


Introduction
Now the center of gravity is shifting. As AI, especially large language models (LLMs), permeates workflows, performance depends less on what data we have and more on how systems are guided to use it. The critical asset has become context: prompts, instruction sets, playbooks, agent memories, tool‑use guides, and domain heuristics that steer reasoning at inference time. Context is the new master data.
Ungoverned context is already creating context chaos, prompts proliferate, teams rewrite instructions ad hoc, know‑how collapses into generic summaries, and behavior drifts. Recent research points to a remedy. The ACE, Agentic Context Engineering framework, from Stanford and UC Berkeley treats context as a comprehensive, evolving playbook refined through a generation → reflection → curation loop. In reported benchmarks, ACE shows +10.6 percentage points on agent tasks and +8.6 points on domain‑specific financial reasoning, with faster adaptation and gains achieved even from natural execution feedback.
The Limitations of Traditional MDM in the AI Era
MDM solved for data: it centralized and synchronized entity records, enforced schemas and survivorship, reconciled duplicates, and provided lineage and stewardship. AI applications, however, run on context. Context is dynamic and operational. It changes as systems encounter new scenarios, is authored by many hands (humans and models), and its quality is judged by downstream task performance and safety, not by schema conformance.
Three failure modes have become common. Brevity bias assumes short prompts are better; in practice, LLMs often perform better with long, detailed contexts and can select relevance at run time. Context collapse occurs when repeated rewriting compresses rich knowledge into bland summaries; in one ACE case, a context shrank from 18,282 tokens at 66.7% accuracy to 122 tokens at 57.1% in a single rewrite. And unchecked proliferation produces inconsistent behavior, slow adaptation, and compliance exposure. Traditional MDM offers little help here.
Master Context Management (MCM)
What MCM Is
Master Context Management is a disciplined way to govern, version, and continually improve the contexts that drive AI behavior. Instead of treating prompts as disposable snippets, MCM treats them as living playbooks that accumulate institutional knowledge, policies, tactics, edge cases, and tool recipes, and evolve without losing their memory.
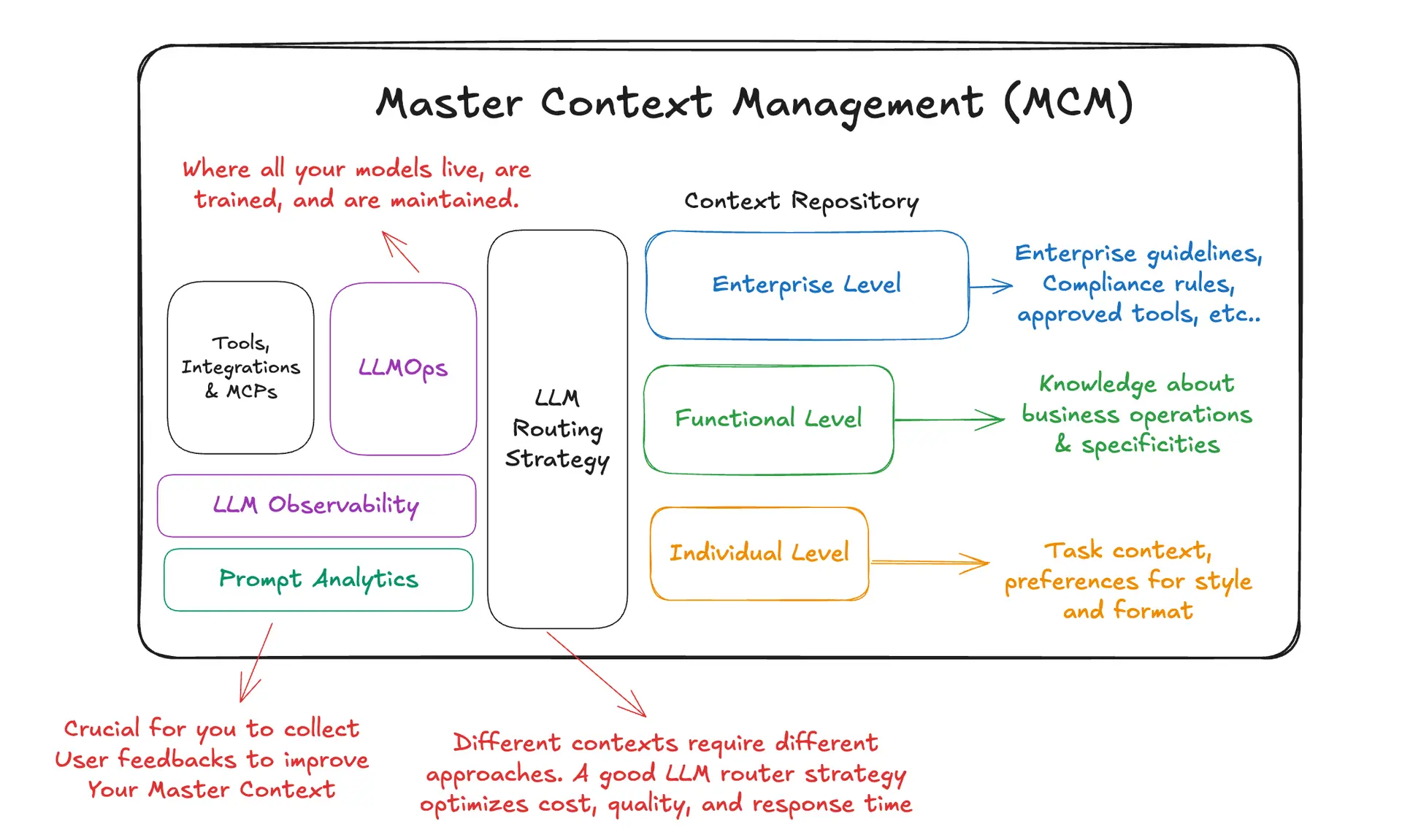
Design Principles
MCM rests on a few habits that keep quality high and drift low. First, favor rich playbooks over compressed summaries; long‑context models and inference optimizations (such as KV‑cache reuse) make this practical. Second, separate roles in the learning loop: a Generator executes tasks and produces trajectories; a Reflector analyzes those traces to extract insights and diagnose failure modes; and a Curator turns insights into narrow, controlled updates. Third, prefer delta editing to big rewrites so improvements are itemized, testable, and reversible. Fourth, learn from execution feedback, success/failure, tool outputs, and user ratings, so contexts improve without labeled data. Finally, practice multi‑epoch refinement by revisiting common queries, strengthening guidance while trimming redundancy.
A Practical Taxonomy
To balance reuse with specificity, MCM organizes context into three layers that interlock naturally. Enterprise context encodes organization‑wide rules, compliance, security posture, and approved tooling. Functional context captures the operating knowledge of a business area, procedures, edge cases, KPIs, and regional nuances. Individual context tailors task setup and preferred style for a specific user or workflow. Together they let teams compose a single, coherent playbook for any request without reinventing the wheel.
Core Capabilities
Context repository and composition. MCM starts with a repository that stores both offline assets (system prompts, instruction templates, policy playbooks, tool guides) and online assets (agent memories, execution traces, reusable conversation segments). Each item carries metadata, owner, domain, risk class, and lineage, and can be assembled on demand into the context an application needs.
Routing and assembly. A lightweight routing layer decides which model to use and how to assemble enterprise, functional, and individual context for a given request. This makes trade‑offs between cost, quality, and latency explicit and repeatable, rather than hidden in ad hoc prompt edits.
Versioning and experimentation. All changes are captured as chains of deltas. Teams can run parallel variants, attach comparative metrics (accuracy, policy adherence, latency, hallucination rate, and business impact), roll out changes gradually, and auto‑revert on regression. Structured updates reduce adaptation latency and lower risk.
The learning workflow. During generation, agents run with current guidance and log plans, tool calls, inputs/outputs, and outcomes. In reflection, those traces are analyzed into concrete guidance, “page through API results before aggregating,” “validate schema before write,” “policy X overrides Y in region Z.” In curation, insights become mergeable entries with IDs and evidence links; duplicates are removed, formatting and guardrails are enforced, and the playbook grows without collapse.
Governance and risk. MCM assigns stewards to major domains, defines approval thresholds for proposed updates, enforces security classifications (PII, regulated, confidential), and maintains full auditability of who changed what, when, and why. The same governance ideas that worked for data—ownership, standards, and escalation paths, translate cleanly to context.
Observability and feedback. Usage analytics reveal where contexts are injected and how they perform. Prompt analytics identify the passages that contribute most to outcomes. Drift detectors watch for sudden size contractions or spikes in “harmful” counters early signs of collapse. User feedback becomes first‑class input to the improvement loop.
Integration and operations. Finally, MCM plugs into day‑to‑day AI operations: models are evaluated and deployed under LLMOps discipline; tools and integrations are exposed as governed capabilities; APIs inject composed contexts into agents and RAG systems; caching and token‑economy features keep costs in line.
A Short Example
Imagine a support copilot that sometimes miscalculates refunds when loyalty tiers change. Generation yields traces from failed cases; reflection surfaces the rule, “if tier changed in last 30 days, re‑price from effective date before refund.” Curation adds a small delta, two sentences and a worked example, tagged to the refund section with a link to the failing trace. The next deployment shows a measurable lift in first‑contact resolution with no broad rewrite and an easy rollback if needed. This is MCM in action: small, provable edits accumulating into robust behavior.
What MCM Prevents
With these practices in place, organizations avoid the common traps: the “prompt‑of‑the‑day” culture, big‑bang rewrites that erase hard‑won knowledge, copy‑paste sprawl across teams, and the inability to explain which guidance produced a given outcome. MCM restores memory, accountability, and repeatability to AI behavior.
The Future: Self‑Improving Context Ecosystems
With MCM, systems can learn from execution and propose updates automatically from natural signals like task success/failure and tool outcomes. ACE demonstrates that this label‑free learning can deliver large gains (for example, +17.1 points on agent tasks), pointing toward resilient systems that improve as they operate. In the 2010s, data moats mattered most; in the 2020s–2030s, context moats, codified know‑how, will differentiate leaders. Expect a revival of knowledge management as operational playbooks become auditable, execution‑validated assets, tighter ties to knowledge graphs for factual grounding, and stronger safety through explicit, reversible behavior. Expanding context windows and inference optimizations are making rich playbooks economical at scale.
Conclusion
MCM doesn’t replace MDM; it extends it to a new asset class. The governance ideas that cleaned up data chaos, stewardship, golden sources, taxonomies, lifecycle, and quality metrics, now apply to contexts, the instructions and heuristics that determine how AI reasons and acts. The ACE framework shows that treating contexts as evolving playbooks and updating them via generation → reflection → curation improves accuracy (+10.6 and +8.6 points), accelerates adaptation, and can self‑improve from execution signals alone. Treat context like master data, prevent collapse with delta‑based curation, leverage your governance foundation, and couple the learning loop with strong observability. Teams that master MCM will enjoy more reliable AI, faster iteration, and durable advantage; those that manage context casually will repeat pre‑MDM sprawl, only with higher risk and cost.
