

Autor

La técnica de SEO no se limita a corregir los 404 y puede resolver problemas importantes en un sitio web. Aquí tienes 5 puntos importantes que debes controlar en una auditoría.
1 - ¿Google ve bien la página web completa?
Desde hace 10 años, los sitios web dependen en gran medida de JavaScript para la creación de sus páginas. Google tiene la capacidad de ejecutar una página con todos sus recursos, pero si una página es grande, tiene posibilidades de ser cargada en su totalidad. A la inversa, el riesgo es que se pierdan elementos esenciales de la página si es demasiado extensa (zonas de contenido, enlaces).
La herramienta de inspección de la URL de Search Console permite comprobar cómo ha visto Google la página: ¿el código HTML generado es el mismo que el de nuestro navegador, los recursos útiles (CSS y JS esenciales) están bien cargados?
La herramienta de inspección de la URL ofrece en realidad dos funciones:
Por lo tanto, estudie sus páginas a través de la versión adaptada a su análisis.

2 - ¿Google sólo ve las páginas útiles del sitio?
Se suele considerar que una URL en HTTP 200 es buena, y una URL en HTTP 404 es un problema. Como ocurre a menudo en SEO, no hay respuesta binaria, y es necesario hacer una rectificación.
Veamos el ejemplo de un sitio de comercio electrónico: se compone principalmente de páginas de listados (categorías) y de fichas de productos.
Un listado de páginas (Categorías, Subcategorías) puede proponer opciones de UX al internauta como filtros (color) y tris (precio).
Estas opciones suelen generar URLs con parámetros casi infinitos debido a las combinaciones de opciones (lo que hace que, por ejemplo,.com/chemises?couleur=Bleu&taille=XS). El riesgo es dejar que Google acceda a un número incontrolado de páginas inutilizables para el SEO, ya sean débiles (demasiados filtros y por tanto pocos productos) o duplicadas (productos idénticos ordenados de forma diferente).
Por lo tanto, comprueba en Search Console el número de páginas "válidas" (verdes). Además, si sus mapas de sitio están bien configurados para no contener más que las páginas útiles y conocidas de su sitio, podrá distinguir :
Por lo tanto, el peligro está en esta segunda categoría, a pesar de su color verde amenazante.

Por otro lado, un producto tiene un ciclo de vida que implica su desaparición del sitio web. Su página pasará naturalmente a HTTP 404, que se sumará a otros productos eliminados anteriormente, por lo que el informe de la Consola de Búsqueda sobre las URLs Excluidas - Introvitable (404). Al igual que las hojas muertas que se acumulan al pie de un árbol en otoño, es un comportamiento normal para un sitio. Y de manera general, ¿qué riesgo tiene tu sitio web de que Google le dé una URL en 404? Ninguno.
3 - ¿Google considera que el sitio es compatible con los móviles?
La fijación de Google en SEO sobre el tema de los móviles ha dado lugar a la puesta en línea de su índice móvil: la calidad de un sitio en SEO se evalúa según su versión móvil. En este sentido, hay que asegurarse de que no haya diferencias de contenido y de enlaces entre la versión de escritorio y la versión móvil.
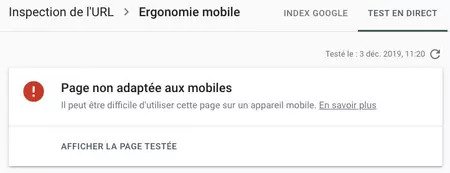
A veces nos encontramos con un problema más raro pero más crítico: Google puede considerar que un sitio no es móvil. La mayoría de los sitios están en Responsive Web Design (RWD) haciendo que un mismo sitio sea compatible en escritorio y en móvil. Precisamente esta tecnología puede ser un inconveniente: se basa en archivos de recursos del sitio (principalmente el CSS) que pueden ser bloqueados por Google de forma involuntaria.
A veces se encuentran en el robots.txt (archivo que indica a Google lo que puede ver o no en un sitio) consignas que bloquean los recursos necesarios para el Responsive Design, a menudo debido a un legado de un antiguo CMS (o de robots.txt que indica varios sitios web bajo diferentes CMS). Google no podrá entonces generar las páginas del sitio si no es con letras de estilo incompatibles y considerará que el sitio no es compatible. Sin embargo, detectar este problema es muy sencillo (Search Console detecta el error y se puede probar una página a través del Test de optimización para móviles) y su solución es relativamente rápida.
4 - ¿Vas a visitar el mismo sitio que Google con tu navegador y tus herramientas?
Una página web es generada por un servidor web. Éste responde a una solicitud de una URL que contiene la información del solicitante, en particular: el User-Agent para identificar el tipo de solicitante (herramienta, navegador, robot de exploración) y la dirección IP. El servidor envía una respuesta HTTP, a menudo acompañada de una página web. Una respuesta HTTP200 está acompañada de la página solicitada, una respuesta HTTP404 o HTTP500 no lo está.
En resumen, algunos sitios responden de forma diferente según quién los solicite. Esto plantea dos problemas importantes:

Un ejemplo ilustrativo es el estado en línea de las páginas que se redirigen para el internauta: una página exemple.com puede existir para Google pero redirigirse a exemple.com/fr_FR/ para el internauta, debido al idioma de su navegador y de su página cookies (lo que no significa que sea el robot de exploración de Google).
5 - Los datos estructurados, ¿son una amenaza para el sitio web?
Con la misma lógica que las extensiones de anuncios en SEA, los resultados naturales se benefician de diversos ajustes visuales. Los datos estructurados son métadrones que identifican varios elementos claros de una página según los formatos definidos. El resultado es una mejor lectura de estos elementos por parte de los investigadores, a cambio de lo cual se obtienen extractos enriquecidos en sus resultados de investigación. El ejemplo más claro es el de los datos estructurados sobre un producto: se identifica su nombre, su precio, su disponibilidad y su nota media, y estos elementos aparecen en esta página de los resultados de la investigación.
A pesar de la gran precisión de la documentación de los datos estructurados (por Schema.org y Google) y de las herramientas de prueba de su implementación, los errores siguen siendo frecuentes, incluso entre los CMS más avanzados del mercado.
En la mayoría de los casos, una mala implementación los hace parcialmente inoperantes - el elemento en cuestión no genera extracciones enriquecidas sin bloquear las otras (un precio bien equilibrado no será bloqueado por una nota media deficiente).
Y lo que es más grave, una implementación válida a primera vista puede perjudicar al sitio. Algunos CMS del mercado son muy frecuentes en su balanceo: las páginas de producto donde se balancea el producto principal pero también los productos asociados (en venta cruzada). El producto principal está claramente identificado por el resto de la página (título, H1) pero los precios son múltiples. Google tiene que elegir un precio para esta página en los resultados de la búsqueda, y no tiene muchas posibilidades de conseguirlo. Por lo tanto, hay páginas que aparecen en las SERP con precios erróneos: inferiores o superiores a los que el internauta puede aceptar.
El caso más grave, y desgraciadamente no tan raro, es el de las sanciones penales de Google. Una implementación considerada como abusiva respecto a las prácticas autorizadas por Google en cuanto a los datos estructurados conlleva la retirada completa de los extractos enriquecidos para el sitio, hasta la resolución del problema y la solicitud de reconsideración de la acción manual (posteriormente validada por una persona física). Los casos más recientes tardaron 2 meses en ser reconsiderados, durante los cuales los sitios en cuestión se redujeron en las SERP con respecto a los competidores (visualmente sólo, sin impacto en las posiciones).

