

作者

简要说明
了解客户反馈,知道自己的优势和劣势,对任何企业来说都至关重要。如今,企业可以获取大量信息,从而获得这些见解:网站评论、聊天互动、对话记录、社交媒体评论......
本文将以消费者的评论为例,介绍如何从文本 data 中快速提取洞察力。我们将介绍 3 种不同的方法:
预定义的业务主题
(专题建模可能是更进一步的第四个选项)
请注意,本文背后的 data 是人为生成的,以确保我们最初项目的保密性。.

客户评论分析
我们正试图从产品评论中找到启示,以了解它们的主要问题/主要优势是什么。产品为相机设备和配件,评分从 1 分(差)到 5 分(优)不等。.
在此,我们将采用三种不同的方法来收集 data 的见解。.
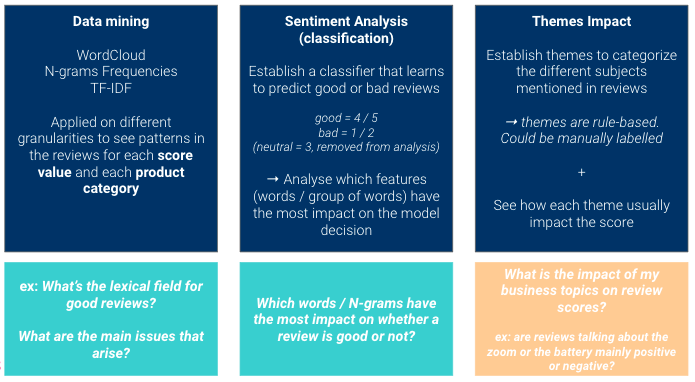
关键是要有互补的观点:
全面了解您收集的 data
无论何时开始新的 data 项目,第一步总是要了解 data 的总体情况(是否不平衡? 是否有足够的 data?).
每个产品类别有多少条评论?
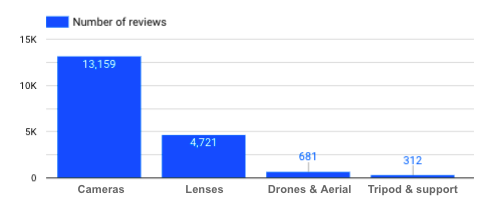
每个产品类别的评论数量
→ 如果我们分析三脚架这一特定产品类别的评论,就应该牢记三脚架评论并没有那么多这一事实。data 越多越好,这样才能得出公正、相关的结论。.
每个等级有多少条评论?
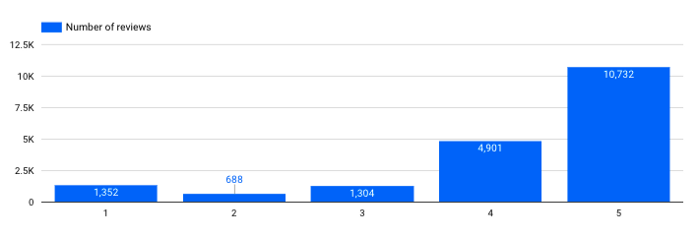
每个分数的评论数
→ 这一点很重要。我们看到 dataset 相当不平衡,正面评论比负面评论多得多。在训练专用模型(例如:用于情感分析的分类模型)时需要考虑这类信息。.
每个类别的评级分布情况如何?
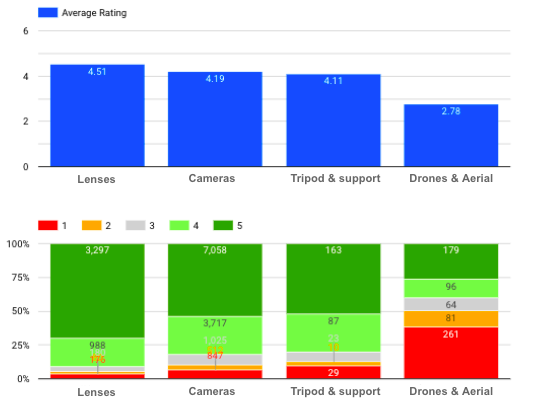
各产品类别的平均评级和分布情况
我们可以看到,镜头的平均评分最高,而无人机和航空成像的负面评论较多(尤其是 1 分)。.
利用 NLP 了解客户的关切
现在,为了了解评论的内容,我们将采用前面提到的不同 NLP 方法。.
Data 清洁
在做其他任何事情之前,我们需要清理文本 data,使其可用于不同的 NLP 方法(这一步骤并不总是必需的,取决于您要使用的算法)。.
我们应用了与 data 相关的标准预处理功能(去除 HTML、标点符号、电话号码......),并自定义了一个从评论中删除的停用词列表(例如,“相机 ”一词不会给我们的分析带来太多信息)。.
您可以在我们的 NLPretext Github 存储库。.
只需几行代码就能挖掘洞察力
现在,我们对每次审查都进行了审查:
我们可以从最常见的词(单词、双词组、三词组......)入手。这只是一个简单的分析,但它能让你立即了解每个分数和类别的主要话题是什么。.
从集合导入计数器
import matplotlib.pyplot as plt
导入 wordcloud
plt.rcParams[“figure.figsize”] = [16, 9]
def create_ngrams(token_list, nb_elements):
“””
为标记列表创建 n-grams
参数
----
token_list : list
字符串列表
nb_elements :
n-gram 中的元素数
返回
---
发电机
生成器
“””
ngrams = zip(*[token_list[index_token:] for index_token in range(nb_elements)])
return (” “.join(ngram) for ngrams in ngrams)
def frequent_words(list_words, ngrams_number=1, number_top_words=10):
“””
为标记列表创建 n-grams
参数
----
ngrams_number : int
number_top_words : int
输出 data 框架长度
返回
---
DataFrame
Data 框架中的实体及其频率。.
“””
frequent = []
如果 ngrams_number == 1:
通过
elif ngrams_number >= 2:
list_words = create_ngrams(list_words, ngrams_number)
否则
raise ValueError(“n-grams number should be >= 1”)
counter = Counter(list_words)
frequent = counter.most_common(number_top_words)
常回
def make_word_cloud(text_or_counter, stop_words=None):
if isinstance(text_or_counter, str):
word_cloud = wordcloud.WordCloud(stopwords=stop_words).generate(text_or_counter)
否则
如果 stop_words 不是 None:
text_or_counter = Counter(word for word in text_or_counter if word not in stop_words)
word_cloud = wordcloud.WordCloud(stopwords=stop_words).generate_from_frequencies(text_or_counter)
plt.imshow(word_cloud)
plt.axis(“off”)
plt.show()
词云
利用这些功能,我们可以使用得分在 1 和 2 之间的相机评论,轻松显示出最常出现词语的词云:

然后使用得分在 4-5 分之间的相机评论,显示类似的词云:
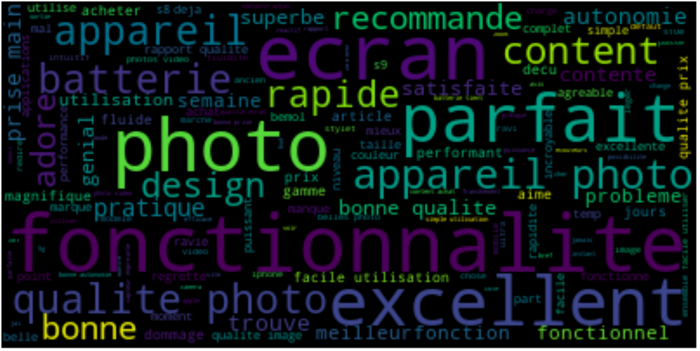
我们可以很容易地找出这两个案例中提出的要点。.
我们可以对公司的每种产品都做这样的练习,以便了解每种产品的特殊性,并在更细的层面上得出结论。.
N-grams 数量
我们还可以使用 frequent_words 函数来显示最常出现的词、双图或三图:

为了更进一步,您可以设置一个功能,显示与关键字相关的评论,以便放大您认为有趣的 n-gram。您还可以查看具有最高/最低评论的 n-gram。 TF-IDF (很容易计算 学习 库),因为它可以让你根据不同于简单频率计数器的指标来查看重要单词。.
情感分析
接下来,我们将讨论情感分析方法。通常,它用于预测文本是正面的还是负面的。在我们的案例中,我们已经掌握了这一信息(1 到 5 之间的分数给出了评论背后的情感)。但训练一个模型来预测这一评分,将有助于我们找到哪些词语(特征)对客户来说是关键。.
我们能做的是 在 data 上训练情感分析分类器, 然后使用 SHAP 或 LIME 等库来理解 其特点是 (=字) 影响最大 评论分为正面和负面。.
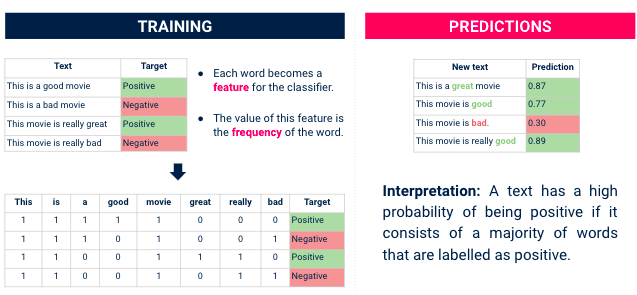
分类器
要训练分类器,您可以使用多种可能的算法,从经典的 sklearn LogisticRegression 到 ULM-fit 模型 (看看 本子 来训练法国的 ULM 拟合模型,以及 本条 以进一步了解 ULM-fit)或 Uber 开发的路德维希分类器。.
在采用更复杂的算法之前,您可能想先从简单的算法开始,看看它是否能满足您的需求。.
请务必考虑到这样一个事实,即您的 dataset 很可能是不平衡的(就我们而言,正面评价多于负面评价)。.
功能的重要性
实现分类器后,您就可以进入最重要的一步:从特征重要性中获取见解。.
在下面的示例中,我们将 SHAP 应用于我们的模型(这里是一个简单的 sklearn LogisticRegression):

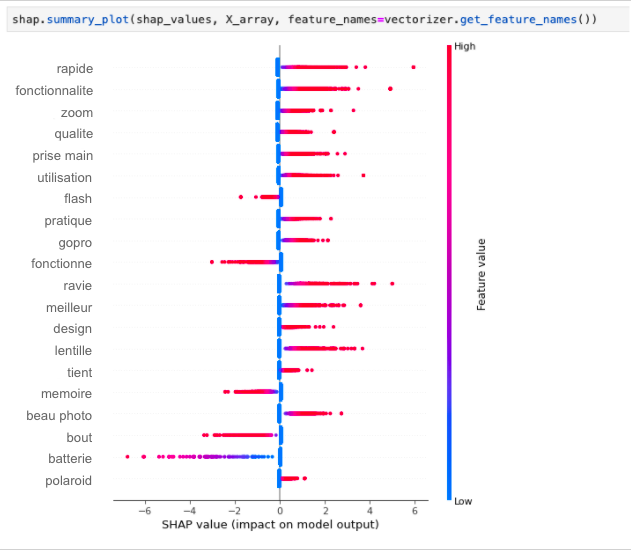
从这里我们可以看出,功能、照片质量和变焦功能对客户的满意度有非常积极的影响,而闪光灯、存储卡或电池在评论中被提及时往往会产生非常消极的影响。.
本分析(在训练分类器之前)删除了 “优秀”、“完美 ”或 “糟糕 ”等词语,因为它们将被视为最重要的特征,而在我们的案例中,我们希望专注于寻找对产品的见解,而不是真正提高分类器的性能。.
参见 本子 的示例,说明如何使用 SHAP 和公共 dataset。.
业务主题的影响
我们的第三种方法与前几种方法有些不同,因为它是由了解产品的人从与商业相关的主题出发选择的。.
重点是分析预定义的业务主题如何影响产品评级,了解这些主题是优势还是需要解决的问题。.
确定主题
第一步是将评论分类到主题类别中。您可以手动为 dataset 贴标签(然后,如果您想自动将新评论归入主题,可以训练分类器),也可以使用基于规则的模型。.
在我们的案例中,我们使用了基于规则的模型,因为它已经可以以较低的成本带来良好的结果(例如:如果您对您的镜片质量或售后服务感到好奇,可以很简单地建立规则来确定评论是否提及这些内容)。.
主题影响
第二步,您可以计算全球平均得分,然后计算特定主题评论的平均得分。.
将这两项得分相减,就可以得出主题对总得分的影响。.
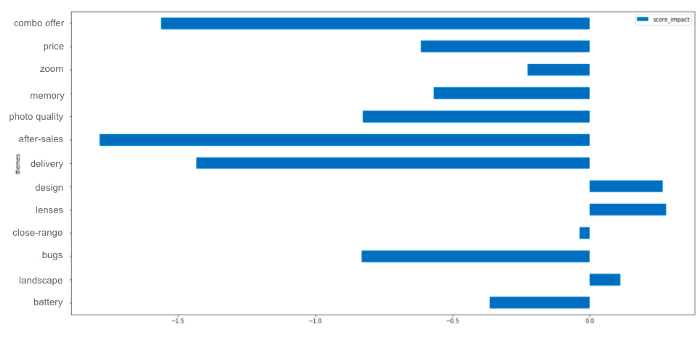
在这里,我们应该担心的是我们的售后服务,因为它经常被以负面的方式提及(当然也可能是因为联系售后服务的人往往一开始就有问题。因此,您应该详细查看提及这一主题的评论,以真正了解为何会出现这一问题)。.
→ 同样,业务知识对于理解结果也至关重要。.
另一方面,当我们的设计或镜头被提及时,往往会与高分评论联系在一起,这可能意味着这是我们的强项之一。.
参见 本条 以获取更多 Wordcloud 的可视化替代方案。.
更进一步
我们可以更进一步,尝试检测评论中的主题:您可以使用 Top2Vec 库来提取主题,并查看主题和分数之间的相关性(任何主题建模库都可以使用,但 Top2Vec 它的优点是无需任何预处理,也无需预先确定主题数量,就能获得很好的结果)。.
本文介绍了如何通过实用而简单的分析,从文本 data 中获得客户洞察力。感谢您阅读本文,如果您对本文有任何意见,请随时联系我们!您可以访问我们的博客 这里 了解有关我们机器学习项目的更多信息。.

