


Os preços por token caíram 75% em um ano, mas a maioria das organizações está gastando mais em IA, não menos. A ilusão do custo está escondida à vista de todos.
O projeto de lei que não encolheu
Imagine um CFO analisando os gastos trimestrais de cloud. A equipe de AI apresenta um gráfico convincente: os custos de inferência por token caíram 75% ano a ano. Os modelos são mais rápidos, as APIs são mais baratas e o fornecedor está oferecendo descontos por volume. Tudo aponta para a economia. Então, chega a fatura real e o total é maior que o do último trimestre.
Esse não é um cenário hipotético. Ele está ocorrendo em todas as empresas no momento e revela uma lacuna entre a narrativa sobre os custos de IA e a realidade operacional. O setor comemora a queda dos preços dos tokens como se insumos mais baratos significassem automaticamente resultados mais baratos. Mas, na prática, a forma como as organizações consomem IA mudou tão drasticamente que a queda dos preços unitários conta apenas metade da história.
A questão que vale a pena examinar não é se os tokens estão ficando mais baratos. Eles estão. A questão mais reveladora é se esse barateamento está se traduzindo em contas de IA mais baixas ou se está permitindo discretamente padrões de consumo que empurram os custos totais na direção oposta.
A queda de preço é real
Para ser claro: o declínio no preço por token é genuíno e significativo. De acordo com o data de gastos empresariais da Ramp, o custo médio por milhão de tokens nos principais provedores caiu de aproximadamente $10 para $2,50 em um único ano. A pesquisa da Epoch AI sugere que os custos de inferência estão caindo a taxas próximas a 200 vezes por ano, levando em conta as melhorias de preço e eficiência. Andreessen Horowitz cunhou o termo “LLMflation” para descrever essa curva deflacionária, traçando um paralelo com a Lei de Moore em semicondutores.
Os motivadores são bem compreendidos. A concorrência entre os fornecedores de modelos de fronteira (OpenAI, Anthropic, Google, Meta) criou uma pressão agressiva sobre os preços. Modelos de peso aberto, como Llama e Mistral, estabeleceram um piso de preço que os fornecedores proprietários não podem ignorar. Os aprimoramentos de hardware, incluindo a arquitetura Blackwell da NVIDIA e o silício personalizado do Google (TPU v6) e da Amazon (Trainium), melhoraram constantemente o rendimento da inferência por dólar. A quantização, a decodificação especulativa e as técnicas de destilação reduziram ainda mais a computação necessária por token.
Para casos de uso simples e limitados (um chatbot que responde a perguntas frequentes, uma ferramenta de resumo que processa documentos), essa queda de preço está gerando economias reais. As organizações que fixaram seus padrões de uso de IA com antecedência estão, em muitos casos, realmente gastando menos.
O problema começa quando os padrões de uso não ficam bloqueados.
A explosão do consumo
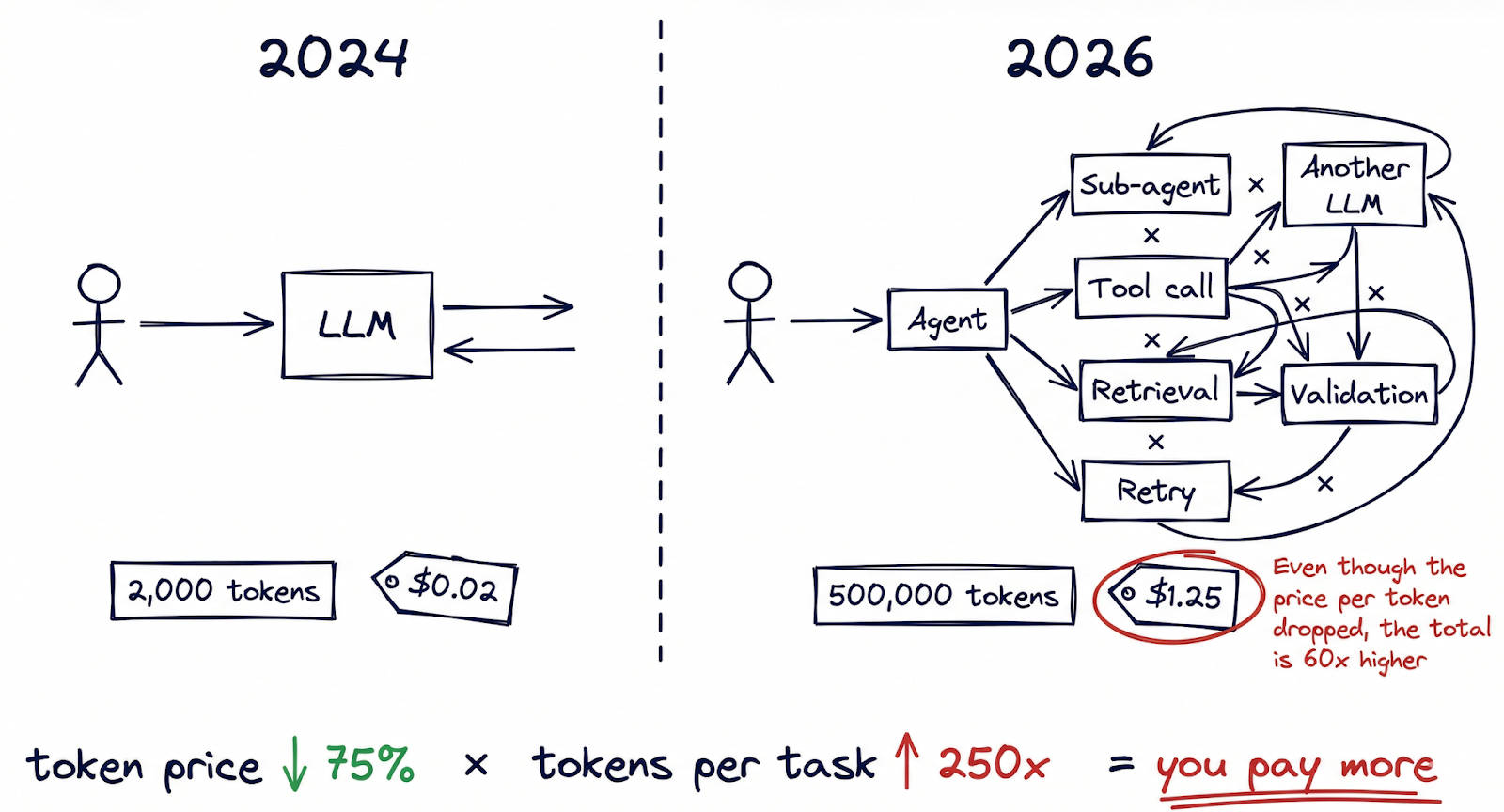
Aqui está a parte da equação que raramente aparece nas manchetes: o número de tokens consumidos por tarefa cresceu em ordens de magnitude e está se acelerando.
Há um ano, uma interação típica de IA poderia envolver uma única solicitação e resposta, talvez 2.000 tokens no total. Hoje, fluxos de trabalho de IA autêntica mudaram fundamentalmente essa aritmética. Uma única tarefa executada por um sistema multiagente (pesquisar um tópico, redigir um documento, validá-lo em relação às políticas internas e, em seguida, iterar com base no feedback) pode queimar de 50.000 a 500.000 tokens antes de produzir um resultado final. Os assistentes de codificação sempre ativos processam rotineiramente milhões de tokens por desenvolvedor e por dia. As estruturas de orquestração de vários agentes, como o OpenClaw, permitem fluxos de trabalho em que os agentes chamam outros agentes, cada interação aumentando a contagem de tokens.
A evidência dessa mudança é visível no data. O TechCrunch relatou um fenômeno que chamou de “tokenmaxxing”, descrevendo usuários avançados em planos de assinatura de IA de taxa fixa que estavam consumindo quantidades extraordinárias de computação. Alguns desses “inferência baleias” gerou mais de $35.000 em custos de computação enquanto pagava $200 por mês. Com essa proporção, o provedor está absorvendo um subsídio de 175 vezes sobre seus usuários mais pesados.
O impacto financeiro já está aparecendo nos lucros reports. A Notion divulgou um declínio de 10 pontos percentuais nas margens brutas vinculadas diretamente ao custo de incorporação de recursos de IA em seu produto. A análise da OpsLyft das implementações de IA corporativa constatou que os custos ocultos (aumento de recuperação, geração de incorporação, gerenciamento de janelas de contexto, lógica de repetição) adicionavam rotineiramente 40-60% à conta de inferência bruta que a maioria das equipes estava acompanhando.
O modelo mental que a maioria das organizações usa para os custos de IA está ancorado em um mundo por consulta. Mas passamos para um mundo por fluxo de trabalho, em que uma única ação do usuário pode acionar dezenas de chamadas de inferência em vários modelos. Os tokens mais baratos multiplicados por um número muito maior de tokens por tarefa nem sempre equivalem a gastos menores.
A grande tecnologia está se recalibrando
Se o problema do consumo fosse apenas um desafio orçamentário da empresa, ele poderia ser gerenciável. Mas há sinais de que até mesmo as maiores empresas de tecnologia estão reconhecendo os limites do uso subsidiado de IA.
A recente reestruturação do Google de seu modelo de assinatura de IA é instrutiva. A empresa introduziu um sistema em camadas: AI Pro por $19.99 por mês e AI Ultra a $249,99 por mês, com um novo Créditos de IA mecanismo que mede o uso em vez de oferecer acesso ilimitado. A mudança de “tudo o que o senhor pode comer” para o consumo medido é um sinal significativo. Ela sugere que mesmo uma empresa com a infraestrutura e as margens do Google não pode sustentar o consumo ilimitado de tokens a preços fixos para centenas de milhões de usuários.
Os números das despesas de capital reforçam essa leitura. A Alphabet projetou $75 bilhões em capex para 2025, e agora espera-se que esse número atinja $175 a $185 bilhões em 2026, quase dobrando em um único ano. A maior parte desse aumento é direcionada à infraestrutura de IA: centros de data, chips personalizados e capacidade de rede para lidar com a demanda de inferência. A Microsoft, a Amazon e a Meta estão assumindo compromissos de escala semelhante.
Esses não são os padrões de gastos das empresas que resolveram a equação econômica da IA. São os padrões de gastos das empresas que estão correndo para desenvolver a capacidade de uma curva de demanda que elas podem prever, mas que ainda não podem atender de forma lucrativa. O modelo de subsídio (oferecer recursos generosos de IA a preços acessíveis ao consumidor para impulsionar a adoção) tem sido eficaz na construção de bases de usuários. A questão é por quanto tempo ele pode continuar antes que os preços reflitam os custos reais de computação.
O padrão aqui ecoa os primeiros dias da computação cloud, quando os provedores ofereciam preços agressivamente baixos para conquistar participação no mercado e, em seguida, introduziam gradualmente instâncias reservadas, preços diferenciados e faturamento baseado em consumo à medida que o uso amadurecia. O ciclo de preços da IA parece estar comprimindo essa mesma evolução em um período de tempo muito mais curto.
O renascimento do local
Para as organizações que estão observando o desenrolar dessa dinâmica, uma alternativa conhecida está ganhando atenção renovada: executar a infraestrutura de IA localmente.
O anúncio da NVIDIA de NemoClaw na GTC em março de 2026, vale a pena prestar atenção. O NemoClaw amplia o OpenClaw (a estrutura de IA agêntica de código aberto que se tornou rapidamente o padrão para a criação de sistemas multiagentes) com recursos de nível empresarial: controles de segurança, roteamento de privacidade, registro de auditoria e suporte nativo para o próprio Nemotron família de modelos executados em hardware local. Trata-se, na verdade, de uma distribuição corporativa da pilha de IA agêntica, projetada para ser executada no local ou em ambientes privados cloud.
Jensen Huang enquadrou a importância diretamente: “Qual é a sua estratégia OpenClaw?” agora é uma pergunta da diretoria, disse ele ao GTC audience. A implicação é que a infraestrutura de agentes de IA está se tornando tão fundamental para a estratégia de tecnologia corporativa quanto a infraestrutura cloud era há uma década, e que as organizações precisam de uma posição deliberada sobre onde e como executá-la.
O apelo da IA no local vai além da previsibilidade de custos, embora isso seja importante. Ela aborda data soberania (o data sensível nunca sai da rede da organização), conformidade regulatória (particularmente relevante quando as disposições operacionais da Lei de IA da UE entrarem em vigor), e governança de tokens (a capacidade de monitorar, medir e controlar exatamente quanta inferência está sendo consumida, por quem e para qual finalidade). Em um mundo em que um único fluxo de trabalho agêntico descontrolado pode queimar milhares de dólares em tokens da noite para o dia, ter controles no nível da infraestrutura não é um luxo.
Isso não significa que todas as organizações devam se apressar para comprar clusters de GPU. Os requisitos de capital são substanciais, a complexidade operacional é real e o ritmo de aprimoramento do modelo significa que o hardware local de hoje pode estar abaixo do ideal dentro de dezoito meses. Mas para as organizações com volumes de inferência significativos, restrições regulamentares ou requisitos de sensibilidade data, a economia de propriedade está se tornando cada vez mais competitiva com os preços de API cloud.
O paradoxo da democratização
Há uma tensão mais profunda por trás da dinâmica de custos que vale a pena mencionar: as próprias forças que tornam a IA mais acessível também estão tornando sua economia menos sustentável em escala.
O OpenClaw talvez seja a ilustração mais clara. Como uma estrutura de código aberto para a criação de sistemas de IA agêntica, ele reduziu drasticamente a barreira para a criação de fluxos de trabalho sofisticados com vários agentes. Agora, uma pequena equipe pode criar um produto com tecnologia de IA que, há dois anos, exigiria uma equipe de infraestrutura dedicada. Essa é uma mudança real, e o ecossistema que ela criou a posiciona como algo próximo a um sistema operacional para IA pessoal e empresarial.
Mas a democratização tem sua própria curva de custo, e acho que o setor tem demorado a reconhecê-la. Quando se torna trivialmente fácil criar agentes, as organizações tendem a criar muitos deles. Cada agente consome tokens. Cada interação com vários agentes multiplica o consumo. O efeito composto é que a mesma acessibilidade que torna a IA poderosa também a torna cara, não porque qualquer chamada individual seja cara, mas porque o volume total de chamadas aumenta mais rapidamente do que o previsto no orçamento.
Este é o ilusão de custo de token em sua forma mais pura: o preço unitário da inteligência está caindo, mas as unidades consumidas por resultado estão aumentando ainda mais rapidamente.
A bifurcação da empresa na estrada
Essas forças estão puxando na mesma direção: aumento do consumo, recalibração dos subsídios, amadurecimento das opções no local e crescente pressão regulatória. Juntas, elas estão empurrando as empresas para uma escolha estratégica que moldará sua economia de IA nos próximos anos. Três caminhos amplos estão surgindo.
Caminho A: Soberania no local. Crie ou alugue uma infraestrutura de IA dedicada para controle de custos, soberania data e conformidade normativa. O NemoClaw e distribuições empresariais semelhantes tornam isso cada vez mais viável. Mais adequado para organizações com grandes volumes de inferência, data sensível ou operações em setores regulamentados. A compensação é a intensidade de capital e a complexidade operacional.
Caminho B: especialização em neonuvem. Uma nova categoria de provedores de cloud está surgindo, focada especificamente na computação de IA em vez de serviços de cloud de uso geral. Esses provedores (CoreWeave, Lambda, Together AI e outros) oferecem infraestrutura otimizada para GPU com modelos de preços projetados para cargas de trabalho pesadas de inferência. Eles representam um caminho intermediário: Flexibilidade do cloud sem dependência total do modelo de preços do hyperscaler.
Caminho C: Hyperscaler Dependência. Continuar a desenvolver os serviços de IA dos principais provedores de cloud, aceitando a evolução de seus preços em troca de profundidade de integração, amplitude do ecossistema e simplicidade operacional. Esse caminho é o mais fácil de começar, mas é o mais exposto a mudanças de preços à medida que os subsídios são reduzidos.
Na prática, a maioria das grandes organizações adotará uma abordagem híbrida, combinando elementos de todas as três com base na sensibilidade da carga de trabalho, nos requisitos normativos e nos perfis de custo. O ponto crítico é que isso está se tornando uma decisão estratégica deliberada, e não uma decisão padrão. Com o aumento das tensões geopolíticas, os requisitos de localização data e as estruturas regulatórias, como a Lei de IA da UE, todos puxando na mesma direção, a questão de onde sua inferência de IA é executada não é mais uma decisão puramente tecnológica. É uma decisão de governança.
Gerenciando a economia da IA de forma responsável
Estamos nos aproximando de um ponto de inflexão na conversa sobre custos de IA. Nos últimos dois anos, a narrativa dominante tem sido a de uma deflação implacável: modelos cada vez mais baratos, inferência cada vez mais rápida, barreiras cada vez menores. Essa narrativa não está errada, mas é incompleta. Ela descreve o preço de um único token sem levar em conta quantos tokens uma organização realmente consome ou a rapidez com que esse número está crescendo.
A disciplina emergente pode ser chamada de governança de tokensCapacidade organizacional de monitorar, prever e gerenciar os custos de inferência de IA com o mesmo rigor que as empresas aplicam aos gastos de cloud, ao número de funcionários ou à alocação de capital. Isso inclui a observabilidade dos custos (saber em tempo real o que cada fluxo de trabalho, agente e equipe está consumindo), as políticas de consumo (definir limites para os fluxos de trabalho agênticos a fim de evitar a queima descontrolada de tokens) e a estratégia de infraestrutura (fazer escolhas deliberadas sobre onde a inferência é executada e a que custo).
As organizações que gerenciarem bem essa transição não serão necessariamente as que gastarem menos com IA. Elas serão aquelas que entenderão, com precisão, o que estão gastando e por quê. Em um mundo em que a inteligência está se tornando uma utilidade, gerenciar cuidadosamente sua economia pode ser tão importante quanto aproveitar seus recursos.
