


每枚令牌的价格在一年内下降了 75%,但大多数企业在人工智能上的支出却有增无减。成本假象隐藏在众目睽睽之下。.
没有缩水的法案
想象一下,一位首席财务官正在审查季度 cloud 支出。AI 团队展示了一张引人注目的图表:每个令牌的推理成本同比下降了 75%。模型更快,API 更便宜,供应商还提供批量折扣。一切都指向节省成本。然后,实际发票到了,总额比上一季度还高。.
这不是一种假设。它揭示了有关人工智能成本的说法与运营现实之间的差距。整个行业都在庆祝代币价格的崩溃,似乎更便宜的投入自动意味着更便宜的结果。但实际上,企业消费人工智能的方式已经发生了巨大变化,单价下降只能说明问题的一半。.
值得研究的问题不是代币是否越来越便宜。它们确实在变便宜。更能说明问题的是,这种便宜是否转化为人工智能账单的降低,还是悄无声息地促成了将总成本推向相反方向的消费模式。.
价格下降是真实的
需要明确的是:单位代币定价的下降是真实而显著的。根据 Ramp 的企业支出 data,主要供应商每百万代币的平均成本在一年内从大约 $10 降至 $2.50。Epoch AI 的研究表明,如果考虑到定价和效率的提高,推理成本每年的下降速度接近 200 倍。安德森-霍洛维茨(Andreessen Horowitz)创造了一个术语“LLMflation”来描述这种通货紧缩曲线,与半导体的摩尔定律相类似。.
驱动因素众所周知。前沿模型提供商(OpenAI、Anthropic、谷歌、Meta)之间的竞争造成了巨大的定价压力。Llama 和 Mistral 等开放式重量模型已经确立了价格底线,专有模型提供商无法忽视。包括英伟达(NVIDIA)的 Blackwell 架构以及谷歌(TPU v6)和亚马逊(Trainium)的定制芯片在内的硬件改进稳步提高了每美元的推理吞吐量。量化、推测解码和蒸馏技术进一步降低了每个令牌所需的计算量。.
对于简单、有限制的用例(回答常见问题的聊天机器人、处理文档的摘要工具)来说,价格下降带来了真正的节省。及早锁定人工智能使用模式的企业,在很多情况下都真正减少了开支。.
当使用模式无法保持锁定时,麻烦就来了。.
消费爆炸
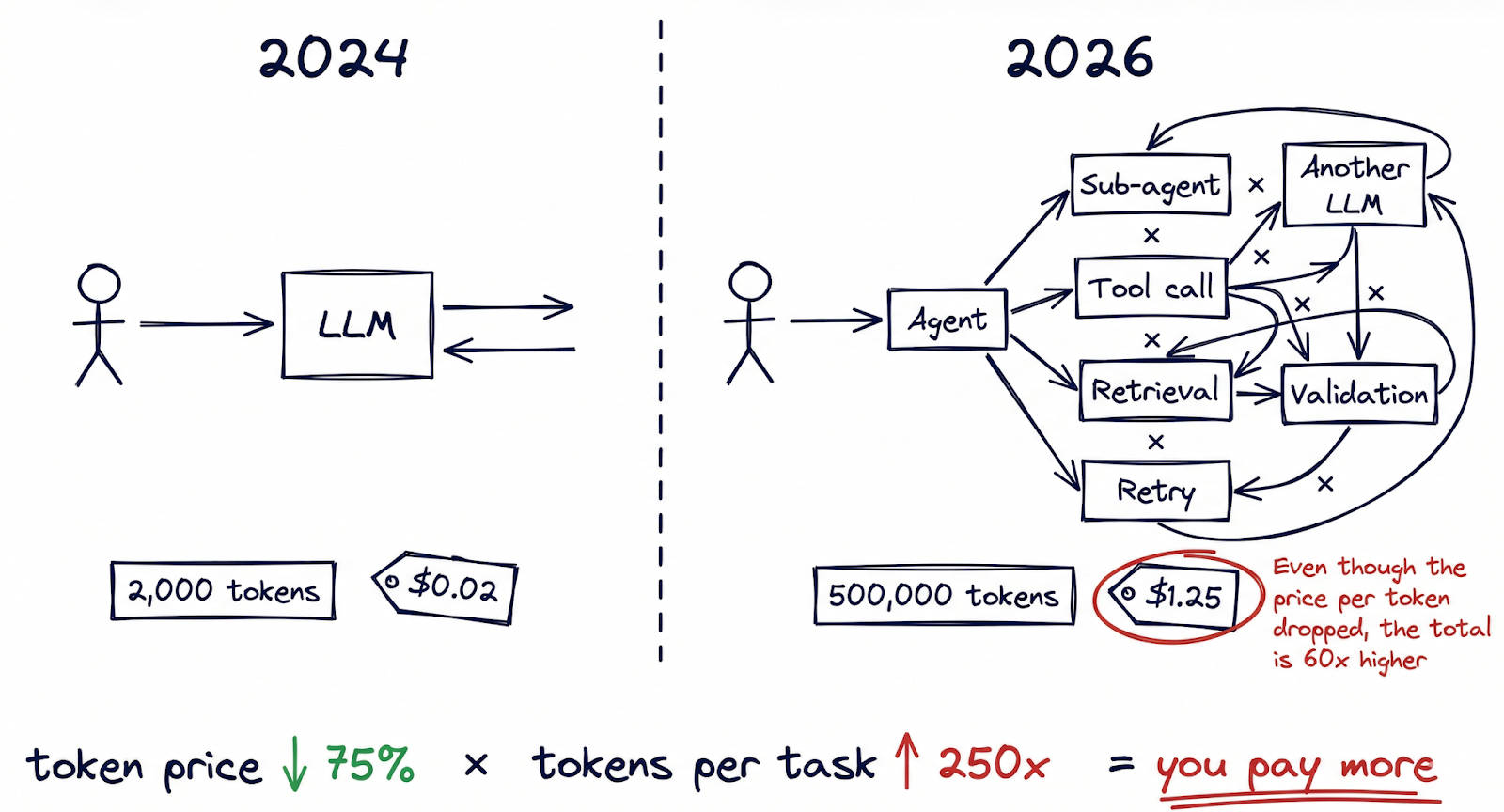
这里是很少成为头条新闻的部分:每个任务消耗的代币数量已经增长了几个数量级,而且还在加速增长。.
一年前,典型的人工智能交互可能只涉及一次提示和回应,总共可能需要 2000 个代币。而今天,人工智能的交互方式已经发生了翻天覆地的变化、, 代理人工智能工作流程 从根本上改变了这种计算方法。由多智能体系统执行的一项任务(研究一个主题、起草一份文件、根据内部策略对其进行验证,然后根据反馈进行迭代)在产生最终输出之前,可能要消耗 50,000 到 500,000 个代币。始终在线的编码助手每天要为每位开发人员处理数百万个令牌。OpenClaw 等多代理协调框架支持代理调用其他代理的工作流,每次交互都会增加令牌数量。.
这种转变的证据在 data 上显而易见。TechCrunch 报道了一种现象,称其为“代币兑换”,描述的是使用统一人工智能订阅计划的强大用户,他们消耗的计算量非常大。其中一些“推论 鲸鱼”每月支付 $200 美元,却产生了超过 $35,000 美元的计算成本。按照这个比例,提供商要为最重要的用户提供 175 倍的补贴。.
财务影响已经在财报中显现出来reports。Notion 披露,毛利率下降了 10 个百分点,这与其在产品中嵌入人工智能功能的成本直接相关。OpsLyft 对企业人工智能部署的分析发现,隐性成本(检索增强、嵌入生成、上下文窗口管理、重试逻辑)通常会在大多数团队跟踪的原始推理账单基础上增加 40-60%。.
大多数企业在人工智能成本方面使用的心智模式都是以每次查询为基础的。但我们已经进入了一个按工作流计算的世界,在这个世界里,用户的一个操作就可能触发多个模型的数十次推理调用。更便宜的令牌乘以每个任务更多的令牌,并不总是等于更低的成本。.
大型科技公司正在重新调整
如果消费问题仅仅是企业预算方面的挑战,也许还可以解决。但有迹象表明,即使是最大的科技公司也认识到了补贴人工智能使用的局限性。.
谷歌最近对其人工智能订阅模式的调整很有启发意义。该公司引入了一个分级系统: 人工智能专业 每月 $19.99 和 超级人工智能 每月 $249.99 美元,新的 人工智能学分 机制,对用量进行计量,而不是提供无限制的使用。从 “包吃包住 ”到计量消费的转变是一个重要信号。它表明,即使是拥有谷歌这样的基础设施和利润率的公司,也无法维持数亿用户以统一价格无限消费令牌。.
资本支出数字强化了这一解读。Alphabet 预计 2025 年的资本支出为 $75 亿美元,现在预计 2026 年这一数字将达到 $175 亿美元到 $185 亿美元,几乎在一年内翻了一番。这一增长主要针对人工智能基础设施:data 中心、定制芯片和网络容量,以处理推理需求。微软、亚马逊和 Meta 也分别做出了类似规模的承诺。.
这些并不是已经解决了人工智能经济学方程式的公司的支出模式。这些都是公司的支出模式,它们竞相建立能力,以应对它们可以预见到的需求曲线,但却无法从中获利。补贴模式(以消费者友好的价格提供丰富的人工智能功能,以推动采用)在建立用户基础方面一直很有效。问题是,在定价必须反映实际计算成本之前,这种模式还能持续多久。.
这种模式与 cloud 计算早期的情况如出一辙,当时,提供商为抢占市场份额,积极提供低价,然后随着使用的成熟,逐步引入预留实例、分级定价和基于消费的计费方式。人工智能定价周期似乎正在将同样的演变压缩到更短的时间内。.
企业内部复兴
对于关注这些动态发展的企业来说,一个熟悉的替代方案正重新获得关注:在本地运行人工智能基础设施。.
英伟达™(NVIDIA®)宣布 尼莫克劳 在 2026 年 3 月举行的全球技术大会上,NemoClaw 值得关注。NemoClaw 扩展了 OpenClaw(开源代理人工智能框架,该框架已迅速成为构建多代理系统的标准)的企业级功能:安全控制、隐私路由、审计日志,以及对英伟达自己的 Nemotron 在本地硬件上运行的模型系列。实际上,它是代理人工智能堆栈的企业分发版,设计用于在企业内部或私有 cloud 环境中运行。.
黄仁勋直接提出了这一意义:他在 GTC audience 上说,“你们的 OpenClaw 战略是什么?”现在已经成为董事会的一个问题。这意味着人工智能代理基础架构正在成为企业技术战略的基础,就像十年前的 cloud 基础架构一样,企业需要对在哪里以及如何运行它有一个深思熟虑的定位。.
预置式人工智能的吸引力不仅仅在于成本的可预测性,尽管这也很重要。它解决了 data 主权 (敏感的 data 永远不会离开组织的网络)、, 监管合规 (欧盟人工智能法》的实施条款生效时尤为重要),以及 代币治理 (能够准确监控、计量和控制推理的消耗量、消耗者和消耗目的)。在这个世界上,一个失控的代理工作流就能在一夜之间消耗掉数千美元的代币,因此拥有基础设施级的控制能力并不奢侈。.
这并不意味着每个企业都应该急于购买 GPU 集群。资金需求是巨大的,操作复杂性是真实的,而且模型改进的速度意味着今天的内部部署硬件可能在十八个月内就无法达到最佳状态。但是,对于推理量大、有监管限制或有 data 灵敏度要求的企业来说,与 cloud API 的价格相比,购买 GPU 集群的经济性正变得越来越有竞争力。.
民主化悖论
在成本动态的背后,还有一个更深层次的矛盾值得一提:使人工智能更容易获得的力量,同时也使其经济性在规模上更难以为继。.
OpenClaw 或许是最明显的例证。作为构建代理人工智能系统的开源框架,它大大降低了创建复杂的多代理工作流程的门槛。现在,一个小团队就能构建一个人工智能驱动的产品,而两年前这需要一个专门的基础设施团队。这是一个真正的转变,它所创建的生态系统将其定位为个人和企业人工智能的操作系统。.
但是,民主化也有其自身的成本曲线,我认为业界对这一点的认识还很迟钝。当创建代理变得非常容易时,企业往往会创建很多代理。每个代理都会消耗代币。每个多代理互动都会成倍增加消耗。其复合效应是,使人工智能变得强大的可访问性也使人工智能变得昂贵,这并不是因为单个呼叫成本高昂,而是因为呼叫总量的扩展速度超过了任何人的预算。.
这是 代币成本幻象 其最纯粹的形式是:智力的单价在下降,但每项成果所消耗的单位却在以更快的速度上升。.
企业的岔路口
这些力量正朝着同一个方向发展:不断增长的消费、重新调整的补贴、日渐成熟的内部部署选项以及日益增长的监管压力。这些因素共同推动企业做出战略选择,并将在未来数年内影响其人工智能经济效益。目前出现了三大路径。.
路径 A:现场主权。. 构建或租赁专用人工智能基础设施,以实现成本控制、data 主权和监管合规。NemoClaw 和类似的企业发行版使这种做法越来越可行。最适合推理量大、data 敏感或在受监管行业运营的企业。需要权衡资本密集度和操作复杂性。.
路径 B:新云专业化。. 一类新的 cloud 提供商正在崛起,它们专门专注于人工智能计算,而非通用 cloud 服务。这些提供商(CoreWeave、Lambda、Together AI 等)提供经过 GPU 优化的基础设施,其定价模式专为推理繁重的工作负载而设计。它们代表了一条中间道路:cloud 的灵活性,而不完全依赖于超级分频器的定价模式。.
路径 C:Hyperscaler 依赖关系。. 继续以主要 cloud 提供商的人工智能服务为基础,接受他们的定价演变,以换取集成深度、生态系统广度和操作简便性。这条道路最容易起步,但随着补贴的取消,价格变化的风险也最大。.
在实践中,大多数大型企业都会采用混合方法,根据工作量敏感性、监管要求和成本情况,将三者的要素混合在一起。关键在于,这正在成为一项深思熟虑的战略决策,而不是默认决策。随着日益紧张的地缘政治局势、data 本地化要求以及欧盟人工智能法案等监管框架都朝着同一个方向发展,人工智能推理在哪里运行的问题不再纯粹是一个技术决策。这是一个管理决策。.
负责任地管理人工智能经济
我们正在接近人工智能成本对话的一个支点。在过去的两年里,主流的说法一直是无情的通货紧缩:模型越来越便宜,推理越来越快,门槛越来越低。这种说法没有错,但并不全面。它描述的是单个代币的价格,而没有考虑一个组织实际消耗了多少代币,或者这个数字增长得有多快。.
这门新兴学科可称为 代币治理人工智能推理的成本管理:企业具备与 cloud 支出、员工人数或资本分配同样严格的组织能力,以监控、预测和管理人工智能推理的成本。这包括成本可观察性(实时了解每个工作流、代理和团队的消耗)、消耗策略(为代理工作流设定界限,防止令牌消耗失控)和基础设施策略(对推理运行的位置和成本做出审慎的选择)。.
能够很好地管理这一转变的组织不一定是在人工智能上花费最少的组织。他们将是那些能够准确了解自己的花费和原因的人。在智能正在成为一种实用工具的世界里,深思熟虑地管理其经济效益可能会被证明与利用其能力同样重要。.

