

Author

Le SEO technique ne se limite pas à corriger ses 404 et peut relever des problèmes majeurs sur un site web. Voici 5 points importants à contrôler dans un audit.
1 – Google voit-il bien la page web complète ?
Depuis bien 10 ans, les sites web sont très dépendants du JavaScript pour la génération de leurs pages. Google est en capacité d’exécuter une page avec toutes ses ressources, mais plus une page est légère, elle a de chances d’être chargée en entier. A l’inverse, le risque est qu’il passe à côté d’éléments essentiels de la page si elle est trop lourde (zones de contenu, liens).
L’outil d’Inspection de l’URL de la Search Console permet de vérifier comment Google a vu la page : le code HTML généré est-il bien le même que ce qu’on a dans notre navigateur, les ressources utiles (CSS et JS essentiels) sont-elles bien chargées ?
L’outil d’inspection de l’URL propose en réalité deux fonctions :
Attention donc à étudier vos pages à travers la version adaptée à votre analyse.

2 – Google ne voit-il que les pages utiles du site ?
On a la mauvaise habitude de considérer qu’une URL en HTTP 200 est une bonne chose, et une URL en HTTP 404 est un problème. Comme souvent en SEO, il n’y a pas de réponse binaire, et une prise de recul est nécessaire.
Prenons l’exemple d’un site e-commerce : il se compose principalement de pages de listings (catégories) et de fiches produit.
Une page listing (Catégories, Sous-catégories) est susceptible de proposer des options d’UX à l’internaute comme des filtres (couleur) et des tris (prix).
Ces options génèrent souvent des URLs avec paramètres quasiment infinies du fait des combinaisons d’options (ce qui donnerait exemple.com/chemises?couleur=Bleu&taille=XS). Le risque est de laisser accessible à Google un nombre incontrôlé de pages inutiles au SEO, car faibles (trop de filtres donc peu de produits) ou dupliquées (produits identiques ordonnées différemment).
Surveillez donc dans la Search Console le nombre de pages “Valides” (vertes). Encore mieux, si vos sitemaps sont proprement configurés pour ne contenir que les pages utiles et connues de votre site, vous pourrez distinguer :
Le danger est donc dans cette seconde catégorie, malgré sa couleur verte rassurante.

D’un autre côté, un produit a un cycle de vie qui implique sa disparition du site à terme. Sa page sera naturellement passée en HTTP 404, qui s’ajoutera aux autres produits disparus récemment – donc au rapport de Couverture de la Search Console sur les URLs Exclues – Introuvable (404). Au même titre que les feuilles mortes qui s’accumulent au pied d’un arbre en automne, c’est un comportement normal pour un site. Et d’une manière générale, quel est le risque pour votre site que Google voie des URLs en 404 ? Aucun.
3 – Google considère-t-il bien le site comme compatible mobile ?
La fixation de Google en SEO sur le sujet du mobile a abouti à la mise en ligne de son index mobile : la qualité d’un site en SEO est évaluée selon sa version mobile. Il faut notamment s’assurer qu’il n’y a pas de différences de contenu et de liens entre version desktop et version mobile.
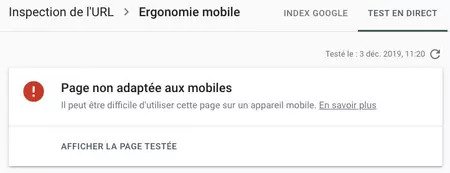
On rencontre parfois un problème plus rare mais plus critique : Google peut considérer qu’un site n’est pas mobile. La plupart des sites sont en Responsive Web Design (RWD) rendant un même site compatible en desktop et en mobile. C’est justement cette technologie qui peut être un piège : elle est gérée par des fichiers de ressources du site (principalement le CSS) qui peuvent être bloqués à Google involontairement.
On retrouve parfois dans le robots.txt (fichier indiquant à Google ce qu’il peut voir ou non sur un site) des consignes bloquant les ressources nécessaires au Responsive Design, souvent dû à un legacy d’ancien CMS (ou de robots.txt gérant plusieurs répertoires sous des CMS différents). Google ne pourra alors générer les pages du site qu’avec des feuilles de style incomplètes et jugera le site non compatible. Heureusement, constater ce problème est simplissime (la Search Console remonte l’erreur, on peut tester une page via le Test d’optimisation mobile) et sa résolution en général relativement rapide.
4 – Voyez-vous bien le même site que Google avec votre navigateur et vos outils ?
Une page web est générée par un serveur web. Celui-ci répond à une requête à une URL qui contient les informations du demandeur, notamment : l’User-Agent pour identifier le type de demandeur (outil, navigateur, robot d’exploration) et l’adresse IP. Le serveur renvoie donc une réponse HTTP, accompagnée souvent d’une page web. Une réponse HTTP200 est accompagnée de la page demandée, une réponse HTTP404 ou HTTP500 ne l’est pas.
En bref, certains sites répondront différemment selon qui fait la demande. Ce qui pose deux problèmes majeurs :

Un exemple courant est le statut en ligne de pages qui sont redirigées pour l’internaute : une page exemple.com peut exister pour Google mais être redirigée vers exemple.com/fr_FR/ pour l’internaute, du fait de la langue de son navigateur et de ses cookies (ce dont ne se sert pas le robot d’exploration de Google).
5 – Les données structurées sont-elles une menace pour le site ?
Dans la même logique que les extensions d’annonces en SEA, les résultats naturels bénéficient d’ajouts visuels variés. Les données structurées sont des métadonnées identifiant plusieurs éléments clés d’une page selon des formats définis. La finalité est une meilleure lecture de ces éléments par les moteurs de recherche, en échange de quoi ils génèrent des extraits enrichis dans leurs résultats de recherche. L’exemple phare est celui des données structurées relatives à un produit : on identifie son nom, son prix, sa disponibilité et sa note moyenne, et ces éléments s’afficheront pour cette page dans les résultats de recherche.
Malgré la grande précision de la documentation des données structurées (par Schema.org et Google) et les outils de test de leur implémentation, les erreurs restent courantes, même parmi les CMS les plus avancés du marché.
Dans le meilleur des cas, une mauvaise implémentation les rend partiellement inopérantes – l’élément en cause ne génèrera pas d’extraits enrichis sans bloquer les autres (un prix bien balisé ne sera pas bloqué par une note moyenne déficiente).
Plus grave, une implémentation valide à première vue peut nuire au site. Certains CMS du marché se montrent très généreux dans leur balisage : des pages produit où sont balisés le produit principal mais également les produits associés (en cross-sell). Le produit principal est clairement identifié par le reste de la page (title, H1) mais les prix sont multiples. Google doit choisir un prix à afficher pour cette page dans les résultats de recherche, et a peu de chances de retenir le bon. On se retrouve donc avec des pages produit dans les SERP avec des prix incorrects : inférieurs ou supérieurs, déceptifs pour l’internaute.
Le cas le plus sérieux et malheureusement pas si rare concerne les pénalités manuelles de Google. Une implémentation considérée comme abusive vis-à-vis des pratiques autorisées par Google quant aux données structurées amènera à un retrait complet des extraits enrichis pour le site, jusqu’à résolution du problème et demande de reconsidération de l’action manuelle (ensuite validée par une personne physique). Des cas récents ont pris 2 mois à être reconsidérés, pendant lesquels les sites concernés étaient désavantagés dans les SERP vis-à-vis des concurrents (visuellement uniquement, sans impact sur les positions).

