


Introduction
Aujourd'hui, le centre de gravité se déplace. À mesure que l'IA, en particulier les grands modèles de langage (LLM), pénètre les flux de travail, les performances dépendent moins du data dont nous disposons et davantage du comment les systèmes sont guidés pour l'utiliser. L'actif critique est devenu contexteLes outils d'aide à la décision : invites, jeux d'instructions, manuels de jeu, mémoires d'agents, guides d'utilisation des outils et heuristiques du domaine qui orientent le raisonnement au moment de l'inférence. Le contexte est le nouveau maître data.
Un contexte non gouverné crée déjà le chaos contextuel, Les invites prolifèrent, les équipes réécrivent les instructions de manière ad hoc, le savoir-faire se résume à des résumés génériques et les comportements dérivent. Des recherches récentes montrent qu'il existe un remède. Les ACE, cadre d'ingénierie contextuelle agentique, de Stanford et de l'UC Berkeley traite le contexte comme une un cahier des charges complet et évolutif affiné grâce à un génération → réflexion → curation boucle. Dans les tests de référence rapportés, ACE montre +10,6 points de pourcentage sur les tâches des agents et +8,6 points sur le raisonnement financier spécifique au domaine, L'adaptation est plus rapide et les gains sont obtenus même à partir d'un retour d'information sur l'exécution naturelle.
Les limites du MDM traditionnel à l'ère de l'IA
MDM résolu pour dataLes applications d'intelligence artificielle, quant à elles, s'exécutent à l'aide d'un système de gestion de l'information. Les applications d'intelligence artificielle, cependant, fonctionnent sur contexte. Le contexte est dynamique et opérationnel. Il change au fur et à mesure que les systèmes rencontrent de nouveaux scénarios, il est rédigé par de nombreuses personnes (humains et modèles) et sa qualité est jugée en fonction de l'exécution des tâches en aval et de la sécurité, et non en fonction de la conformité au schéma.
Trois modes de défaillance sont devenus courants. Parti pris de concision suppose que les messages courts sont meilleurs ; dans la pratique, les LLM sont souvent plus performants. mieux avec des contextes longs et détaillés et peut sélectionner la pertinence au moment de l'exécution. Effondrement du contexte se produit lorsque la réécriture répétée comprime des connaissances riches en résumés insipides ; dans un cas de CAE, un contexte a été ramené de 18 282 jetons à 66,7% de précision à 122 jetons à 57.1% en une seule réécriture. Et prolifération incontrôlée produit un comportement incohérent, une adaptation lente et une exposition à la conformité. Le MDM traditionnel n'est pas d'un grand secours à cet égard.
Gestion du contexte principal (MCM)
Qu'est-ce que la MCM ?
Maîtriser la gestion du contexte est une manière disciplinée de de régir, de décliner et d'améliorer en permanence les contextes qui déterminent le comportement de l'IA. Au lieu de traiter les invites comme des bribes jetables, MCM les traite comme des livres de jeu vivants qui accumulent des connaissances institutionnelles, des politiques, des tactiques, des cas particuliers et des recettes d'outils, et qui évoluent sans perdre leur mémoire.
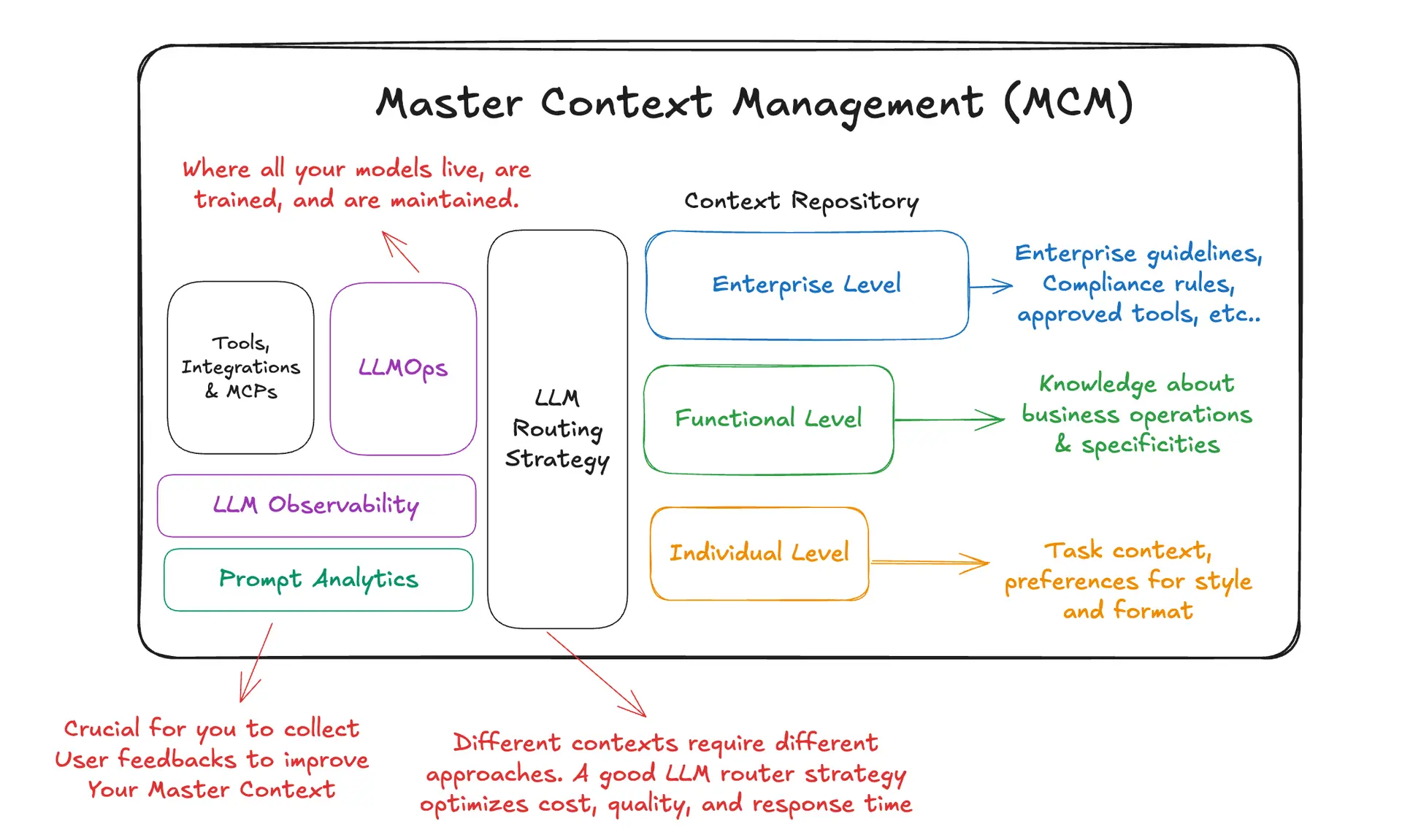
Principes de conception
MCM repose sur quelques habitudes qui permettent de maintenir un niveau de qualité élevé et de limiter les dérives. Tout d'abord, privilégiez des playbooks riches sur des résumés compressés ; les modèles à contexte long et les optimisations de l'inférence (telles que la réutilisation du cache KV) rendent cela pratique. Deuxièmement, des rôles distincts dans la boucle d'apprentissage : un générateur exécute des tâches et produit des trajectoires ; un réflecteur analyse ces traces pour en tirer des enseignements et diagnostiquer les modes d'échec ; et un conservateur transforme les enseignements en des mises à jour étroites et contrôlées. Troisièmement, préférez édition delta aux réécritures importantes afin que les améliorations soient détaillées, testables et réversibles. Quatrièmement, tirer des enseignements du retour d'information sur l'exécution, les succès/échecs, les résultats des outils et les évaluations des utilisateurs, de sorte que les contextes s'améliorent sans être étiquetés data. Enfin, la pratique raffinement multi-époques en réexaminant les questions les plus courantes, en renforçant les conseils tout en éliminant les redondances.
Une taxonomie pratique
Pour concilier réutilisation et spécificité, MCM organise le contexte en trois couches qui s'imbriquent naturellement. Contexte de l'entreprise codifie les règles, la conformité, la posture de sécurité et les outils approuvés à l'échelle de l'organisation. Contexte fonctionnel capture les connaissances opérationnelles d'un domaine d'activité, les procédures, les cas particuliers, les indicateurs clés de performance et les nuances régionales. Contexte individuel adapte la configuration des tâches et le style préféré d'un utilisateur ou d'un flux de travail spécifique. Ensemble, ils permettent aux équipes de composer un cahier des charges unique et cohérent pour n'importe quelle demande, sans réinventer la roue.
Capacités de base
Dépôt et composition du contexte. Le MCM commence par un référentiel qui stocke à la fois les actifs hors ligne (messages-guides du système, modèles d'instruction, manuels de politique, guides d'outils) et les actifs en ligne (mémoires d'agents, traces d'exécution, segments de conversation réutilisables). Chaque élément porte la métadata, le propriétaire, le domaine, la classe de risque et la lignée, et peut être assemblé à la demande dans le contexte dont une application a besoin.
Routage et assemblage. Une couche de routage légère décide du modèle à utiliser et de la manière d'assembler le contexte de l'entreprise, le contexte fonctionnel et le contexte individuel pour une demande donnée. Cela permet de faire des compromis entre le coût, la qualité et la latence explicite et reproductible, plutôt que cachée dans des vérifications ponctuelles.
Version et expérimentation. Toutes les modifications sont saisies en tant que chaînes de deltas. Les équipes peuvent exécuter des variantes en parallèle, attacher des mesures comparatives (précision, respect des règles, latence, taux d'hallucination et impact sur l'entreprise), déployer les changements progressivement et revenir automatiquement en arrière en cas de régression. Les mises à jour structurées réduisent le temps de latence de l'adaptation et diminuent les risques.
Le processus d'apprentissage. Pendant génération, Les agents s'appuient sur les orientations actuelles et enregistrent les plans, les appels d'outils, les entrées/sorties et les résultats. En réflexion, Ces traces sont analysées et transformées en conseils concrets : “consulter les résultats de l'API avant de les agréger”, “valider le schéma avant d'écrire”, “la politique X prévaut sur la politique Y dans la région Z”. En curation, Les idées deviennent des entrées fusionnables avec des identifiants et des liens de preuve ; les doublons sont supprimés, le formatage et les garde-fous sont appliqués, et le cahier de jeu s'enrichit sans s'effondrer.
Gouvernance et risques. Le MCM affecte des responsables aux principaux domaines, définit des seuils d'approbation pour les mises à jour proposées, applique des classifications de sécurité (PII, réglementé, confidentiel) et maintient une auditabilité complète de qui a modifié quoi, quand et pourquoi. Les mêmes idées de gouvernance qui ont fonctionné pour data - propriété, normes et voies d'escalade - s'appliquent parfaitement au contexte.
Observabilité et retour d'information. Les analyses d'utilisation révèlent où les contextes sont injectés et comment ils fonctionnent. L'analyse des messages identifie les passages qui contribuent le plus aux résultats. Les détecteurs de dérive surveillent les contractions de taille soudaines ou les pics dans les compteurs “nuisibles”, signes précurseurs d'un effondrement. Le retour d'information de l'utilisateur devient une entrée de premier ordre dans la boucle d'amélioration.
Intégration et opérations. Enfin, le MCM s'intègre dans les opérations quotidiennes de l'IA : les modèles sont évalués et déployés dans le cadre de la discipline LLMOps ; les outils et les intégrations sont exposés en tant que capacités régies ; les API injectent des contextes composés dans les agents et les systèmes RAG ; les fonctions de mise en cache et d'économie de jetons permettent de maintenir les coûts à un niveau raisonnable.
Un bref exemple
Imaginez un copilote d'assistance qui calcule parfois mal les remboursements lorsque les niveaux de fidélité changent. La génération produit des traces de cas échoués ; la réflexion fait apparaître la règle suivante : “si le niveau a changé au cours des 30 derniers jours, refaire le prix à partir de la date d'entrée en vigueur avant de procéder au remboursement”. La curation ajoute un petit delta, deux phrases et un exemple travaillé, étiqueté dans la section des remboursements avec un lien vers la trace de l'échec. Le déploiement suivant montre une amélioration mesurable de la résolution au premier contact sans réécriture générale et avec un retour en arrière facile si nécessaire. C'est le MCM en action : de petites modifications prouvables s'accumulant en un comportement robuste.
Ce que MCM prévient
Grâce à ces pratiques, les organisations évitent les pièges les plus fréquents : la culture du “prompt du jour”, les réécritures à grande échelle qui effacent les connaissances durement acquises, la prolifération des copier-coller au sein des équipes et l'incapacité d'expliquer quelles orientations ont abouti à un résultat donné. MCM rétablit la mémoire, la responsabilité et la reproductibilité au comportement de l'IA.
L'avenir : Des écosystèmes contextuels qui s'améliorent d'eux-mêmes
Avec la MCM, les systèmes peuvent tirer des enseignements de l'exécution et proposer des mises à jour automatiquement à partir de signaux naturels tels que la réussite ou l'échec d'une tâche et les résultats d'un outil. L'ACE démontre que cet apprentissage sans étiquette peut apporter des gains importants (par exemple, +17,1 points sur les tâches des agents), ce qui laisse présager des systèmes résilients qui s'améliorent au fur et à mesure de leur fonctionnement. Dans les années 2010, les fossés data étaient les plus importants ; dans les années 2020-2030, les douves de contexte, Les leaders se différencieront par leur savoir-faire codifié. Il faut s'attendre à un renouveau de la gestion des connaissances à mesure que les guides opérationnels deviendront des outils de gestion des connaissances. contrôlable, validé par l'exécution des liens plus étroits avec les graphes de connaissances pour une base factuelle, et une sécurité plus forte grâce à un comportement explicite et réversible. L'élargissement des fenêtres contextuelles et l'optimisation de l'inférence rendent les playbooks riches et économiques à l'échelle.
Pour conclure
Le MCM ne remplace pas le MDM, il l'étend à une nouvelle classe d'actifs. Les idées de gouvernance qui ont nettoyé le chaos de data, l'intendance, les sources d'or, les taxonomies, le cycle de vie et les mesures de qualité, s'appliquent maintenant à contextes, Le cadre ACE montre qu'il est possible d'obtenir des informations sur la façon dont l'intelligence artificielle raisonne et agit, grâce à des instructions et des heuristiques. Le cadre ACE montre que traiter les contextes comme des manuels de jeu évolutifs et de les mettre à jour via génération → réflexion → curation améliore la précision (+10,6 et +8,6 points), accélère l'adaptation et peut s'auto-améliorer à partir des seuls signaux d'exécution. Traitez le contexte comme le maître data, évitez l'effondrement avec une curation basée sur le delta, tirez parti de votre fondation de gouvernance et couplez la boucle d'apprentissage avec une forte observabilité. Les équipes qui maîtrisent le MCM bénéficieront d'une IA plus fiable, d'une itération plus rapide et d'un avantage durable ; celles qui gèrent le contexte avec désinvolture répéteront l'étalement antérieur au MCM, mais avec des risques et des coûts plus élevés.
Références
- ACE : Ingénierie contextuelle agentique - arXiv (PDF (EN ANGLAIS))
- Fiche de contrôle dynamique (mémoire adaptative) - arXiv
- Document de référence AppWorld - Anthologie ACL
- Site du projet AppWorld
- Classement AppWorld
- IBM CUGA (agent généraliste d'entreprise) - blog de recherche
- Cadre de reproduction ouvert ACE - GitHub
