Reto: ampliar el marketing de precisión avanzado a más de 30 mercados
Sanofi es uno de los líderes mundiales de la industria farmacéutica. En los últimos 3 años, Artefact ha ayudado a la unidad de negocio CHC (Consumer Health Care) de Sanofi comercializa sus medicamentos sin receta a través de tácticas y facilitadores "digital-first" para llegar a los consumidores adecuados en el momento oportuno con el mensaje adecuado, en más de 30 mercados.
Para su categoría de productos estacionales, Sanofi CHC ha desarrollado un enfoque basado en la previsión para ajustar el gasto en medios digitales en función de los picos de demanda previstos. A través de múltiples campañas piloto, el equipo de Transformación Digital Global pudo demostrar el valor añadido de este enfoque con un ROAS multiplicado por 2 a 4 según las geografías.
Sin embargo, crear una nueva campaña seguía llevando mucho tiempo: Los científicos de data tenían que realizar una serie de tareas manuales, repetitivas y propensas a errores, lo que les impedía centrarse en otros proyectos innovadores. Con el fin de escalar sus innovadoras canalizaciones de ML, el equipo científico de Sanofi data definió sus necesidades para industrializar el caso de uso y solicitó el apoyo de Artefact para diseñar e implementar conjuntamente una solución robusta.
Solución: un proceso de industrialización codiseñado basado en 6 soluciones clave
“La clave del éxito del proyecto fue la estrecha colaboración entre los expertos empresariales de Sanofi y los científicos del data de Sanofi con el equipo del Artefact.”
- Albert Pla Planas, Data Jefe de equipo científico, Sanofi
A través de una estrecha colaboración entre el Artefact y el data de Sanofi y los equipos empresariales, se ha puesto en marcha un proceso de industrialización integral que aprovecha el sistema unificado de Databricks plataforma fue diseñada. Nuestros objetivos conjuntos eran
Simplifique la configuración de principio a fin de una nueva campaña estacional
Automatizar las tareas de ingestión y procesamiento de data
Hacer la solución más robusta para evitar errores y el mantenimiento manual
Mejorar la mantenibilidad y escalabilidad del proyecto
Tras una rápida auditoría de una semana para trazar el proceso actual y los puntos débiles técnicos, el equipo se alineó para implantar una infraestructura preparada para el futuro basada en 6 soluciones clave:
Separación de preocupaciones:
Disponer de una canalización ETL separada del proceso del modelo de previsión facilita su mantenimiento y ampliación. Esto nos permitió implementar comprobaciones automatizadas junto con un sistema de supervisión que envía reports detallados a los equipos pertinentes sobre el estado de la ingestión.
Uso de Lago Delta como fuente de oro data:
En los equipos de DS en los que la infraestructura puede ser una molestia de obtener/mantener, Delta Lake combina las características clave de las soluciones data warehouse y data lakes, eliminando así la complejidad de la administración de SQL database. También cuenta con capacidades de versionado -importantes para la reproducibilidad del ML- y servirá como única fuente de verdad para data.
Empaquetar todo el código posible en una biblioteca Python para simplificar los procesos:
Parte del código inicial estaba disperso entre varios cuadernos dentro de Databricks, lo que complicaba la gestión de las dependencias y la reutilización del código. El desarrollo basado en cuadernos es pertinente para la creación de prototipos, pero puede plantear dificultades para la industrialización de proyectos de ML. Tener claramente definidas las bibliotecas Python implementadas en el cuaderno y mantener sólo Databricks como punto de entrada para Compute facilitó la generalización de los cuadernos y la organización de las campañas entrantes.
Aprovechando Spark y Databricks:
Entrenar el modelo utilizando métodos de búsqueda de hiperparámetros puede llevar mucho tiempo y ser muy exigente. Aquí es donde la infraestructura de autoescalado de Databricks y el tiempo de ejecución ML gestionado con Spark e HyperOpt resultan útiles. El uso de cálculos en memoria de forma distribuida entre un conjunto de trabajadores acelera el rendimiento y mejora considerablemente el tiempo de entrenamiento.
Uso de ML Seguimiento del flujo:
Con ML Seguimiento del flujo en marcha, Sanofi dispone ahora de una interfaz de usuario en la que los científicos del Data pueden comparar las ejecuciones del modelo y hacer un seguimiento de todos los parámetros utilizados (versión del Data y parámetros del modelo) y de los resultados obtenidos.
Simplificación de la prueba y aplicación de nuevos modelos de ML:
Se creó un marco genérico de fábrica de modelos, lo que facilitó la implementación de nuevos modelos de aprendizaje automático y la posibilidad de probarlos durante una campaña de marketing de precisión con muy poco esfuerzo.
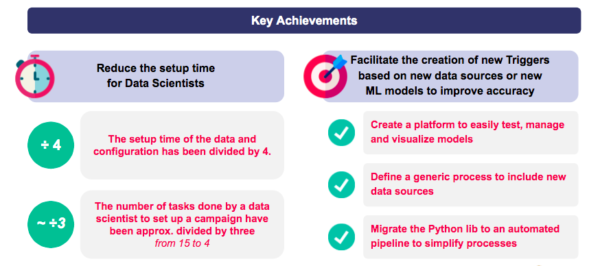
Resultados y enseñanzas: un tiempo de preparación dividido por cuatro para la ingesta y configuración del data
Gracias a este proyecto, Sanofi CHC pudo simplificar en gran medida su pipeline data y acelerar el escalado de su caso de uso de marketing de precisión basado en la previsión.
Reducción del tiempo de preparación de nuevas campañas:
- El tiempo de preparación para la ingesta y configuración del data se ha reducido hasta en una cuarta parte.
- El número de tareas realizadas por los científicos del data para poner en marcha una nueva campaña se ha reducido hasta en un tercio.
Simplificación de la creación de nuevos modelos de previsión:
- Plataforma accesible para probar, gestionar y visualizar fácilmente los modelos.
- Proceso genérico para incluir nuevas fuentes data.
- Tubería automatizada data.
El proyecto también permitió a los equipos generar 4 aprendizajes importantes para futuros proyectos basados en ML:
Integrar la ingeniería data en los proyectos de ML:
Implique a los Data Engineer desde el principio de un proyecto para acelerar la industrialización de la tubería, y desvincule claramente las diferentes etapas de la tubería (todo el manejo, transformación y curación de data debe ocurrir antes de saltar a las etapas de ML).
Aproveche las herramientas preconfeccionadas:
El uso de Databricks con Delta Lake y ML Flow fue crucial para el éxito de la industrialización, garantizando una infraestructura de autoservicio sencilla sin necesidad de DevOps.
Profunda colaboración entre los equipos Business y Data:
Posiblemente, el factor de éxito más importante fue la estrecha colaboración entre los expertos empresariales de Sanofi y los científicos del data, que idearon e impulsaron el proyecto, con el equipo del Artefact, que aportó experiencia y conocimientos técnicos adicionales para la industrialización.
Utilizar metodologías ágiles para industrializar:
La metodología ágil (sprints e iteraciones rápidas seguidas de semanas de retroalimentación y alineación) fue muy eficaz para identificar y abordar todos los puntos débiles de Sanofi y garantizar la entrega de valor para los equipos de Sanofi.
Artefact desea agradecer a Ayaka Yanagisawa, Albert Pla Planas, Antoine Tran-Quan-Nam, Laurent Gautier y Sergio Villordo de Sanofi su confianza y colaboración en este proyecto, así como al equipo de Databricks su apoyo reactivo. Este artículo ha sido coproducido por los equipos de Sanofi CHC y Databricks junto con Tristan Silhol, Maui Bar, Louise Morin y Eva Le Saux de las oficinas de Artefact en Estados Unidos y Francia.