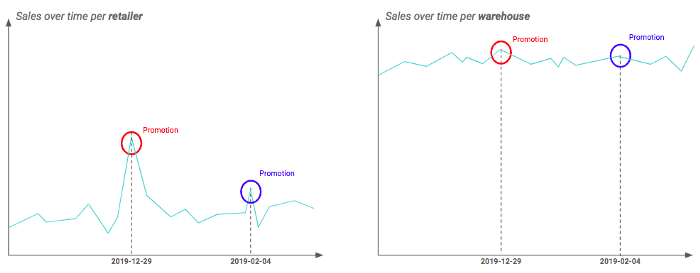
Difference of the promotion impact depending on the granularity
Once the EDA has been done and the promotion data is at the right granularity, the objective is to create the most relevant features for future planned promotions for which we want to predict the associated sales.
Tips 3: Crafting the right features
People may think that just adding a dummy variable in your training dataset will be enough. This works to guide the model in understanding why demand or sales is higher at one point in time. However, it is a really poor way to model how promotion may impact sales. Typically, some promotion types may be more efficient than others, the impact of promotions may also be higher near the start date, lower after (as there are few people left that could benefit from the reduction).
A more sophisticated feature we found useful when using boosting algorithms is to compute sales rolling means so as to give your model insights about how much each promo type was successful in the past.
1. Theory
The idea behind this kind of feature is to measure, for a given promotion, the average volume recently generated by “similar promotions” in the past. We are going to compute the average historical sell-in on a similar scope (same promotion type, same SKU, same retailer) on a rolling window with a given horizon (e.g. on the 7 past days).
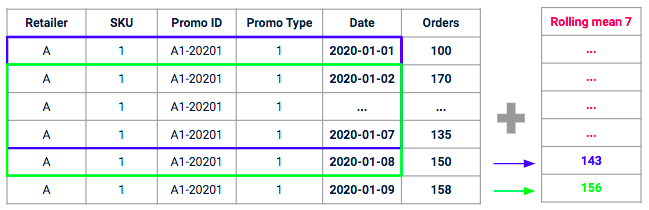
Example of a rolling mean with a 7-days window
For this kind of features, a particular attention should be paid to data leakage, especially when setting the time horizon.
2. Python implementation
Let’s see how to implement a 7-days rolling mean feature step by step in Python. First of all, let’s define our DataFrame with the following information:
# Initialize our example dataframe with 6 columns: sku, retailer, promotion type,
# promotion id, date, sellin
df = pd.DataFrame(
{
‘sku’: [1] * 25,
‘retailer’: [‘A’] * 20 + [‘B’] * 5,
‘promotion_type’: [1] * 10 + [2] * 10 + [2] * 3 + [3] * 2,
‘promotion_id’: [‘A1-2019’] * 2 + [‘A1-20201’] * 8 + [‘A2-20201’] * 3 + \[‘A2-20203’] * 5 + [‘A2-20204’] * 2 + [‘B2-20201’] * 3 + \[‘B3-20201’] * 2,
‘date’: [
pd.Timestamp(el) for el in [“2019-12-01”, “2019-12-02”, “2020-01-01”,
“2020-01-02”, “2020-01-03”, “2020-01-04”,
“2020-01-05”, “2020-01-06”, “2020-01-07”,
“2020-01-08”, “2020-01-21”, “2020-01-22”,
“2020-01-23”, “2020-03-01”, “2020-03-02”,
“2020-03-03”, “2020-03-04”, “2020-03-05”,
“2020-04-15”, “2020-04-16”, “2020-01-21”,
“2020-01-22”, “2020-01-23”, “2020-01-21”,
“2020-01-22”]],
‘sellin’: [rd.randint(100, 200) for i in range(25)]
}
)
# Initialize our horizon: 7-days rolling mean
horizon = 7
# Add a line “in the future” for which we want to forecast the sell-in (unknown for
# now) and therefore for which we want to have a value for the rolling mean feature
df = df.append(
{
‘sku’: 1,
‘retailer’: ‘A’,
‘promotion_type’: 3,
‘promotion_id’: ‘A3-20203’,
‘date’: pd.Timestamp(‘2020-06-01’),
‘sellin’: np.nan
},
ignore_index=True
)
Once created, our DataFrame looks like this:
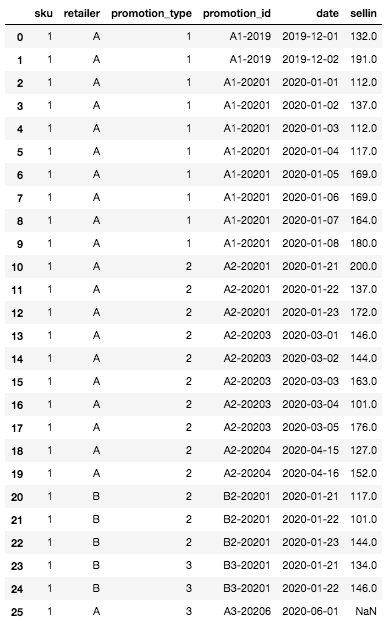
Initial DataFrame
Next we will create two important columns : the start date of promotion and the rolling mean (empty for now).
# We create two new columns:
# – the minimum promo date (start date based on promotion ID)
df = df.merge(
df.groupby([“sku”, “retailer”, “promotion_id”]).date.min() \
.reset_index() \
.rename(columns={“date”: “min_promo_date”}),
on=[“sku”, “retailer”, “promotion_id”],
how=”left”
)
df = df.sort_values(“min_promo_date”)
# – the rolling mean feature, filled with NaN for the moment
df[‘promo_rolling_mean’] = np.nan
Now, the DataFrame should look like this:
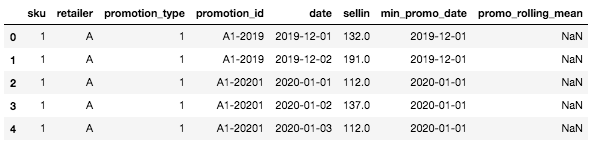
Head of the DataFrame with the two new columns
From there, we can start filling in the promo_rolling_mean column. Remember that the goal is to compute the mean of sell-in of previous similar promotions but the notion of similarity can be tricky. In the best case scenario, we have in our history a promotion with the same type, for the same retailer, for the same SKU. In worst case scenario, there is a new promotion with a new type for which we do not have any history for any SKU, any retailer. Therefore the idea is to define several levels of granularity for which we will see if we have a history and therefore a possibility to calculate a rolling mean, starting from the most granular level (e.g. SKU x retailer x promotion type) to the least granular level (e.g. SKU).
For example, let’s take SKU : 1, retailer : A, promotion type : 1, date : 2020–01–01. We look for a similar promotion in the past. Lucky for us, there has been a promotion with the same promotion type, for the same SKU, the same retailer (i.e. the most granular level) in 2019 (promotion_id = ‘A1–2019’). Thus we will take the mean of the sell-in for the 7 most recent dates where this kind of promotion happened. In other cases we may not find any match for this granularity so we will be looking for a match by SKU and promotion type only. Again, if there is no match, we will finally take the mean at the SKU level only.
# Definition of granularity levels to compute the rolling means, from the most granular
# to the less granular
AGG_LEVELS = {
“1”: [“sku”, “retailer”, “promotion_type”],
“2”: [“sku”, “promotion_type”],
“3”: [“sku”]
}
# We iterate on the granularity levels (from the most granular to the less granular) in
# order to compute the rolling mean on the most similar promotion for each row
for agg_level_number, agg_level_columns in AGG_LEVELS.items():
# Once the rolling mean feature is filled, we break from the loop
if df[“promo_rolling_mean”].isna().sum() == 0:
break
# (1) We aggregate our dataframe to the current granularity level
agg_level_df = df.groupby([“promotion_id”] + agg_level_columns) \
.agg({“sellin”: “mean”, “date”: “min”}) \
.reset_index() \
.rename(columns={“date”: “min_promo_date”}) \
.dropna(subset=[“sellin”]) \
.sort_values(“min_promo_date”)
# (2) We compute the rolling mean on the given horizon for the current granularity
# level
agg_level_df[“sellin”] = agg_level_df.groupby(agg_level_columns) \
.rolling(horizon, 1)[“sellin”] \
.mean() \
.droplevel(
level=list(
range(len(agg_level_columns))
)
)
# (3) We merge the results with the main dataframe on the right columns and min promo
# date. We use the merge_asof to only take rolling means computed for dates before each
# observation date.
df = pd.merge_asof(
df,
agg_level_df,
by=agg_level_columns,
on=”min_promo_date”,
direction=”backward”,
suffixes=(None, f”_{agg_level_number}”),
allow_exact_matches=False
)
# We fill the feature with the rolling mean values for the current granularity level
df[“promo_rolling_mean”] = df[“promo_rolling_mean”].fillna(
df[f”sellin_{agg_level_number}”])
cols_to_keep = [
“sku”, “retailer”, “promotion_type”, “promotion_id”, “date”,
“sellin”, “promo_rolling_mean”
]
df = df[cols_to_keep].sort_values(
by=[‘sku’, ‘retailer’, ‘promotion_type’, ‘promotion_id’, ‘date’])
At the end of the for loop, as you merge this new feature with the train set, you must pay attention at data leakage and only take rolling means computed for dates before each observation date (the date for which you want to make forecasts). Here, we have decided to use the merge_asof method. This allows us to merge two datasets avoiding exact matches. The idea behind it is: do not take the exact date match (with the allow_exact_matches=False parameter), but take the previous ones (with the direction=”backward” parameter).
Here is what our dataset looks like with the rolling mean feature filled after this step:
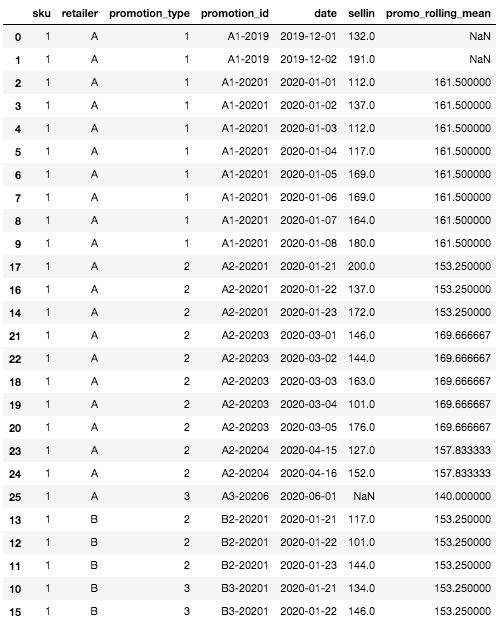
Final DataFrame with the rolling mean feature
We can first see that there are some missing values for the rolling mean feature at the top of the DataFrame. This is normal and is due to the fact that for the first rows, we do not have any history on any SKU, any retailer, therefore no possibility to compute a rolling mean. This is the only case where the rolling mean will be empty, any other case can be handled by the definition of the granularity aggregation levels.
For example, for the specific row we have defined at the beginning (SKU: 1, Retailer A, Promotion type: 3, Date: 2020–06–01), the one for which we don’t know the sell-in yet, the rolling mean value will be the mean of the sell-in for the most similar and recent promotion. In our case, there is no history for the promotion type 3 for the retailer A, but there is for retailer B. Therefore, the rolling mean value will be the mean of sell-in for SKU=1, Promotion type= 3, Retailer=B, here: mean([134, 146]) = 140.
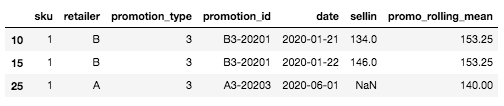
Example for a new promotion type for a couple SKU x retailer
This logic can be extended to several other cases that can be encountered in this type of projects. For example, an additional level could be created which would be the product family and which could be used in the case where there is no history for a given product. In that case we will take the average based on products belonging to the same family. It is therefore important to think about these levels of granularity and prioritize them according to your own definition of “promotion similarity” which can be based on your EDA or business insights, for example.
Instead of the rolling means, you can also measure the promotional uplift (i.e. the additional volume generated by a given promotion) for a given product and a given customer. The idea would be to compute a ratio between sales during a given promotion and the sales without any promotion instead.
Tips 4: Dealing with big data
Working at such a level of granularity can drastically increase complexity and the need for computational power. If like us you are dealing with hundreds of SKUs, retailers and several years of daily historical sell-in, it will be essential to find a way to parallelize computations. For example, if you have no need to get any information from other SKUs for your promotion features, you can partition your data on the sku column and use distributed computing. We found it useful to use Dask for this task:
from dask import delayed, compute
def compute_rolling_mean(df):
…
return df
skus_list = set(df[‘sku’])
dfs_with_promo = [
delayed(compute_rolling_mean)(df.loc[df.sku == sku]) for sku in skus_list
]
df_final = pd.concat(compute(*dfs_with_promo), axis=0, ignore_index=True)
Tips 5: Taking into account demand transfers across products
Don’t forget that each SKU sales will be impacted by its promotions, but also by promotions from substitutable products, such phenomena is known as cannibalization. In order to have a performant model, it is mandatory to anticipate the potential downlift on some products resulting from cannibalization.
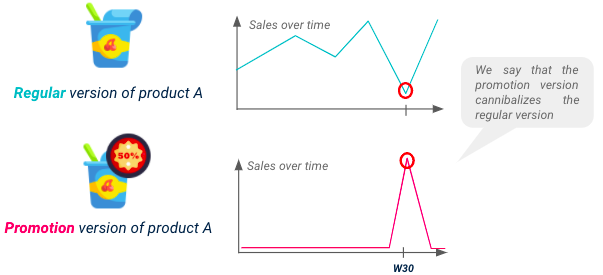
Cannibalization illustration
In order to be able to model the phenomenon, we first have to detect the cannibalization relationships between products. Two main approaches can be distinguished:
Automatic detection deep dive
One possibility to automatically detect cannibalization relationships is to use correlation scores. The idea is to bring together products that are really likely to cannibalize each other, not on the basis of their category, but on the basis of correlations between the evolution of their historical sales. Correlation scores are calculated for each pair of products and if they are strongly negative then we can assume that these products are cannibalizing each other
Cannibalization features deep dive
From these cannibalization relationships we can create features following the same approach as for direct promotions. For example:
Results and Conclusions
In our projects, we have observed that, in most cases, rolling mean features tended to work better for the model than uplift/downlift features. For example, for a given country, the rolling mean features resulted in a 2.8% increase in forecast accuracy while the uplift features resulted in a 2% increase.
However, each project is different and our main learning is that the exploration phase is essential and serves as a basis for the creation of features later on. It is necessary to really understand how promotions work and their impact in order to model them correctly. This involves discussions with the business owners as well as Exploratory Data Analysis.


Interested in Data Consulting | Data & Digital Marketing | Digital Commerce ?
Read our monthly newsletter to get actionable advice, insights, business cases, from all our data experts around the world!

