


Le prix des jetons a chuté de 75% en un an, mais la plupart des entreprises dépensent plus pour l'IA, et non moins. L'illusion du coût se cache à la vue de tous.
Le projet de loi qui n'a pas rétréci
Imaginez un directeur financier en train d'examiner les dépenses trimestrielles cloud. L'équipe AI lui présente un graphique convaincant : les coûts d'inférence par jeton ont baissé de 75% d'une année sur l'autre. Les modèles sont plus rapides, les API sont moins chères et le fournisseur propose des remises sur volume. Tout semble indiquer des économies. Puis la facture arrive, et le montant total est plus élevé que celui du trimestre dernier.
Il ne s'agit pas d'un scénario hypothétique. Il se déroule actuellement dans les entreprises et révèle un fossé entre le discours sur les coûts de l'IA et la réalité opérationnelle. L'industrie célèbre l'effondrement des prix des jetons comme si des intrants moins chers signifiaient automatiquement des résultats moins chers. Mais dans la pratique, la façon dont les organisations consomment l'IA a changé de façon si spectaculaire que la chute des prix unitaires n'explique que la moitié de la situation.
La question qui mérite d'être examinée n'est pas de savoir si les jetons deviennent moins chers. C'est le cas. La question la plus révélatrice est de savoir si cette baisse des prix se traduit par une diminution des factures d'IA, ou si elle favorise discrètement des modes de consommation qui font grimper les coûts totaux dans la direction opposée.
La baisse des prix est réelle
Soyons clairs : la baisse du prix par jeton est réelle et significative. Selon les dépenses d'entreprise de Ramp (data), le coût moyen par million de jetons chez les principaux fournisseurs est passé d'environ $10 à $2,50 en un an. Les recherches d'Epoch AI suggèrent que les coûts d'inférence chutent à un rythme proche de 200 fois par an si l'on tient compte à la fois des prix et des améliorations de l'efficacité. Andreessen Horowitz a inventé le terme “LLMflation”pour décrire cette courbe déflationniste, établissant un parallèle avec la loi de Moore dans le domaine des semi-conducteurs.
Les moteurs sont bien compris. La concurrence entre les fournisseurs de modèles d'avant-garde (OpenAI, Anthropic, Google, Meta) a créé une pression agressive sur les prix. Les modèles à poids ouvert comme Llama et Mistral ont établi un plancher de prix que les fournisseurs propriétaires ne peuvent ignorer. Les améliorations matérielles, notamment l'architecture Blackwell de NVIDIA et le silicium personnalisé de Google (TPU v6) et d'Amazon (Trainium), ont régulièrement amélioré le débit d'inférence par dollar. La quantification, le décodage spéculatif et les techniques de distillation ont encore réduit le calcul nécessaire par jeton.
Pour des cas d'utilisation simples et limités (un chatbot répondant à des FAQ, un outil de synthèse traitant des documents), cette baisse de prix permet de réaliser de réelles économies. Les organisations qui ont intégré très tôt leurs modèles d'utilisation de l'IA sont, dans de nombreux cas, réellement moins dépensières.
Les problèmes commencent lorsque les habitudes d'utilisation ne restent pas verrouillées.
L'explosion de la consommation
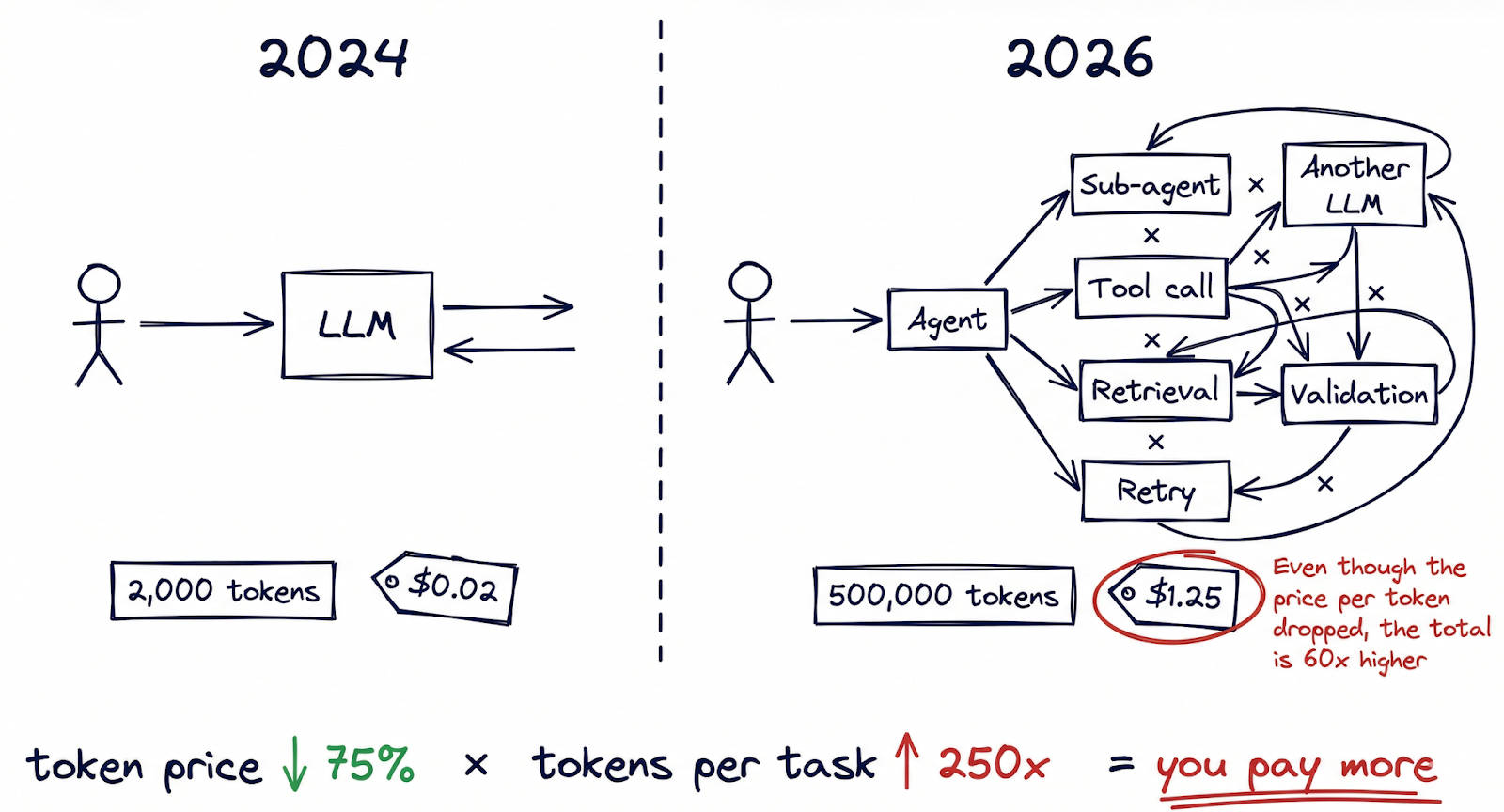
Voici la partie de l'équation qui fait rarement les gros titres : le nombre de jetons consommés par tâche a augmenté de plusieurs ordres de grandeur, et ce phénomène s'accélère.
Il y a un an, une interaction typique avec l'IA pouvait impliquer une seule demande et une seule réponse, soit peut-être 2 000 jetons au total. Aujourd'hui, flux de travail d'IA agentique ont fondamentalement changé cette arithmétique. Une seule tâche exécutée par un système multi-agents (recherche d'un sujet, rédaction d'un document, validation par rapport aux politiques internes, puis itération en fonction du retour d'information) peut consommer de 50 000 à 500 000 jetons avant de produire un résultat final. Les assistants de codage toujours actifs traitent couramment des millions de jetons par développeur et par jour. Les cadres d'orchestration multi-agents comme OpenClaw permettent des flux de travail où les agents appellent d'autres agents, chaque interaction augmentant le nombre de jetons.
La preuve de ce changement est visible dans le data. TechCrunch a fait état d'un phénomène qu'il a appelé “tokenmaxxing”Il s'agit d'utilisateurs puissants ayant souscrit à des abonnements forfaitaires à l'IA et consommant des quantités extraordinaires de données informatiques. Certains de ces “déduction baleines”L'utilisateur " a généré plus de $35 000 en coûts de calcul tout en payant $200 par mois. À ce taux, le fournisseur absorbe une subvention de 175 fois sur ses utilisateurs les plus importants.
L'impact financier se fait déjà sentir dans les résultats reports. Notion a révélé une baisse de 10 points de pourcentage de ses marges brutes, directement liée au coût de l'intégration des fonctions d'IA dans son produit. L'analyse d'OpsLyft sur les déploiements d'IA en entreprise a révélé que les coûts cachés (augmentation de la recherche, génération d'intégration, gestion de la fenêtre contextuelle, logique de relance) ajoutaient régulièrement 40-60% à la facture d'inférence brute que la plupart des équipes suivaient.
Le modèle mental que la plupart des organisations utilisent pour les coûts de l'IA est ancré dans un monde par requête. Or, nous sommes passés à un monde de flux de travail, où une seule action de l'utilisateur peut déclencher des dizaines d'appels d'inférence à travers de multiples modèles. Des jetons moins chers multipliés par un nombre considérablement plus élevé de jetons par tâche ne sont pas toujours synonymes de dépenses moindres.
Les grandes entreprises technologiques se rééquilibrent
Si le problème de la consommation n'était qu'un défi budgétaire pour l'entreprise, il pourrait être gérable. Mais certains signes montrent que même les plus grandes entreprises technologiques reconnaissent les limites de l'utilisation subventionnée de l'IA.
La récente restructuration par Google de son modèle d'abonnement à l'IA est instructive. L'entreprise a mis en place un système à plusieurs niveaux : AI Pro à $19.99 par mois et à $19.99 par mois et à $19.99 par mois. AI Ultra à $249.99 par mois, avec un nouveau Crédits AI qui mesure l'utilisation plutôt que d'offrir un accès illimité. Le passage d'une consommation “à volonté” à une consommation mesurée est un signal important. Il suggère que même une entreprise disposant de l'infrastructure et des marges de Google ne peut soutenir une consommation illimitée de jetons à des prix forfaitaires pour des centaines de millions d'utilisateurs.
Les chiffres des dépenses d'investissement renforcent cette lecture. Alphabet prévoyait $75 milliards de capex pour 2025, et ce chiffre devrait maintenant atteindre $175 à $185 milliards en 2026, soit un quasi-doublement en une seule année. La majeure partie de cette augmentation concerne l'infrastructure de l'IA : centres de data, puces personnalisées et capacité de mise en réseau pour gérer la demande d'inférence. Microsoft, Amazon et Meta prennent chacun des engagements d'une ampleur similaire.
Il ne s'agit pas des dépenses des entreprises qui ont résolu l'équation économique de l'IA. Il s'agit plutôt des dépenses d'entreprises qui s'efforcent de renforcer leurs capacités pour répondre à une courbe de demande qu'elles voient venir, mais qu'elles ne peuvent pas encore satisfaire de manière rentable. Le modèle de subvention (qui consiste à offrir des capacités d'IA généreuses à des prix avantageux pour le consommateur afin d'encourager l'adoption) a été efficace pour créer des bases d'utilisateurs. La question est de savoir combien de temps il pourra durer avant que les prix ne reflètent les coûts de calcul réels.
Ce schéma fait écho aux premiers jours de l'informatique cloud, lorsque les fournisseurs proposaient des prix agressivement bas pour conquérir des parts de marché, puis introduisaient progressivement des instances réservées, une tarification échelonnée et une facturation basée sur la consommation au fur et à mesure que l'utilisation arrivait à maturité. Le cycle de tarification de l'IA semble comprimer cette même évolution dans un délai beaucoup plus court.
La renaissance du "on-prem
Pour les organisations qui observent cette dynamique, une alternative familière suscite un regain d'intérêt : l'exécution locale de l'infrastructure d'IA.
L'annonce par NVIDIA de NemoClaw à la GTC en mars 2026 vaut la peine qu'on s'y intéresse. NemoClaw étend OpenClaw (le cadre d'IA agentique open-source qui est rapidement devenu la norme pour la construction de systèmes multi-agents) avec des fonctionnalités de niveau entreprise : contrôles de sécurité, routage de la confidentialité, enregistrement d'audit et prise en charge native de la technologie de NVIDIA, le Nemotron famille de modèles fonctionnant sur du matériel local. Il s'agit en fait d'une distribution d'entreprise de la pile d'IA agentique, conçue pour fonctionner sur place ou dans des environnements privés cloud.
Jensen Huang a directement souligné l'importance de cette question : “Quelle est votre stratégie OpenClaw ?” est désormais une question posée au conseil d'administration, a-t-il déclaré à la GTC audience. L'implication est que l'infrastructure d'agents d'IA devient aussi fondamentale pour la stratégie technologique de l'entreprise que l'infrastructure cloud l'était il y a dix ans, et que les organisations doivent adopter une position délibérée sur l'endroit et la manière dont elles l'exploitent.
L'attrait de l'IA sur site va au-delà de la prévisibilité des coûts, même si celle-ci est importante. Il s'agit de data souveraineté (le data sensible ne quitte jamais le réseau de l'organisation), conformité réglementaire (particulièrement important lorsque les dispositions opérationnelles de la loi sur l'IA de l'UE entreront en vigueur), et gouvernance des jetons (la capacité de surveiller, de mesurer et de contrôler exactement la quantité d'inférence consommée, par qui et dans quel but). Dans un monde où un seul flux de travail agentique peut brûler des milliers de dollars en jetons du jour au lendemain, avoir des contrôles au niveau de l'infrastructure n'est pas un luxe.
Cela ne signifie pas que toutes les entreprises doivent se précipiter pour acheter des grappes de GPU. Les besoins en capitaux sont importants, la complexité opérationnelle est réelle et le rythme d'amélioration des modèles signifie que le matériel sur site d'aujourd'hui pourrait être sous-optimal d'ici dix-huit mois. Mais pour les entreprises ayant des volumes d'inférence importants, des contraintes réglementaires ou des exigences de sensibilité de data, les coûts de possession deviennent de plus en plus compétitifs par rapport aux prix de l'API de cloud.
Le paradoxe de la démocratisation
La dynamique des coûts est sous-tendue par une tension plus profonde qui mérite d'être soulignée : les forces mêmes qui rendent l'IA plus accessible rendent également son économie moins viable à grande échelle.
OpenClaw en est peut-être l'illustration la plus claire. En tant que cadre open-source pour la construction de systèmes d'IA agentique, il a considérablement abaissé la barrière à la création de flux de travail multi-agents sophistiqués. Une petite équipe peut désormais construire un produit doté d'IA qui aurait nécessité une équipe d'infrastructure dédiée il y a deux ans. Il s'agit d'un véritable changement, et l'écosystème qu'il a créé le positionne comme quelque chose de proche d'un système d'exploitation pour l'IA personnelle et d'entreprise.
Mais la démocratisation a une courbe de coût qui lui est propre, et je pense que l'industrie a été lente à la reconnaître. Lorsqu'il devient trivialement facile de créer des agents, les organisations ont tendance à en créer beaucoup. Chaque agent consomme des jetons. Chaque interaction multi-agent multiplie la consommation. L'effet composé est que la même accessibilité qui rend l'IA puissante rend également l'IA coûteuse, non pas parce qu'un appel individuel est coûteux, mais parce que le volume total des appels augmente plus rapidement que ce qui avait été prévu dans le budget.
Il s'agit de la illusion du coût du jeton dans sa forme la plus pure : le prix unitaire de l'intelligence diminue, mais les unités consommées par résultat augmentent encore plus rapidement.
La bifurcation de l'entreprise
Ces forces tirent dans la même direction : augmentation de la consommation, recalibrage des subventions, maturation des options sur site et pression réglementaire croissante. Ensemble, elles poussent les entreprises à faire un choix stratégique qui façonnera l'économie de l'IA pour les années à venir. Trois grandes voies se dessinent.
Voie A : Souveraineté sur place. Construisez ou louez une infrastructure d'IA dédiée pour maîtriser les coûts, assurer votre souveraineté et respecter les réglementations. NemoClaw et les distributions d'entreprise similaires rendent cette solution de plus en plus viable. Cette solution est particulièrement adaptée aux organisations ayant des volumes d'inférence élevés, des data sensibles ou des activités dans des secteurs réglementés. Le compromis est l'intensité du capital et la complexité opérationnelle.
Voie B : Spécialisation néo-cloud. Une nouvelle catégorie de fournisseurs de cloud émerge, axée spécifiquement sur le calcul de l'IA plutôt que sur les services cloud généraux. Ces fournisseurs (CoreWeave, Lambda, Together AI et d'autres) proposent une infrastructure optimisée pour les GPU avec des modèles de tarification conçus pour les charges de travail à forte intensité d'inférence. Ils représentent une voie médiane : La flexibilité du cloud sans dépendre entièrement du modèle de tarification de l'hyperscaler.
Chemin C : Hyperscaler Dépendance. Continuer à développer les services d'IA des principaux fournisseurs de cloud, en acceptant l'évolution de leurs prix en échange d'une profondeur d'intégration, d'une étendue de l'écosystème et d'une simplicité opérationnelle. Cette voie est la plus facile pour commencer, mais elle est la plus exposée aux changements de prix au fur et à mesure que les subventions se dénouent.
Dans la pratique, la plupart des grandes entreprises adopteront une approche hybride, mélangeant des éléments des trois approches en fonction de la sensibilité de la charge de travail, des exigences réglementaires et des profils de coûts. L'essentiel est qu'il s'agit d'une décision stratégique délibérée plutôt que d'une décision par défaut. Avec la montée des tensions géopolitiques, les exigences de localisation data et les cadres réglementaires tels que la loi européenne sur l'IA qui vont tous dans le même sens, la question de savoir où s'exécute votre inférence d'IA n'est plus une décision purement technologique. C'est une décision de gouvernance.
Gérer l'économie de l'IA de manière responsable
Nous approchons d'un tournant dans le débat sur les coûts de l'IA. Au cours des deux dernières années, le discours dominant a été celui d'une déflation incessante : les modèles sont de moins en moins chers, l'inférence est de plus en plus rapide, les barrières sont de plus en plus basses. Ce discours n'est pas faux, mais il est incomplet. Il décrit le prix d'un seul jeton sans tenir compte du nombre de jetons qu'une organisation consomme réellement, ni de la vitesse à laquelle ce nombre augmente.
La discipline émergente pourrait s'appeler gouvernance des jetonsLa capacité organisationnelle à surveiller, prévoir et gérer les coûts d'inférence de l'IA avec la même rigueur que les entreprises appliquent aux dépenses cloud, aux effectifs ou à l'affectation des capitaux. Cela inclut l'observabilité des coûts (savoir en temps réel ce que chaque flux de travail, agent et équipe consomme), les politiques de consommation (fixer des limites aux flux de travail des agents pour éviter l'emballement de la consommation de jetons) et la stratégie d'infrastructure (faire des choix délibérés sur l'endroit où l'inférence s'exécute et à quel coût).
Les organisations qui gèrent bien cette transition ne seront pas nécessairement celles qui dépenseront le moins pour l'IA. Elles seront celles qui comprendront, avec précision, ce qu'elles dépensent et pourquoi. Dans un monde où l'intelligence devient un service public, la gestion réfléchie de ses aspects économiques pourrait s'avérer aussi importante que l'exploitation de ses capacités.
