


Executive Summary
MotherDuck extends DuckDB’s analytical performance to the cloud with collaborative features, delivering 4x faster performance than BigQuery and cost savings over traditional data warehouses through serverless, pay-per-use pricing. Following the announcement of MotherDuck’s new European cloud region, we were impressed by its performance and attractive pricing. MotherDuck can already be integrated into your gold layers in order to accelerate the serving of data use cases while saving costs at the same time. See performance benchmark.
Introduction
In the rapidly evolving landscape of data analytics, a new player is challenging the established order of cloud data warehouses. MotherDuck, built on the foundation of DuckDB‘s lightning-fast analytical engine, promises to deliver enterprise-grade performance with the simplicity and cost-effectiveness that modern data teams crave. But can this duck really compete with the established giants?
We put MotherDuck through rigorous testing against established competitors to see if it lives up to the hype. What we discovered challenges the current status quo of analytical databases and suggests a fundamental shift in how we approach cloud-based data processing. This is the story of how an embedded database learned to fly, and why it might just revolutionize your data stack.
To capture this evolving customer, retailers must adapt quickly.
A hatching duck
MotherDuck describes itself as a “DuckDB cloud data warehouse scaling to terabytes for customer-facing analytics and BI.” To understand what makes this cloud data warehouse special, we first need to look at DuckDB, the open-source database system that’s been quietly revolutionizing the data stack over the past few years. In simple terms, DuckDB is an in-memory OLAP SQL database system. For those who don’t live and breathe database jargon, let’s unpack what that actually means:
OLAP stands for Online Analytical Processing. Think of it as a database designed to crunch through massive amounts of data and answer complex business questions fast. Unlike traditional databases that excel at finding individual records (like looking up a customer’s order), OLAP databases are built to scan millions of rows and perform heavy calculations in seconds. They achieve this speed by storing data in columns rather than rows, making it lightning-fast to analyze trends, calculate averages, or sum up sales across entire datasets. This is the same approach used by modern data warehouses like BigQuery or Snowflake. On the flip side, you have OLTP (Online Transaction Processing) databases like PostgreSQL, SQLite, or MySQL. These are the workhorses that power your applications, handling thousands of individual reads and writes per second to keep your app running smoothly. See more on OLAP vs OLTP.
In order to understand how revolutionary DuckDB’s approach really is, we need to step back and look at how we got here. In the mid-1990s, as web giants like Yahoo and Amazon exploded onto the scene, they hit a wall that would reshape the entire data landscape. These companies were drowning in data, what we’d later call “big data”, and their existing systems simply couldn’t keep up. The solution? Expensive, monolithic infrastructures that could handle the scale. But as hardware costs plummeted in the 2000s, a new philosophy emerged: instead of buying bigger machines, why not use lots of smaller, cheaper ones? This thinking gave birth to distributed systems like MapReduce and Apache Hadoop, technologies designed to spread workloads across clusters of commodity hardware. Amazon capitalized on this trend, packaging these distributed technologies as services and launching Amazon Web Services, the first major cloud platform. For years, this became the default playbook: when you hit a data problem, you distributed it across more machines (Fundamentals of Data Engineering, Joe Reis & Matt Housley).
But here’s what’s fascinating: while everyone was busy building distributed systems, something else was happening quietly in the background. The same forces that made distributed computing economical, also made individual machines incredibly powerful. Your laptop today has become incredibly powerful with more RAM, faster processors, and better storage. The developers behind DuckDB recognized this overlooked opportunity: what if, instead of always scaling out, we could scale up more intelligently? What if we could solve many data problems without the complexity of distributed systems at all?
One of the most deployed database engines in the world, SQLite takes a radically different approach from traditional databases. While PostgreSQL and MySQL run as separate servers that applications connect to over a network, SQLite embeds directly into your application as a lightweight library. There’s no server to configure, no network overhead, and no complex setup, just pure, local database functionality that runs within your app’s process. This simplicity, combined with remarkable reliability and speed, has made SQLite ubiquitous across everything from mobile apps to web browsers.
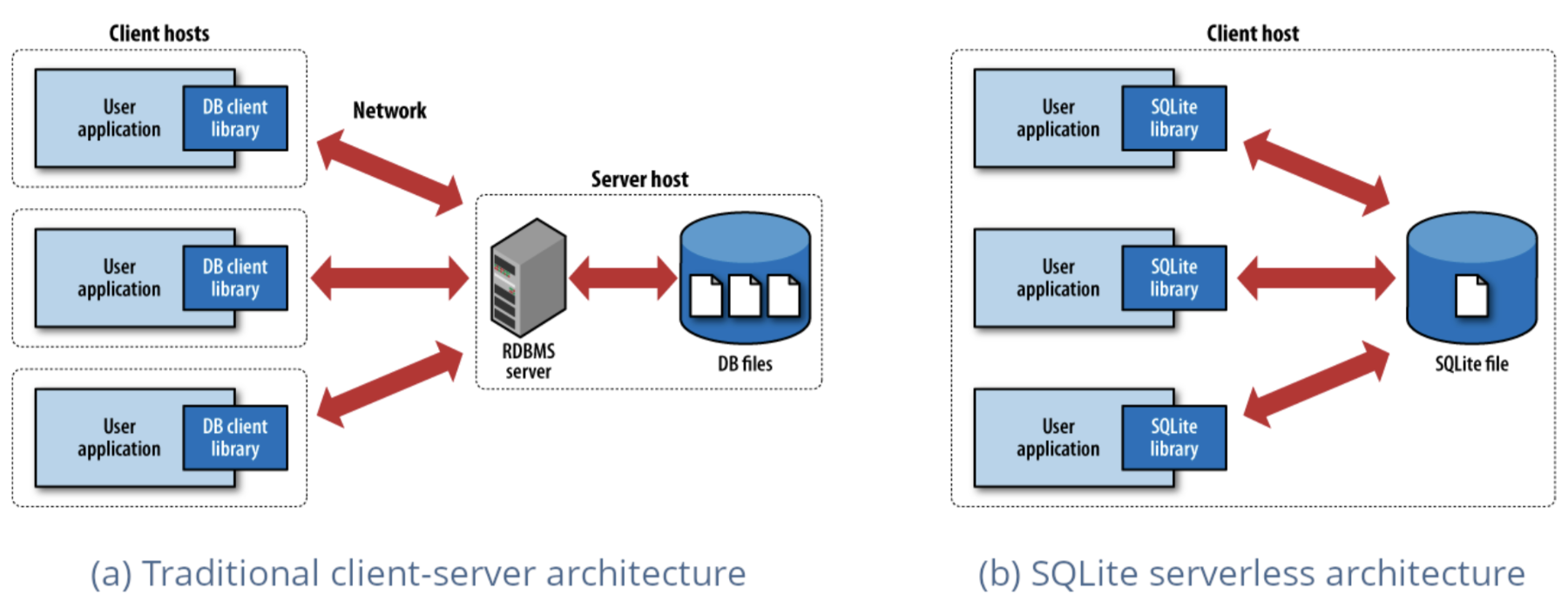
DuckDB applies this same embedded philosophy to analytical workloads, proving that you don’t always need a distributed system to crunch through large datasets. Just like SQLite revolutionized local data storage, DuckDB leverages the raw power of your local machine to make analytics simple again. Installation takes seconds, there are no external dependencies to wrestle with, and suddenly you’re running complex analytical queries on gigabytes of data without spinning up a single cloud instance.
What makes DuckDB particularly compelling is how it meets developers where they are. Need to analyze a Python DataFrame? DuckDB can query it directly. Want to crunch through a CSV file? No problem. This seamless integration, combined with its blazing-fast columnar engine, has made DuckDB one of the fastest-growing database systems in the analytics space. The performance gains are often dramatic enough to make you question why you were using distributed systems in the first place. If you want to dive deeper into the technical philosophy behind this approach, we highly recommend reading “In-Process Analytical Data Management with DuckDB” by DuckDB’s co-creator, Hannes Mühleisen.
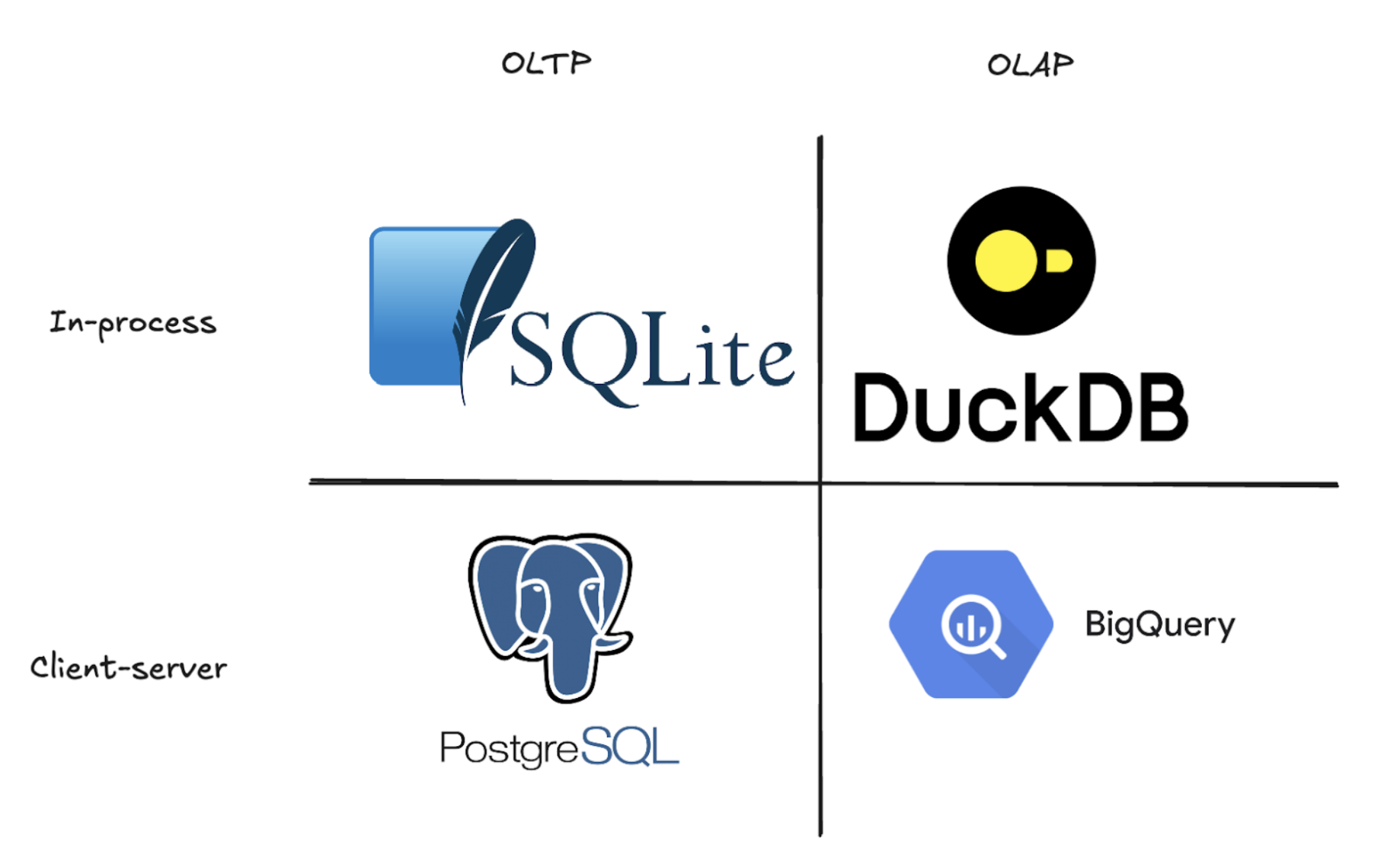
Now that you understand what DuckDB is, let’s talk about its limitations. Every technology has trade-offs. DuckDB can only operate on a single machine and accepts just one connection at a time. In a world where data teams build cloud-native solutions that serve entire organizations, this is a pretty significant constraint. You can’t have multiple analysts querying the same DuckDB instance simultaneously, and you certainly can’t share datasets across teams the way you would with a traditional data warehouse. For all its speed and simplicity, DuckDB essentially locks your data on one machine, accessible to one person at a time. So how do you take this incredibly fast but inherently single-user database and turn it into a cloud data warehouse that can serve an entire organization?
The duck that learned how to fly
Here’s where MotherDuck enters the picture. MotherDuck is a serverless data warehouse that bridges the gap between DuckDB’s raw performance and the collaborative needs of modern data teams. MotherDuck creates what they call an “individualized analytics data warehouse” giving each user their own high-performance DuckDB instance while maintaining the ability to share data across the organization. Here’s how the architecture works:
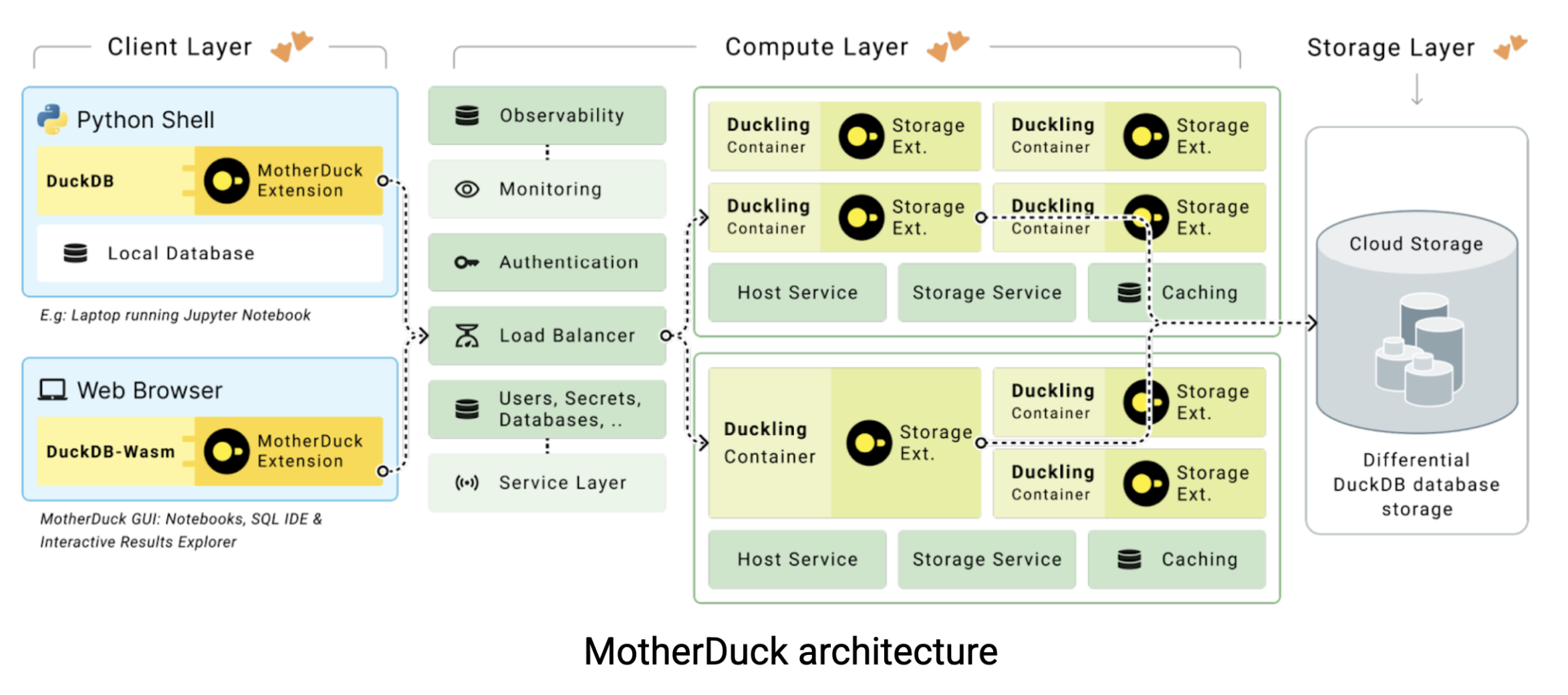
In traditional cloud data warehouses, your laptop is just a dumb terminal. All the heavy lifting happens on remote servers you’re paying for by the hour. But here’s the thing: your MacBook is probably faster than a $20-60 per hour data warehouse instance. MotherDuck tries to leverage this computational power with two innovative approaches:
- Browser-based analytics that bring computation directly to the user.
- Dual execution that intelligently combines your local machine’s processing power with cloud resources to deliver results faster than either approach could achieve alone.
Before diving into both of these methods, I would like to state that MotherDuck’s computational power really shines when applied to your gold layer. For those unfamiliar with the term, the gold layer is the final, business-ready data that’s been cleaned, aggregated, and enriched. Essentially the polished datasets that power your analytics, reporting, and machine learning. This is the data that drives your most critical business decisions, which makes performance here absolutely crucial. Every stakeholder has suffered through painfully slow dashboards, and every data team member has stared at the spinning wheel of death while waiting for complex queries to finish. MotherDuck tackles this frustration head-on.
In-browser analytics
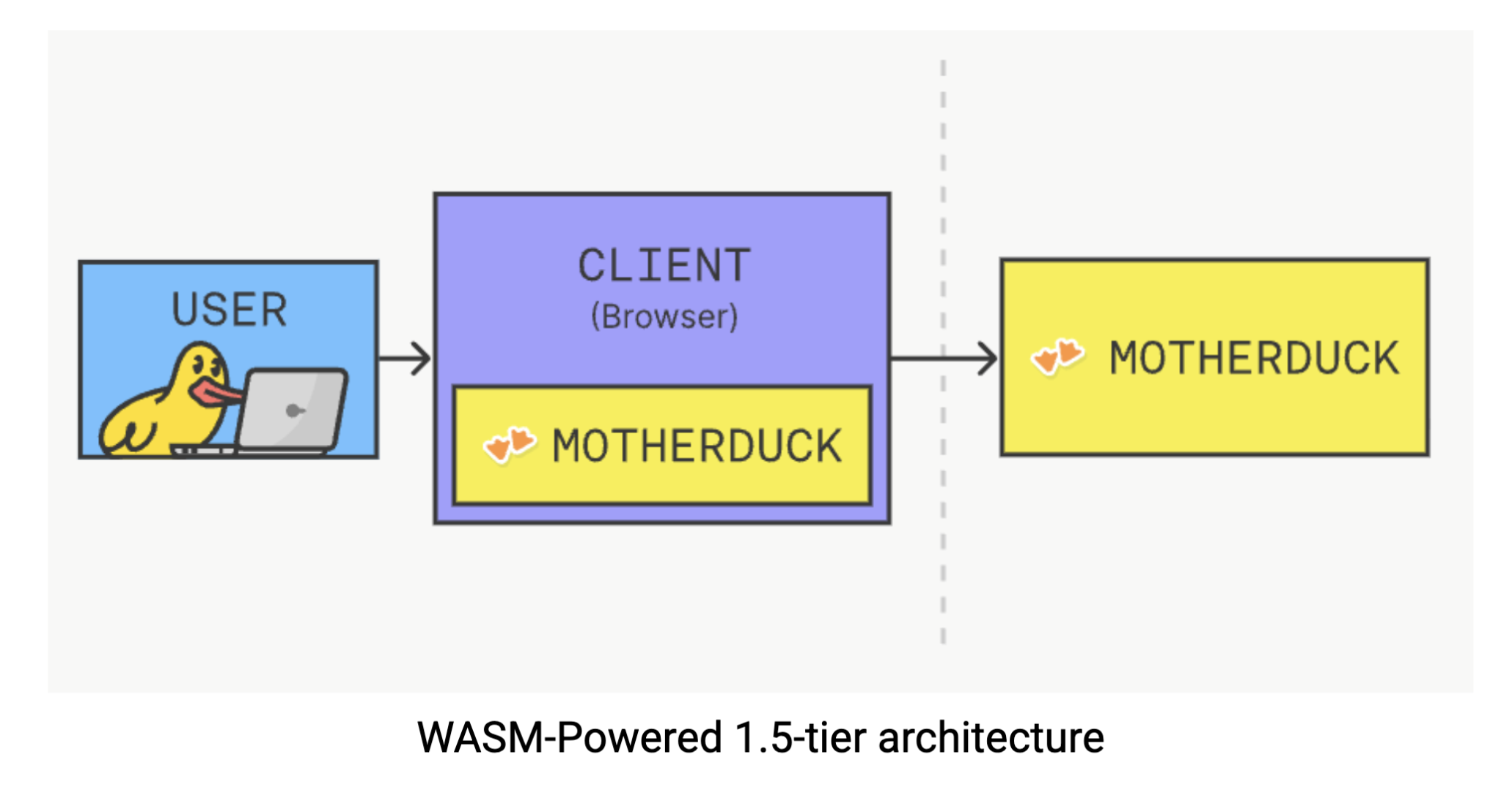
This solution leverages DuckDB’s lightweight and portable design, allowing it to run directly in your browser through WebAssembly (Wasm). Think of Wasm as a technology that lets complex software run natively in your browser: no plugins, no downloads, just computational power where you need it most. With DuckDB running client-side, you can execute complex analytical queries without the usual dance of sending requests to a server and waiting for responses. The data processing happens right in your browser, eliminating network latency and reducing infrastructure dependencies entirely. You can experience this magic yourself by trying DuckDB in your browser.
While we won’t dive deep into the technical implementation here, it’s worth noting that DuckDB-Wasm excels. Research detailed in this paper shows it significantly outperforms existing browser-based solutions like SQLite’s Wasm version or Lovefield, a JavaScript-based database. This clever technical demo signals a fundamental shift in how we think about the location of analytical computation.
MotherDuck offers this Wasm-powered architecture as explained by Mehdi Ouazza in this article. This approach is particularly powerful for gold layer analytics. Your data team gets to work with clean, business-ready data without worrying about backend infrastructure, processing happens locally for maximum speed, and you achieve some of the fastest response times possible by eliminating network latency entirely. Plus, you are avoiding the hefty computational costs that traditional cloud data warehouses love to charge you for every query. It’s a compelling proposition: faster analytics, lower costs, and simpler architecture all rolled into one.
Dual execution
Another way to leverage MotherDuck in your gold layer is through its dual execution capability, which intelligently combines local processing power with cloud scale. Instead of forcing your entire data team to share the same computational resources, MotherDuck gives each user their own “duckling”: an individual, serverless compute instance that scales with their needs.
The real power of dual execution shines when you’re working with data scattered across different sources. Imagine you need to query data stored in MotherDuck, combine it with files in S3, and join it with a dataset sitting locally on your laptop. Traditional cloud systems would force you to upload everything to one place before you could run cross-source queries. MotherDuck’s hybrid execution is smarter. It analyzes your query, keeps only the necessary data from each source, and performs intelligent joins across locations, saving you time and data transfer costs.
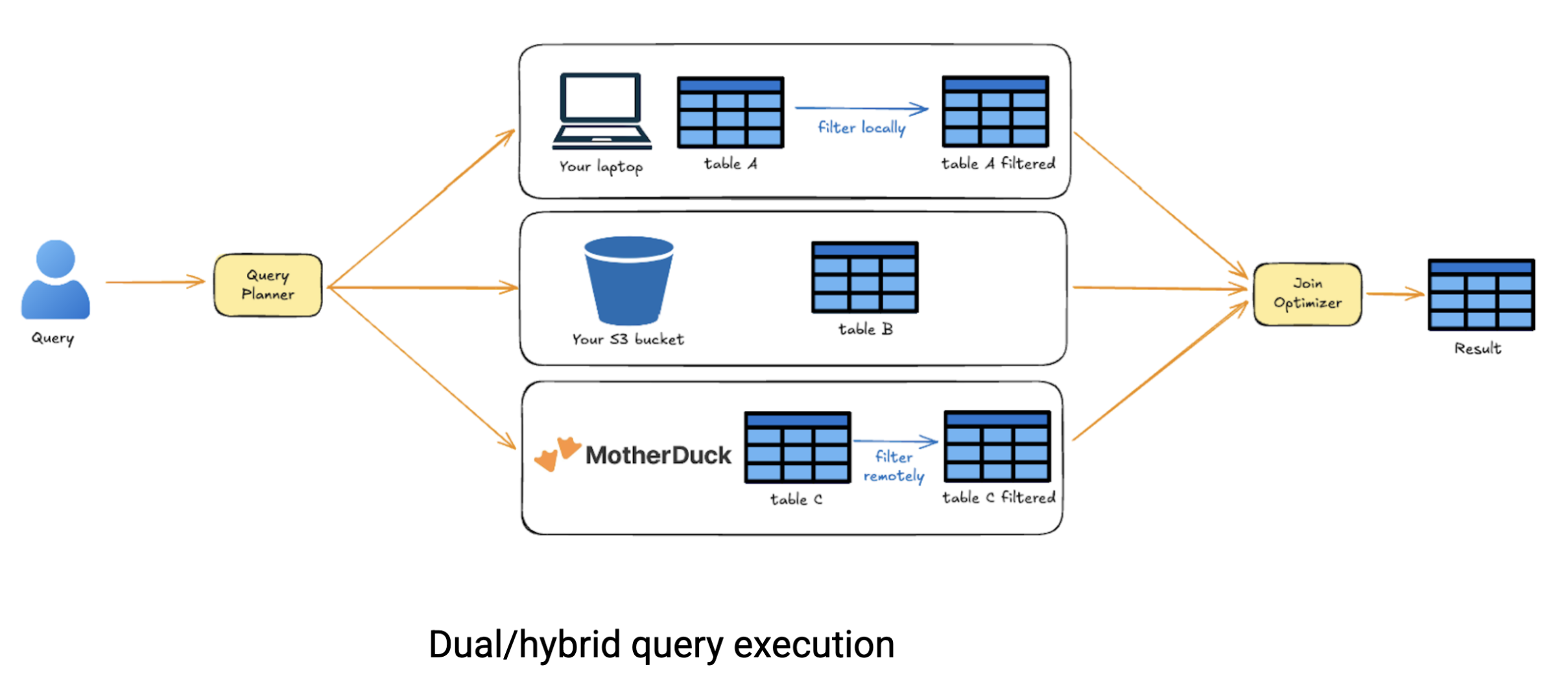
Under the hood, MotherDuck’s optimizer breaks down your query into a DAG (directed acyclic graph) of operations, estimates the cost of running each node locally versus remotely, and handles data movement automatically. You just write SQL; MotherDuck figures out the optimal execution strategy. This approach fundamentally redefines cloud analytics. We are no longer stuck choosing between local simplicity and cloud scalability, each with their own complexity around data sharing and workflow orchestration. With MotherDuck, you get the best of both worlds: run locally when your machine can handle it, scale to the cloud when needed, and share effortlessly throughout. It’s a serverless solution that reduces cloud computation costs because you only pay for what you actually compute.
But here’s where it gets interesting: sharing data becomes effortless. Remember how DuckDB’s single-user nature made collaboration painful? If a data analyst created an amazing analysis, they would have to export everything and upload it to a shared storage system just to let teammates access it. With MotherDuck, sharing is as simple as clicking a button or running a single line of code to create a zero-copy snapshot with proper access controls. No data movement, no storage duplication, just instant collaboration.
Learn more about Dual/Hybrid Query Execution in MotherDuck’s paper from the Conference on Innovative Data Systems Research (CIDR). You can also watch this dbt Coalesce talk by Jordan Tigani, co-founder and CEO of MotherDuck.
Ducks in the Wild
We have seen how MotherDuck removes significant overhead from data teams while delivering powerful analytics capabilities for your gold layer. But theory only goes so far. We wanted to put MotherDuck to the test against established players in the cloud data warehouse space. Looking at the Data Stack Report of 2025 published by Metabase, we found something surprising: PostgreSQL remains the most popular database choice, even for analytical workloads, followed by Snowflake and BigQuery among surveyed companies. This gave us our comparison targets.
We decided to benchmark MotherDuck against hosted PostgreSQL on Google Cloud and BigQuery, using Apache Superset as our BI tool of choice. Superset made sense for several reasons: it’s open source, widely adopted, and it has native MotherDuck compatibility along with most other major databases. Our test environment consisted of Apache Superset deployed on Google Cloud Kubernetes Engine, connected to three different backends: BigQuery, PostgreSQL on Cloud SQL, and MotherDuck.
We structured our testing into two phases. First, we ran the TPC-H benchmark: a standardized decision support benchmark that would show us how MotherDuck performs in a controlled, theoretical environment. Then we moved closer to reality, testing how the relationship between Superset and MotherDuck compared to traditional data warehouses in real-world dashboarding scenarios.
TPC-H benchmarking
TPC-H is the standard for testing analytical database performance. It is a decision support benchmark designed to examine large volumes of data, execute complex queries, and deliver answers to critical business questions across different industries. You can find the complete specification in the official documentation. The benchmark consists of 22 queries that simulate real-world analytical workloads, from simple aggregations to complex multi-table joins.
We ran each query individually through Superset’s SQL Lab for all three databases: MotherDuck, BigQuery, and PostgreSQL. We also tested the queries directly in MotherDuck’s GUI to eliminate client-server latency and because, frankly, any company using MotherDuck would likely have their data analysts working in MotherDuck’s notebook-inspired interface rather than Superset’s SQL Lab. Additionally, MotherDuck’s app can leverage the WebAssembly architecture we discussed earlier, and we were curious to see how this browser-based execution would perform compared to traditional server-client models. To ensure fair testing, Superset’s cache was disabled throughout all benchmarks.
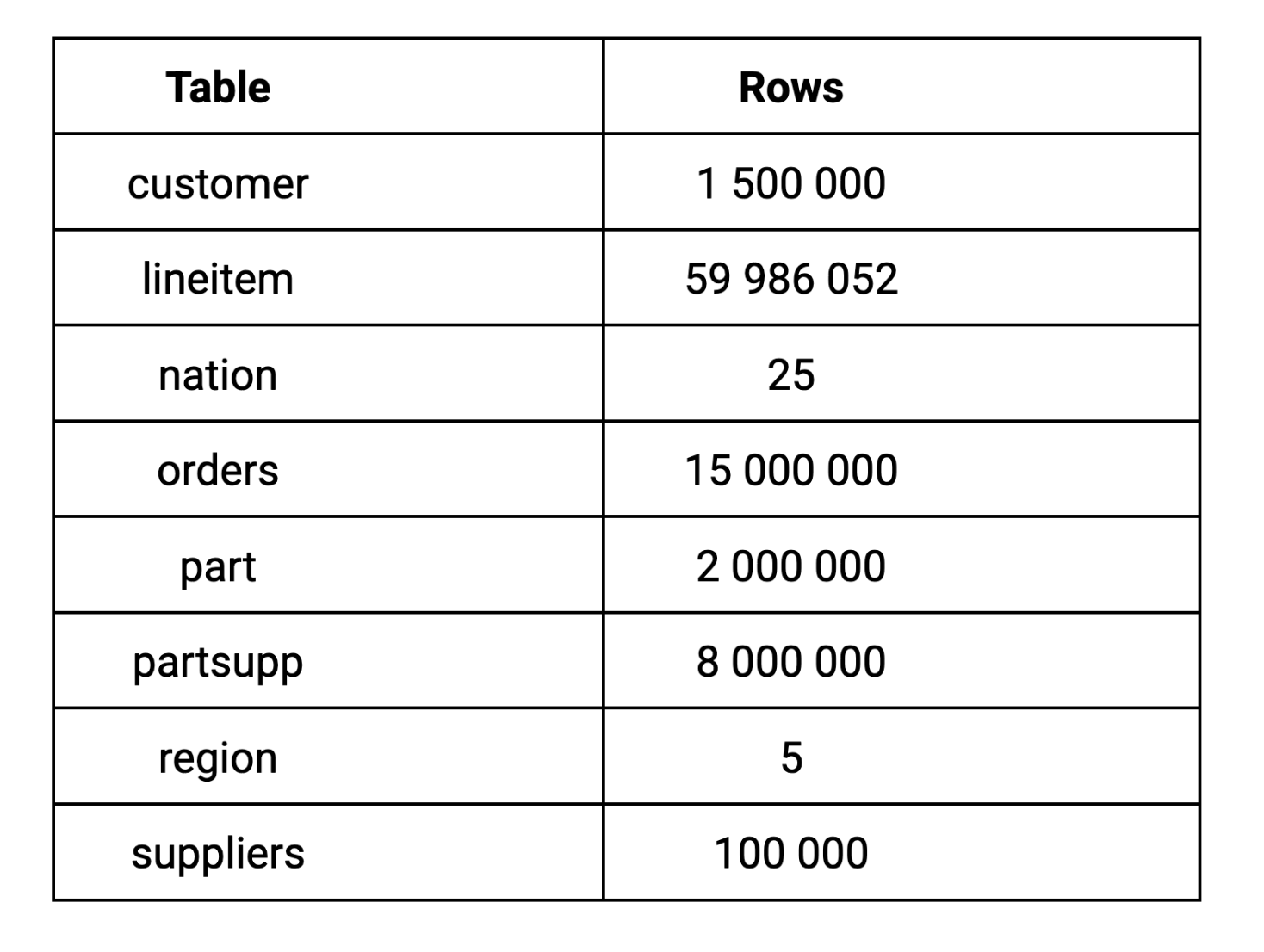
For this benchmark, we used TPC-H scale factor 10 (SF-10), which generates a 10GB dataset. We chose scale factor 10 because 10GB represents a realistic dataset size for most companies’ analytical workloads, large enough to reveal meaningful performance differences without requiring enterprise-scale infrastructure. Here’s how the data breaks down across the key tables:
We used the DuckDB TPC-H extension to generate the data locally, then uploaded it seamlessly to MotherDuck. The process took just minutes thanks to MotherDuck’s data loading capabilities.
Here are the TPC-H SF-10 results in seconds. The yellow column shows results from MotherDuck app’s native UI, while the other columns represent performance through Superset’s (SST) SQL Lab:
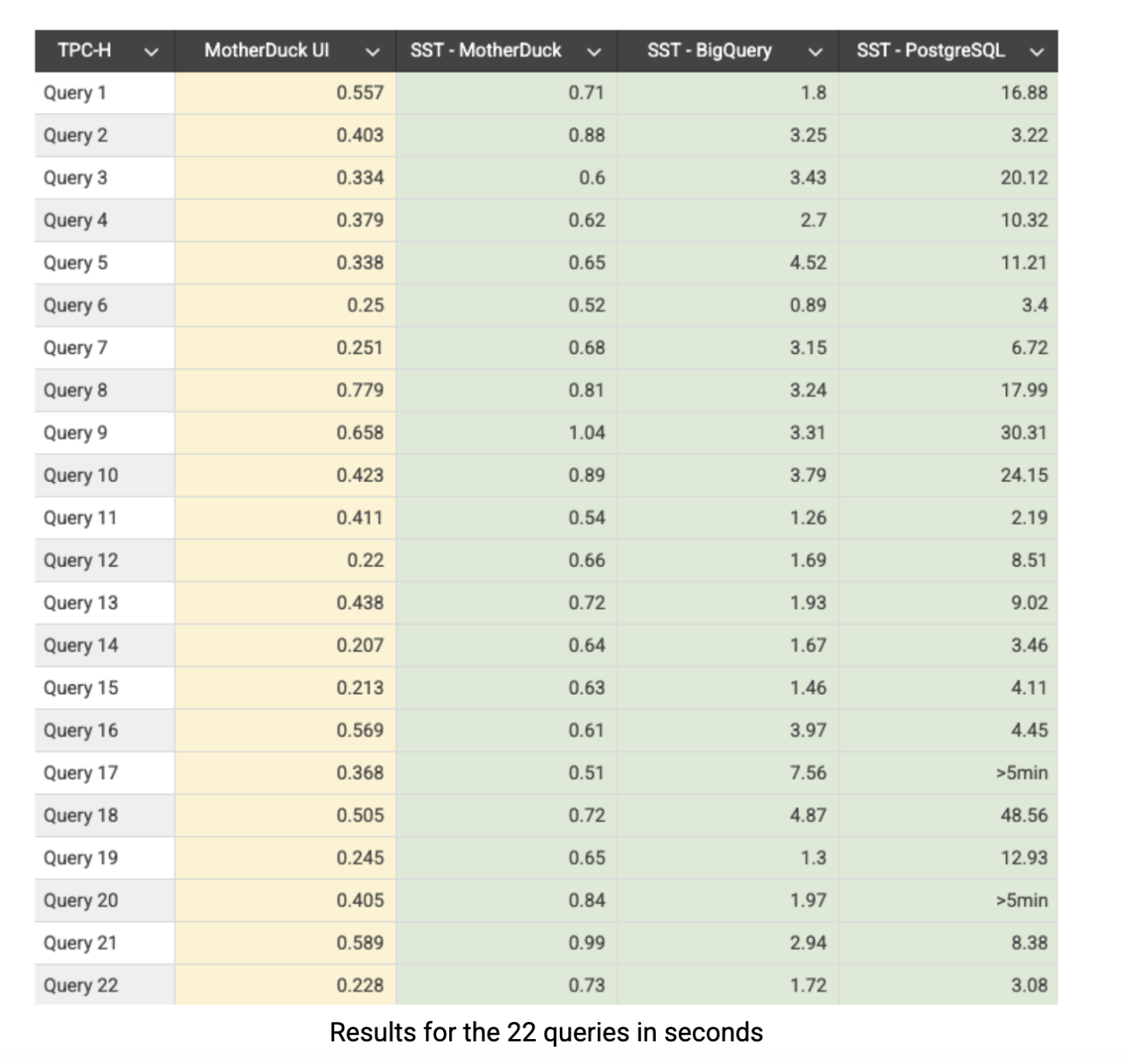
MotherDuck consistently delivers sub-second performance across the board: 21 out of 22 queries through Superset finish in under a second, with all queries completing sub-second when run directly through MotherDuck’s app. BigQuery shows respectable performance but averages roughly 4x slower than MotherDuck across the benchmark suite. PostgreSQL tells a different story entirely, with significantly slower performance and clear struggles on complex aggregations and joins. This was predictable since PostgreSQL is fundamentally designed for OLTP workloads rather than analytical processing, but we included it in our comparison because it remains widely used by companies for analytical tasks. It is worth noting that PostgreSQL could achieve much better performance with proper optimization techniques like indexing, partitioning, or materialized views, but even then, it would still be fighting against its row-based architecture. The performance gap highlights exactly why purpose-built OLAP systems like MotherDuck exist: when you’re running complex analytical queries on substantial datasets, architecture matters enormously.
While TPC-H shows raw query performance, the real test is how this translates to actual user experience in business intelligence tools.
Dashboard performance
We saw that performance was excellent for data analysts working with SQL on their data warehouse, but we wanted to test whether this improvement would translate to dashboarding, where business stakeholders actually interact with the data. After all, blazing-fast SQL queries don’t matter much if your dashboards still take forever to load.
To test this, we used a realistic e-commerce dataset from Kaggle containing 67.5 million rows across 9GB of data, the kind of scale many companies work with for their monthly customer analytics. Using this single table, we built a comprehensive dashboard that would stress-test each system’s ability to handle real-world business intelligence workloads:
I tested the dashboard extensively across multiple runs, applying various filters, measuring loading times, disabling cache, and monitoring response times through my browser’s developer tools. After multiple test cycles to ensure consistent results, here are the dashboard performance metrics in seconds:
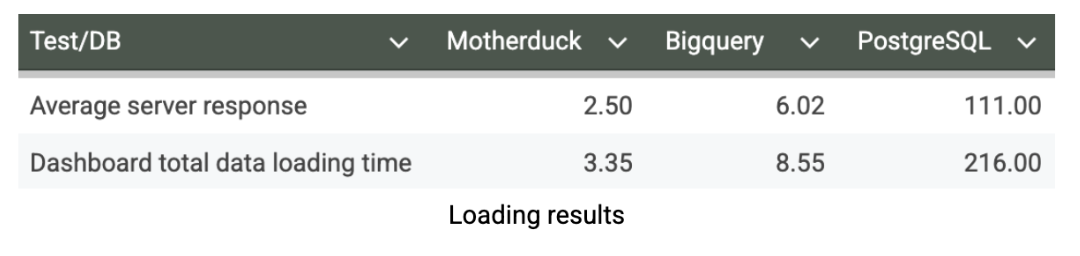
Our dashboard loading tests reveal the practical implications of database performance on user experience. MotherDuck delivers exceptional dashboard responsiveness with an average loading time of just 3.35 seconds, enabling truly interactive analytics where users can explore data fluidly without friction. In contrast, BigQuery requires 8.55 seconds to load the same dashboard. It is still acceptable for planned reporting but creating noticeable delays that can discourage exploratory analysis. PostgreSQL’s 216-second loading time (>3 minutes) renders it completely impractical for dashboard use. This performance advantage for MotherDuck represents can fundamentally transform how business users interact with data. When dashboards load in seconds rather than minutes, user adoption soars, analysts can iterate quickly on insights, and analytics becomes a competitive advantage rather than a bottleneck.
Price comparison
MotherDuck combines storage with pay-as-you-go compute, optimized for interactive analytics. Because it scales up on a single machine instead of distributing across a cluster, it avoids overhead that users end up paying for. A session of dozens of queries might cost just $0.05–$0.10, while a team running thousands of queries monthly might spend only $20–$40. In contrast, always-on databases can run $300–$500/month just to stay live, and cloud warehouses often charge $5–$10 per TB scanned. With its scale-up design, MotherDuck keeps pricing simple, predictable, and cost-efficient.

MotherDuck may initially appear more expensive due to its organizational fee and different compute pricing model. However, both systems use pricing models that favor different usage patterns: BigQuery excels at large batch processing while MotherDuck is optimized for interactive analytics. For our TPC-H benchmark, running 22 queries on SF-10 cost $0.03 for MotherDuckversus $0.60-$1.00 for BigQuery. When factoring in infrastructure overhead, our PostgreSQL setup required €14/day just to stay online, MotherDuck’s serverless approach often delivers superior total cost of ownership for interactive analytical workloads.
At enterprise scale, the economics shift depending on usage patterns. BigQuery becomes more cost-effective for very high-volume batch processing, while MotherDuck maintains its advantage for interactive analytics and exploratory workflows. The key insight: choose your pricing model based on how your team actually works with data, not just the raw per-unit costs.
Note: All pricing examples are based on europe-west4 region and should be considered illustrative rather than exact, as actual costs depend heavily on specific usage patterns and data characteristics.
Conclusion
MotherDuck represents a fundamental shift in how we think about analytical databases, one that challenges the assumption that you need complex, distributed systems to handle serious data workloads. By taking DuckDB’s embedded philosophy and extending it to the cloud, MotherDuck delivers the collaborative capabilities that modern data teams require while maintaining the raw performance that makes DuckDB exceptional.
Our benchmarking results tell a compelling story: MotherDuck consistently outperformed both BigQuery and PostgreSQL by significant margins, delivering sub-second query performance on 10GB datasets and dashboard loading times that enable truly interactive analytics. The performance advantage over BigQuery and the very large advantage over PostgreSQL in dashboard scenarios isn’t just about faster queries, it’s about transforming analytics into a more interactive, exploratory experience that encourages data-driven decision making.
Perhaps most importantly, MotherDuck achieves this performance while dramatically reducing infrastructure complexity and costs. Where traditional cloud setups require always-on infrastructure costing hundreds of dollars monthly, MotherDuck’s serverless model charges only for actual usage, often reducing costs. The pay-per-compute pricing aligns perfectly with how analysts actually work: running multiple queries in exploration sessions rather than isolated, infrequent requests.
The implications extend beyond just performance and cost. MotherDuck’s dual execution model and browser-based analytics capabilities suggest a future where the boundary between local and cloud computing becomes increasingly fluid. Instead of forcing teams to choose between local simplicity and cloud scalability, MotherDuck offers both, intelligently routing computation to wherever it makes the most sense.
What truly impressed me during testing was MotherDuck’s simplicity of use and setup. The dual execution model seamlessly allowed me to query data both locally and in the cloud simultaneously, while setting up the connection between Superset and MotherDuck was remarkably straightforward.
For organizations looking to modernize their analytical capabilities starting with the gold layer, MotherDuck offers a very attractive proposition: enterprise-grade performance, collaborative workflows, and cost efficiency, all without the operational overhead of traditional data warehouse infrastructure. In a world where data-driven decisions increasingly determine competitive advantage, the ability to explore data interactively at sub-second speeds isn’t just a nice-to-have; it’s becoming essential.
Ready to experience MotherDuck’s performance for yourself? You can start with a 21-day free trial or with their free 10GB plan to test it with your own datasets and workloads. If you’re looking for guidance on whether MotherDuck fits your specific data stack or need help with implementation, reach out to our team at Artefact, we would be happy to assess your analytical needs and help you navigate the transition to more efficient, cost-effective analytics infrastructure.
