Uitdaging: schalen van geavanceerde Precisiemarketing over 30+ markten
Sanofi is een van de wereldleiders in de farmaceutische industrie. In de afgelopen 3 jaar, Artefact heeft geholpen de business unit CHC (Consumer Health Care) van Sanofi brengt zijn receptvrije geneesmiddelen op de markt via digital-first tactieken en enablers om de juiste consumenten op het juiste moment met de juiste boodschap te bereiken, in meer dan 30 markten.
Voor de categorie seizoensgebonden producten heeft Sanofi CHC een op prognoses gebaseerde aanpak ontwikkeld om digitale mediabestedingen aan te passen aan voorspelde pieken in de vraag. Door middel van meerdere proefcampagnes kon het Global Digital Transformation-team de toegevoegde waarde van deze aanpak bewijzen met een ROAS vermenigvuldigd met 2 tot 4 afhankelijk van de regio's.
Echter, het opzetten van een nieuwe campagne bleef tijdrovend: data wetenschappers moesten een reeks handmatige, repetitieve en foutgevoelige taken uitvoeren, waardoor ze zich niet konden concentreren op andere innovatieve projecten. Om hun innovatieve ML-pijplijnen op te schalen, definieerde het Sanofi data wetenschapsteam hun behoeften om de use case te industrialiseren en riep de hulp in van Artefact om samen een robuuste oplossing te ontwerpen en te implementeren.
Oplossing: een gezamenlijk ontworpen industrialisatieproces op basis van 6 belangrijke oplossingen
“De sleutel tot het succes van het project was de nauwe samenwerking tussen de bedrijfsexperts van Sanofi en de Sanofi data wetenschappers met het Artefact team.”
- Albert Pla Planas, Data Wetenschapsteamleider, Sanofi
Door een nauwe samenwerking tussen Artefact en Sanofi's data en bedrijfsteams is een uitgebreid industrialisatieproces opgestart dat gebruik maakt van de verenigde 1TP-technologie. Databricks platform ontworpen. Onze gezamenlijke doelstellingen waren
Vereenvoudig het van begin tot eind opzetten van een nieuwe seizoensgebonden campagne
data opname en verwerkingstaken automatiseren
De oplossing robuuster maken om fouten en handmatig onderhoud te voorkomen
De onderhoudbaarheid en schaalbaarheid van projecten verbeteren
Na een snelle audit van 1 week om het huidige proces en de technische pijnpunten in kaart te brengen, richtte het team zich op de implementatie van een toekomstbestendige infrastructuur op basis van 6 belangrijke oplossingen:
Scheiding van zorgen:
Door een aparte ETL-pijplijn te hebben voor het prognosemodelproces, is het gemakkelijker te onderhouden en op te schalen. Hierdoor konden we geautomatiseerde controles implementeren naast een monitoringsysteem dat gedetailleerde reports naar de relevante teams stuurt over de ingestiestatus.
Gebruik van Deltameer als een data gouden bron:
In DS-teams waar infrastructuur een pijnpunt kan zijn om te verkrijgen/onderhouden, combineert Delta Lake de belangrijkste kenmerken van data warehouse en data lakes oplossingen, waardoor de complexiteit van SQL database admin wegvalt. Het heeft ook versiebeheer mogelijkheden - belangrijk voor ML reproduceerbaarheid - en zal dienen als de unieke bron van waarheid voor data.
Zoveel mogelijk code verpakken in een Python-bibliotheek om processen te vereenvoudigen:
Een deel van de oorspronkelijke code was verspreid over verschillende notebooks binnen Databricks, waardoor het beheer van afhankelijkheden en de herbruikbaarheid van code ingewikkelder werd. Notebookgebaseerde ontwikkeling is relevant voor prototyping, maar kan uitdagingen creëren voor de industrialisatie van ML-projecten. Door duidelijk gedefinieerde Python-bibliotheken op de notebook te implementeren en alleen Databricks als toegangspunt voor Compute te houden, werd het eenvoudiger om notebooks te veralgemenen en binnenkomende campagnes te organiseren.
Spark en Databricks gebruiken:
Het trainen van het model met behulp van hyperparameterzoekmethoden kan tijdrovend en veeleisend zijn. Dit is waar de autoscaling infrastructuur van Databricks en de beheerde ML runtime met Spark en HyperOpt van pas komen. Door geheugenberekeningen gedistribueerd over een aantal werkers te gebruiken, worden de prestaties versneld en wordt de trainingstijd aanzienlijk verbeterd.
Gebruik van ML Stroomtracering:
Met ML Volgen van stromen geïnstalleerd, heeft Sanofi nu een gebruikersinterface waar Data wetenschappers modelruns kunnen vergelijken en alle gebruikte parameters (Data versie en modelparameters) en verkregen resultaten kunnen bijhouden.
Vereenvoudigd testen en implementeren van nieuwe ML-modellen:
Er werd een generiek model factory framework opgezet, waardoor het eenvoudiger werd om nieuwe machine-learning modellen te implementeren en deze met weinig moeite uit te proberen tijdens een Precision Marketing campagne.
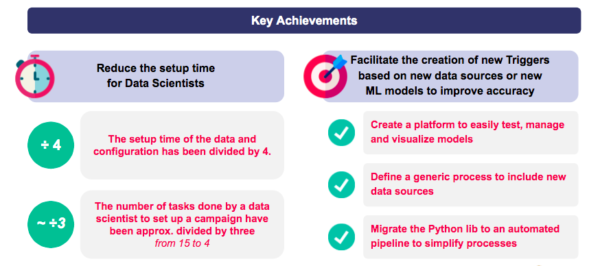
Resultaten en bevindingen: een insteltijd gedeeld door vier voor data opname en configuratie
Dankzij dit project kon Sanofi CHC zijn data pijplijn sterk vereenvoudigen en de schaalvergroting van zijn op voorspellingen gebaseerde Precision Marketing use case versnellen.
Verkorting van de insteltijd voor nieuwe campagnes:
- De insteltijd voor opname en configuratie van de data is met een vierde verminderd.
- Het aantal taken dat data wetenschappers moeten uitvoeren om een nieuwe campagne op te zetten, is met een derde verminderd.
Vereenvoudiging van het maken van nieuwe prognosemodellen:
- Toegankelijk platform om modellen eenvoudig te testen, beheren en visualiseren.
- Generiek proces om nieuwe data bronnen op te nemen.
- Geautomatiseerde data pijpleiding.
Het project stelde de teams ook in staat om 4 belangrijke lessen te genereren voor toekomstige ML-gestuurde projecten:
data engineering integreren in ML projecten:
Betrek Data Engineer's vanaf het begin bij een project om de industrialisatie van de pijplijn te versnellen, en ontkoppel de verschillende stadia van de pijplijn duidelijk van elkaar (alle data behandeling, transformatie en curatie moet gebeuren voordat er naar de ML stadia gesprongen wordt).
Gebruik voorverpakte tools:
Het gebruik van Databricks met Delta Lake en ML Flow was cruciaal voor het succes van de industrialisatie en zorgde voor een eenvoudige self-service infrastructuur zonder dat DevOps nodig was.
Nauwe samenwerking tussen bedrijfs- en Data-teams:
Misschien wel de belangrijkste succesfactor was de nauwe samenwerking tussen de bedrijfsexperts van Sanofi en de data wetenschappers, die het project bedachten en aanstuurden, en het Artefact team, dat extra industrialisatie-ervaring en knowhow inbracht.
Agile methodologieën gebruiken om te industrialiseren:
De agile methodologie (sprints, en snelle iteraties gevolgd door feedback & afstemmingsweken) was zeer efficiënt om alle pijnpunten van Sanofi te identificeren en aan te pakken en ervoor te zorgen dat de teams van Sanofi waarde konden leveren.
Artefact wil graag Ayaka Yanagisawa, Albert Pla Planas, Antoine Tran-Quan-Nam, Laurent Gautier en Sergio Villordo van Sanofi bedanken voor hun vertrouwen en medewerking aan dit project, evenals het Databricks team voor hun reactieve ondersteuning. Dit artikel is geproduceerd door de teams van Sanofi CHC en Databricks, samen met Tristan Silhol, Maui Bar, Louise Morin en Eva Le Saux van de kantoren van Artefact in de VS en Frankrijk.