


Resumo executivo
A MotherDuck estende o desempenho analítico do DuckDB para o cloud com recursos colaborativos, oferecendo desempenho 4x mais rápido do que o BigQuery e economia de custos em relação aos armazéns data tradicionais por meio de preços sem servidor e de pagamento por uso. Após o anúncio da nova região europeia do cloud da MotherDuck, ficamos impressionados com seu desempenho e preço atraente. A MotherDuck já pode ser integrada às suas camadas de ouro para acelerar o atendimento de casos de uso de data e, ao mesmo tempo, economizar custos. Veja o benchmark de desempenho.
Introdução
No cenário em rápida evolução da análise data, um novo participante está desafiando a ordem estabelecida dos armazéns cloud data. MãePato, construído sobre a base de DuckDB‘promete oferecer desempenho de nível empresarial com a simplicidade e a economia que as equipes data modernas desejam. Mas será que esse pato pode realmente competir com os gigantes estabelecidos?
Colocamos o MotherDuck em testes rigorosos com concorrentes estabelecidos para ver se ele está à altura da propaganda. O que descobrimos desafia o status quo atual das bases data analíticas e sugere uma mudança fundamental na forma como abordamos o processamento data baseado em cloud. Esta é a história de como um database incorporado aprendeu a voar e por que ele pode revolucionar sua pilha de data.
Para conquistar esse cliente em evolução, os varejistas precisam se adaptar rapidamente.
Um pato chocando
MãePato descreve-se como um “armazém DuckDB cloud data escalonável até terabytes para análise e BI voltados para o cliente”. Para entender o que torna esse warehouse cloud data especial, primeiro precisamos analisar o DuckDB, DuckDB, o sistema database de código aberto que vem revolucionando discretamente a pilha data nos últimos anos. Em termos simples, o DuckDB é um sistema database SQL OLAP em memória. Para aqueles que não vivem e respiram o jargão do database, vamos explicar o que isso realmente significa:
OLAP significa Online Analytical Processing (processamento analítico on-line). Pense nele como um database projetado para processar grandes quantidades de data e responder rapidamente a perguntas comerciais complexas. Diferentemente dos bancos de dados data tradicionais, que são excelentes para encontrar registros individuais (como procurar o pedido de um cliente), os bancos de dados data OLAP são criados para examinar milhões de linhas e realizar cálculos pesados em segundos. Eles atingem essa velocidade armazenando o data em colunas em vez de linhas, o que torna extremamente rápida a análise de tendências, o cálculo de médias ou a soma de vendas em conjuntos inteiros de data. Essa é a mesma abordagem usada pelos modernos armazéns de data, como BigQuery ou Snowflake. Por outro lado, o senhor tem bases de dados data OLTP (Online Transaction Processing) como PostgreSQL, SQLite ou MySQL. Esses são os cavalos de batalha que alimentam seus aplicativos, lidando com milhares de leituras e gravações individuais por segundo para manter o aplicativo funcionando sem problemas. Veja mais sobre OLAP vs OLTP.
Para entender como a abordagem do DuckDB é realmente revolucionária, precisamos dar um passo atrás e ver como chegamos até aqui. Em meados da década de 1990, quando gigantes da Web como Yahoo e Amazon entraram em cena, eles atingiram um obstáculo que reformularia todo o cenário do data. Essas empresas estavam se afogando em data, o que mais tarde chamaríamos de “grande data”, e seus sistemas existentes simplesmente não conseguiam acompanhar. A solução? Infraestruturas caras e monolíticas que podiam lidar com a escala. Mas como os custos de hardware despencaram nos anos 2000, surgiu uma nova filosofia: em vez de comprar máquinas maiores, por que não usar várias máquinas menores e mais baratas? Esse pensamento deu origem a sistemas distribuídos como o MapReduce e o Apache Hadoop, tecnologias projetadas para distribuir cargas de trabalho em clusters de hardware de commodity. A Amazon capitalizou essa tendência, empacotando essas tecnologias distribuídas como serviços e lançando o Amazon Web Services, a primeira grande plataforma cloud. Durante anos, esse se tornou o manual padrão: quando o senhor encontrava um problema de data, distribuía-o em mais máquinas (Fundamentals of Data Engineering, Joe Reis & Matt Housley).
Mas eis o que é fascinante: enquanto todos estavam ocupados criando sistemas distribuídos, outra coisa estava acontecendo silenciosamente em segundo plano. As mesmas forças que tornaram a computação distribuída econômica, também tornaram as máquinas individuais incrivelmente poderosas. Seu laptop atual tornou-se incrivelmente poderoso com mais RAM, processadores mais rápidos e melhor armazenamento. Os desenvolvedores por trás do DuckDB reconheceram essa oportunidade negligenciada: e se, em vez de sempre aumentar a escala, pudéssemos aumentar a escala de forma mais inteligente? E se pudéssemos resolver muitos problemas data sem a complexidade dos sistemas distribuídos?
Um dos motores database mais utilizados no mundo, Em um ambiente de trabalho com um sistema de gerenciamento de dados, o SQLite adota uma abordagem radicalmente diferente das bases data tradicionais. Enquanto o PostgreSQL e o MySQL são executados como servidores separados aos quais os aplicativos se conectam por meio de uma rede, o SQLite é incorporado diretamente ao seu aplicativo como uma biblioteca leve. Não há nenhum servidor a ser configurado, nenhuma sobrecarga de rede e nenhuma instalação complexa, apenas a funcionalidade pura e local do database que é executada no processo do seu aplicativo. Essa simplicidade, combinada com confiabilidade e velocidade notáveis, tornou o SQLite onipresente em tudo, desde aplicativos móveis até navegadores da Web.
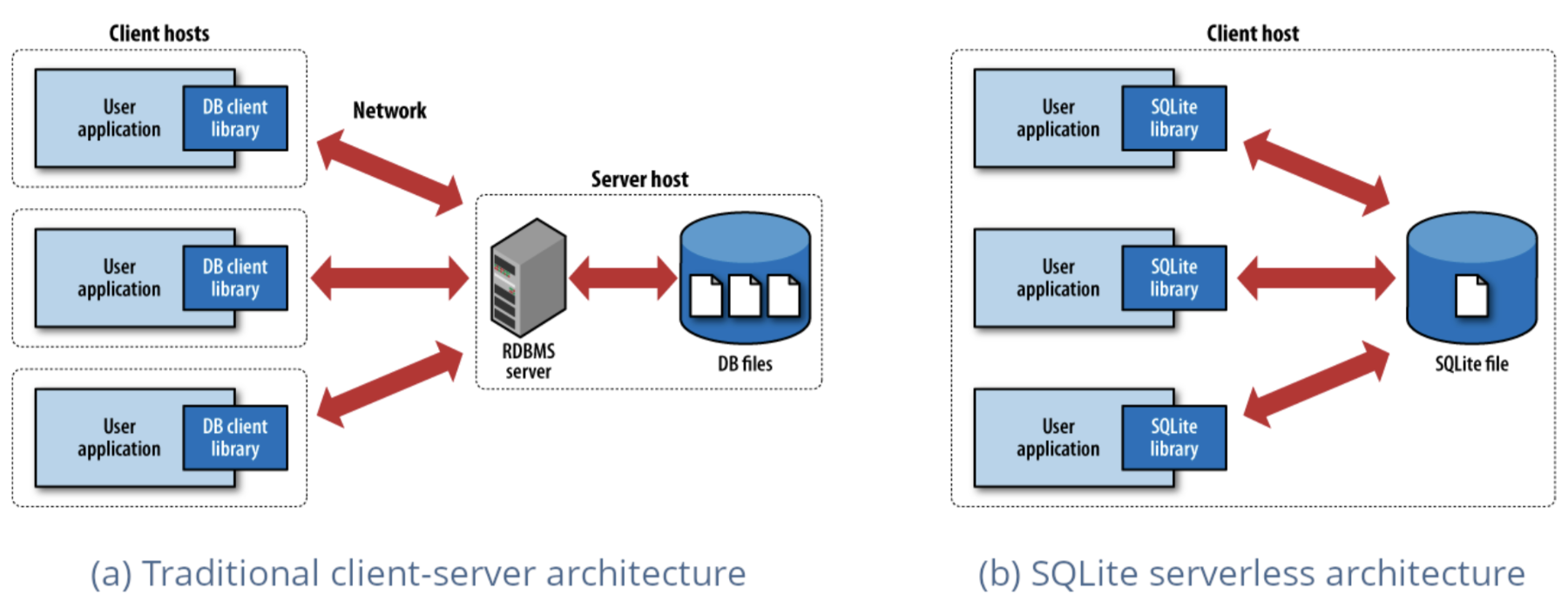
O DuckDB aplica essa mesma filosofia incorporada a cargas de trabalho analíticas, provando que o senhor nem sempre precisa de um sistema distribuído para analisar grandes conjuntos de data. Assim como o SQLite revolucionou o armazenamento local de data, o DuckDB aproveita o poder bruto de sua máquina local para tornar a análise simples novamente. A instalação leva segundos, não há dependências externas com as quais se preocupar e, de repente, o senhor está executando consultas analíticas complexas em gigabytes de data sem rodar uma única instância de cloud.
O que torna o DuckDB particularmente atraente é a forma como ele atende aos desenvolvedores onde eles estão. O senhor precisa analisar um quadro Python DataFrame? O DuckDB pode consultá-lo diretamente. Deseja analisar um arquivo CSV? Não tem problema. Essa integração perfeita, combinada com seu mecanismo colunar extremamente rápido, fez do DuckDB um dos sistemas database de crescimento mais rápido no espaço de análise. Os ganhos de desempenho são, muitas vezes, suficientemente significativos para fazer com que o senhor se pergunte por que estava usando sistemas distribuídos. Se o senhor quiser se aprofundar na filosofia técnica por trás dessa abordagem, recomendamos a leitura de “Gerenciamento analítico em processo Data com DuckDB” pelo cocriador do DuckDB, Hannes Mühleisen.
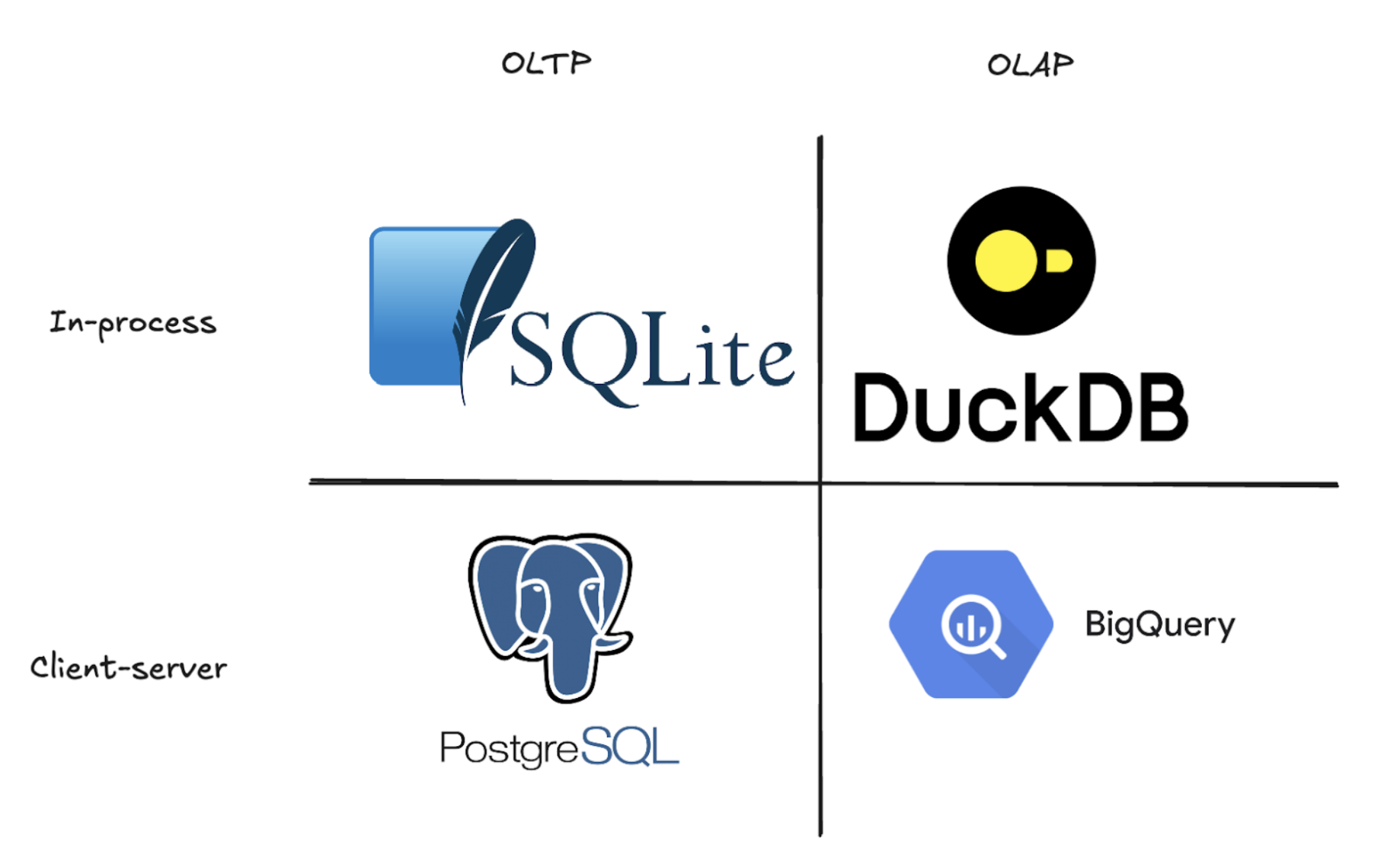
Agora que o senhor já sabe o que é o DuckDB, vamos falar sobre suas limitações. Toda tecnologia tem desvantagens. O DuckDB só pode operar em uma única máquina e aceita apenas uma conexão por vez. Em um mundo em que as equipes do data criam soluções nativas do cloud que atendem a organizações inteiras, essa é uma restrição bastante significativa. Não é possível ter vários analistas consultando a mesma instância do DuckDB simultaneamente e, certamente, não é possível compartilhar datasets entre as equipes da mesma forma que seria possível com um warehouse data tradicional. Apesar de toda a sua velocidade e simplicidade, o DuckDB essencialmente bloqueia seu data em uma máquina, acessível a uma pessoa de cada vez. Então, como o senhor pega esse banco de dados data incrivelmente rápido, mas inerentemente de usuário único, e o transforma em um depósito data cloud que pode atender a uma organização inteira?
O pato que aprendeu a voar
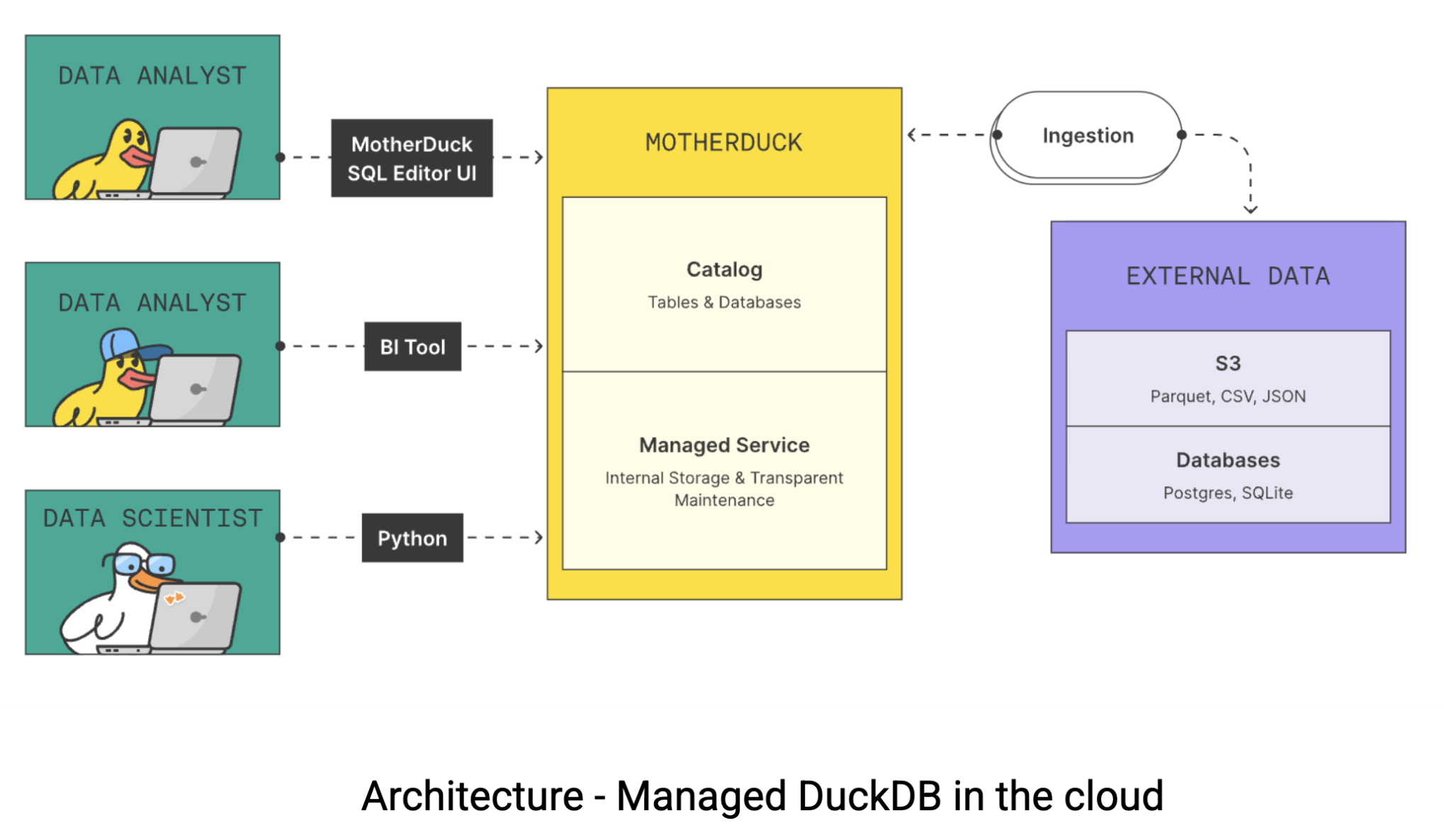
É aqui que o MotherDuck entra em cena. O MotherDuck é um warehouse data sem servidor que preenche a lacuna entre o desempenho bruto do DuckDB e as necessidades de colaboração das equipes data modernas. O MotherDuck cria o que eles chamam de “armazém data de análise individualizada”, dando a cada usuário sua própria instância de alto desempenho do DuckDB e mantendo a capacidade de compartilhar o data em toda a organização. Veja como a arquitetura funciona:
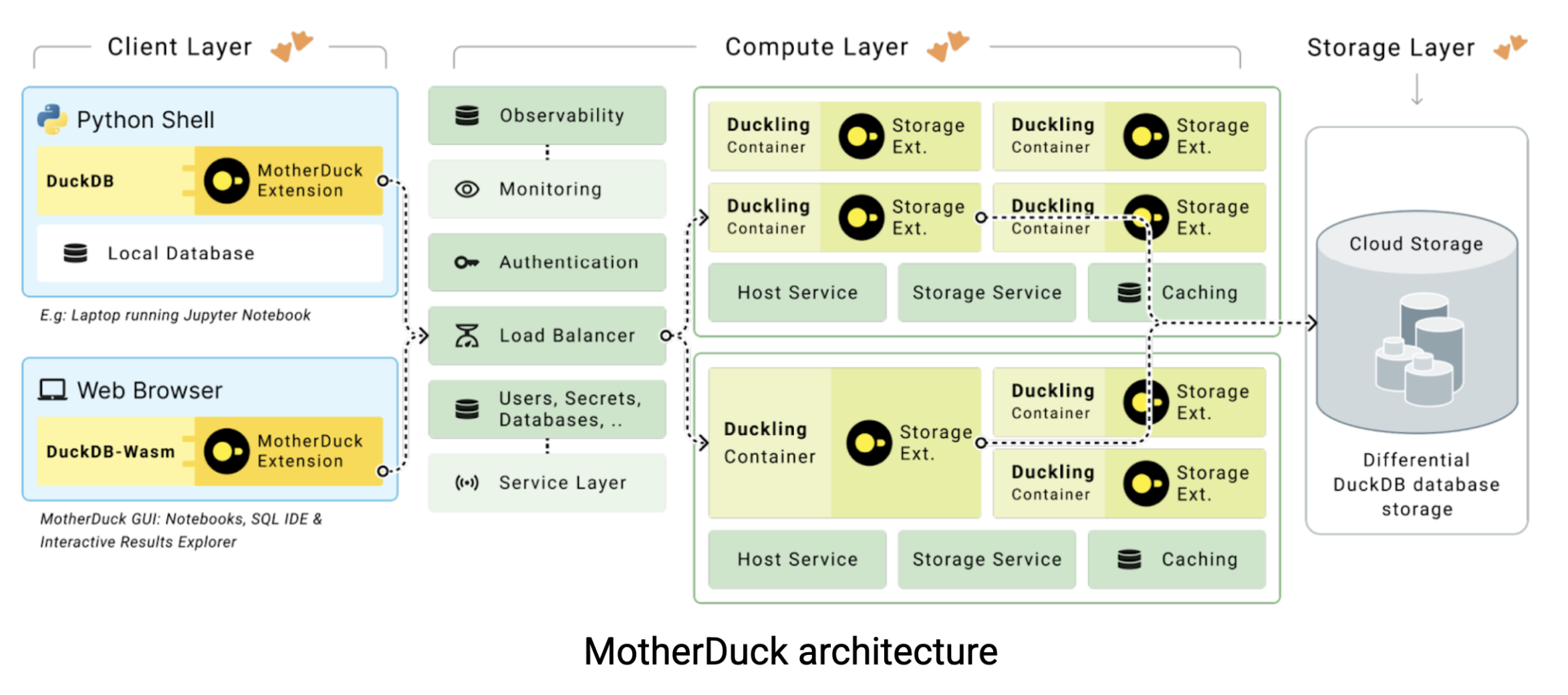
Nos armazéns cloud data tradicionais, seu laptop é apenas um terminal burro. Todo o trabalho pesado acontece em servidores remotos pelos quais o senhor paga por hora. Mas a questão é a seguinte: seu MacBook provavelmente é mais rápido do que uma instância de armazém $20-60 por hora data. O MotherDuck tenta aproveitar esse poder computacional com duas abordagens inovadoras:
- Análise baseada em navegador que trazem a computação diretamente para o usuário.
- Execução dupla que combina de forma inteligente o poder de processamento de sua máquina local com os recursos do cloud para fornecer resultados mais rápidos do que qualquer uma das abordagens poderia alcançar sozinha.
Antes de me aprofundar nesses dois métodos, gostaria de afirmar que o poder computacional do MotherDuck realmente se destaca quando aplicado ao seu camada de ouro. Para aqueles que não estão familiarizados com o termo, a camada de ouro é o data final, pronto para os negócios, que foi limpo, agregado e enriquecido. Essencialmente, são os conjuntos polidos de data que alimentam suas análises, relatórios e aprendizado de máquina. Esse é o data que orienta suas decisões comerciais mais importantes, o que torna o desempenho aqui absolutamente crucial. Todas as partes interessadas já sofreram com painéis dolorosamente lentos e todos os membros da equipe do data já olharam para a roda da morte enquanto aguardavam a conclusão de consultas complexas. O MotherDuck enfrenta essa frustração de frente.
Análise no navegador
Essa solução aproveita o design leve e portátil do DuckDB, permitindo que ele seja executado diretamente em seu navegador por meio do WebAssembly (Wasm). Pense no Wasm como uma tecnologia que permite que softwares complexos sejam executados nativamente em seu navegador: sem plug-ins, sem downloads, apenas com poder computacional onde o senhor mais precisa. Com o DuckDB em execução no lado do cliente, o senhor pode executar consultas analíticas complexas sem a dança habitual de enviar solicitações a um servidor e aguardar as respostas. O processamento do data ocorre diretamente em seu navegador, eliminando a latência da rede e reduzindo totalmente as dependências de infraestrutura. O senhor pode experimentar essa mágica experimentando DuckDB em seu navegador.
Embora não vamos nos aprofundar na implementação técnica aqui, vale a pena observar que o DuckDB-Wasm é excelente. A pesquisa detalhada em este documento mostra que ele supera significativamente o desempenho das soluções existentes baseadas em navegador, como a versão Wasm do SQLite ou o Lovefield, um database baseado em JavaScript. Essa demonstração técnica inteligente sinaliza uma mudança fundamental na forma como pensamos sobre o local da computação analítica.
A MotherDuck oferece essa arquitetura baseada em Wasm, conforme explicado por Mehdi Ouazza em este artigo. Essa abordagem é particularmente poderosa para a análise da camada de ouro. Sua equipe data começa a trabalhar com um data limpo e pronto para os negócios sem se preocupar com a infraestrutura de back-end, o processamento ocorre localmente para obter velocidade máxima e o senhor obtém alguns dos tempos de resposta mais rápidos possíveis, eliminando totalmente a latência da rede. Além disso, o senhor evita os altos custos de computação que os armazéns cloud data tradicionais adoram cobrar por cada consulta. É uma proposta atraente: análise mais rápida, custos mais baixos e arquitetura mais simples, tudo em um só lugar.
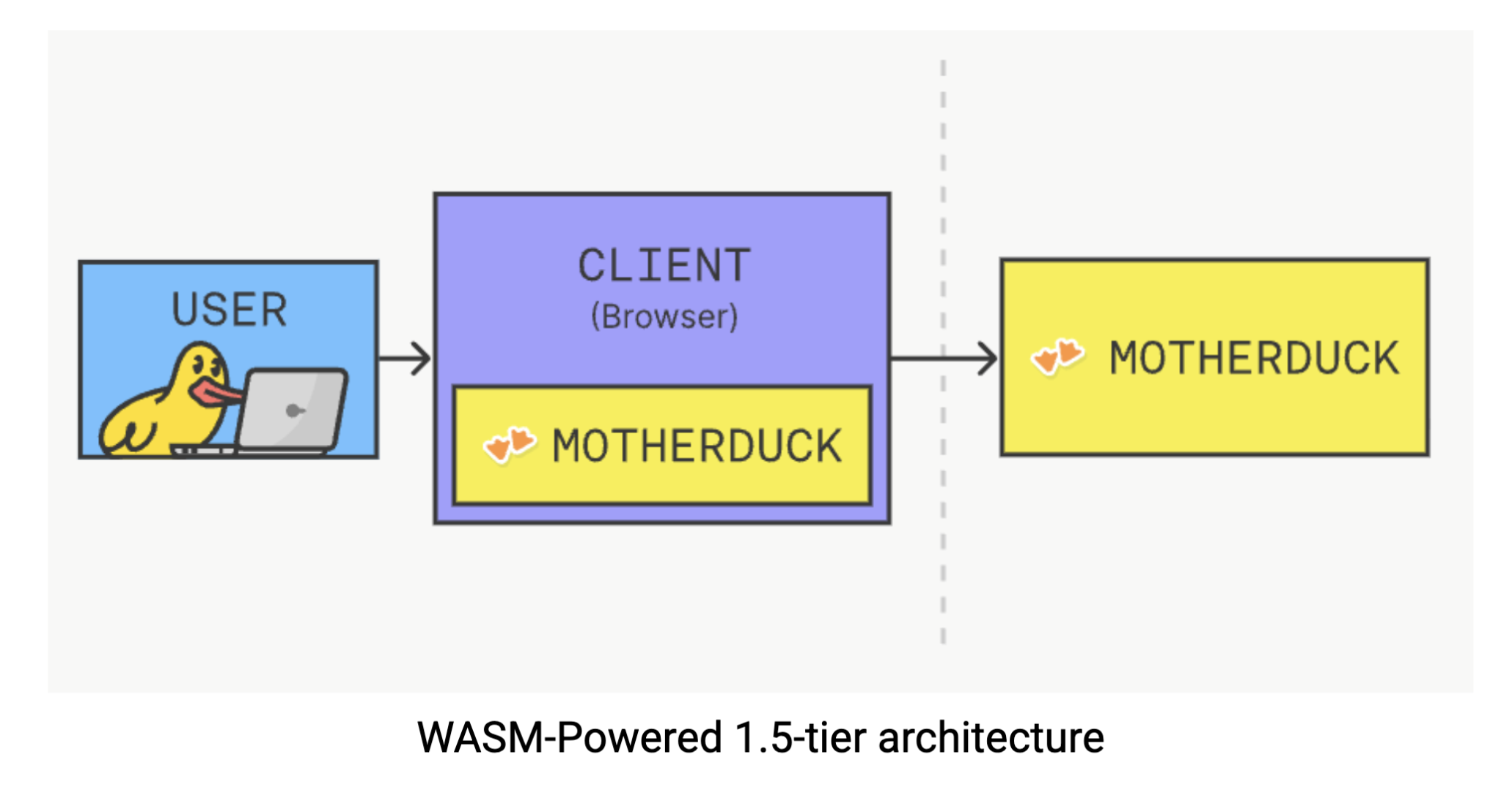
Execução dupla
Outra maneira de aproveitar o MotherDuck em sua camada de ouro é por meio de seu recurso de execução dupla, que combina de forma inteligente o poder de processamento local com a escala do cloud. Em vez de forçar toda a sua equipe de data a compartilhar os mesmos recursos computacionais, o MotherDuck oferece a cada usuário seu próprio “patinho”: uma instância de computação individual e sem servidor que é dimensionada de acordo com suas necessidades.
O verdadeiro poder da execução dupla se destaca quando o senhor está trabalhando com data espalhado por diferentes fontes. Imagine que o senhor precise consultar o data armazenado no MotherDuck, combiná-lo com arquivos no S3 e juntá-lo a um conjunto de data armazenado localmente em seu laptop. Os sistemas cloud tradicionais obrigariam o senhor a carregar tudo em um único local antes de poder executar consultas entre fontes. A execução híbrida do MotherDuck é mais inteligente. Ela analisa sua consulta, mantém apenas o data necessário de cada fonte e realiza uniões inteligentes entre locais, economizando tempo e custos de transferência de data.
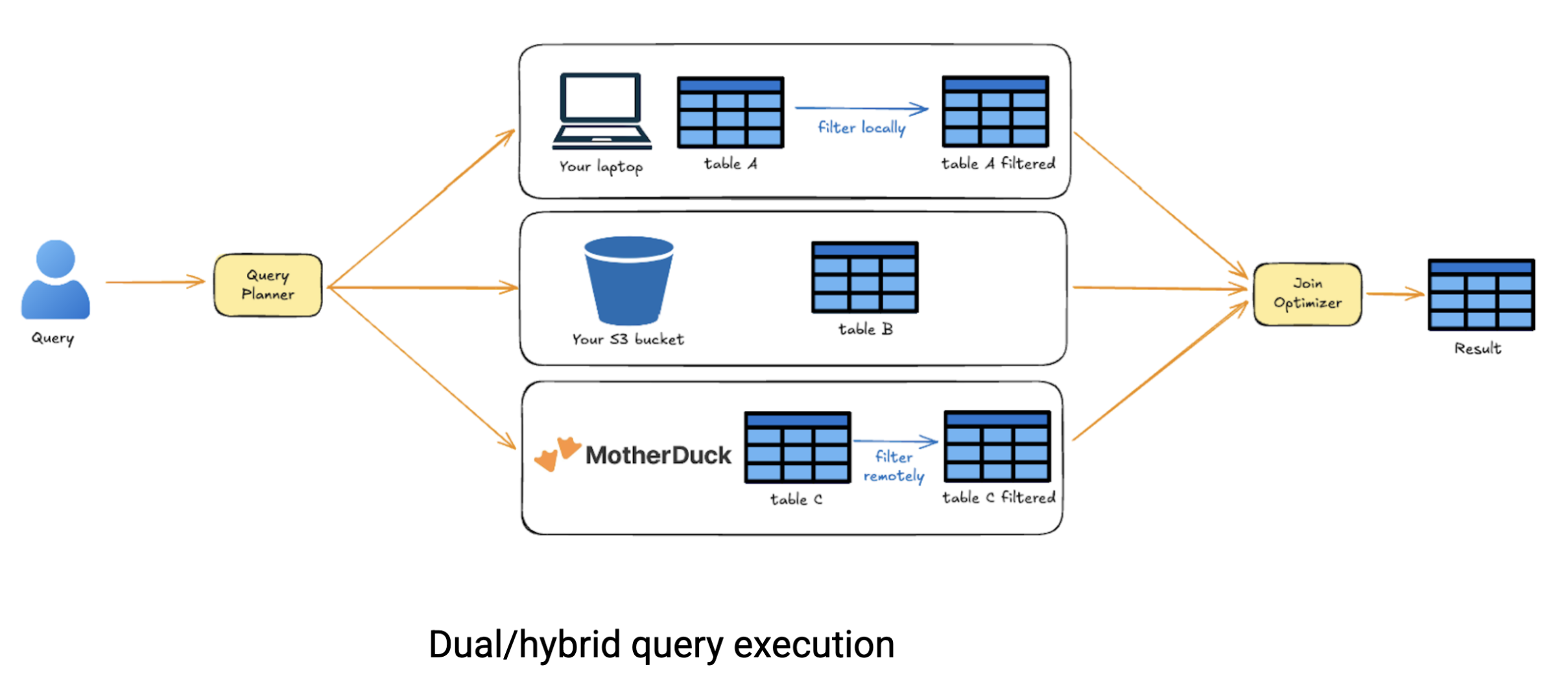
Nos bastidores, o otimizador do MotherDuck divide sua consulta em um DAG (gráfico acíclico direcionado) de operações, estima o custo de execução de cada nó localmente ou remotamente e lida com o movimento data automaticamente. O senhor apenas escreve o SQL; o MotherDuck calcula a estratégia de execução ideal. Essa abordagem redefine fundamentalmente a análise de cloud. Não estamos mais presos à escolha entre a simplicidade local e a escalabilidade do cloud, cada uma com sua própria complexidade em relação ao compartilhamento do data e à orquestração do fluxo de trabalho. Com o MotherDuck, o senhor obtém o melhor dos dois mundos: execute localmente quando sua máquina puder lidar com isso, dimensione para o cloud quando necessário e compartilhe sem esforço em todo o processo. É uma solução sem servidor que reduz os custos de computação do cloud porque o senhor só paga pelo que realmente computa.
Mas é aqui que as coisas ficam interessantes: o compartilhamento do data se torna fácil. Lembra-se de como a natureza de usuário único do DuckDB tornava a colaboração dolorosa? Se um analista do data criasse uma análise incrível, teria que exportar tudo e carregá-lo em um sistema de armazenamento compartilhado apenas para permitir que os colegas de equipe o acessassem. Com o MotherDuck, o compartilhamento é tão simples quanto clicar em um botão ou executar uma única linha de código para criar um instantâneo de cópia zero com controles de acesso adequados. Sem movimentação de data, sem duplicação de storage, apenas colaboração instantânea.
Saiba mais sobre a execução de consultas duplas/híbridas no artigo da MotherDuck em a Conferência sobre Pesquisa de Sistemas Data Inovadores (CIDR). O senhor também pode assistir a este dbt Coalesce talk por Jordan Tigani, cofundador e CEO da MotherDuck.
Patos na natureza
Vimos como o MotherDuck elimina uma sobrecarga significativa das equipes data e, ao mesmo tempo, oferece recursos avançados de análise para sua camada de ouro. Mas a teoria só vai até certo ponto. Queríamos colocar o MotherDuck à prova contra os participantes estabelecidos no espaço do armazém cloud data. Analisando o Relatório de pilha Data de 2025 publicado pelo Metabase, descobrimos algo surpreendente: O PostgreSQL continua sendo a opção de database mais popular, mesmo para cargas de trabalho analíticas, seguido pelo Snowflake e pelo BigQuery entre as empresas pesquisadas. Isso nos deu nossas metas de comparação.
Decidimos comparar o MotherDuck com o PostgreSQL hospedado no Google Cloud e com o BigQuery, usando Superconjunto Apache como nossa ferramenta de BI preferida. O Superset fazia sentido por vários motivos: é de código aberto, amplamente adotado e tem compatibilidade nativa com o MotherDuck e com a maioria das outras grandes bases data. Nosso ambiente de teste consistiu no Apache Superset implantado no Google Cloud Kubernetes Engine, conectado a três back-ends diferentes: BigQuery, PostgreSQL no Cloud SQL e MotherDuck.
Estruturamos nossos testes em duas fases. Primeiro, executamos o benchmark TPC-H: um benchmark padronizado de suporte à decisão que nos mostraria o desempenho do MotherDuck em um ambiente teórico e controlado. Em seguida, nos aproximamos da realidade, testando como a relação entre o Superset e o MotherDuck se comparava aos armazéns data tradicionais em cenários de painéis do mundo real.
Benchmarking TPC-H
O TPC-H é o padrão para testar o desempenho analítico do database. É um benchmark de suporte a decisões projetado para examinar grandes volumes de data, executar consultas complexas e fornecer respostas a questões comerciais críticas em diferentes setores. O senhor pode encontrar a especificação completa no documentação oficial. O benchmark consiste em 22 consultas que simulam cargas de trabalho analíticas do mundo real, desde agregações simples até uniões complexas de várias tabelas.
Executamos cada consulta individualmente no SQL Lab do Superset para todas as três bases data: MotherDuck, BigQuery e PostgreSQL. Também testamos as consultas diretamente na GUI do MotherDuck para eliminar a latência cliente-servidor e porque, francamente, qualquer empresa que use o MotherDuck provavelmente terá seus analistas data trabalhando na interface inspirada no notebook do MotherDuck em vez do SQL Lab do Superset. Além disso, o aplicativo da MotherDuck pode aproveitar a arquitetura WebAssembly que discutimos anteriormente, e estávamos curiosos para ver o desempenho dessa execução baseada em navegador em comparação com os modelos tradicionais de servidor-cliente. Para garantir um teste justo, o cache do Superset foi desativado em todos os benchmarks.
Para esse benchmark, usamos o fator de escala 10 (SF-10) do TPC-H, que gera um dataset de 10 GB. Escolhemos o fator de escala 10 porque 10 GB representa um tamanho realista de dataset para as cargas de trabalho analíticas da maioria das empresas, grande o suficiente para revelar diferenças significativas de desempenho sem exigir uma infraestrutura em escala empresarial. Veja como o data se divide entre as principais tabelas:
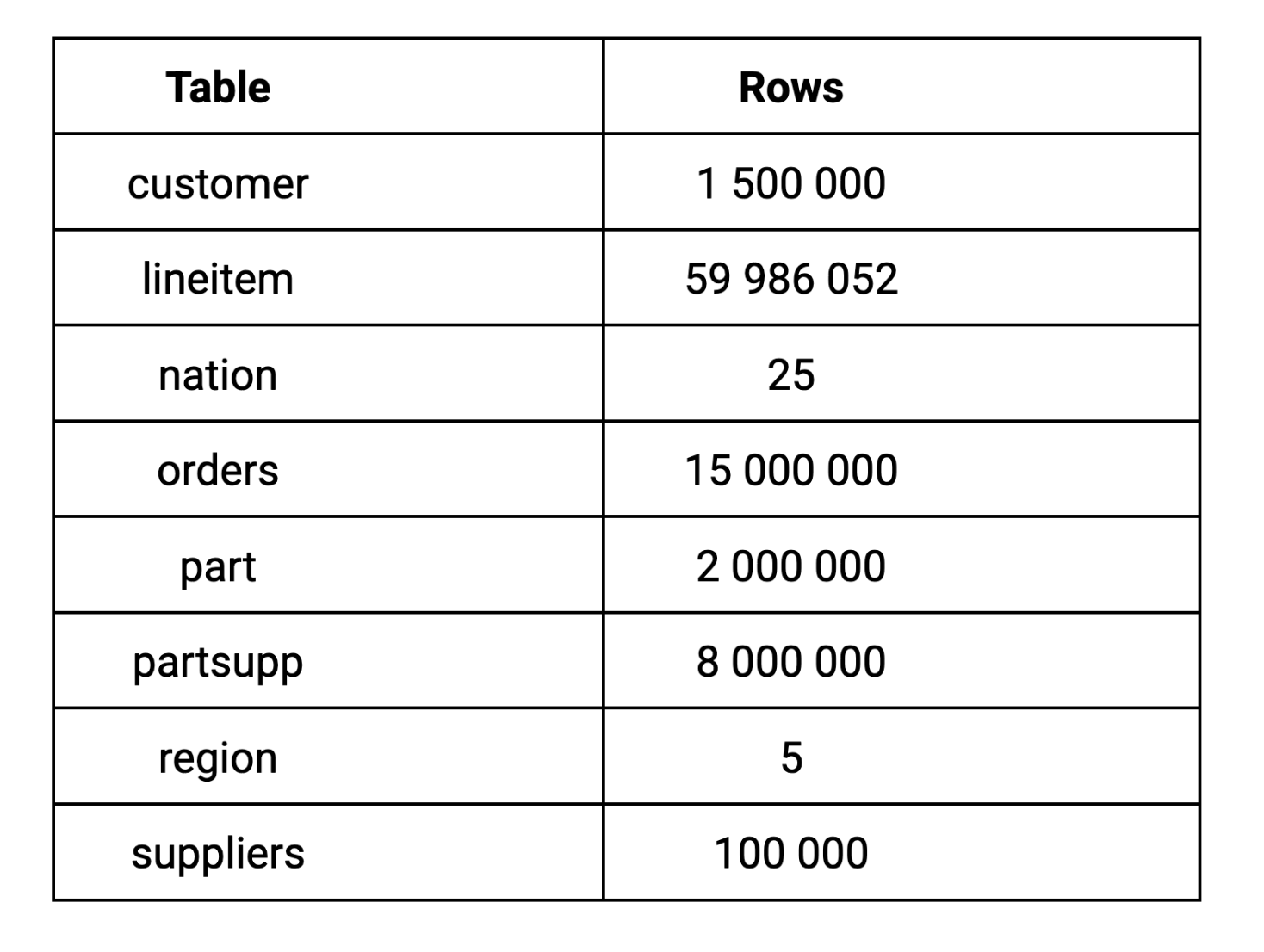
Usamos a extensão TPC-H do DuckDB para gerar o data localmente e, em seguida, fizemos o upload dele sem problemas para o MotherDuck. O processo levou apenas alguns minutos graças aos recursos de carregamento do data do MotherDuck.
Aqui estão os resultados do TPC-H SF-10 em segundos. A coluna amarela mostra os resultados da interface de usuário nativa do aplicativo MotherDuck, enquanto as outras colunas representam o desempenho por meio do SQL Lab do Superset (SST):
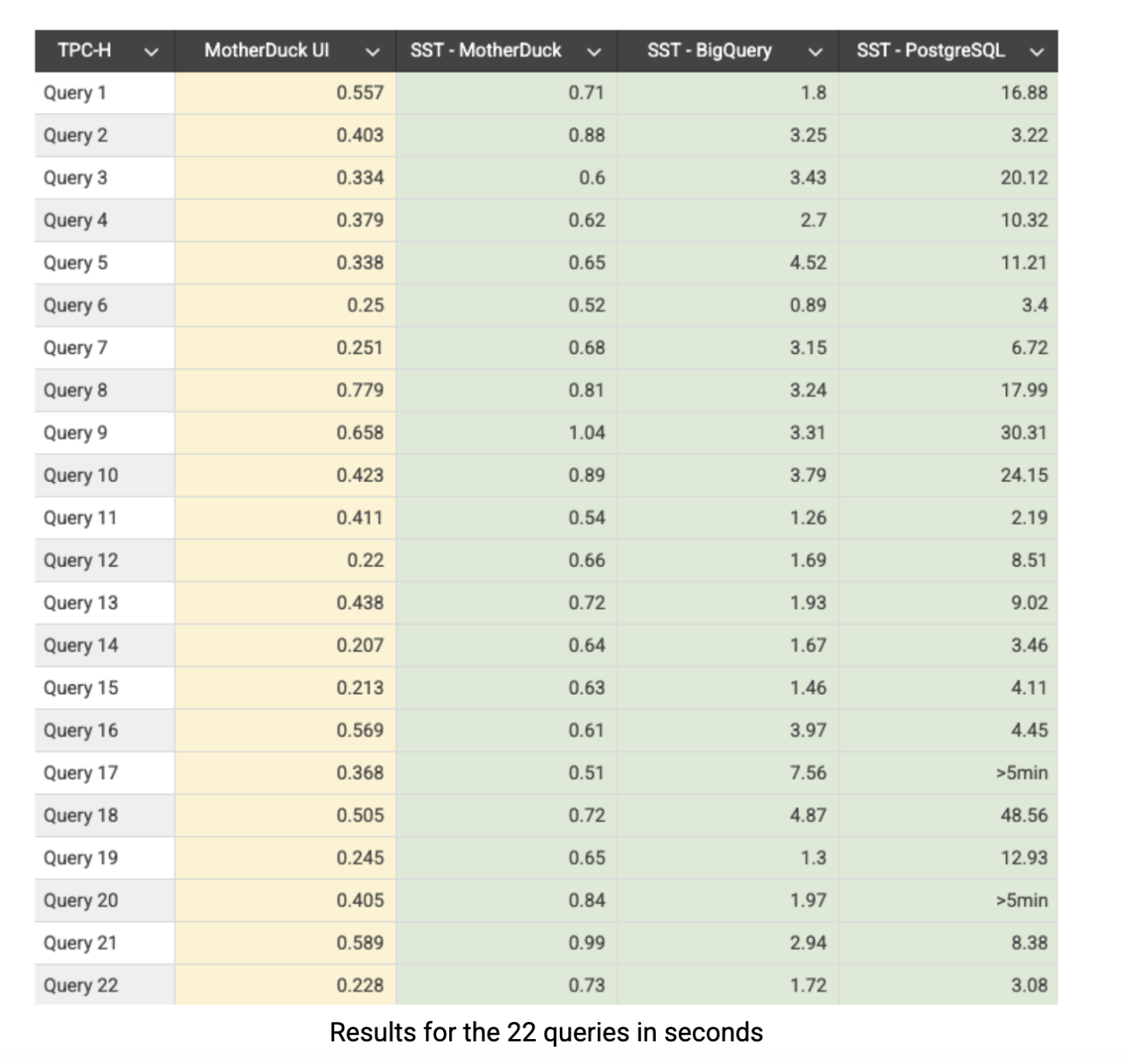
O MotherDuck oferece consistentemente um desempenho abaixo de um segundo em todas as áreas: 21 das 22 consultas feitas pelo Superset terminam em menos de um segundo, com todas as consultas concluídas em menos de um segundo quando executadas diretamente pelo aplicativo da MotherDuck. O BigQuery mostra um desempenho respeitável, mas tem uma média de aproximadamente 4 vezes mais lento que o MotherDuck em todo o conjunto de benchmarks. O PostgreSQL conta uma história totalmente diferente, com desempenho significativamente mais lento e dificuldades claras em agregações e junções complexas. Isso era previsível, pois o PostgreSQL foi fundamentalmente projetado para cargas de trabalho OLTP em vez de processamento analítico, mas o incluímos em nossa comparação porque ele continua sendo amplamente usado por empresas para tarefas analíticas. Vale a pena observar que o PostgreSQL poderia obter um desempenho muito melhor com técnicas de otimização adequadas, como indexação, particionamento ou visualizações materializadas, mas, mesmo assim, ainda estaria lutando contra sua arquitetura baseada em linhas. A lacuna de desempenho destaca exatamente o motivo pelo qual existem sistemas OLAP criados para fins específicos, como o MotherDuck: quando o senhor está executando consultas analíticas complexas em datasets substanciais, a arquitetura é extremamente importante.
Embora o TPC-H mostre o desempenho bruto da consulta, o verdadeiro teste é como isso se traduz na experiência real do usuário em ferramentas de business intelligence.
Desempenho do painel
Vimos que o desempenho era excelente para os analistas do data que trabalhavam com SQL em seu armazém do data, mas queríamos testar se essa melhoria se traduziria em painéis, onde as partes interessadas da empresa realmente interagem com o data. Afinal de contas, consultas SQL extremamente rápidas não importam muito se os painéis ainda demorarem muito para carregar.
Para testar isso, usamos um conjunto realista de comércio eletrônico data de Kaggle contendo 67,5 milhões de linhas em 9 GB de data, o tipo de escala com que muitas empresas trabalham para suas análises mensais de clientes. Usando essa única tabela, criamos um painel abrangente que testaria a capacidade de cada sistema de lidar com cargas de trabalho reais de business intelligence:
Testei o painel extensivamente em várias execuções, aplicando vários filtros, medindo os tempos de carregamento, desativando o cache e monitorando os tempos de resposta por meio das ferramentas de desenvolvimento do meu navegador. Após vários ciclos de teste para garantir resultados consistentes, aqui estão as métricas de desempenho do painel em segundos:
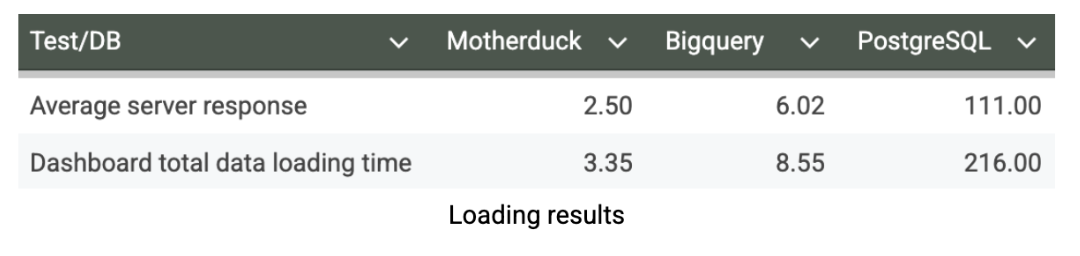
Nossos testes de carregamento do painel revelam as implicações práticas do desempenho do database na experiência do usuário. O MotherDuck oferece uma capacidade de resposta excepcional do painel com um tempo médio de carregamento de apenas 3,35 segundos, permitindo uma análise verdadeiramente interativa em que os usuários podem explorar o data de forma fluida e sem atrito. Em contrapartida, o BigQuery requer 8,55 segundos para carregar o mesmo painel. Isso ainda é aceitável para relatórios planejados, mas cria atrasos perceptíveis que podem desencorajar a análise exploratória. O tempo de carregamento de 216 segundos do PostgreSQL (>3 minutos) o torna completamente impraticável para o uso de painéis. Essa vantagem de desempenho que o MotherDuck representa pode transformar fundamentalmente a forma como os usuários corporativos interagem com o data. Quando os painéis são carregados em segundos em vez de minutos, a adoção do usuário aumenta, os analistas podem iterar rapidamente as informações e a análise se torna uma vantagem competitiva em vez de um gargalo.
Comparação de preços
O MotherDuck combina armazenamento com pagamento conforme o uso otimizado para análises interativas. Como ele é dimensionado em uma única máquina em vez de ser distribuído em um cluster, ele evita a sobrecarga que os usuários acabam pagando. Uma sessão de dezenas de consultas pode custar apenas $0.05-$0.10, enquanto uma equipe que executa milhares de consultas mensalmente pode gastar apenas $20-$40. Por outro lado, as bases data sempre ativas podem custar $300-$500/mês apenas para se manterem ativas, e os armazéns cloud geralmente cobram $5-$10 por TB digitalizado. Com seu projeto de aumento de escala, o MotherDuck mantém os preços simples, previsíveis e econômicos.

A princípio, o MotherDuck pode parecer mais caro devido à sua taxa organizacional e ao modelo de preço de computação diferente. Entretanto, ambos os sistemas usam modelos de preços que favorecem diferentes padrões de uso: O BigQuery se destaca no processamento de grandes lotes, enquanto o MotherDuck é otimizado para análises interativas. Para o nosso benchmark TPC-H, a execução de 22 consultas no SF-10 custou $0,03 para o MotherDuck, em comparação com $0,60-$1,00 para o BigQuery. Ao levar em conta a sobrecarga de infraestrutura - nossa configuração do PostgreSQL exigia 14 euros/dia apenas para permanecer on-line -, a abordagem sem servidor da MotherDuck geralmente oferece um custo total de propriedade superior para cargas de trabalho analíticas interativas.
Em escala empresarial, a economia muda de acordo com os padrões de uso. O BigQuery se torna mais econômico para processamento em lote de volume muito alto, enquanto o MotherDuck mantém sua vantagem para análises interativas e fluxos de trabalho exploratórios. O principal insight: escolha seu modelo de preço com base em como sua equipe realmente trabalha com o data, e não apenas nos custos brutos por unidade.
Observação: todos os exemplos de preços são baseados na região europe-west4 e devem ser considerados ilustrativos e não exatos, pois os custos reais dependem muito de padrões de uso específicos e das características do data.
Conclusão
O MotherDuck representa uma mudança fundamental na forma como pensamos sobre as bases analíticas do data, uma mudança que desafia a suposição de que o senhor precisa de sistemas complexos e distribuídos para lidar com cargas de trabalho sérias do data. Ao adotar a filosofia incorporada do DuckDB e estendê-la ao cloud, o MotherDuck oferece os recursos colaborativos que as equipes modernas do data exigem, mantendo o desempenho bruto que torna o DuckDB excepcional.
Nossos resultados de benchmarking contam uma história convincente: O MotherDuck superou consistentemente o BigQuery e o PostgreSQL por margens significativas, oferecendo desempenho de consulta de menos de um segundo em conjuntos de 10 GB data e tempos de carregamento de painel que permitem uma análise verdadeiramente interativa. A vantagem de desempenho sobre o BigQuery e a grande vantagem sobre o PostgreSQL em cenários de painel não se trata apenas de consultas mais rápidas, mas de transformar a análise em uma experiência mais interativa e exploratória que incentiva a tomada de decisões data-driven.
Talvez o mais importante seja o fato de a MotherDuck alcançar esse desempenho e, ao mesmo tempo, reduzir drasticamente a complexidade e os custos da infraestrutura. Enquanto as configurações tradicionais de cloud exigem uma infraestrutura sempre ativa que custa centenas de dólares por mês, o modelo sem servidor da MotherDuck cobra apenas pelo uso real, reduzindo os custos com frequência. O preço de pagamento por computação se alinha perfeitamente à forma como os analistas realmente trabalham: executando várias consultas em sessões de exploração em vez de solicitações isoladas e pouco frequentes.
As implicações vão além do desempenho e do custo. O modelo de execução dupla do MotherDuck e os recursos de análise baseados em navegador sugerem um futuro em que a fronteira entre a computação local e a de cloud se tornará cada vez mais fluida. Em vez de forçar as equipes a escolherem entre a simplicidade local e a escalabilidade de cloud, a MotherDuck oferece ambos, direcionando a computação de forma inteligente para onde fizer mais sentido.
O que realmente me impressionou durante os testes foi a simplicidade de uso e configuração do MotherDuck. O modelo de execução dupla permitiu que eu consultasse o data tanto localmente quanto no cloud simultaneamente, enquanto a configuração da conexão entre o Superset e o MotherDuck foi extremamente simples.
Para as organizações que buscam modernizar seus recursos analíticos começando pela camada de ouro, a MotherDuck oferece uma proposta muito atraente: desempenho de nível empresarial, fluxos de trabalho colaborativos e eficiência de custos, tudo isso sem a sobrecarga operacional da infraestrutura tradicional de armazém data. Em um mundo em que as decisões data-driven determinam cada vez mais a vantagem competitiva, a capacidade de explorar o data de forma interativa em velocidades inferiores a um segundo não é apenas algo agradável de se ter; está se tornando essencial.
Pronto para experimentar o desempenho do MotherDuck por si mesmo? O senhor pode começar com um Teste gratuito de 21 dias ou com seu plano gratuito de 10 GB para testá-lo com seus próprios conjuntos de data e cargas de trabalho. Se estiver procurando orientação sobre a adequação do MotherDuck à sua pilha data específica ou se precisar de ajuda com a implementação, entre em contato com nossa equipe em A Artefact, Se o senhor tiver alguma dúvida sobre o que é uma infraestrutura analítica, teremos prazer em avaliar suas necessidades analíticas e ajudá-lo a navegar na transição para uma infraestrutura analítica mais eficiente e econômica.
