


Per-token prices have dropped 75% in a year, but most organizations are spending more on AI, not less. The cost illusion is hiding in plain sight.
The bill that did not shrink
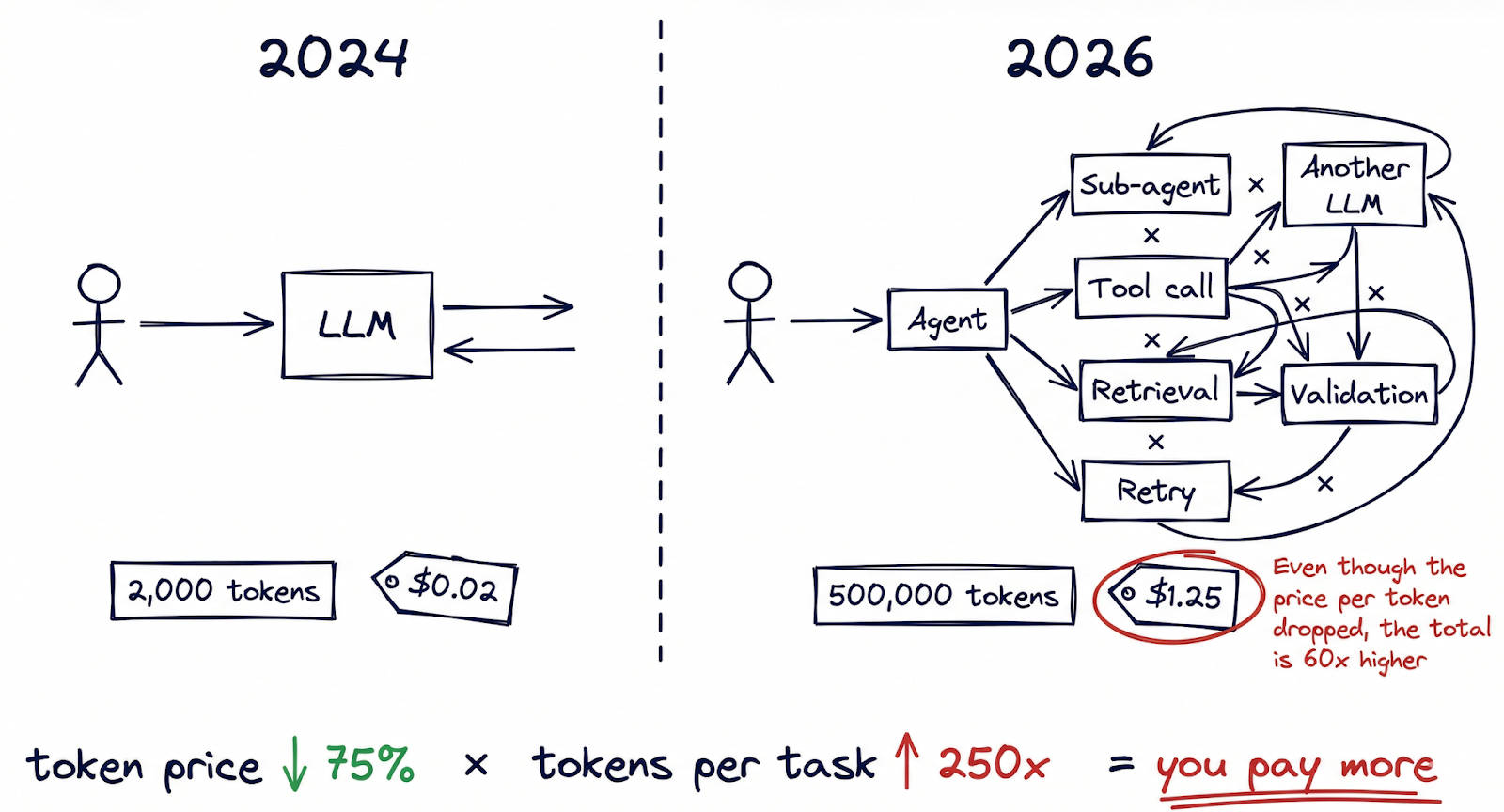
Imagine a CFO reviewing the quarterly cloud spend. The AI team presents a compelling chart: per-token inference costs have dropped 75% year-over-year. The models are faster, the APIs are cheaper, and the vendor is offering volume discounts. Everything points toward savings. Then the actual invoice arrives, and the total is higher than last quarter.
This is not a hypothetical scenario. It is playing out across enterprises right now, and it reveals a gap between the narrative around AI costs and the operational reality. The industry celebrates collapsing token prices as if cheaper inputs automatically mean cheaper outcomes. But in practice, the way organizations consume AI has changed so dramatically that falling unit prices tell only half the story.
The question worth examining is not whether tokens are getting cheaper. They are. The more revealing question is whether that cheapness is translating into lower AI bills, or whether it is quietly enabling consumption patterns that push total costs in the opposite direction.
The price drop is real
To be clear: the decline in per-token pricing is genuine and significant. According to Ramp’s enterprise spending data, the average cost per million tokens across major providers fell from roughly $10 to $2.50 in a single year. Epoch AI’s research suggests that inference costs are dropping at rates approaching 200x per year when accounting for both pricing and efficiency improvements. Andreessen Horowitz has coined the term “LLMflation” to describe this deflationary curve, drawing a parallel to Moore’s Law in semiconductors.
The drivers are well understood. Competition among frontier model providers (OpenAI, Anthropic, Google, Meta) has created aggressive pricing pressure. Open-weight models like Llama and Mistral have established a price floor that proprietary providers cannot ignore. Hardware improvements, including NVIDIA’s Blackwell architecture and custom silicon from Google (TPU v6) and Amazon (Trainium), have steadily improved inference throughput per dollar. Quantization, speculative decoding, and distillation techniques have further reduced the compute required per token.
For simple, bounded use cases (a chatbot answering FAQs, a summarization tool processing documents), this price decline is delivering real savings. Organizations that locked in their AI usage patterns early are, in many cases, genuinely spending less.
The trouble begins when usage patterns do not stay locked in.
The consumption explosion
Here is the part of the equation that rarely makes the headlines: the number of tokens consumed per task has grown by orders of magnitude, and it is accelerating.
A year ago, a typical AI interaction might have involved a single prompt and response, perhaps 2,000 tokens in total. Today, agentic AI workflows have fundamentally changed that arithmetic. A single task executed by a multi-agent system (researching a topic, drafting a document, validating it against internal policies, then iterating based on feedback) can burn through 50,000 to 500,000 tokens before producing a final output. Always-on coding assistants routinely process millions of tokens per developer per day. Multi-agent orchestration frameworks like OpenClaw enable workflows where agents call other agents, each interaction compounding the token count.
The evidence of this shift is visible in the data. TechCrunch reported on a phenomenon it called “tokenmaxxing”, describing power users on flat-rate AI subscription plans who were consuming extraordinary amounts of compute. Some of these “inference whales” generated over $35,000 in compute costs while paying $200 per month. At that ratio, the provider is absorbing a 175x subsidy on their heaviest users.
The financial impact is already showing up in earnings reports. Notion disclosed a 10-percentage-point decline in gross margins linked directly to the cost of embedding AI features across its product. OpsLyft’s analysis of enterprise AI deployments found that hidden costs (retrieval augmentation, embedding generation, context window management, retry logic) routinely added 40-60% on top of the raw inference bill that most teams were tracking.
The mental model most organizations use for AI costs is anchored to a per-query world. But we have moved into a per-workflow world, where a single user action can trigger dozens of inference calls across multiple models. Cheaper tokens multiplied by dramatically more tokens per task do not always equal lower spend.
Big tech is recalibrating
If the consumption problem were merely an enterprise budgeting challenge, it might be manageable. But there are signs that even the largest technology companies are recognizing the limits of subsidized AI usage.
Google’s recent restructuring of its AI subscription model is instructive. The company introduced a tiered system: AI Pro at $19.99 per month and AI Ultra at $249.99 per month, with a new AI Credits mechanism that meters usage rather than offering unlimited access. The shift from “all you can eat” to metered consumption is a significant signal. It suggests that even a company with Google’s infrastructure and margins cannot sustain unlimited token consumption at flat-rate pricing across hundreds of millions of users.
The capital expenditure numbers reinforce this reading. Alphabet projected $75 billion in capex for 2025, and that figure is now expected to reach $175 to $185 billion in 2026, nearly doubling in a single year. Most of that increase is directed at AI infrastructure: data centers, custom chips, and networking capacity to handle inference demand. Microsoft, Amazon, and Meta are each making commitments of similar scale.
These are not the spending patterns of companies that have solved the AI economics equation. They are the spending patterns of companies racing to build capacity for a demand curve they can see coming, but cannot yet profitably serve. The subsidy model (offering generous AI capabilities at consumer-friendly prices to drive adoption) has been effective at building user bases. The question is how long it can continue before pricing must reflect actual compute costs.
The pattern here echoes the early days of cloud computing, when providers offered aggressively low pricing to capture market share, then gradually introduced reserved instances, tiered pricing, and consumption-based billing as usage matured. The AI pricing cycle appears to be compressing that same evolution into a much shorter timeframe.
The on-prem renaissance
For organizations watching these dynamics unfold, a familiar alternative is gaining renewed attention: running AI infrastructure locally.
NVIDIA’s announcement of NemoClaw at GTC in March 2026 is worth paying attention to. NemoClaw extends OpenClaw (the open-source agentic AI framework that has rapidly become the standard for building multi-agent systems) with enterprise-grade features: security controls, privacy routing, audit logging, and native support for NVIDIA’s own Nemotron family of models running on local hardware. It is, in effect, an enterprise distribution of the agentic AI stack, designed to run on-premises or in private cloud environments.
Jensen Huang framed the significance directly: “What is your OpenClaw strategy?” is now a boardroom question, he told the GTC audience. The implication is that AI agent infrastructure is becoming as foundational to enterprise technology strategy as cloud infrastructure was a decade ago, and that organizations need a deliberate position on where and how they run it.
The appeal of on-premise AI goes beyond cost predictability, though that matters. It addresses data sovereignty (sensitive data never leaves the organization’s network), regulatory compliance (particularly relevant as the EU AI Act’s operational provisions take effect), and token governance (the ability to monitor, meter, and control exactly how much inference is being consumed, by whom, and for what purpose). In a world where a single runaway agentic workflow can burn through thousands of dollars in tokens overnight, having infrastructure-level controls is not a luxury.
This does not mean every organization should rush to buy GPU clusters. The capital requirements are substantial, the operational complexity is real, and the pace of model improvement means that today’s on-prem hardware may be suboptimal within eighteen months. But for organizations with significant inference volumes, regulatory constraints, or data sensitivity requirements, the economics of ownership are becoming increasingly competitive with cloud API pricing.
The democratization paradox
There is a deeper tension beneath the cost dynamics that is worth naming: the very forces making AI more accessible are also making its economics less sustainable at scale.
OpenClaw is perhaps the clearest illustration. As an open-source framework for building agentic AI systems, it has dramatically lowered the barrier to creating sophisticated multi-agent workflows. A small team can now build an AI-powered product that would have required a dedicated infrastructure team two years ago. That is a real shift, and the ecosystem it has created positions it as something close to an operating system for personal and enterprise AI.
But democratization has a cost curve of its own, and it is one that I think the industry has been slow to acknowledge. When it becomes trivially easy to spin up agents, organizations tend to spin up many of them. Each agent consumes tokens. Each multi-agent interaction multiplies consumption. The compound effect is that the same accessibility that makes AI powerful also makes AI expensive, not because any individual call is costly, but because the total volume of calls scales faster than anyone budgeted for.
This is the token cost illusion in its purest form: the unit price of intelligence is falling, but the units consumed per outcome are rising even faster.
The enterprise fork in the road
These forces are pulling in the same direction: rising consumption, recalibrating subsidies, maturing on-prem options, and growing regulatory pressure. Together, they are pushing enterprises toward a strategic choice that will shape their AI economics for years to come. Three broad paths are emerging.
Path A: On-Premise Sovereignty. Build or lease dedicated AI infrastructure for cost control, data sovereignty, and regulatory compliance. NemoClaw and similar enterprise distributions make this increasingly viable. Best suited for organizations with high inference volumes, sensitive data, or operations in regulated industries. The tradeoff is capital intensity and operational complexity.
Path B: Neo-Cloud Specialization. A new category of cloud providers is emerging, focused specifically on AI compute rather than general-purpose cloud services. These providers (CoreWeave, Lambda, Together AI, and others) offer GPU-optimized infrastructure with pricing models designed for inference-heavy workloads. They represent a middle path: cloud flexibility without full dependence on the hyperscaler pricing model.
Path C: Hyperscaler Dependency. Continue building on the major cloud providers’ AI services, accepting their pricing evolution in exchange for integration depth, ecosystem breadth, and operational simplicity. This path is the easiest to start, but carries the most exposure to pricing changes as subsidies unwind.
In practice, most large organizations will pursue a hybrid approach, mixing elements of all three based on workload sensitivity, regulatory requirements, and cost profiles. The critical point is that this is becoming a deliberate strategic decision rather than a default one. With rising geopolitical tensions, data localization requirements, and regulatory frameworks like the EU AI Act all pulling in the same direction, the question of where your AI inference runs is no longer purely a technology decision. It is a governance decision.
Managing AI economics responsibly
We are approaching a pivot point in the AI cost conversation. For the past two years, the dominant narrative has been one of relentless deflation: models getting cheaper, inference getting faster, barriers getting lower. That narrative is not wrong, but it is incomplete. It describes the price of a single token without accounting for how many tokens an organization actually consumes, or how quickly that number is growing.
The emerging discipline might be called token governance: the organizational capability to monitor, forecast, and manage AI inference costs with the same rigor that enterprises apply to cloud spend, headcount, or capital allocation. This includes cost observability (knowing in real time what each workflow, agent, and team is consuming), consumption policies (setting boundaries on agentic workflows to prevent runaway token burn), and infrastructure strategy (making deliberate choices about where inference runs and at what cost).
The organizations that manage this transition well will not necessarily be the ones spending the least on AI. They will be the ones who understand, with precision, what they are spending and why. In a world where intelligence is becoming a utility, managing its economics thoughtfully may prove to be as important as harnessing its capabilities.
