Challenge: scaling advanced Precision Marketing across 30+ markets
Sanofi is one of the world leaders in the pharmaceutical industry. In the past 3 years, Artefact has helped the Sanofi CHC (Consumer Health Care) business unit market its over-the-counter medications via digital-first tactics and enablers to reach the right consumers at the right time with the right message, across more than 30 markets.
For its seasonal products category, Sanofi CHC has developed a forecasting-based approach to adjust digital media spend according to predicted demand peaks. Through multiple pilot campaigns, the Global Digital Transformation team was able to prove the added value of this approach with an ROAS multiplied by 2 to 4 according to geographies.
However, setting up a new campaign remained time-consuming: data scientists had to go through a series of manual, repetitive and error-prone tasks, preventing them from focusing on other innovative projects. In order to scale its innovative ML pipelines, the Sanofi data science team defined their needs to industrialise the use case and called for the support of Artefact to jointly design and implement a robust solution.
Solution: a co-designed industrialisation process based on 6 key solutions
“The key to the success of the project was the close collaboration between Sanofi business experts and Sanofi data scientists with the Artefact team.”
– Albert Pla Planas, Data Science Team Lead, Sanofi
Through a close collaboration between Artefact and Sanofi’s data and business teams, a comprehensive industrialisation process leveraging the unified Databricks platform was designed. Our joint objectives were to:
Simplify the end-to-end setup of a new seasonal campaign
Automate data ingestion and processing tasks
Make the solution more robust to prevent errors and manual maintenance
Improve project maintainability and scaling
Following a swift 1-week audit to map out the current process and technical pain points, the team aligned on implementing a future-proof infrastructure based on 6 key solutions:
Separation of concerns:
Having a separate ETL pipeline from the forecasting model process makes it easier to maintain and scale. This allowed us to implement automated checks alongside a monitoring system that sends detailed reports to the relevant teams about the ingestion status.
Use of Delta Lake as a data golden source:
In DS teams where infrastructure can be a pain to obtain/maintain, Delta Lake combines the key features of data warehouse and data lakes solutions, thereby removing the complexity of SQL database admin. It also has versioning capabilities – important for ML reproducibility – and will serve as the unique source of truth for data.
Packaging as much code as possible into a Python library to simplify processes:
Part of the initial code was scattered among several notebooks within Databricks, complexifying management of dependencies and code reusability. Notebook-based development is relevant for prototyping but can create challenges for ML projects industrialisation. Having clearly defined Python libraries implemented on the notebook and keeping only Databricks as entry point for Compute made it easier to generalise notebooks and organise incoming campaigns.
Leveraging Spark and Databricks:
Training the model using hyperparameter search methods can be time-consuming and demanding. This is where the autoscaling infrastructure of Databricks and the managed ML runtime with Spark and HyperOpt come in handy. Using memory computations in a distributed manner over a set of workers speeds up performance and considerably improves training time.
Use of ML Flow tracking:
With ML Flow tracking in place, Sanofi now has a User Interface where Data Scientists can compare model runs and keep track of all parameters used (Data version and model parameters) and results obtained.
Simplified new ML model testing and implementation:
A generic model factory framework was set up, making it easier to implement new machine learning models, and to try them during a Precision Marketing campaign with very little effort.
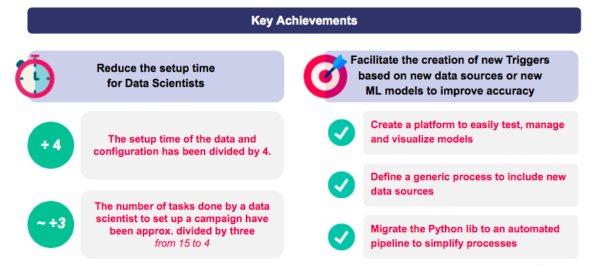
Results and Learnings: a setup time divided by four for data ingestion and configuration
Thanks to this project, Sanofi CHC was able to greatly simplify its data pipeline and accelerate the scaling of its forecasting-based Precision Marketing use case.
Reduction of setup time for new campaigns:
- Setup time for data ingestion and configuration reduced by up to a fourth.
- Number of tasks performed by data scientists to set up a new campaign reduced by up to a third.
Simplification of the creation of new forecasting models:
- Accessible platform to easily test, manage and visualise models.
- Generic process to include new data sources.
- Automated data pipeline.
The project also allowed the teams to generate 4 important learnings for future ML-driven projects:
Integrate data engineering in ML projects:
Involve Data Engineers from the beginning of a project to accelerate industrialisation of the pipeline, and clearly decouple the different stages of the pipeline (all data handling, transformation and curation must happen before jumping into the ML stages).
Tap into pre-packaged tools:
The use of Databricks with Delta Lake and ML Flow was crucial to industrialisation success, ensuring an easy self-service infrastructure without the need for DevOps.
Deep collaboration between Business and Data teams:
Possibly the most important success factor was the close collaboration between Sanofi business experts and data scientists, who ideated and drove the project, with the Artefact team, who brought additional industrialisation experience and know-how.
Use agile methodologies to industrialise:
The agile methodology (sprints, and quick iterations followed by feedback & alignment weeks) was very efficient to identify and address all Sanofi’s pain points and ensure value delivery for Sanofi teams.
Artefact would like to thank Ayaka Yanagisawa, Albert Pla Planas, Antoine Tran-Quan-Nam, Laurent Gautier and Sergio Villordo from Sanofi for their trust and collaboration on this project, as well as the Databricks team for their reactive support. This article was co-produced by the Sanofi CHC and Databricks teams alongside Tristan Silhol, Maui Bar, Louise Morin and Eva Le Saux from Artefact US and France offices.