


Zusammenfassung
MotherDuck erweitert die analytische Leistung von DuckDB auf das cloud mit kollaborativen Funktionen und bietet eine 4x schnellere Leistung als BigQuery sowie Kosteneinsparungen gegenüber herkömmlichen data-Warehouses durch serverlose, nutzungsabhängige Preise. Nach der Ankündigung der neuen europäischen cloud-Region von MotherDuck waren wir von der Leistung und dem attraktiven Preis beeindruckt. MotherDuck kann bereits in Ihre Goldschichten integriert werden, um die Bereitstellung von data-Anwendungsfällen zu beschleunigen und gleichzeitig Kosten zu sparen. Siehe Leistungsbenchmark.
Einführung
In der sich schnell entwickelnden Landschaft der data-Analytik fordert ein neuer Akteur die etablierte Ordnung der cloud data-Lagerhäuser heraus. MotherDuck, aufgebaut auf dem Fundament von DuckDB‘Die blitzschnelle Analyse-Engine von data verspricht eine Leistung auf Unternehmensniveau mit der Einfachheit und Kosteneffizienz, nach der sich moderne Teams sehnen. Aber kann diese Ente wirklich mit den etablierten Giganten mithalten?
Wir haben MotherDuck einem strengen Test mit etablierten Wettbewerbern unterzogen, um zu sehen, ob es dem Hype gerecht wird. Was wir herausgefunden haben, stellt den aktuellen Status Quo der analytischen databases in Frage und deutet auf einen grundlegenden Wandel in der Art und Weise hin, wie wir die cloud-basierte data-Verarbeitung angehen. Dies ist die Geschichte, wie eine eingebettete database das Fliegen lernte und warum sie gerade Ihren data-Stack revolutionieren könnte.
Um diesen sich entwickelnden Kunden zu gewinnen, müssen sich Einzelhändler schnell anpassen.
Eine schlüpfende Ente
MotherDuck beschreibt sich selbst als ein “DuckDB cloud data Warehouse, das auf Terabytes skaliert, für kundenorientierte Analysen und BI.” Um zu verstehen, was dieses cloud data Warehouse so besonders macht, müssen wir uns zunächst ansehen DuckDB, das Open-Source-System database, das den data-Stack in den letzten Jahren im Stillen revolutioniert hat. Einfach ausgedrückt ist DuckDB ein In-Memory-OLAP-SQL-database-System. Für diejenigen, die mit dem database-Jargon nichts anfangen können, erklären wir Ihnen jetzt, was das bedeutet:
OLAP steht für Online Analytical Processing. Stellen Sie sich eine data-Datenbank vor, die entwickelt wurde, um riesige Mengen von data zu verarbeiten und komplexe Geschäftsfragen schnell zu beantworten. Im Gegensatz zu herkömmlichen data-Datenbanken, die sich durch das Auffinden einzelner Datensätze auszeichnen (z.B. die Suche nach einer Kundenbestellung), sind OLAP-data-Datenbanken darauf ausgelegt, Millionen von Zeilen zu durchsuchen und umfangreiche Berechnungen in Sekundenschnelle durchzuführen. Sie erreichen diese Geschwindigkeit, indem sie data in Spalten und nicht in Zeilen speichern. So können Sie blitzschnell Trends analysieren, Durchschnittswerte berechnen oder Umsätze über ganze data-Sätze summieren. Dies ist derselbe Ansatz, der von modernen data-Warehouses wie BigQuery oder Snowflake verwendet wird. Auf der anderen Seite haben Sie OLTP (Online Transaction Processing) data-Basen wie PostgreSQL, SQLite oder MySQL. Dies sind die Arbeitstiere, die Ihre Anwendungen antreiben und Tausende von einzelnen Lese- und Schreibvorgängen pro Sekunde verarbeiten, damit Ihre Anwendung reibungslos läuft. Sehen Sie mehr über OLAP vs. OLTP.
Um zu verstehen, wie revolutionär der Ansatz von DuckDB wirklich ist, müssen wir einen Schritt zurücktreten und uns ansehen, wie wir hierher gekommen sind. Mitte der 1990er Jahre, als Web-Giganten wie Yahoo und Amazon auf den Plan traten, stießen sie auf eine Mauer, die die gesamte data-Landschaft umgestalten sollte. Diese Unternehmen ertranken in data, dem, was wir später als “großes data” bezeichnen würden, und ihre bestehenden Systeme konnten einfach nicht mehr mithalten. Die Lösung? Teure, monolithische Infrastrukturen, die den Umfang bewältigen konnten. Doch als die Hardwarekosten in den 2000er Jahren drastisch sanken, kam eine neue Philosophie auf: Warum nicht viele kleinere, billigere Maschinen verwenden, anstatt größere zu kaufen? Aus dieser Überlegung heraus entstanden verteilte Systeme wie MapReduce und Apache Hadoop, Technologien zur Verteilung von Arbeitslasten auf Cluster von Standardhardware. Amazon machte sich diesen Trend zunutze, indem es diese verteilten Technologien als Dienste verpackte und Amazon Web Services, die erste große cloud-Plattform, auf den Markt brachte. Jahrelang wurde dies zum Standardverfahren: Wenn Sie auf ein data-Problem stießen, verteilten Sie es auf mehrere Rechner (Fundamentals of Data Engineering, Joe Reis & Matt Housley).
Aber das Faszinierende ist, dass, während alle damit beschäftigt waren, verteilte Systeme zu entwickeln, im Hintergrund noch etwas anderes geschah. Die gleichen Kräfte, die das verteilte Rechnen wirtschaftlich machten, machten auch die einzelnen Rechner unglaublich leistungsfähig. Ihr Laptop ist heute mit mehr Arbeitsspeicher, schnelleren Prozessoren und besserem Speicher unglaublich leistungsfähig geworden. Die Entwickler von DuckDB erkannten diese übersehene Chance: Was wäre, wenn wir, anstatt immer weiter zu skalieren, intelligenter skalieren könnten? Was wäre, wenn wir viele data Probleme ganz ohne die Komplexität verteilter Systeme lösen könnten?
Einer der am häufigsten eingesetzten database-Motoren der Welt, SQLite verfolgt einen radikal anderen Ansatz als herkömmliche data-Basen. Während PostgreSQL und MySQL als separate Server laufen, mit denen sich Anwendungen über ein Netzwerk verbinden, bettet sich SQLite als leichtgewichtige Bibliothek direkt in Ihre Anwendung ein. Es muss kein Server konfiguriert werden, es gibt keinen Netzwerk-Overhead und keine komplexe Einrichtung, sondern nur reine, lokale database-Funktionalität, die innerhalb des Prozesses Ihrer Anwendung läuft. Diese Einfachheit, kombiniert mit bemerkenswerter Zuverlässigkeit und Geschwindigkeit, hat dazu geführt, dass SQLite von mobilen Anwendungen bis hin zu Webbrowsern allgegenwärtig ist.
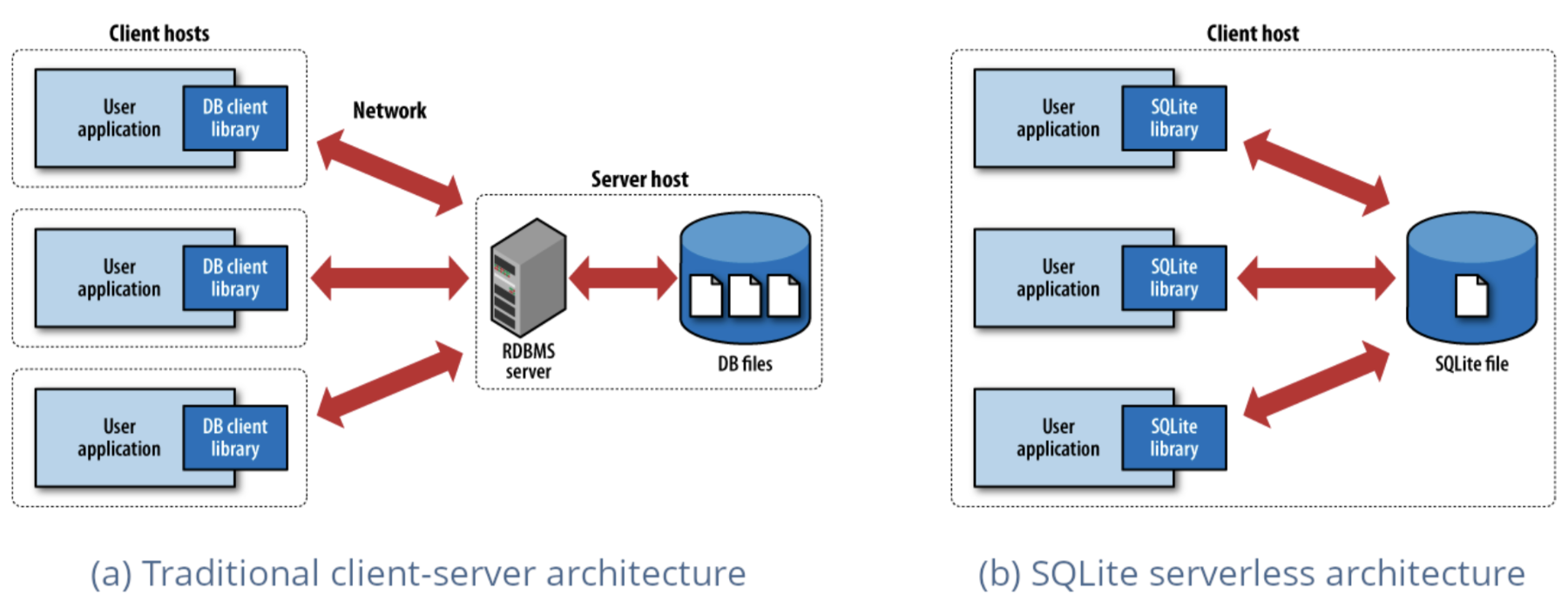
DuckDB wendet dieselbe eingebettete Philosophie auf analytische Workloads an und beweist, dass Sie nicht immer ein verteiltes System benötigen, um große data-Sets zu verarbeiten. So wie SQLite die lokale data-Speicherung revolutioniert hat, nutzt DuckDB die rohe Kraft Ihres lokalen Rechners, um Analysen wieder einfach zu machen. Die Installation dauert nur wenige Sekunden, es gibt keine externen Abhängigkeiten, mit denen Sie sich herumschlagen müssen, und plötzlich können Sie komplexe analytische Abfragen auf Gigabytes von data durchführen, ohne eine einzige cloud-Instanz hochzufahren.
Das Besondere an DuckDB ist, dass es die Entwickler dort abholt, wo sie stehen. Sie müssen einen Python DataFrame analysieren? DuckDB kann ihn direkt abfragen. Sie möchten eine CSV-Datei durchsuchen? Das ist kein Problem. Diese nahtlose Integration hat DuckDB in Verbindung mit seiner blitzschnellen Columnar-Engine zu einem der am schnellsten wachsenden dataBase-Systeme im Bereich der Analytik gemacht. Die Leistungssteigerungen sind oft so dramatisch, dass Sie sich fragen, warum Sie überhaupt verteilte Systeme verwenden. Wenn Sie tiefer in die technische Philosophie hinter diesem Ansatz eintauchen möchten, empfehlen wir Ihnen die Lektüre “Prozessbegleitendes analytisches Data-Management mit DuckDB” vom Miterfinder von DuckDB, Hannes Mühleisen.
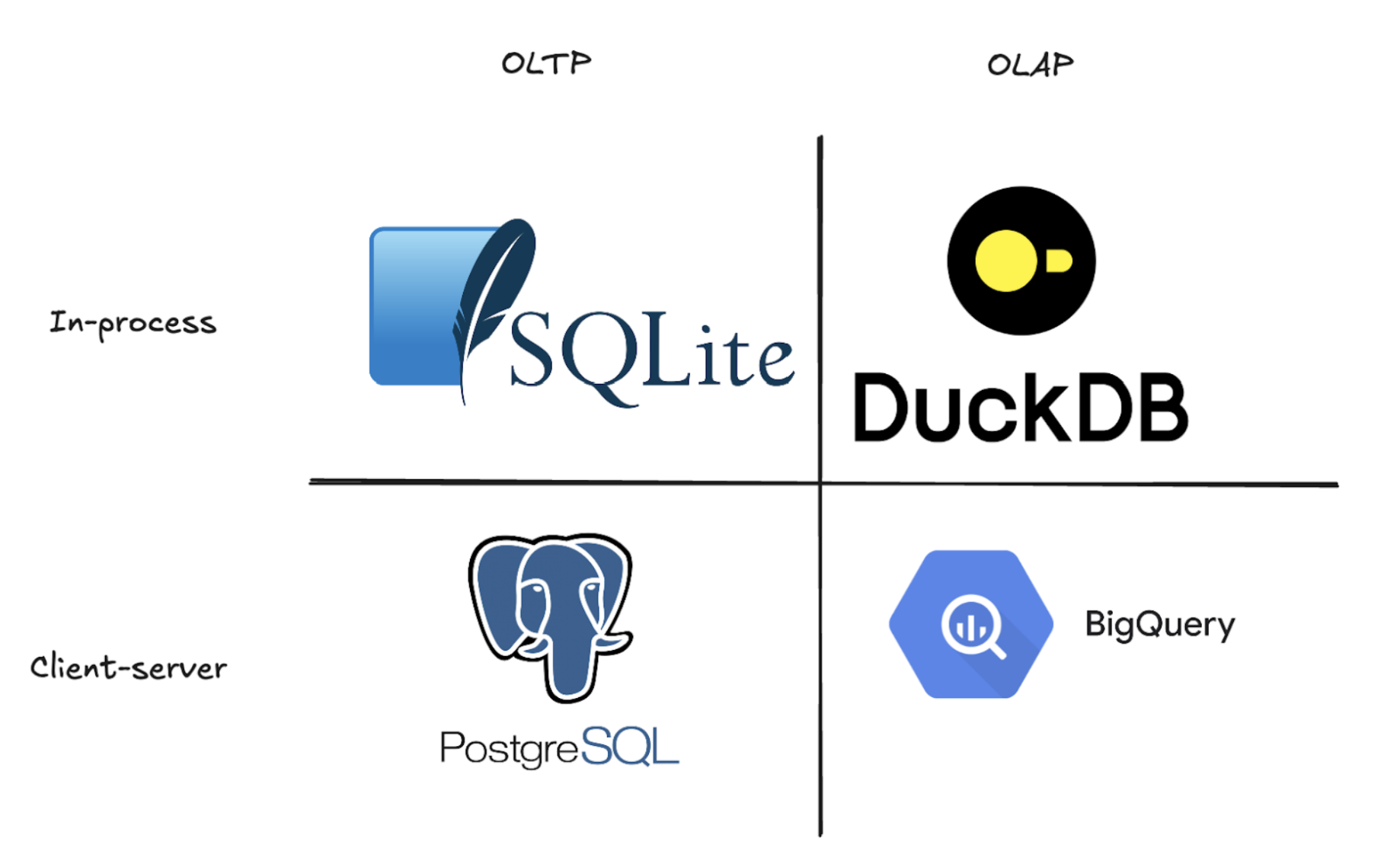
Da Sie nun wissen, was DuckDB ist, lassen Sie uns über seine Grenzen sprechen. Jede Technologie hat Kompromisse. DuckDB kann nur auf einem einzigen Rechner betrieben werden und akzeptiert jeweils nur eine Verbindung. In einer Welt, in der data-Teams cloud-native Lösungen für ganze Unternehmen entwickeln, ist dies eine ziemlich große Einschränkung. Es ist nicht möglich, dass mehrere Analysten gleichzeitig dieselbe DuckDB-Instanz abfragen, und schon gar nicht können Sie data-Sets in verschiedenen Teams gemeinsam nutzen, wie es bei einem herkömmlichen data-Warehouse möglich wäre. Bei aller Geschwindigkeit und Einfachheit sperrt DuckDB Ihr data im Wesentlichen auf einen Rechner, auf den jeweils nur eine Person Zugriff hat. Wie können Sie also diese unglaublich schnelle, aber von Natur aus auf einen einzigen Benutzer beschränkte data-Datenbank in ein cloud data-Warehouse verwandeln, das ein ganzes Unternehmen bedienen kann?
Die Ente, die das Fliegen lernte
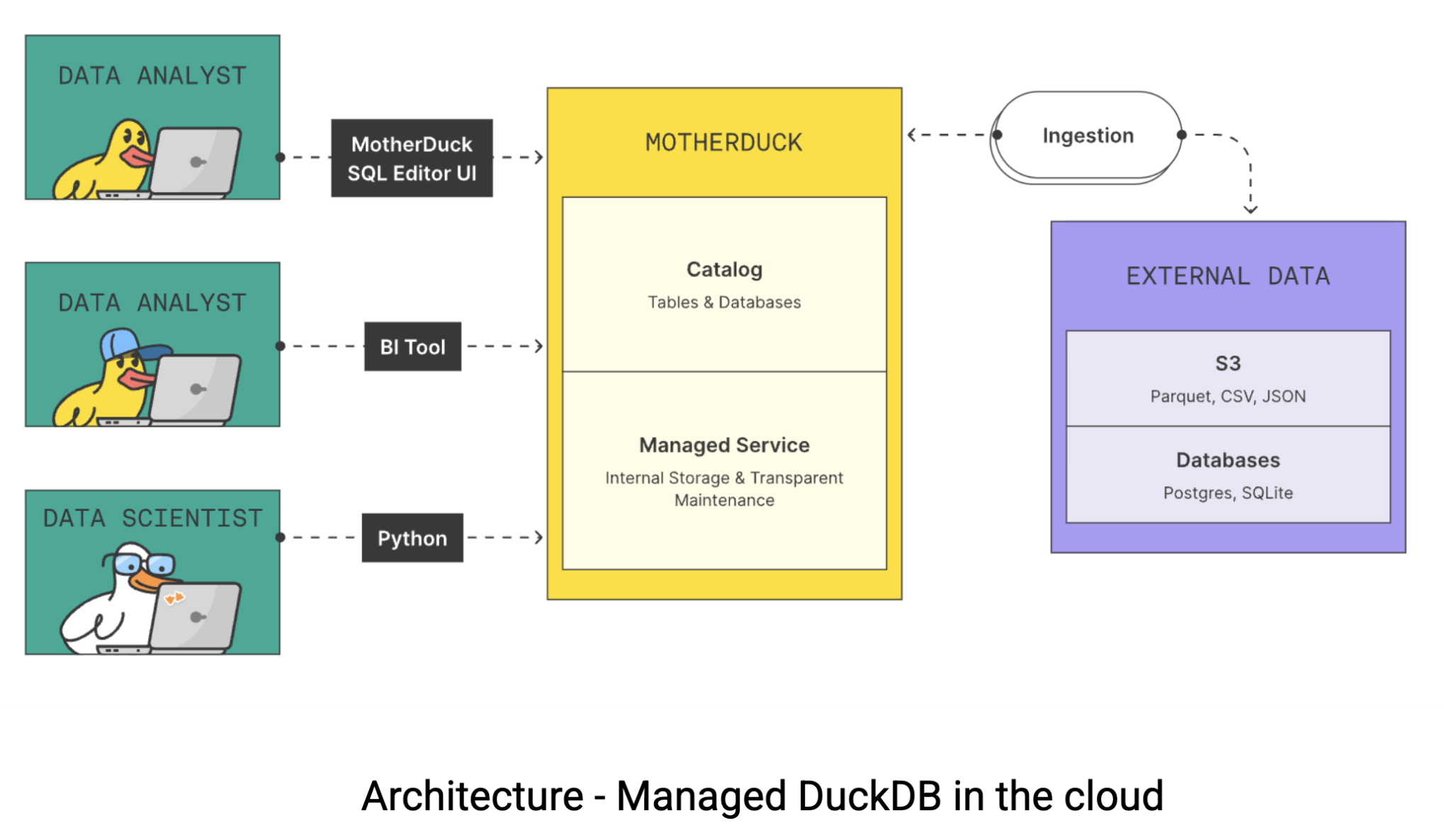
An dieser Stelle kommt MotherDuck ins Spiel. MotherDuck ist ein serverloses data-Warehouse, das die Lücke zwischen der reinen Leistung von DuckDB und den kollaborativen Anforderungen moderner data-Teams schließt. MotherDuck schafft ein, wie sie es nennen, “individualisiertes data-Warehouse für Analysen”, das jedem Benutzer seine eigene leistungsstarke DuckDB-Instanz zur Verfügung stellt und gleichzeitig die Möglichkeit bietet, data im gesamten Unternehmen gemeinsam zu nutzen. So funktioniert die Architektur:
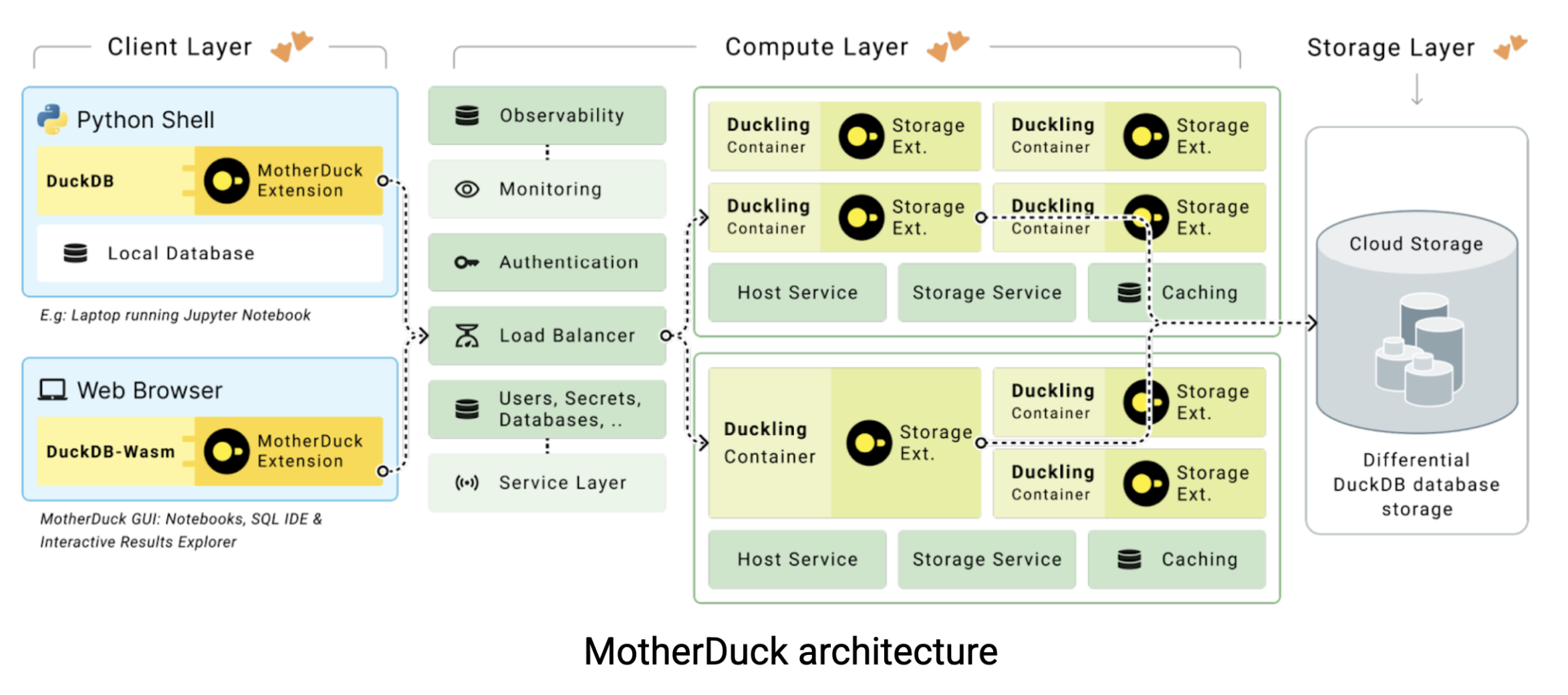
In traditionellen cloud data-Lagern ist Ihr Laptop nur ein dummes Terminal. Alle schweren Aufgaben werden auf entfernten Servern erledigt, für die Sie stundenweise bezahlen. Aber die Sache ist die: Ihr MacBook ist wahrscheinlich schneller als eine $20-60 pro Stunde data Lagerinstanz. MotherDuck versucht, diese Rechenleistung mit zwei innovativen Ansätzen zu nutzen:
- Browserbasierte Analytik die Berechnungen direkt zum Benutzer bringen.
- Doppelte Ausführung die auf intelligente Weise die Rechenleistung Ihres lokalen Rechners mit den Ressourcen des cloud kombiniert, um schneller Ergebnisse zu erzielen, als dies mit einem der beiden Ansätze allein möglich wäre.
Bevor ich auf diese beiden Methoden eingehe, möchte ich darauf hinweisen, dass die Rechenleistung von MotherDuck besonders gut zur Geltung kommt, wenn Sie sie auf Ihre Goldschicht. Für diejenigen, die mit dem Begriff nicht vertraut sind: Die Goldschicht ist das endgültige, geschäftsfähige data, das bereinigt, aggregiert und angereichert wurde. Im Wesentlichen handelt es sich um die ausgefeilten data-Sets, die Ihre Analysen, Berichte und das maschinelle Lernen unterstützen. Dies ist das data, das Ihre wichtigsten Geschäftsentscheidungen beeinflusst, so dass die Leistung hier absolut entscheidend ist. Jeder Stakeholder hat schon einmal unter quälend langsamen Dashboards gelitten, und jedes data-Teammitglied hat schon einmal auf das sich drehende Rad des Todes gestarrt, während es darauf wartete, dass komplexe Abfragen beendet wurden. MotherDuck geht diese Frustration frontal an.
In-Browser-Analysen
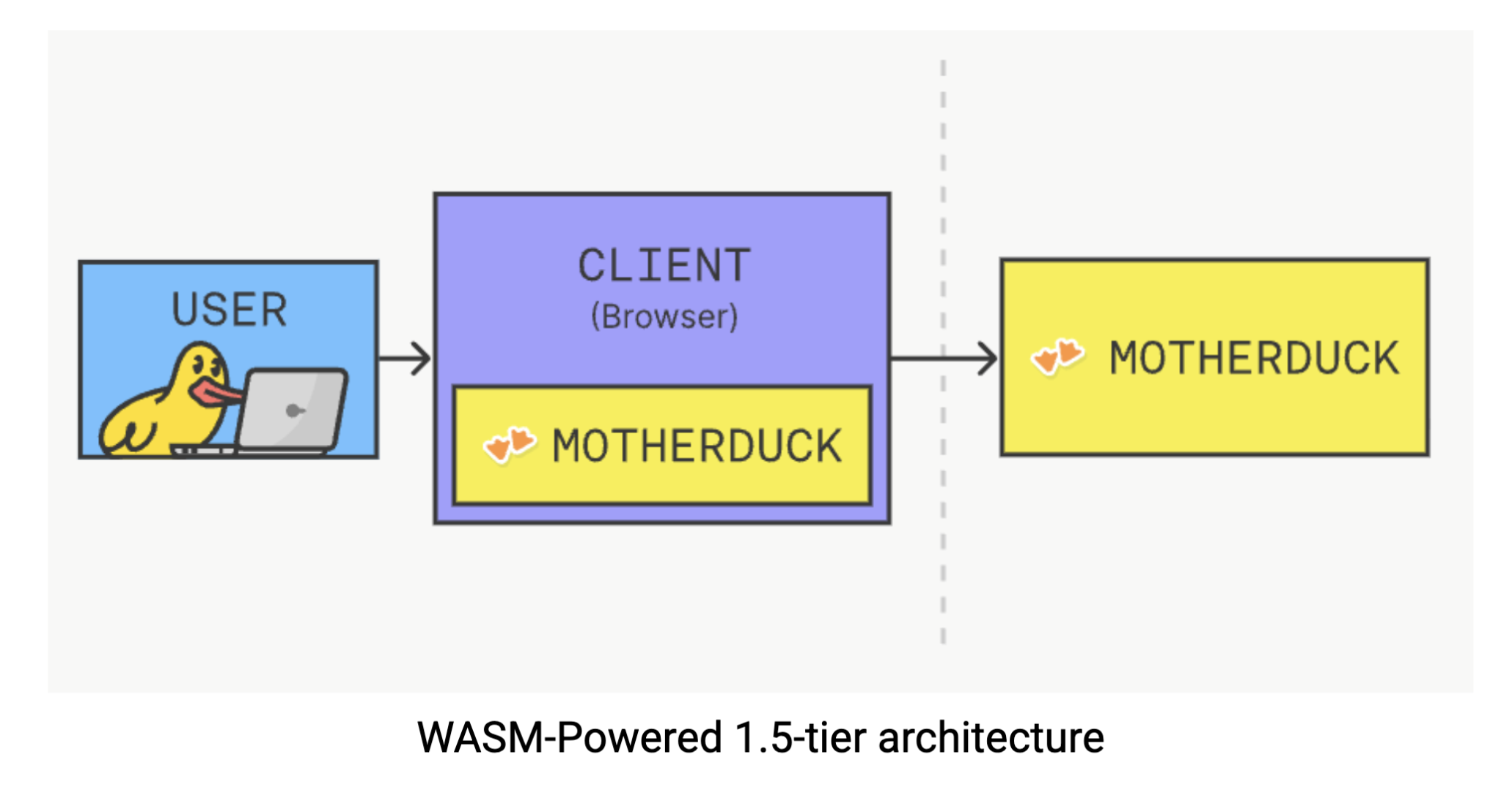
Diese Lösung nutzt das leichtgewichtige und portable Design von DuckDB, so dass sie über WebAssembly (Wasm) direkt in Ihrem Browser ausgeführt werden kann. Stellen Sie sich Wasm als eine Technologie vor, mit der komplexe Software nativ in Ihrem Browser ausgeführt werden kann: keine Plugins, keine Downloads, nur Rechenleistung, wo Sie sie am meisten brauchen. Mit DuckDB, das clientseitig ausgeführt wird, können Sie komplexe analytische Abfragen durchführen, ohne die übliche Prozedur, bei der Sie Anfragen an einen Server senden und auf Antworten warten müssen. Die data-Verarbeitung findet direkt in Ihrem Browser statt, wodurch die Netzwerklatenz entfällt und die Abhängigkeiten von der Infrastruktur vollständig reduziert werden. Sie können diese Magie selbst erleben, indem Sie Folgendes ausprobieren DuckDB in Ihrem Browser.
Wir werden hier nicht näher auf die technische Umsetzung eingehen, aber es ist erwähnenswert, dass sich DuckDB-Wasm auszeichnet. Ausführliche Forschung in dieses Papier zeigt, dass es bestehende browserbasierte Lösungen wie die Wasm-Version von SQLite oder Lovefield, eine JavaScript-basierte database, deutlich übertrifft. Diese clevere technische Demo signalisiert einen grundlegenden Wandel in der Art und Weise, wie wir über den Standort analytischer Berechnungen denken.
MotherDuck bietet diese von Wasm angetriebene Architektur, wie Mehdi Ouazza in dieser Artikel. Dieser Ansatz ist besonders leistungsfähig für die Goldschicht-Analyse. Ihr data-Team kann mit sauberem, geschäftsfähigem data arbeiten, ohne sich um die Backend-Infrastruktur kümmern zu müssen. Die Verarbeitung erfolgt lokal, um eine maximale Geschwindigkeit zu erreichen, und Sie erzielen einige der schnellsten Antwortzeiten, die möglich sind, indem Sie die Netzwerklatenz vollständig eliminieren. Außerdem vermeiden Sie die hohen Rechenkosten, die herkömmliche cloud data-Warehouses Ihnen gerne für jede Abfrage in Rechnung stellen. Das ist ein überzeugendes Angebot: schnellere Analysen, niedrigere Kosten und eine einfachere Architektur - alles in einem.
Doppelte Ausführung
Eine weitere Möglichkeit, MotherDuck in Ihrer Goldschicht zu nutzen, ist seine duale Ausführungsfähigkeit, die auf intelligente Weise lokale Rechenleistung mit cloud-Skalierung kombiniert. Anstatt Ihr gesamtes data-Team zu zwingen, sich dieselben Rechenressourcen zu teilen, gibt MotherDuck jedem Benutzer sein eigenes “Entlein”: eine individuelle, serverlose Recheninstanz, die mit seinen Bedürfnissen skaliert.
Die wahre Stärke der dualen Ausführung zeigt sich, wenn Sie mit data arbeiten, das über verschiedene Quellen verstreut ist. Stellen Sie sich vor, Sie müssen data, das in MotherDuck gespeichert ist, abfragen, es mit Dateien in S3 kombinieren und es mit einem data-Set verbinden, das sich lokal auf Ihrem Laptop befindet. Herkömmliche cloud-Systeme würden Sie dazu zwingen, alles an einem Ort hochzuladen, bevor Sie quellenübergreifende Abfragen durchführen können. Die hybride Ausführung von MotherDuck ist intelligenter. Sie analysiert Ihre Abfrage, behält nur die notwendigen data aus jeder Quelle und führt intelligente Verknüpfungen zwischen den Standorten durch, wodurch Sie Zeit und data-Übertragungskosten sparen.
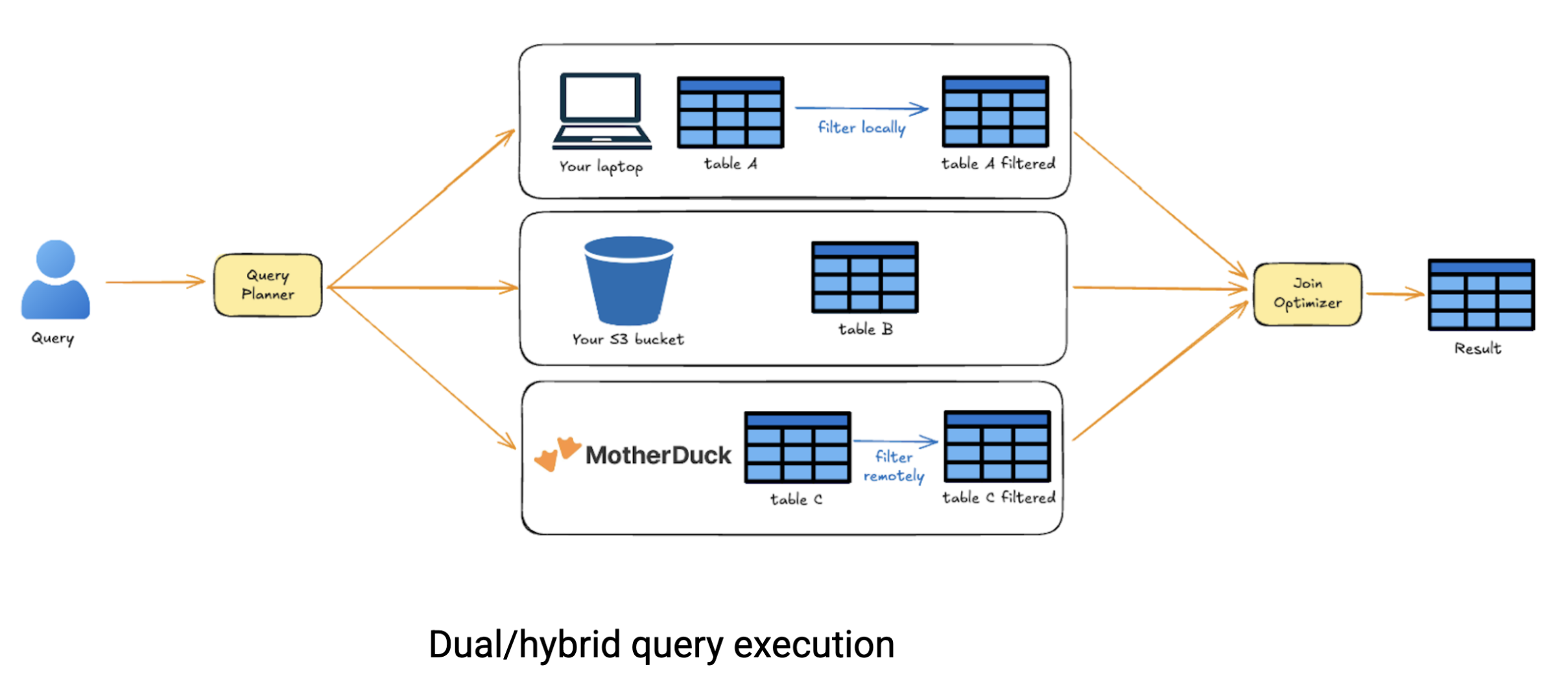
Unter der Haube zerlegt der Optimierer von MotherDuck Ihre Abfrage in einen DAG (gerichteten azyklischen Graphen) von Operationen, schätzt die Kosten für die Ausführung jedes Knotens vor Ort gegenüber der Ausführung aus der Ferne ab und behandelt data-Bewegungen automatisch. Sie schreiben einfach SQL, MotherDuck ermittelt die optimale Ausführungsstrategie. Dieser Ansatz definiert die cloud-Analytik grundlegend neu. Wir müssen uns nicht mehr zwischen lokaler Einfachheit und cloud-Skalierbarkeit entscheiden, die jeweils ihre eigene Komplexität in Bezug auf data-Sharing und Workflow-Orchestrierung mit sich bringen. Mit MotherDuck erhalten Sie das Beste aus beiden Welten: Sie können lokal arbeiten, wenn Ihr Rechner damit zurechtkommt, bei Bedarf auf cloud skalieren und mühelos gemeinsam nutzen. Es handelt sich um eine serverlose Lösung, die die cloud-Rechenkosten senkt, weil Sie nur für das zahlen, was Sie tatsächlich berechnen.
Aber jetzt wird es interessant: Die gemeinsame Nutzung von data wird mühelos. Erinnern Sie sich noch daran, dass die Zusammenarbeit mit DuckDB aufgrund der Einzelplatznutzung mühsam war? Wenn ein data-Analyst eine großartige Analyse erstellte, musste er alles exportieren und auf ein gemeinsames Speichersystem hochladen, nur damit seine Kollegen darauf zugreifen konnten. Mit MotherDuck ist die gemeinsame Nutzung so einfach wie das Klicken auf eine Schaltfläche oder das Ausführen einer einzigen Codezeile, um einen Null-Kopie-Snapshot mit entsprechenden Zugriffskontrollen zu erstellen. Keine data-Bewegung, keine Speicherduplizierung, nur sofortige Zusammenarbeit.
Erfahren Sie mehr über Dual/Hybrid Query Execution in MotherDuck's Paper von die Konferenz über innovative Data-Systemforschung (CIDR). Sie können auch dies sehen dbt Coalesce talk von Jordan Tigani, Mitbegründer und CEO von MotherDuck.
Enten in freier Wildbahn
Wir haben gesehen, wie MotherDuck den data-Teams erheblichen Overhead abnimmt und gleichzeitig leistungsstarke Analysefunktionen für Ihre Goldschicht bereitstellt. Aber die Theorie geht nur so weit. Wir wollten MotherDuck im Vergleich zu etablierten Anbietern im Bereich cloud data-Lager testen. Ein Blick auf die Data Stack Bericht von 2025 veröffentlicht von Metabase, haben wir etwas Überraschendes herausgefunden: PostgreSQL ist nach wie vor die beliebteste database-Wahl, auch für analytische Arbeitslasten, gefolgt von Snowflake und BigQuery bei den befragten Unternehmen. Dies hat uns zu unseren Vergleichszielen geführt.
Wir haben beschlossen, MotherDuck mit gehostetem PostgreSQL auf Google Cloud und BigQuery zu vergleichen, indem wir Apache Superset als unser BI-Tool der Wahl. Superset bot sich aus mehreren Gründen an: Es ist Open Source, weit verbreitet und nativ mit MotherDuck und den meisten anderen wichtigen data-Basen kompatibel. Unsere Testumgebung bestand aus Apache Superset, das auf der Google Cloud Kubernetes Engine eingesetzt wurde und mit drei verschiedenen Backends verbunden war: BigQuery, PostgreSQL auf Cloud SQL und MotherDuck.
Wir haben unsere Tests in zwei Phasen unterteilt. Zunächst führten wir den TPC-H-Benchmark durch: ein standardisierter Benchmark zur Entscheidungsunterstützung, der uns zeigen sollte, wie MotherDuck in einer kontrollierten, theoretischen Umgebung abschneidet. Dann gingen wir näher an die Realität heran und testeten, wie sich die Beziehung zwischen Superset und MotherDuck im Vergleich zu herkömmlichen data-Warehouses in realen Dashboarding-Szenarien darstellt.
TPC-H-Benchmarking
TPC-H ist der Standard für das Testen der analytischen Leistung von database. Es ist ein Benchmark zur Entscheidungsunterstützung, der entwickelt wurde, um große Mengen von data zu untersuchen, komplexe Abfragen auszuführen und Antworten auf kritische Geschäftsfragen in verschiedenen Branchen zu liefern. Die vollständige Spezifikation finden Sie in der offizielle Dokumentation. Der Benchmark besteht aus 22 Abfragen, die reale analytische Arbeitslasten simulieren, von einfachen Aggregationen bis hin zu komplexen Multi-Table-Joins.
Wir haben jede Abfrage einzeln durch das SQL-Labor von Superset für alle drei data-Basen laufen lassen: MotherDuck, BigQuery und PostgreSQL. Wir haben die Abfragen auch direkt in der grafischen Benutzeroberfläche von MotherDuck getestet, um die Client-Server-Latenz auszuschalten und weil, ehrlich gesagt, jedes Unternehmen, das MotherDuck einsetzt, seine data-Analysten wahrscheinlich eher in der vom Notizbuch inspirierten Oberfläche von MotherDuck arbeiten lässt als im SQL Lab von Superset. Außerdem kann die MotherDuck-Anwendung die WebAssembly-Architektur nutzen, die wir bereits besprochen haben, und wir waren neugierig, wie diese browserbasierte Ausführung im Vergleich zu herkömmlichen Server-Client-Modellen abschneiden würde. Um faire Tests zu gewährleisten, war der Cache von Superset während aller Benchmarks deaktiviert.
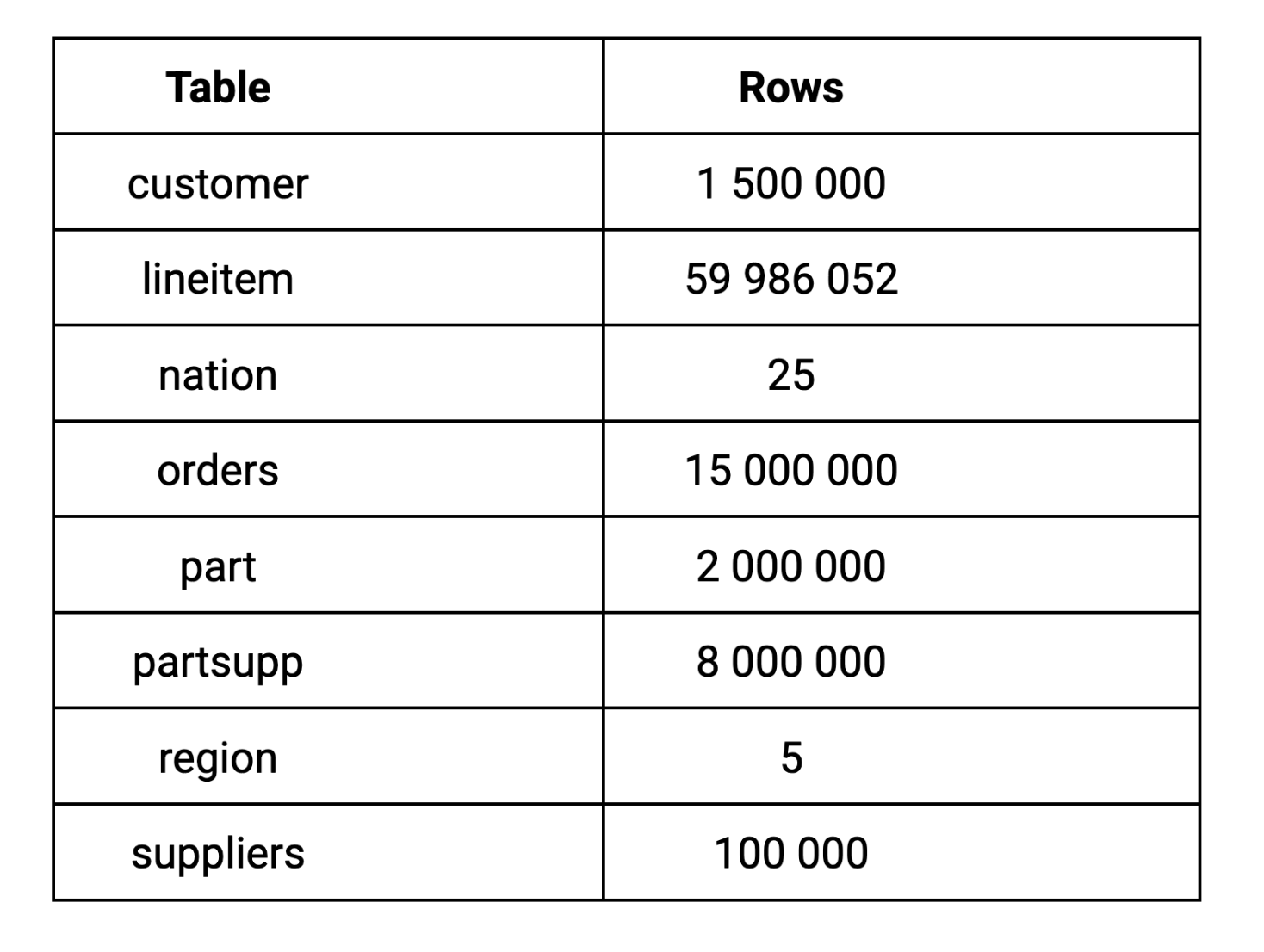
Für diesen Benchmark haben wir den TPC-H Skalierungsfaktor 10 (SF-10) verwendet, der ein 10 GB großes dataset erzeugt. Wir haben uns für den Skalierungsfaktor 10 entschieden, weil 10 GB eine realistische dataset-Größe für die analytischen Arbeitslasten der meisten Unternehmen darstellt, die groß genug ist, um aussagekräftige Leistungsunterschiede zu erkennen, ohne dass eine Infrastruktur im Unternehmensmaßstab erforderlich ist. Hier sehen Sie, wie sich das data auf die wichtigsten Tabellen verteilt:
Wir haben die DuckDB TPC-H-Erweiterung verwendet, um die data lokal zu generieren, und sie dann nahtlos auf MotherDuck hochgeladen. Dank der data-Ladefunktionen von MotherDuck dauerte dieser Vorgang nur wenige Minuten.
Hier sind die TPC-H SF-10 Ergebnisse in Sekunden. Die gelbe Spalte zeigt die Ergebnisse der nativen Benutzeroberfläche der MotherDuck-App, während die anderen Spalten die Leistung des SQL-Labors von Superset (SST) darstellen:
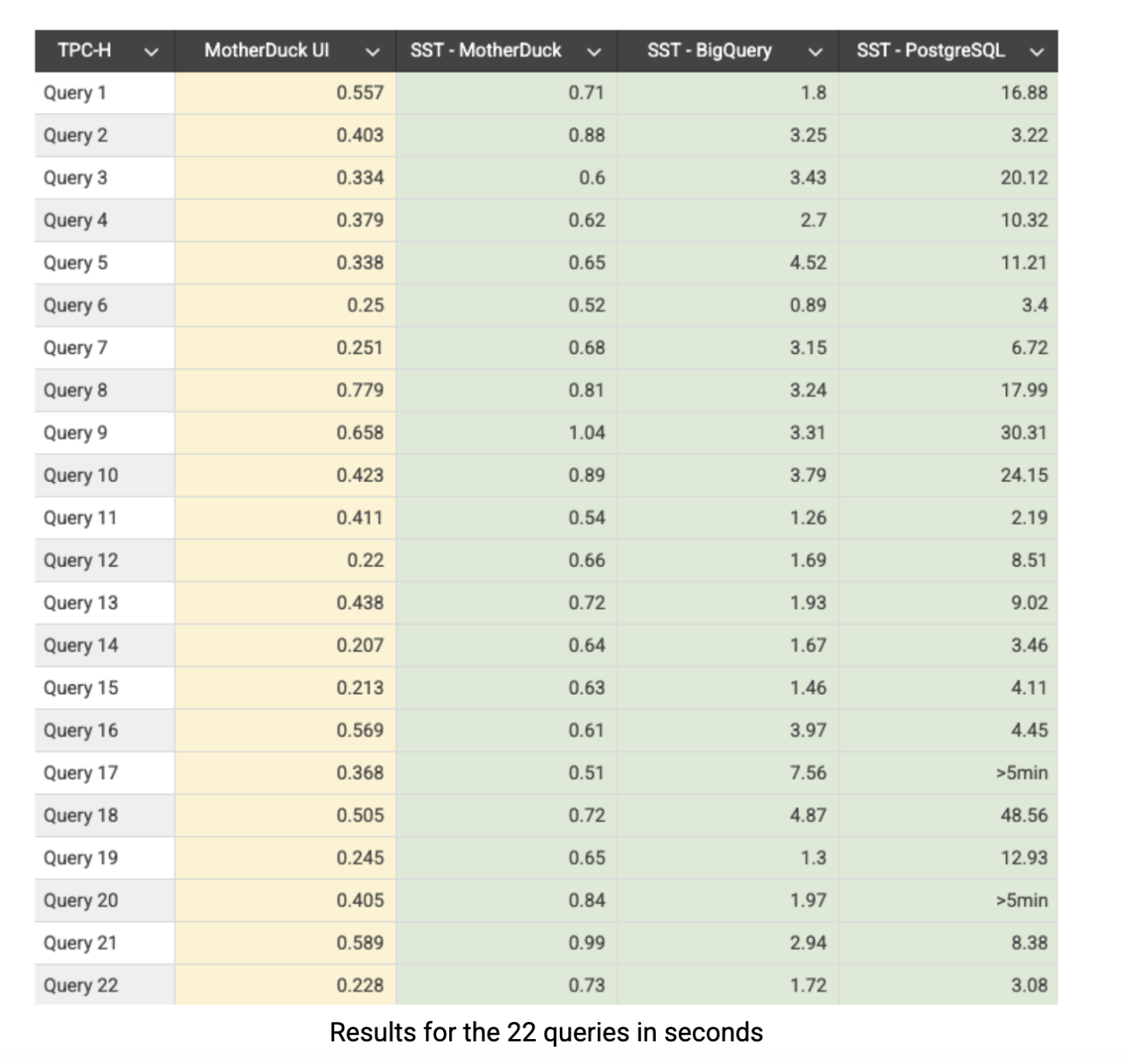
MotherDuck liefert durchgängig eine Leistung im Sekundenbereich: 21 von 22 Abfragen über Superset in weniger als einer Sekunde abgeschlossen, wobei alle Abfragen in weniger als einer Sekunde abgeschlossen werden, wenn sie direkt über die MotherDuck-App ausgeführt werden. BigQuery zeigt eine respektable Leistung, aber im Durchschnitt etwa 4x langsamer als MotherDuck in der gesamten Benchmark-Suite. Bei PostgreSQL sieht das ganz anders aus. Hier ist die Leistung deutlich langsamer und es gibt deutliche Probleme bei komplexen Aggregationen und Joins. Dies war vorhersehbar, da PostgreSQL grundsätzlich für OLTP-Arbeitslasten und nicht für die analytische Verarbeitung konzipiert ist, aber wir haben es in unseren Vergleich einbezogen, weil es von Unternehmen nach wie vor häufig für analytische Aufgaben verwendet wird. Es ist erwähnenswert, dass PostgreSQL mit geeigneten Optimierungstechniken wie Indizierung, Partitionierung oder materialisierten Ansichten eine viel bessere Leistung erzielen könnte, aber selbst dann würde es immer noch gegen seine zeilenbasierte Architektur ankämpfen. Der Leistungsunterschied macht deutlich, warum es speziell entwickelte OLAP-Systeme wie MotherDuck gibt: Wenn Sie komplexe analytische Abfragen auf umfangreichen data-Sets ausführen, ist die Architektur von enormer Bedeutung.
TPC-H zeigt zwar die reine Abfrageleistung an, aber der eigentliche Test ist, wie sich dies auf die tatsächliche Benutzererfahrung in Business Intelligence-Tools auswirkt.
Dashboard Leistung
Wir haben gesehen, dass die Leistung für data-Analysten, die mit SQL auf ihrem data-Warehouse arbeiten, hervorragend war, aber wir wollten testen, ob sich diese Verbesserung auch auf das Dashboarding übertragen lässt, also auf den Bereich, in dem die Geschäftsinteressenten tatsächlich mit dem data interagieren. Schließlich nützen blitzschnelle SQL-Abfragen nicht viel, wenn Ihre Dashboards immer noch ewig zum Laden brauchen.
Um dies zu testen, haben wir ein realistisches E-Commerce dataset von Kaggle mit 67,5 Millionen Zeilen auf 9 GB data, der Größenordnung, mit der viele Unternehmen für ihre monatlichen Kundenanalysen arbeiten. Anhand dieser einzigen Tabelle erstellten wir ein umfassendes Dashboard, mit dem wir die Fähigkeit der einzelnen Systeme zur Bewältigung realer Business Intelligence-Arbeitslasten testen konnten:
Ich habe das Dashboard in mehreren Durchläufen ausgiebig getestet und dabei verschiedene Filter angewendet, Ladezeiten gemessen, den Cache deaktiviert und die Reaktionszeiten über die Entwickler-Tools meines Browsers überwacht. Nach mehreren Testzyklen, um konsistente Ergebnisse sicherzustellen, sind hier die Dashboard-Leistungskennzahlen in Sekunden:
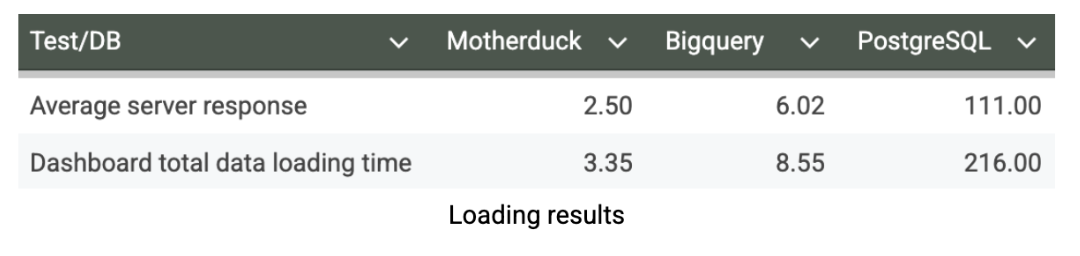
Unsere Dashboard-Ladetests zeigen, welche praktischen Auswirkungen die Leistung von database auf die Benutzererfahrung hat. MotherDuck bietet eine außergewöhnliche Reaktionsfähigkeit des Dashboards mit einer durchschnittlichen Ladezeit von nur 3,35 Sekunden und ermöglicht so wirklich interaktive Analysen, bei denen die Benutzer data ohne Reibungsverluste erkunden können. Im Gegensatz dazu benötigt BigQuery 8,55 Sekunden, um dasselbe Dashboard zu laden. Das ist für geplante Berichte noch akzeptabel, führt aber zu spürbaren Verzögerungen, die von explorativen Analysen abhalten können. Die Ladezeit von PostgreSQL von 216 Sekunden (>3 Minuten) macht es für die Verwendung in Dashboards völlig unpraktisch. Dieser Leistungsvorteil für MotherDuck kann die Art und Weise, wie Geschäftsanwender mit data interagieren, grundlegend verändern. Wenn Dashboards in Sekunden statt in Minuten geladen werden, steigt die Akzeptanz bei den Anwendern, können Analysten schnell auf Erkenntnisse zurückgreifen und die Analyse wird zu einem Wettbewerbsvorteil und nicht zu einem Engpass.
Vergleich der Preise
MotherDuck kombiniert Speicherung mit Umlageverfahren Rechenleistung, optimiert für interaktive Analysen. Da die Skalierung auf einem einzigen Rechner erfolgt, anstatt über einen Cluster verteilt zu werden, wird der Overhead vermieden, für den die Benutzer letztendlich bezahlen. Eine Sitzung mit Dutzenden von Abfragen kostet vielleicht nur $0,05-$0,10, während ein Team, das monatlich Tausende von Abfragen durchführt, vielleicht nur $20-$40 ausgibt. Im Gegensatz dazu können data-Basen, die ständig in Betrieb sind, $300-$500/Monat kosten, nur um in Betrieb zu bleiben, und cloud-Lagerhäuser berechnen oft $5-$10 pro gescanntem TB. Mit seinem Scale-up-Design hält MotherDuck die Preisgestaltung einfach, vorhersehbar und kosteneffizient.

MotherDuck mag auf den ersten Blick teurer erscheinen, weil es eine Organisationsgebühr und ein anderes Preismodell für die Datenverarbeitung hat. Beide Systeme verwenden jedoch Preismodelle, die unterschiedliche Nutzungsmuster begünstigen: BigQuery eignet sich hervorragend für die Verarbeitung großer Stapel, während MotherDuck für interaktive Analysen optimiert ist. Bei unserem TPC-H-Benchmark kostete die Ausführung von 22 Abfragen auf SF-10 $0,03 für MotherDuck gegenüber $0,60-$1,00 für BigQuery. Berücksichtigt man den Infrastruktur-Overhead - unser PostgreSQL-Setup benötigte 14 €/Tag, nur um online zu bleiben -, so liefert der serverlose Ansatz von MotherDuck oft bessere Gesamtbetriebskosten für interaktive analytische Workloads.
Im Unternehmensmaßstab verschiebt sich die Wirtschaftlichkeit je nach Nutzungsmuster. BigQuery wird kosteneffizienter für die Batch-Verarbeitung in sehr großen Mengen, während MotherDuck seinen Vorteil für interaktive Analysen und explorative Workflows beibehält. Die wichtigste Erkenntnis: Wählen Sie Ihr Preismodell auf der Grundlage der Art und Weise, wie Ihr Team tatsächlich mit data arbeitet, und nicht nur auf der Grundlage der Rohkosten pro Einheit.
Hinweis: Alle Preisbeispiele basieren auf der Region Europa-West4 und sollten eher als illustrativ denn als exakt angesehen werden, da die tatsächlichen Kosten stark von den spezifischen Nutzungsmustern und den Eigenschaften des data abhängen.
Fazit
MotherDuck stellt einen grundlegenden Wandel in der Art und Weise dar, wie wir über analytische data-Basen denken. Es stellt die Annahme in Frage, dass Sie komplexe, verteilte Systeme benötigen, um ernsthafte data-Workloads zu bewältigen. MotherDuck übernimmt die eingebettete Philosophie von DuckDB und erweitert sie auf den cloud. Damit bietet MotherDuck die kollaborativen Fähigkeiten, die moderne data-Teams benötigen, und behält gleichzeitig die Leistung bei, die DuckDB so außergewöhnlich macht.
Unsere Benchmarking-Ergebnisse erzählen eine überzeugende Geschichte: MotherDuck übertraf sowohl BigQuery als auch PostgreSQL durchgängig um ein Vielfaches und lieferte eine Abfrageleistung von weniger als einer Sekunde bei 10GB datasets und Dashboard-Ladezeiten, die wirklich interaktive Analysen ermöglichen. Der Leistungsvorteil gegenüber BigQuery und der sehr große Vorteil gegenüber PostgreSQL in Dashboard-Szenarien bezieht sich nicht nur auf schnellere Abfragen, sondern auf die Umwandlung von Analysen in ein interaktives, exploratives Erlebnis, das die data-driven Entscheidungsfindung fördert.
Am wichtigsten ist vielleicht, dass MotherDuck diese Leistung erreicht und gleichzeitig die Komplexität der Infrastruktur und die Kosten drastisch reduziert. Während herkömmliche cloud-Setups eine ständig verfügbare Infrastruktur erfordern, die monatlich Hunderte von Dollar kostet, wird beim serverlosen Modell von MotherDuck nur die tatsächliche Nutzung berechnet, was die Kosten oft senkt. Das Pay-per-Compute-Preismodell entspricht genau der Arbeitsweise von Analysten: Sie führen mehrere Abfragen in Explorationssitzungen durch und nicht nur einzelne, seltene Anfragen.
Die Auswirkungen gehen über die reine Leistung und die Kosten hinaus. Das duale Ausführungsmodell von MotherDuck und die browserbasierten Analysefunktionen deuten auf eine Zukunft hin, in der die Grenze zwischen lokalem und cloud-Computing zunehmend fließend wird. Anstatt Teams zu zwingen, sich zwischen lokaler Einfachheit und cloud-Skalierbarkeit zu entscheiden, bietet MotherDuck beides und leitet Berechnungen auf intelligente Weise dorthin, wo sie am sinnvollsten sind.
Was mich beim Testen wirklich beeindruckt hat, war die Einfachheit der Nutzung und Einrichtung von MotherDuck. Das duale Ausführungsmodell ermöglichte es mir, die data sowohl lokal als auch im cloud gleichzeitig abzufragen, während die Einrichtung der Verbindung zwischen Superset und MotherDuck bemerkenswert einfach war.
Für Unternehmen, die ihre analytischen Fähigkeiten ab der Goldschicht modernisieren möchten, bietet MotherDuck ein sehr attraktives Angebot: Leistung auf Unternehmensniveau, kollaborative Arbeitsabläufe und Kosteneffizienz, und das alles ohne den operativen Aufwand einer herkömmlichen data-Warehouse-Infrastruktur. In einer Welt, in der data-driven-Entscheidungen zunehmend den Wettbewerbsvorteil bestimmen, ist die Fähigkeit, data interaktiv und in Sekundenschnelle zu erforschen, nicht nur ein Nice-to-have, sondern wird immer wichtiger.
Sind Sie bereit, die Performance von MotherDuck selbst zu erleben? Sie können mit einer 21-tägige kostenlose Testversion oder mit dem kostenlosen 10GB-Tarif um es mit Ihren eigenen data-Sets und Workloads zu testen. Wenn Sie wissen möchten, ob MotherDuck zu Ihrem speziellen data-Stack passt, oder wenn Sie Hilfe bei der Implementierung benötigen, wenden Sie sich an unser Team unter Artefact, Wir würden uns freuen, Ihren Analysebedarf zu ermitteln und Ihnen bei der Umstellung auf eine effizientere und kostengünstigere Analyseinfrastruktur zu helfen.
