


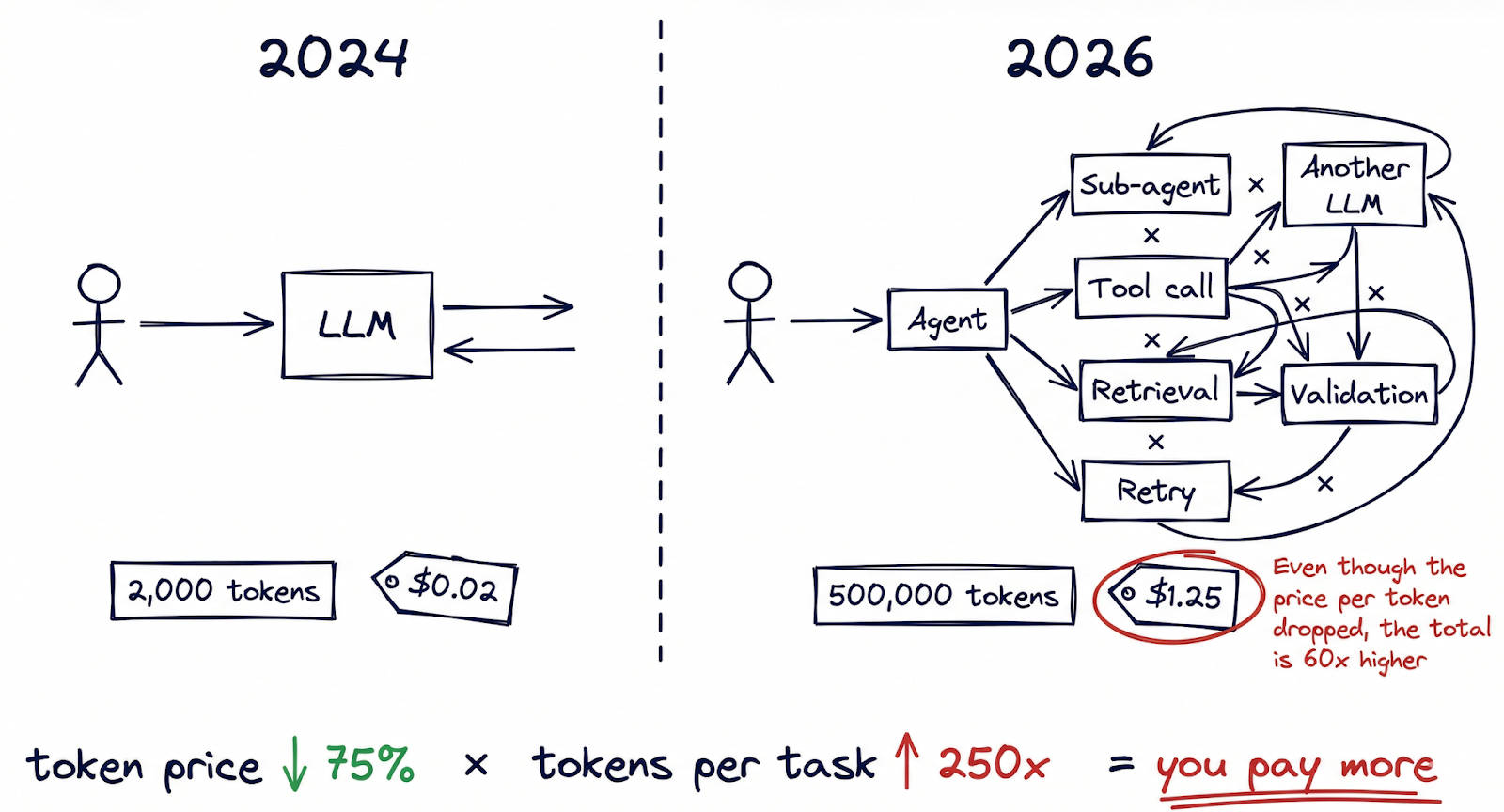
De prijzen per token zijn in een jaar 75% gedaald, maar de meeste organisaties geven meer uit aan AI, niet minder. De kostenillusie verbergt zich in het volle zicht.
Het wetsvoorstel dat niet kromp
Stelt u zich een CFO voor die de driemaandelijkse cloud uitgaven bekijkt. Het AI team presenteert een overtuigende grafiek: de inferentiekosten per token zijn 75% jaar-op-jaar gedaald. De modellen zijn sneller, de API's zijn goedkoper en de leverancier biedt volumekortingen aan. Alles wijst in de richting van besparingen. Dan komt de echte factuur, en het totaal is hoger dan vorig kwartaal.
Dit is geen hypothetisch scenario. Het speelt zich op dit moment af in bedrijven, en het onthult een kloof tussen het verhaal over AI-kosten en de operationele realiteit. De industrie viert het instorten van tokenprijzen alsof goedkopere input automatisch goedkopere resultaten betekent. Maar in de praktijk is de manier waarop organisaties AI gebruiken zo drastisch veranderd dat dalende eenheidsprijzen maar de helft van het verhaal vertellen.
De vraag die onderzocht moet worden is niet of tokens goedkoper worden. Dat zijn ze. De meer onthullende vraag is of die goedkoopheid zich vertaalt in lagere AI-rekeningen, of dat het stilletjes consumptiepatronen mogelijk maakt die de totale kosten in de tegenovergestelde richting duwen.
De prijsdaling is echt
Om duidelijk te zijn: de prijsdaling per token is echt en aanzienlijk. Volgens Ramp's bedrijfsuitgaven data zijn de gemiddelde kosten per miljoen tokens bij de grote aanbieders in één jaar tijd gedaald van ruwweg $10 naar $2,50. Het onderzoek van Epoch AI suggereert dat de inferentiekosten met bijna 200x per jaar dalen als rekening wordt gehouden met zowel prijs- als efficiëntieverbeteringen. Andreessen Horowitz heeft de term “LLMflatie” om deze deflatiecurve te beschrijven, waarbij een parallel wordt getrokken met de Wet van Moore in halfgeleiders.
De drijfveren zijn welbekend. De concurrentie tussen aanbieders van grensverleggende modellen (OpenAI, Anthropic, Google, Meta) heeft een agressieve prijsdruk gecreëerd. Open-gewicht modellen zoals Llama en Mistral hebben een bodem onder de prijs gelegd die propriëtaire aanbieders niet kunnen negeren. Hardwareverbeteringen, waaronder NVIDIA's Blackwell-architectuur en silicium op maat van Google (TPU v6) en Amazon (Trainium), hebben de inferentiedoorvoer per dollar gestaag verbeterd. Kwantisering, speculatieve decodering en distillatietechnieken hebben de benodigde rekenkracht per token verder verlaagd.
Voor eenvoudige, afgebakende use cases (een chatbot die FAQ's beantwoordt, een samenvattingshulpmiddel dat documenten verwerkt) levert deze prijsdaling echte besparingen op. Organisaties die hun AI-gebruikspatronen vroeg hebben vastgelegd, geven in veel gevallen echt minder uit.
Het probleem begint wanneer gebruikspatronen niet vast blijven zitten.
De consumptie-explosie
Dit is het deel van de vergelijking dat zelden de krantenkoppen haalt: het aantal tokens dat per taak wordt verbruikt is met ordes van grootte gegroeid, en het gaat steeds sneller.
Een jaar geleden bestond een typische AI-interactie misschien uit één vraag en antwoord, misschien in totaal 2.000 tokens. Vandaag de dag, agentgerichte AI-workflows hebben die rekensom fundamenteel veranderd. Eén enkele taak die door een multi-agent systeem wordt uitgevoerd (een onderwerp onderzoeken, een document opstellen, het valideren aan de hand van intern beleid, en dan itereren op basis van feedback) kan 50.000 tot 500.000 tokens verwerken voordat er een eindproduct wordt geproduceerd. Altijd-aan codeerassistenten verwerken routinematig miljoenen tokens per ontwikkelaar per dag. Multi-agent orkestratie frameworks zoals OpenClaw maken workflows mogelijk waarbij agents andere agents aanroepen, waarbij elke interactie het aantal tokens vergroot.
Het bewijs van deze verschuiving is zichtbaar in de data. TechCrunch rapporteerde over een fenomeen dat het “tokenmaxxing”, waarin krachtige gebruikers met AI-abonnementen tegen een vast tarief werden beschreven die buitengewoon veel rekenkracht verbruikten. Sommige van deze “gevolgtrekking walvissen” genereerde meer dan $35.000 aan rekenkosten terwijl ze $200 per maand betaalden. Met die verhouding absorbeert de provider een subsidie van 175x op hun zwaarste gebruikers.
De financiële gevolgen zijn al zichtbaar in de winst reports. Notion onthulde een daling van 10 procentpunten in brutomarges die rechtstreeks verband houdt met de kosten voor het inbouwen van AI-functies in haar product. Uit OpsLyft's analyse van Enterprise AI implementaties bleek dat verborgen kosten (retrieval augmentation, embedding generation, context window management, retry logic) routinematig 40-60% bovenop de ruwe inferentierekening kwamen die de meeste teams bijhielden.
Het mentale model dat de meeste organisaties gebruiken voor AI-kosten is verankerd in een per-query wereld. Maar we zijn overgestapt op een per-workflow wereld, waarin één enkele gebruikersactie tientallen inferentieaanroepen kan triggeren in meerdere modellen. Goedkopere tokens vermenigvuldigd met veel meer tokens per taak betekenen niet altijd lagere uitgaven.
Big tech is zich aan het herijken
Als het verbruiksprobleem slechts een budgetteringsuitdaging van de onderneming zou zijn, zou het misschien beheersbaar zijn. Maar er zijn tekenen dat zelfs de grootste technologiebedrijven de grenzen van gesubsidieerd AI-gebruik inzien.
De recente herstructurering van Google's AI-abonnementsmodel is leerzaam. Het bedrijf introduceerde een trapsgewijs systeem: AI Pro voor $19,99 per maand en AI Ultra voor $249,99 per maand, met een nieuwe AI Kredieten mechanisme dat het gebruik meet in plaats van onbeperkte toegang te bieden. De verschuiving van “all you can eat” naar gemeten verbruik is een belangrijk signaal. Het suggereert dat zelfs een bedrijf met de infrastructuur en marges van Google het onbeperkte gebruik van tokens niet kan volhouden tegen vaste prijzen voor honderden miljoenen gebruikers.
De cijfers voor kapitaaluitgaven versterken deze lezing. Alphabet voorspelde $75 miljard aan investeringen voor 2025, en er wordt nu verwacht dat dat cijfer zal oplopen tot $175 tot $185 miljard in 2026, bijna een verdubbeling in één jaar. Het grootste deel van die stijging gaat naar AI-infrastructuur: data centra, aangepaste chips en netwerkcapaciteit om de inferentievraag aan te kunnen. Microsoft, Amazon en Meta doen elk toezeggingen op vergelijkbare schaal.
Dit zijn niet de uitgavenpatronen van bedrijven die de AI-economische vergelijking hebben opgelost. Het zijn de uitgavenpatronen van bedrijven die in een race zijn om capaciteit op te bouwen voor een vraagcurve die ze wel zien aankomen, maar nog niet winstgevend kunnen bedienen. Het subsidiemodel (het aanbieden van royale AI-mogelijkheden tegen consumentvriendelijke prijzen om het gebruik te stimuleren) is effectief geweest bij het opbouwen van een gebruikersbasis. De vraag is hoe lang dit kan doorgaan voordat de prijzen de werkelijke computerkosten moeten weerspiegelen.
Het patroon hier doet denken aan de begindagen van cloud computing, toen providers agressief lage prijzen aanboden om marktaandeel te veroveren, en vervolgens geleidelijk gereserveerde instanties, gedifferentieerde prijzen en op verbruik gebaseerde facturering introduceerden naarmate het gebruik volwassener werd. De AI-prijscyclus lijkt diezelfde evolutie in een veel korter tijdsbestek te comprimeren.
De on-prem renaissance
Organisaties die deze dynamiek zien ontstaan, krijgen steeds meer aandacht voor een bekend alternatief: het lokaal uitvoeren van AI-infrastructuur.
NVIDIA's aankondiging van NemoClaw op de GTC in maart 2026 is de moeite waard om aandacht aan te besteden. NemoClaw breidt OpenClaw (het open-source agentic AI-framework dat snel de standaard is geworden voor het bouwen van multi-agent systemen) uit met enterprise-grade functies: beveiligingscontroles, privacy routing, audit logging, en native ondersteuning voor NVIDIA's eigen Nemotron familie van modellen die op lokale hardware draaien. Het is in feite een bedrijfsdistributie van de agentic AI stack, ontworpen om on-premises of in privé cloud omgevingen te draaien.
Jensen Huang verwoordde het belang direct: “Wat is uw OpenClaw-strategie?” is nu een vraag in de directiekamer, vertelde hij de GTC audience. De implicatie is dat AI-agent infrastructuur net zo belangrijk wordt voor de technologiestrategie van bedrijven als cloud infrastructuur tien jaar geleden was, en dat organisaties een weloverwogen standpunt moeten innemen over waar en hoe ze het gebruiken.
De aantrekkingskracht van on-premise AI gaat verder dan voorspelbaarheid van kosten, hoewel dat wel belangrijk is. Het richt zich op data soevereiniteit (de gevoelige data verlaat nooit het netwerk van de organisatie), regelnaleving (met name relevant nu de operationele bepalingen van de AI-wet van de EU van kracht worden), en bestuur van token (de mogelijkheid om precies te controleren, meten en beheersen hoeveel inferentie verbruikt wordt, door wie, en voor welk doel). In een wereld waarin één op hol geslagen agentworkflow in één nacht duizenden dollars aan tokens kan opbranden, is controle op infrastructuurniveau geen overbodige luxe.
Dit betekent niet dat elke organisatie zich moet haasten om GPU-clusters aan te schaffen. De kapitaalvereisten zijn aanzienlijk, de operationele complexiteit is reëel en het tempo van modelverbetering betekent dat de huidige on-prem hardware binnen achttien maanden suboptimaal kan zijn. Maar voor organisaties met aanzienlijke inferentievolumes, wettelijke beperkingen of data gevoeligheidsvereisten worden de kosten van eigendom steeds concurrerender met cloud API-prijzen.
De democratiseringsparadox
Er zit een diepere spanning onder de kostendynamiek die de moeite waard is om te benoemen: de krachten die AI toegankelijker maken, maken de economische aspecten ervan ook minder duurzaam op schaal.
OpenClaw is misschien wel de duidelijkste illustratie. Als open-source raamwerk voor het bouwen van agentic AI-systemen heeft het de drempel voor het maken van geavanceerde multi-agent workflows drastisch verlaagd. Een klein team kan nu een AI-aangedreven product bouwen waarvoor twee jaar geleden een speciaal infrastructuurteam nodig zou zijn geweest. Dat is een echte verschuiving, en het ecosysteem dat het heeft gecreëerd positioneert het als een besturingssysteem voor persoonlijke en bedrijfs-AI.
Maar democratisering heeft zijn eigen kostencurve, en ik denk dat de sector die maar langzaam onderkent. Wanneer het triviaal eenvoudig wordt om agenten op te zetten, hebben organisaties de neiging om er veel van op te zetten. Elke agent verbruikt tokens. Elke interactie met meerdere agenten vermenigvuldigt het verbruik. Het samengestelde effect is dat dezelfde toegankelijkheid die AI krachtig maakt, AI ook duur maakt, niet omdat elke individuele oproep duur is, maar omdat het totale volume van oproepen sneller toeneemt dan iemand had begroot.
Dit is de token kosten illusie in zijn zuiverste vorm: de eenheidsprijs van intelligentie daalt, maar de verbruikte eenheden per uitkomst stijgen nog sneller.
De tweesprong in de onderneming
Deze krachten trekken in dezelfde richting: stijgende consumptie, herijkende subsidies, rijpende on-prem opties en toenemende regeldruk. Samen duwen ze ondernemingen naar een strategische keuze die hun AI-economie voor de komende jaren zal bepalen. Er ontstaan drie brede paden.
Traject A: On-Premise Soevereiniteit. Bouw of lease een speciale AI-infrastructuur voor kostenbeheersing, data soevereiniteit en naleving van de regelgeving. NemoClaw en vergelijkbare bedrijfsdistributies maken dit steeds haalbaarder. Het meest geschikt voor organisaties met grote inferentievolumes, gevoelige data of activiteiten in gereguleerde sectoren. De afweging is kapitaalintensiviteit en operationele complexiteit.
Traject B: Neo-Cloud Specialisatie. Er is een nieuwe categorie van cloud aanbieders in opkomst, die zich specifiek richt op AI compute in plaats van algemene cloud diensten. Deze aanbieders (CoreWeave, Lambda, Together AI, en anderen) bieden GPU-geoptimaliseerde infrastructuur met prijsmodellen die ontworpen zijn voor inferentiezware werklasten. Zij vertegenwoordigen een middenweg: cloud flexibiliteit zonder volledige afhankelijkheid van het prijsmodel van de hyperscaler.
Pad C: Hyperscaler Afhankelijkheid. Blijven voortbouwen op de AI-diensten van de grote cloud providers en hun prijsevolutie accepteren in ruil voor integratiediepte, breedte van het ecosysteem en operationele eenvoud. Dit pad is het gemakkelijkst om mee te beginnen, maar brengt de meeste blootstelling met zich mee aan prijsveranderingen naarmate subsidies afnemen.
In de praktijk zullen de meeste grote organisaties voor een hybride aanpak kiezen, waarbij elementen van alle drie worden gemengd op basis van de gevoeligheid van de werklast, wettelijke vereisten en kostenprofielen. Het kritieke punt is dat dit een weloverwogen strategische beslissing wordt in plaats van een standaard beslissing. Met de toenemende geopolitieke spanningen, data lokalisatievereisten en regelgevende kaders zoals de EU AI Act die allemaal in dezelfde richting trekken, is de vraag waar uw AI-inferentie wordt uitgevoerd niet langer puur een technologische beslissing. Het is een bestuurlijke beslissing.
AI-economie verantwoord beheren
We naderen een kantelpunt in het gesprek over AI-kosten. De afgelopen twee jaar was het overheersende verhaal er een van voortdurende deflatie: modellen worden goedkoper, inferentie wordt sneller, drempels worden lager. Dat verhaal is niet verkeerd, maar het is wel onvolledig. Het beschrijft de prijs van een enkel token zonder rekening te houden met hoeveel tokens een organisatie eigenlijk verbruikt, of hoe snel dat aantal groeit.
De opkomende discipline zou bestuur van tokenDe organisatiecapaciteit om de kosten van AI-inferenties te bewaken, voorspellen en beheren met dezelfde nauwkeurigheid die bedrijven toepassen op cloud-uitgaven, personeelsaantallen of kapitaalallocatie. Dit omvat de waarneembaarheid van kosten (in realtime weten wat elke workflow, agent en team verbruikt), verbruiksbeleid (grenzen stellen aan agentworkflows om te voorkomen dat token burn op hol slaat) en infrastructuurstrategie (weloverwogen keuzes maken over waar inferentie wordt uitgevoerd en tegen welke kosten).
De organisaties die deze overgang goed managen, zullen niet noodzakelijkerwijs degenen zijn die het minste uitgeven aan AI. Zij zullen degenen zijn die precies begrijpen wat ze uitgeven en waarom. In een wereld waarin intelligentie een gebruiksvoorwerp wordt, kan het doordacht beheren van de economische aspecten ervan net zo belangrijk blijken te zijn als het benutten van de mogelijkheden ervan.
