


Einführung
Jetzt verlagert sich das Schwergewicht. Da KI, insbesondere große Sprachmodelle (LLMs), die Arbeitsabläufe durchdringen, hängt die Leistung weniger davon ab, welche data wir haben, sondern mehr von wie die Systeme zur Nutzung angeleitet werden. Das kritische Gut ist zum Kontext: Prompts, Anweisungssätze, Playbooks, Agentenspeicher, Leitfäden für die Verwendung von Werkzeugen und Domänenheuristiken, die die Schlussfolgerungen während der Inferenzzeit steuern. Context ist der neue Master data.
Ein unregierter Kontext schafft bereits Kontext-Chaos, Aufforderungen häufen sich, Teams schreiben Anweisungen ad hoc um, das Know-how zerfällt in allgemeine Zusammenfassungen und das Verhalten driftet ab. Jüngste Forschungen weisen auf eine Lösung hin. Die ACE, Agentic Context Engineering Framework, aus Stanford und UC Berkeley behandelt den Kontext als eine umfassendes, sich weiterentwickelndes Spielbuch verfeinert durch ein Generierung → Reflexion → Kuratierung Schleife. In gemeldeten Benchmarks zeigt ACE +10,6 Prozentpunkte bei Agentenaufgaben und +8.6 Punkte beim bereichsspezifischen Finanzwissen, mit schnellerer Anpassung und Gewinnen, die sogar durch natürliches Ausführungsfeedback erzielt werden.
Die Grenzen des traditionellen MDM in der KI-Ära
MDM gelöst für data: Es zentralisiert und synchronisiert Entitätsdatensätze, erzwingt Schemata und Überlebensfähigkeit, gleicht Duplikate ab und sorgt für Abstammung und Verwaltung. KI-Anwendungen laufen jedoch auf Kontext. Der Kontext ist dynamisch und operativ. Er verändert sich, wenn Systeme auf neue Szenarien treffen, wird von vielen Händen (Menschen und Modellen) verfasst und seine Qualität wird nach der Leistung und Sicherheit der nachgelagerten Aufgaben beurteilt, nicht nach der Konformität mit dem Schema.
Drei Ausfallarten haben sich durchgesetzt. Prägnanzverzerrung geht davon aus, dass kurze Prompts besser sind; in der Praxis führen LLMs oft besser mit langen, detaillierten Kontexten und können die Relevanz während der Laufzeit auswählen. Kontext zusammenbrechen tritt auf, wenn durch wiederholtes Neuschreiben reichhaltiges Wissen zu faden Zusammenfassungen komprimiert wird; in einem ACE-Fall schrumpfte ein Kontext von 18.282 Token bei 66,7% Genauigkeit zu 122 Token zu 57.1% in einer einzigen Neufassung. Und unkontrollierte Ausbreitung führt zu inkonsistentem Verhalten, langsamer Anpassung und der Gefährdung durch Compliance. Traditionelles MDM bietet hier wenig Hilfe.
Master Context Management (MCM)
Was MCM ist
Master Context Management ist ein disziplinierter Weg zu verwalten, versionieren und kontinuierlich verbessern die Kontexte, die das Verhalten der KI steuern. Anstatt Prompts als Wegwerf-Schnipsel zu behandeln, behandelt MCM sie als Lebendige Spielbücher die institutionelles Wissen, Richtlinien, Taktiken, Grenzfälle und Werkzeugrezepte ansammeln und sich weiterentwickeln, ohne ihr Gedächtnis zu verlieren.
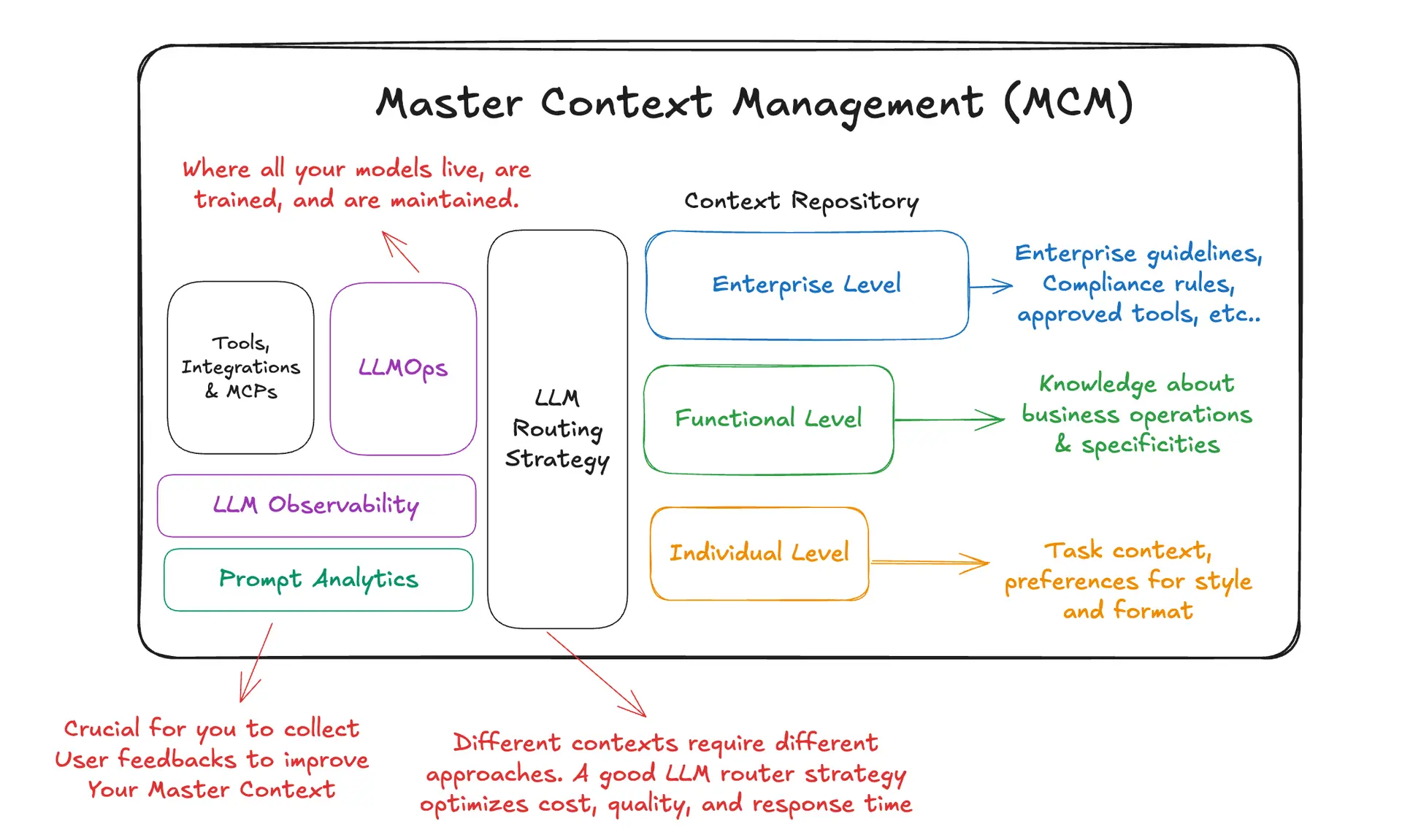
Gestaltungsprinzipien
MCM stützt sich auf einige Gewohnheiten, die die Qualität hoch und die Abwanderung niedrig halten. Erstens: Bevorzugen Sie umfangreiche Spielbücher über komprimierte Zusammenfassungen; Modelle für lange Kontexte und Optimierungen der Schlussfolgerungen (wie die Wiederverwendung des KV-Caches) machen dies praktisch. Zweitens, getrennte Rollen in der Lernschleife: Ein Generator führt Aufgaben aus und erzeugt Trajektorien; ein Reflektor analysiert diese Trajektorien, um Erkenntnisse zu gewinnen und Fehlermodi zu diagnostizieren; und ein Kurator verwandelt Erkenntnisse in enge, kontrollierte Aktualisierungen. Drittens, bevorzugen Delta-Bearbeitung zu großen Umschreibungen, so dass Verbesserungen aufgeschlüsselt, testbar und umkehrbar sind. Viertens, aus dem Feedback zur Ausführung lernen, Erfolg/Misserfolg, Tool-Outputs und Benutzerbewertungen, so dass sich die Kontexte auch ohne die Bezeichnung data verbessern. Schließlich, Praxis Multi-Epochen-Verfeinerung indem wir häufig gestellte Fragen überarbeiten, die Anleitung verbessern und gleichzeitig Redundanzen abbauen.
Eine praktische Taxonomie
Um ein Gleichgewicht zwischen Wiederverwendung und Spezifität herzustellen, gliedert MCM den Kontext in drei Ebenen, die natürlich ineinandergreifen. Unternehmenskontext kodiert unternehmensweite Regeln, Compliance, Sicherheitsstatus und genehmigte Tools. Funktionaler Kontext erfasst das operative Wissen eines Geschäftsbereichs, Verfahren, Randfälle, KPIs und regionale Nuancen. Individueller Kontext passt die Aufgabeneinrichtung und den bevorzugten Stil für einen bestimmten Benutzer oder Arbeitsablauf an. Zusammen ermöglichen sie es Teams, ein einziges, kohärentes Playbook für jede Anfrage zu erstellen, ohne das Rad neu erfinden zu müssen.
Kernkompetenzen
Kontextspeicher und Komposition. MCM beginnt mit einem Repository, das sowohl Offline-Assets (System-Prompts, Anweisungsvorlagen, Policy Playbooks, Tool Guides) als auch Online-Assets (Agentenspeicher, Ausführungsspuren, wiederverwendbare Gesprächsabschnitte) speichert. Jedes Element enthält Metadata, Eigentümer, Domäne, Risikoklasse und Herkunft und kann bei Bedarf zu dem Kontext zusammengestellt werden, den eine Anwendung benötigt.
Routing und Montage. Eine leichtgewichtige Routing-Schicht entscheidet, welches Modell zu verwenden ist und wie der Unternehmens-, Funktions- und individuelle Kontext für eine bestimmte Anfrage zusammengesetzt wird. Dadurch werden Kompromisse zwischen Kosten, Qualität und Latenzzeit explizit und wiederholbar sein, anstatt in Ad-hoc-Eingabeaufforderungen versteckt zu sein.
Versionierung und Experimentieren. Alle Änderungen werden erfasst als Ketten von Deltas. Teams können parallele Varianten ausführen, vergleichende Metriken (Genauigkeit, Richtlinieneinhaltung, Latenz, Halluzinationsrate und geschäftliche Auswirkungen) anhängen, Änderungen schrittweise einführen und bei Regression automatisch zurückkehren. Strukturierte Updates reduzieren die Anpassungslatenz und verringern das Risiko.
Der Lern-Workflow. Während Generation, Die Agenten arbeiten mit aktuellen Anleitungen und protokollieren Pläne, Toolaufrufe, Eingaben/Ausgaben und Ergebnisse. In Reflexion, werden diese Spuren in konkrete Anleitungen umgewandelt: “API-Ergebnisse vor der Aggregation durchblättern”, “Schema vor dem Schreiben validieren”, “Richtlinie X hat Vorrang vor Y in Region Z”. In Kuratieren, Erkenntnisse werden zu zusammenführbaren Einträgen mit IDs und Links zu Beweisen. Duplikate werden entfernt, Formatierungen und Leitplanken werden durchgesetzt, und das Spielbuch wächst, ohne zusammenzubrechen.
Governance und Risiko. MCM weist den wichtigsten Bereichen Verantwortliche zu, definiert Genehmigungsschwellen für vorgeschlagene Aktualisierungen, setzt Sicherheitseinstufungen durch (PII, reguliert, vertraulich) und sorgt für eine vollständige Nachvollziehbarkeit, wer was, wann und warum geändert hat. Die gleichen Governance-Ideen wie bei data - Eigentümerschaft, Standards und Eskalationspfade - lassen sich nahtlos auf den Kontext übertragen.
Beobachtbarkeit und Feedback. Nutzungsanalysen zeigen, wo Kontexte eingefügt werden und wie sie funktionieren. Prompt-Analysen identifizieren die Passagen, die am meisten zu den Ergebnissen beitragen. Drift-Detektoren achten auf plötzliche Verkleinerungen oder Spitzen bei “schädlichen” Zählern - frühe Anzeichen für einen Zusammenbruch. Das Feedback der Benutzer wird zu einem erstklassigen Input für die Verbesserungsschleife.
Integration und Betrieb. Schließlich fügt sich MCM in den alltäglichen KI-Betrieb ein: Modelle werden unter LLMOps-Disziplin evaluiert und eingesetzt; Tools und Integrationen werden als kontrollierte Fähigkeiten offengelegt; APIs injizieren komponierte Kontexte in Agenten und RAG-Systeme; Caching und Token-Economy-Funktionen halten die Kosten im Rahmen.
Ein kurzes Beispiel
Stellen Sie sich einen Support-Copiloten vor, der manchmal Rückerstattungen falsch berechnet, wenn sich die Treuekategorien ändern. Die Generierung liefert Spuren von fehlgeschlagenen Fällen; die Reflexion bringt die Regel zum Vorschein: “Wenn sich die Stufe in den letzten 30 Tagen geändert hat, berechnen Sie vor der Erstattung den Preis ab dem Gültigkeitsdatum neu.” Curation fügt ein kleines Delta hinzu, zwei Sätze und ein praktisches Beispiel, das mit einem Link zum Abschnitt über die Rückerstattung versehen ist. Der nächste Einsatz zeigt eine messbare Verbesserung bei der Lösung des Erstkontakts, ohne dass eine umfassende Neuformulierung erforderlich ist, und ein einfaches Rollback, falls erforderlich. Das ist MCM in Aktion: kleine, nachweisbare Änderungen, die sich zu robustem Verhalten summieren.
Was MCM verhindert
Mit diesen Praktiken vermeiden Unternehmen die üblichen Fallen: die “Prompt-of-the-Day”-Kultur, umfangreiche Neufassungen, die hart erarbeitetes Wissen auslöschen, Copy-Paste-Wildwuchs in den Teams und die Unfähigkeit zu erklären, welche Anleitung zu einem bestimmten Ergebnis geführt hat. MCM stellt wieder her Gedächtnis, Verantwortlichkeit und Wiederholbarkeit zum KI-Verhalten.
Die Zukunft: Selbstverbessernde Kontext-Ökosysteme
Mit MCM können Systeme aus der Ausführung lernen und schlagen automatisch Aktualisierungen anhand von natürlichen Signalen wie Erfolg/Misserfolg der Aufgabe und den Ergebnissen der Werkzeuge vor. ACE zeigt, dass dieses kennzeichnungsfreie Lernen große Vorteile bringen kann (zum Beispiel, +17,1 Punkte auf Agentenaufgaben), was auf widerstandsfähige Systeme hindeutet, die sich im Laufe ihres Betriebs verbessern. In den 2010er Jahren waren die data-Gräben am wichtigsten, in den 2020er-2030er Jahren, Kontext Gräben, kodifiziertes Know-How, wird die Marktführer auszeichnen. Erwarten Sie eine Wiederbelebung des Wissensmanagements, wenn operative Playbooks zu prüfbar, ausführungsgeprüft Assets, engere Verknüpfungen mit Wissensgraphen für eine faktische Grundlage und mehr Sicherheit durch explizites, reversibles Verhalten. Die Erweiterung von Kontextfenstern und die Optimierung von Schlussfolgerungen machen umfangreiche Playbooks in großem Maßstab wirtschaftlich.
Fazit
MCM ersetzt MDM nicht, sondern erweitert es auf eine neue Anlageklasse. Die Governance-Ideen, die das data-Chaos beseitigt haben, nämlich Stewardship, Golden Sources, Taxonomien, Lebenszyklus und Qualitätsmetriken, gelten jetzt auch für Kontexte, die Anweisungen und Heuristiken, die bestimmen, wie KI denkt und handelt. Der ACE-Rahmen zeigt, dass Kontexte als sich entwickelnde Spielbücher behandeln und aktualisieren sie über Generierung → Reflexion → Kuratierung verbessert die Genauigkeit (+10,6 und +8,6 Punkte), beschleunigt die Anpassung und kann sich allein durch Ausführungssignale selbst verbessern. Behandeln Sie Kontext wie Master data, verhindern Sie einen Kollaps mit deltabasierter Kuration, nutzen Sie Ihre Governance-Grundlage und koppeln Sie die Lernschleife mit starker Beobachtbarkeit. Teams, die MCM beherrschen, werden von zuverlässigerer KI, schnellerer Iteration und dauerhaften Vorteilen profitieren. Diejenigen, die den Kontext nachlässig verwalten, werden die Auswüchse aus der Zeit vor MCM wiederholen, nur mit höherem Risiko und höheren Kosten.
