Herausforderung: Skalierung von fortschrittlichem Präzisionsmarketing in über 30 Märkten
Sanofi ist einer der Weltmarktführer in der Pharmaindustrie. In den letzten 3 Jahren, Artefact hat geholfen die Geschäftseinheit Sanofi CHC (Consumer Health Care) vermarktet ihre rezeptfreien Medikamente über Digital-First-Taktiken und -Einrichtungen, um die richtigen Verbraucher zur richtigen Zeit mit der richtigen Botschaft zu erreichen, in mehr als 30 Märkten.
Für seine Kategorie der saisonalen Produkte hat Sanofi CHC einen auf Prognosen basierenden Ansatz entwickelt, um die Ausgaben für digitale Medien entsprechend den vorhergesagten Nachfragespitzen anzupassen. Durch mehrere Pilotkampagnen konnte das Global Digital Transformation Team den Mehrwert dieses Ansatzes mit einen ROAS, der je nach Region mit 2 bis 4 multipliziert wird.
Allerdings, das Einrichten einer neuen Kampagne blieb zeitaufwendig: Die Wissenschaftler von data mussten eine Reihe von manuellen, sich wiederholenden und fehleranfälligen Aufgaben erledigen, was sie daran hinderte, sich auf andere innovative Projekte zu konzentrieren. Um seine innovativen ML-Pipelines zu skalieren, definierte das data-Wissenschaftlerteam von Sanofi seine Bedürfnisse, um den Anwendungsfall zu industrialisieren, und bat um die Unterstützung von Artefact, um gemeinsam eine robuste Lösung zu entwickeln und zu implementieren.
Lösung: ein mitgestalteter Industrialisierungsprozess auf der Grundlage von 6 Schlüssellösungen
“Der Schlüssel zum Erfolg des Projekts war die enge Zusammenarbeit zwischen den Geschäftsexperten von Sanofi und den Wissenschaftlern von Sanofi data mit dem Artefact-Team.”
- Albert Pla Planas, Data Wissenschaftlicher Teamleiter, Sanofi
Durch eine enge Zusammenarbeit zwischen dem Artefact und dem data von Sanofi sowie den Geschäftsteams wurde ein umfassender Industrialisierungsprozess unter Nutzung des einheitlichen Databricks Plattform entworfen wurde. Unsere gemeinsamen Ziele waren:
Vereinfachen Sie die durchgängige Einrichtung einer neuen saisonalen Kampagne
Automatisieren Sie data-Aufnahme- und Verarbeitungsaufgaben
Machen Sie die Lösung robuster, um Fehler und manuelle Wartung zu vermeiden
Verbessern Sie die Wartbarkeit und Skalierbarkeit des Projekts
Nach einem schnellen 1-wöchigen Audit, bei dem die aktuellen Prozesse und technischen Probleme erfasst wurden, konzentrierte sich das Team auf die Implementierung einer zukunftssicheren Infrastruktur auf der Grundlage von 6 Schlüssellösungen:
Trennung der Anliegen:
Eine vom Prognosemodellprozess getrennte ETL-Pipeline ist einfacher zu pflegen und zu skalieren. So konnten wir neben einem Überwachungssystem, das detaillierte reports an die zuständigen Teams über den Ingestion-Status sendet, auch automatisierte Prüfungen implementieren.
Verwendung von Deltasee als data goldene Quelle:
In DS-Teams, in denen die Beschaffung/Wartung der Infrastruktur mühsam sein kann, kombiniert Delta Lake die wichtigsten Funktionen von data Warehouse- und data Lakes-Lösungen und beseitigt so die Komplexität der SQL database-Administration. Delta Lake verfügt außerdem über Versionierungsfunktionen - wichtig für die Reproduzierbarkeit von ML - und wird als einzige Quelle der Wahrheit für data dienen.
Packen Sie so viel Code wie möglich in eine Python-Bibliothek, um Prozesse zu vereinfachen:
Ein Teil des ursprünglichen Codes war über mehrere Notebooks innerhalb von Databricks verstreut, was die Verwaltung von Abhängigkeiten und die Wiederverwendbarkeit von Code erschwerte. Die Notebook-basierte Entwicklung ist für das Prototyping von Bedeutung, kann aber bei der Industrialisierung von ML-Projekten eine Herausforderung darstellen. Durch klar definierte Python-Bibliotheken, die auf dem Notebook implementiert wurden, und die Beibehaltung von Databricks als Einstiegspunkt für Compute war es einfacher, die Notebooks zu verallgemeinern und die eingehenden Kampagnen zu organisieren.
Nutzung von Spark und Databricks:
Das Training des Modells mit Hyperparametersuchmethoden kann zeitaufwändig und anspruchsvoll sein. Hier kommen die autoskalierende Infrastruktur von Databricks und die verwaltete ML-Laufzeit mit Spark und HyperOpt ins Spiel. Die verteilte Nutzung von Speicherberechnungen über eine Reihe von Workern beschleunigt die Leistung und verbessert die Trainingszeit erheblich.
Verwendung von ML Flow Tracking:
Mit ML Flow Tracking verfügt Sanofi nun über eine Benutzeroberfläche, über die Data-Wissenschaftler Modellläufe vergleichen und alle verwendeten Parameter (Data-Version und Modellparameter) sowie die erzielten Ergebnisse verfolgen können.
Vereinfachtes Testen und Implementieren neuer ML-Modelle:
Es wurde ein generisches Modellfabrik-Framework eingerichtet, das die Implementierung neuer Modelle für maschinelles Lernen und deren Erprobung während einer Precision Marketing-Kampagne mit sehr geringem Aufwand erleichtert.
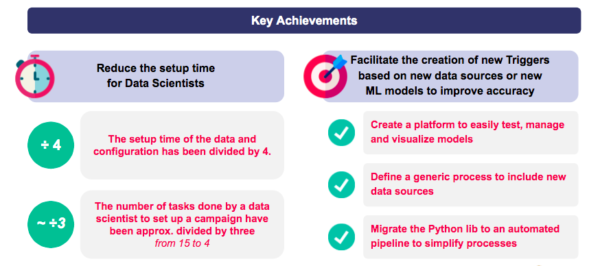
Ergebnisse und Erkenntnisse: eine durch vier geteilte Einrichtungszeit für data Ingestion und Konfiguration
Dank dieses Projekts war Sanofi CHC in der Lage, seine data-Pipeline erheblich zu vereinfachen und die Skalierung seines auf Prognosen basierenden Precision Marketing-Anwendungsfalls zu beschleunigen.
Verkürzung der Einrichtungszeit für neue Kampagnen:
- Die Einrichtungszeit für die data-Ingestion und -Konfiguration wurde um bis zu einem Viertel reduziert.
- Die Anzahl der von data-Wissenschaftlern durchgeführten Aufgaben zur Einrichtung einer neuen Kampagne wurde um bis zu einem Drittel reduziert.
Vereinfachung der Erstellung von neuen Prognosemodellen:
- Zugängliche Plattform zum einfachen Testen, Verwalten und Visualisieren von Modellen.
- Generischer Prozess zur Aufnahme neuer data-Quellen.
- Automatisierte data-Pipeline.
Das Projekt ermöglichte es den Teams außerdem, 4 wichtige Erkenntnisse für zukünftige ML-gesteuerte Projekte zu gewinnen:
Integrieren Sie data-Technik in ML-Projekte:
Beziehen Sie Data Engineers von Anfang an in ein Projekt ein, um die Industrialisierung der Pipeline zu beschleunigen, und entkoppeln Sie die verschiedenen Phasen der Pipeline klar voneinander (die gesamte data-Bearbeitung, -Umwandlung und -Kuration muss vor dem Sprung in die ML-Phasen erfolgen).
Nutzen Sie vorgefertigte Tools:
Der Einsatz von Databricks mit Delta Lake und ML Flow war entscheidend für den Erfolg der Industrialisierung, da sie eine einfache Self-Service-Infrastruktur ohne DevOps gewährleisten.
Intensive Zusammenarbeit zwischen Business- und Data-Teams:
Der vielleicht wichtigste Erfolgsfaktor war die enge Zusammenarbeit zwischen den Geschäftsexperten von Sanofi und den Wissenschaftlern des data, die das Projekt konzipiert und vorangetrieben haben, und dem Team des Artefact, das zusätzliche Erfahrung und Know-how bei der Industrialisierung einbrachte.
Verwenden Sie agile Methoden zur Industrialisierung:
Die agile Methodik (Sprints und schnelle Iterationen, gefolgt von Feedback- und Anpassungswochen) war sehr effizient, um alle Schmerzpunkte von Sanofi zu identifizieren und anzugehen und die Wertschöpfung für die Sanofi-Teams sicherzustellen.
Artefact dankt Ayaka Yanagisawa, Albert Pla Planas, Antoine Tran-Quan-Nam, Laurent Gautier und Sergio Villordo von Sanofi für ihr Vertrauen und ihre Mitarbeit an diesem Projekt sowie dem Team von Databricks für seine reaktive Unterstützung. Dieser Artikel wurde von den Teams von Sanofi CHC und Databricks gemeinsam mit Tristan Silhol, Maui Bar, Louise Morin und Eva Le Saux aus den Büros von Artefact in den USA und Frankreich verfasst.