


作者

逐步指导如何为机器学习算法收集和预处理卫星图像 data
本文是两部分系列文章的第一部分,探讨机器学习算法在卫星图像上的应用。在这里,我们将重点介绍 data 的采集和预处理步骤,而第二部分将展示各种机器学习算法的使用。.
简要说明
本文将
我们将以农田检测和分类为例。预处理步骤使用 Python 和 jupyter notebook。. 用于重现步骤的 jupyter 笔记本可在 github 上获取.
本文假定 data 科学和 python 具有基本的基础知识。.
计算机视觉是机器学习的一个迷人分支,近年来发展迅速。随着公众可以访问许多现成的算法库(如......张力流, OpenCv, Pytorch, Fastai ...)以及开源 datasets (CIFAR -10, Imagenet, IMDB ......)对于 data 科学家来说,获得这方面的实践经验非常容易。.
但您知道您也可以获取开源卫星图像吗?这些类型的图像可用于大量用例(农业、物流、能源......)。然而,由于其大小和复杂性,它们给 data 科学家带来了额外的挑战。我撰写了这篇文章,与大家分享我在工作中的一些主要心得。.
步骤 1 - 选择卫星打开 data 信号源
首先,您需要选择要使用的卫星。这里需要注意的主要功能有 :
以下是免费提供 data 的卫星:
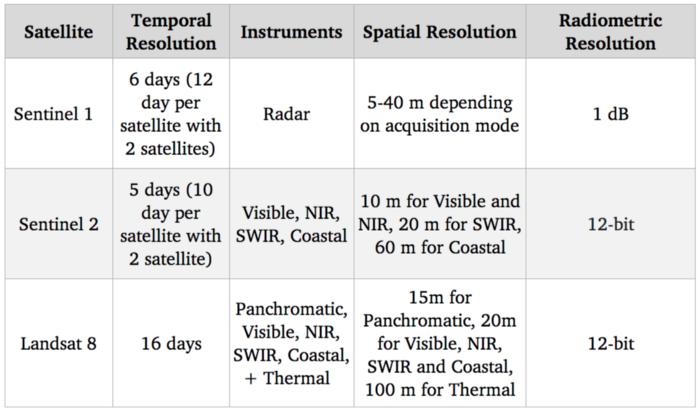
卫星系统的基准
由于我们的目标是检测和识别农作物,因此可见光谱(用于提供标准彩色图像)应该非常有用。此外,农作物的氮含量与 NIR(近红外)光谱波段之间也存在相关性。就免费选项而言,哨兵 2 号目前在这些光谱波段的分辨率方面是最好的,达到了 10 米,因此我们将使用这颗卫星。.
当然,与商业卫星达到 30 厘米的卫星图像分辨率相比,10 米的分辨率要低得多。获取商业卫星 data 可以解锁许多用例,但尽管进入这一市场的新公司竞争日益激烈,它们的价格仍然很高,因此很难集成到规模用例中。.
步骤 2 - 从哨兵 2 号收集卫星图像 data
既然我们已经选择了卫星来源,新的步骤就是下载图像。哨兵 2 号是哥白尼计划的一部分。 欧洲航天局. .我们可以使用 SentinelSat python 应用程序接口.
我们首先需要在 哥白尼开放存取中心. .另外请注意,该网站还提供了使用图形用户界面查询图像的方法。.
向应用程序接口提供 geojson 文件是指定要探索的区域的一种方法,该文件是一个包含区域 GPS 坐标位置(纬度和经度)的 json 文件。可以通过以下方式快速创建 Geojson 文件 网站.
这样,您就可以查询与所提供区域相交的所有卫星图像。.
在此,我们列出了在给定区域和时间范围内的所有可用图像:
api = SentinelAPI(
凭证[“用户名”]、,
凭据[“密码”]、,
“https://scihub.copernicus.eu/dhus”
)
shape = geojson_to_wkt(read_geojson(geojson_path))
图像 = api.query(
形状,
date=(date(2020, 5, 1), date(2020, 5, 10))、,
platformname=”Sentinel-2″、,
处理级别 = “2A级”、,
cloudcoverpercentage=(0, 30)
)
images_df = api.to_dataframe(images)
注意参数的使用:

图像
Images_df 是一个 pandas dataframe,其中包含与我们的查询相匹配的所有图像。我们选择一张 cloud 覆盖率较低的图片,并使用 api .NET 下载:
api.download(uuid)
步骤 3 - 了解使用哪些频谱带并管理量化
下载压缩文件后,我们可以看到它实际上包含了多个图像。.
这是因为正如我们在步骤 1 中所说的,哨兵 2 号捕捉的光谱波段很多,而不仅仅是红绿蓝,而且每个波段都捕捉在一张图像中。.
此外,其仪器的空间分辨率也不尽相同,因此为 10 米、20 米和 60 米的不同分辨率分别设置了一个子文件夹。.
如果我们检查 GRANULE//IMG_DATA 在文件夹中,我们可以看到每个不同分辨率都有一个子文件夹:10、20 和 60 米的光谱波段。我们将使用最大分辨率为 10 米的波段,因为它们提供了蓝光、绿光、红光和近红外波段 2、3、4 和 8。第 7、8 和 9 波段是植被红边(介于红色和近红外之间的光谱波段,标志着植被反射率值的过渡),也可用于探测农作物,但由于它们的分辨率较低,我们现在暂不使用。
在这里,我们将每个频段加载为二维 numpy 矩阵:
def get_band(image_folder, band, resolution=10):
subfolder = [f for f in os.listdir(image_folder + "/GRANULE") if f[0] == "L"][0]
image_folder_path = f"/GRANULE//IMG_DATA/Rm"
image_files = [im for im in os.listdir(image_folder_path) if im[-4:] == ".jp2"] 选择的文件 = [im for im in image_files if im.split("_")[2] == band][0
selected_file = [im for im in image_files if im.split("_")[2] == band][0]
使用 rasterio.open(f"/") 作为 infile:
img = infile.read(1)
返回 img
band_dict =
for band in ["B02", "B03", "B04", "B08"]:
band_dict[band] = get_band(图像文件夹,band,10)
为确保一切正常,我们可以尝试使用 opencv 和 matplotlib 重新创建真彩色图像(即 RGB)并将其显示出来:
img = cv2.merge((band_dict[“B04”], band_dict[“B03”], band_dict[“B02”]))
plt.imshow(img)
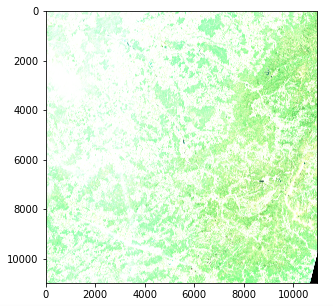
卫星图像 - 色彩强度问题(哥白尼哨兵 data 2020)
不过,在颜色强度方面存在一个问题。这是因为量化(可能值的数量)不同于 matplotlib 的标准,后者假定为 0-255 int 值或 0-1 float 值。标准图像通常使用 8 位量化(256 个可能值),但哨兵 2 号图像使用 12 位量化,并通过重新处理将值转换为 16 位整数(65536 个值)。.
如果我们要将 16 位整数缩放为 8 位整数,理论上应该除以 256,但这实际上会导致图像非常暗,因为没有使用整个可能的数值范围。我们图像中的最大值实际上是 65536 中的 16752,而实际上很少有像素的值超过 4000,因此除以 8 实际上会得到一个对比度不错的图像。
img_processed = img / 8
img_processed = img_processed.astype(int)
plt.imshow(img_processed)
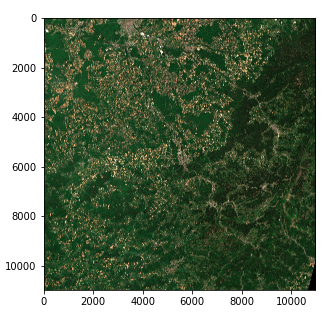
卫星图像 - 右侧颜色强度(哥白尼哨兵 data 2020)
现在,我们有了一个以 numpy 数组形式存在的三维张量,其形状为 (10980, 10980, 3) 的 8 位整数
注意到 :
步骤 4 - 将图像分割成机器学习所需的大小
我们可以尝试将算法应用到当前图像中,但实际上,由于图像的大小,大多数技术都无法做到这一点。即使拥有强大的计算能力,大多数算法(尤其是深度学习)也无法实现。.
因此,我们必须将图像分割成片段。一个问题是如何设置片段的大小。.
我们决定将每幅图像分割成 45 * 45 的网格(45 正好是 10980 的分隔线)。
在完成参数固定后,这一步就可以直接使用 numpy 数组操作了。我们使用 (x, y) 元组作为键,将值存储在一个 dict 中。.
frag_count = 45
frag_size = int(img_processed.shape[0] / frag_count)
frag_dict =
for y, x in itertools.product(range(frag_count), range(frag_count)):
frag_dict[(x, y)] = img_processed[y*frag_size: (y+1)*frag_size、,
x*frag_size: (x+1)*frag_size, :]
plt.imshow(frag_dict[(10, 10)])
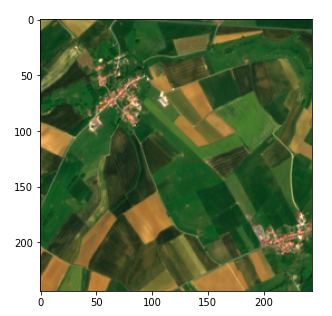
卫星图像片段(哥白尼哨兵 data 2020)
第 5 步 - 使用 GPS 至 UTM 转换将 data 与卫星图像连接起来

最后,我们需要将图像与农田上的 data 相连接,以实现有监督的机器学习方法。在我们的案例中,农田上的 data 是以 GPS 坐标(纬度和经度)列表的形式存在的,与我们在第 2 步中使用的 geojson 类似,我们希望能够找到它们的像素位置。不过,为了清楚起见,我将首先展示像素转换为 GPS 坐标的过程,然后再展示反向过程
在请求 SentinelSat API 时收集的 metadata 提供了图像角落(足迹列)的 GPS 坐标,而我们需要的是特定像素的坐标。纬度和经度是角度值,不会在图像内线性变化,因此我们无法使用像素位置进行简单的比例运算。有一些方法可以用数学公式来解决这个问题,但在 python 中已经存在现成的解决方案。.
一种快速的解决方案是将像素位置转换为 UTM(Universal Transverse Mercator,通用横轴默卡托),在 UTM 中,位置由区域以及(x、y)位置(以米为单位)定义,而后者与图像呈线性变化。因此,我们可以使用 utm 库提供的 UTM 到经度/纬度的转换。为此,我们首先需要获取 UTM 区域和图像左上角的位置,这可以在真彩色图像的 metadata 中找到。.
#Obtaining meatadata
transform = rasterio.open(tci_file_path, driver=’JP2OpenJPEG’).transform
zone_number = int(tci_file_path.split(“/”)[-1][1:3])
zone_letter = tci_file_path.split(“/”)[-1][0]
utm_x, utm_y = transform[2], transform[5]
# 将像素位置转换为 utm
east = utm_x + pixel_column * 10
north = utm_y + pixel_row * - 10
# 将 UTM 转换为经纬度
纬度、经度 = utm.to_latlon(east, north, zone_number, zone_letter)
GPS 定位到像素的转换使用相反的公式完成。在这种情况下,我们必须确保获得的区域与我们的图像相匹配。这可以通过指定区域来实现。如果我们的对象不在图像中,这将导致像素值超出边界。.
# 将经纬度转换为 UTM
east, north, zone_number, zone_letter = utm.from_latlon(
纬度, 经度, force_zone_number=zone_number
)
# 将 UTM 转换为列和行
pixe_column = round((east - utm_x) / 10)
pixel_row = round((north - utm_y) / -10)
查看原始
结论
现在,我们可以将卫星图像用于机器学习了!
在本系列 2 部分的下一篇文章中,我们将了解如何利用这些图像,通过有监督和无监督的机器学习来检测字段表面并对其进行分类。.
感谢您的阅读,请随时 关注 Artefact 技术博客 如果您希望在下一篇文章发布时收到通知 !

