


Résumé
MotherDuck étend les performances analytiques de DuckDB au cloud avec des fonctionnalités collaboratives, offrant des performances quatre fois plus rapides que BigQuery et des économies par rapport aux entrepôts data traditionnels grâce à une tarification sans serveur et à l'utilisation. Suite à l'annonce de la nouvelle région européenne cloud de MotherDuck, nous avons été impressionnés par ses performances et son prix attractif. MotherDuck peut déjà être intégré dans vos couches d'or afin d'accélérer le service des cas d'utilisation data tout en réduisant les coûts. Voir l'analyse comparative des performances.
Introduction
Dans le paysage en évolution rapide de l'analyse data, un nouvel acteur remet en question l'ordre établi des entrepôts cloud data. MotherDuck, qui repose sur les fondements de la DuckDB‘Le moteur analytique rapide comme l'éclair de la société promet d'offrir des performances de niveau entreprise avec la simplicité et la rentabilité que les équipes modernes data recherchent. Mais ce canard peut-il vraiment rivaliser avec les géants établis ?
Nous avons soumis MotherDuck à des tests rigoureux par rapport à des concurrents établis pour voir s'il était à la hauteur de l'engouement qu'il suscitait. Ce que nous avons découvert remet en question le statu quo actuel des bases data analytiques et suggère un changement fondamental dans la manière dont nous abordons le traitement data basé sur le cloud. Voici comment une base data embarquée a appris à voler, et pourquoi elle pourrait bien révolutionner votre pile data.
Pour capter cette clientèle en évolution, les détaillants doivent s'adapter rapidement.
Un canard à couver
MotherDuck se décrit comme un “entrepôt DuckDB cloud data évoluant jusqu'au téraoctet pour l'analyse et la BI orientées client”. Pour comprendre ce qui rend cet entrepôt cloud data spécial, nous devons d'abord nous pencher sur les points suivants DuckDB, DuckDB est un système open-source database qui révolutionne discrètement la pile data depuis quelques années. En termes simples, DuckDB est un système database SQL OLAP en mémoire. Pour ceux qui ne vivent pas et ne respirent pas le jargon de database, voyons ce que cela signifie réellement :
OLAP signifie Online Analytical Processing (traitement analytique en ligne). Il s'agit d'une base de data conçue pour traiter des quantités massives de data et répondre rapidement à des questions commerciales complexes. Contrairement aux bases de données data traditionnelles qui excellent dans la recherche d'enregistrements individuels (comme la recherche de la commande d'un client), les bases de données data OLAP sont conçues pour analyser des millions de lignes et effectuer des calculs lourds en quelques secondes. Elles atteignent cette vitesse en stockant les data en colonnes plutôt qu'en lignes, ce qui permet d'analyser rapidement les tendances, de calculer des moyennes ou d'additionner les ventes sur des ensembles entiers de data. Il s'agit de la même approche que celle utilisée par les entrepôts modernes de data tels que BigQuery ou Snowflake. De l'autre côté, vous avez les bases data OLTP (Online Transaction Processing) comme PostgreSQL, SQLite ou MySQL. Ce sont les bêtes de somme qui alimentent vos applications, gérant des milliers de lectures et d'écritures individuelles par seconde pour assurer le bon fonctionnement de votre application. En savoir plus sur OLAP vs OLTP.
Pour comprendre à quel point l'approche de DuckDB est révolutionnaire, nous devons prendre du recul et examiner comment nous en sommes arrivés là. Au milieu des années 1990, lorsque des géants du web comme Yahoo et Amazon ont explosé sur la scène, ils se sont heurtés à un mur qui allait remodeler l'ensemble du paysage du data. Ces entreprises se noyaient dans le data, ce que nous appellerons plus tard le “gros data”, et leurs systèmes existants ne pouvaient tout simplement pas suivre. La solution ? Des infrastructures coûteuses et monolithiques capables de gérer l'échelle. Mais avec la chute des coûts du matériel dans les années 2000, une nouvelle philosophie est apparue : au lieu d'acheter de plus grosses machines, pourquoi ne pas utiliser un grand nombre de machines plus petites et moins chères ? Cette philosophie a donné naissance à des systèmes distribués tels que MapReduce et Apache Hadoop, des technologies conçues pour répartir les charges de travail sur des grappes de matériel de base. Amazon a capitalisé sur cette tendance, en présentant ces technologies distribuées comme des services et en lançant Amazon Web Services, la première grande plateforme cloud. Pendant des années, c'est devenu la règle du jeu par défaut : lorsque vous rencontrez un problème de data, vous le répartissez sur un plus grand nombre de machines (Fundamentals of Data Engineering, Joe Reis & Matt Housley).
Mais voici ce qui est fascinant : pendant que tout le monde était occupé à construire des systèmes distribués, quelque chose d'autre se passait tranquillement en arrière-plan. Les mêmes forces qui ont rendu l'informatique distribuée économique ont également rendu les machines individuelles incroyablement puissantes. Aujourd'hui, votre ordinateur portable est devenu incroyablement puissant, avec plus de mémoire vive, des processeurs plus rapides et une meilleure capacité de stockage. Les développeurs de DuckDB ont reconnu cette opportunité négligée : et si, au lieu de toujours passer à l'échelle supérieure, nous pouvions passer à l'échelle supérieure de manière plus intelligente ? Et si nous pouvions résoudre de nombreux problèmes data sans la complexité des systèmes distribués ?
L'un des moteurs database les plus déployés au monde, SQLite adopte une approche radicalement différente des bases data traditionnelles. Alors que PostgreSQL et MySQL fonctionnent comme des serveurs distincts auxquels les applications se connectent via un réseau, SQLite s'intègre directement dans votre application sous la forme d'une bibliothèque légère. Il n'y a pas de serveur à configurer, pas de réseau, pas d'installation complexe, juste une fonctionnalité database locale pure qui s'exécute dans le processus de votre application. Cette simplicité, associée à une fiabilité et une vitesse remarquables, a rendu SQLite omniprésent dans tous les domaines, des applications mobiles aux navigateurs web.
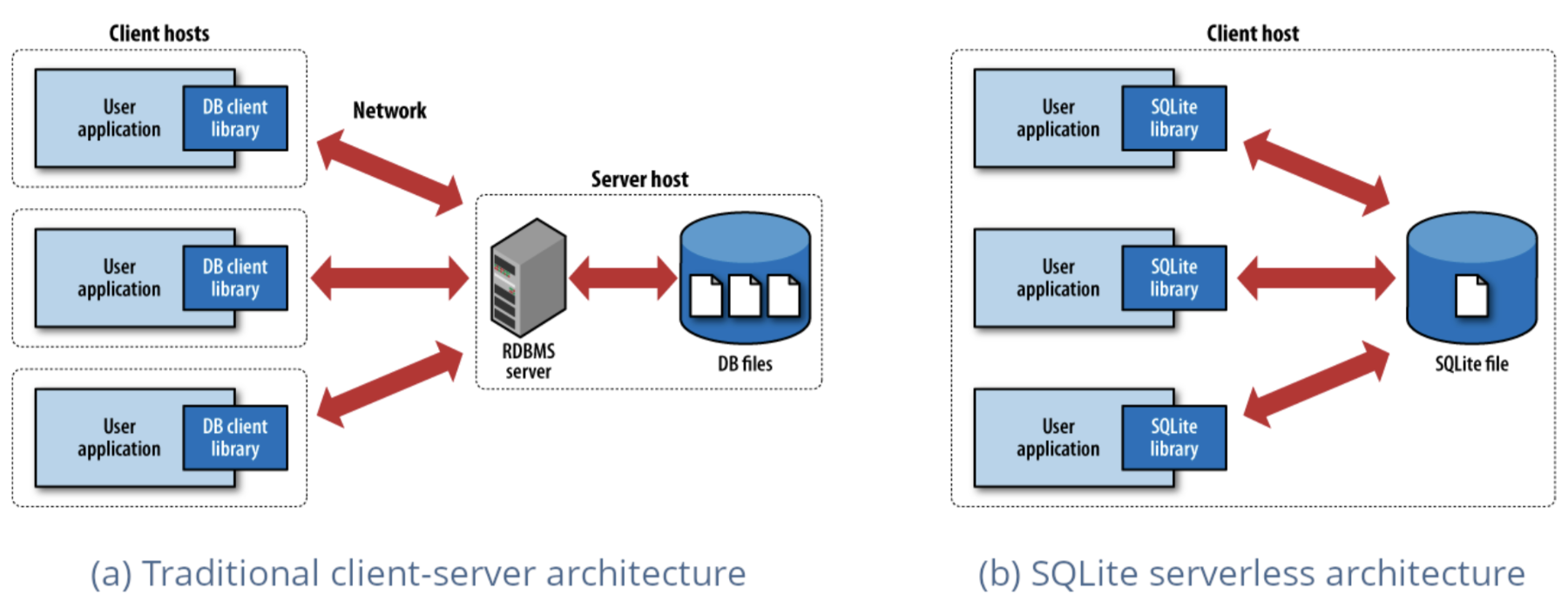
DuckDB applique cette même philosophie intégrée aux charges de travail analytiques, prouvant que vous n'avez pas toujours besoin d'un système distribué pour analyser de grands ensembles de data. Tout comme SQLite a révolutionné le stockage local de data, DuckDB exploite la puissance brute de votre machine locale pour rendre l'analyse à nouveau simple. L'installation prend quelques secondes, il n'y a pas de dépendances externes à gérer, et soudain vous exécutez des requêtes analytiques complexes sur des gigaoctets de data sans avoir à lancer une seule instance de cloud.
Ce qui rend DuckDB particulièrement convaincant, c'est qu'il va à la rencontre des développeurs là où ils se trouvent. Vous avez besoin d'analyser un Python DataFrame ? DuckDB peut l'interroger directement. Vous voulez analyser un fichier CSV ? Aucun problème. Cette intégration transparente, associée à son moteur en colonnes ultra-rapide, a fait de DuckDB l'un des systèmes database à la croissance la plus rapide dans le domaine de l'analyse. Les gains de performance sont souvent suffisamment spectaculaires pour que vous vous demandiez pourquoi vous utilisiez des systèmes distribués au départ. Si vous souhaitez approfondir la philosophie technique qui sous-tend cette approche, nous vous recommandons vivement de lire le document suivant “Gestion des analyses en cours de fabrication Data avec DuckDB” par le co-créateur de DuckDB, Hannes Mühleisen.
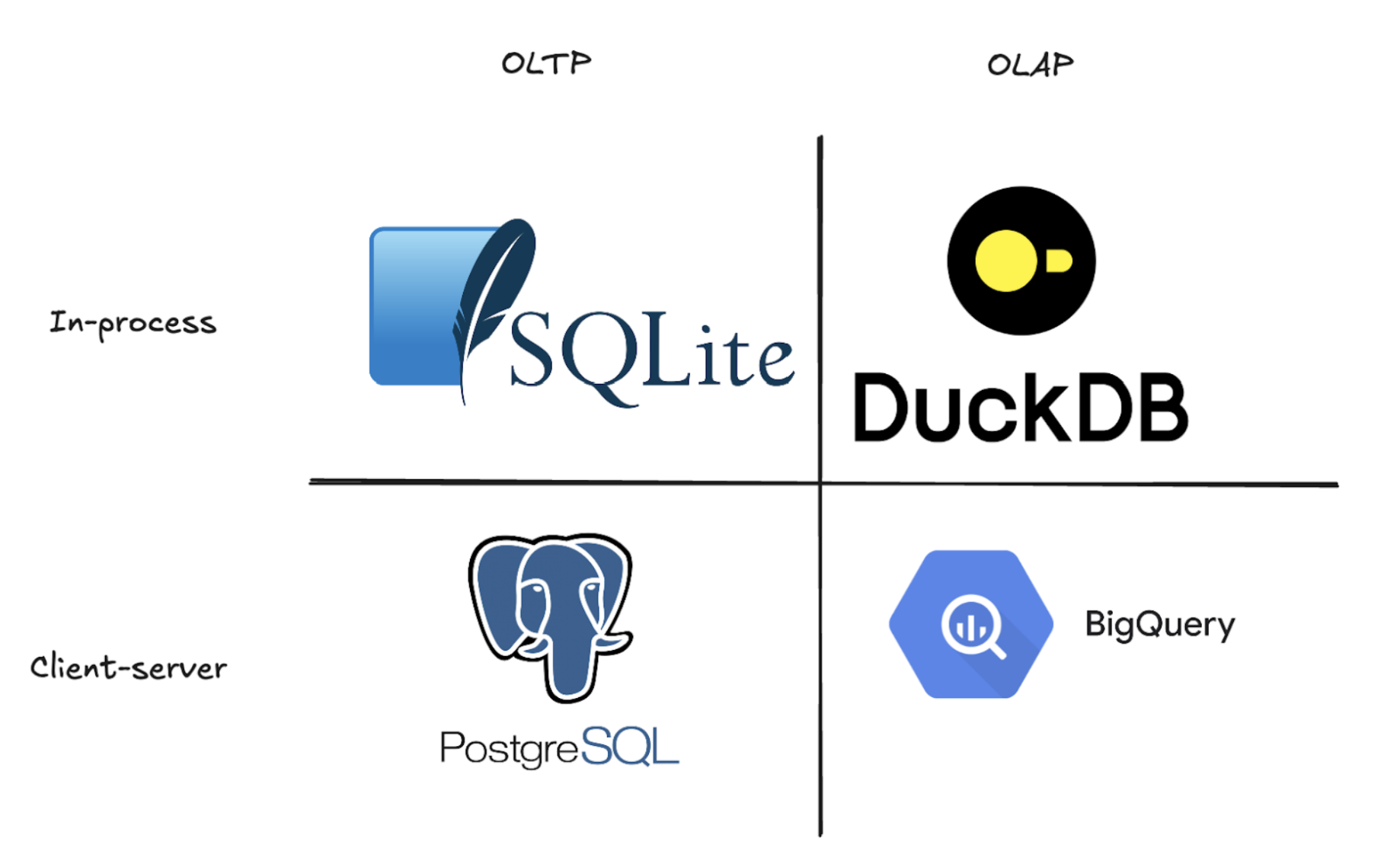
Maintenant que vous savez ce qu'est DuckDB, parlons de ses limites. Toute technologie comporte des compromis. DuckDB ne peut fonctionner que sur une seule machine et n'accepte qu'une seule connexion à la fois. Dans un monde où les équipes data construisent des solutions natives cloud qui servent des organisations entières, il s'agit d'une contrainte assez importante. Vous ne pouvez pas avoir plusieurs analystes qui interrogent simultanément la même instance de DuckDB, et vous ne pouvez certainement pas partager des ensembles data entre les équipes comme vous le feriez avec un entrepôt data traditionnel. Malgré sa vitesse et sa simplicité, DuckDB verrouille essentiellement votre data sur une seule machine, accessible à une seule personne à la fois. Alors, comment transformer cette database incroyablement rapide mais intrinsèquement mono-utilisateur en un entrepôt de cloud data pouvant servir à l'ensemble d'une organisation ?
Le canard qui a appris à voler
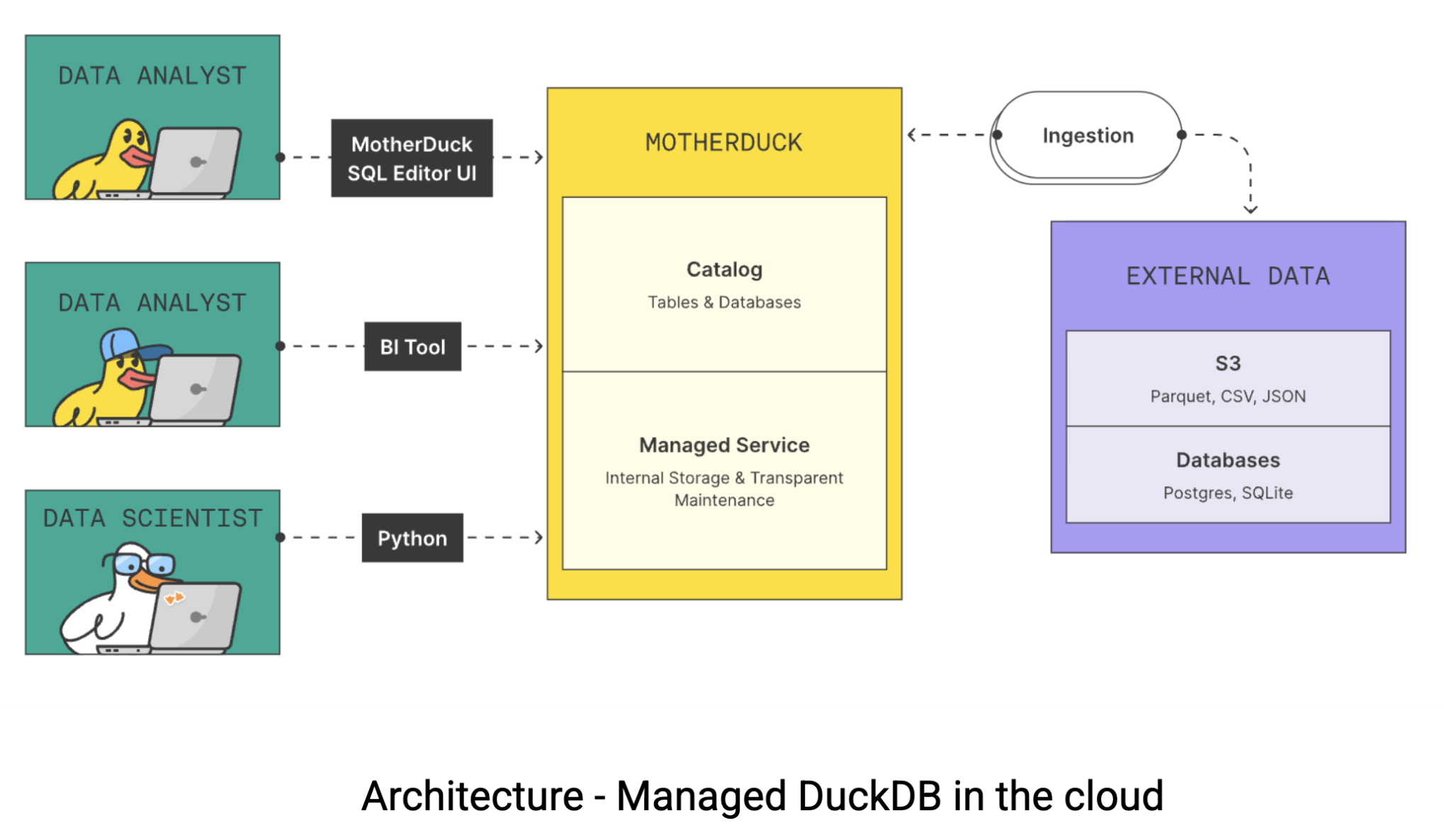
C'est là que MotherDuck entre en scène. MotherDuck est un entrepôt data sans serveur qui comble le fossé entre les performances brutes de DuckDB et les besoins de collaboration des équipes data modernes. MotherDuck crée ce qu'il appelle un “entrepôt data analytique individualisé”, donnant à chaque utilisateur sa propre instance DuckDB haute performance tout en conservant la possibilité de partager data dans l'ensemble de l'organisation. Voici comment fonctionne l'architecture :
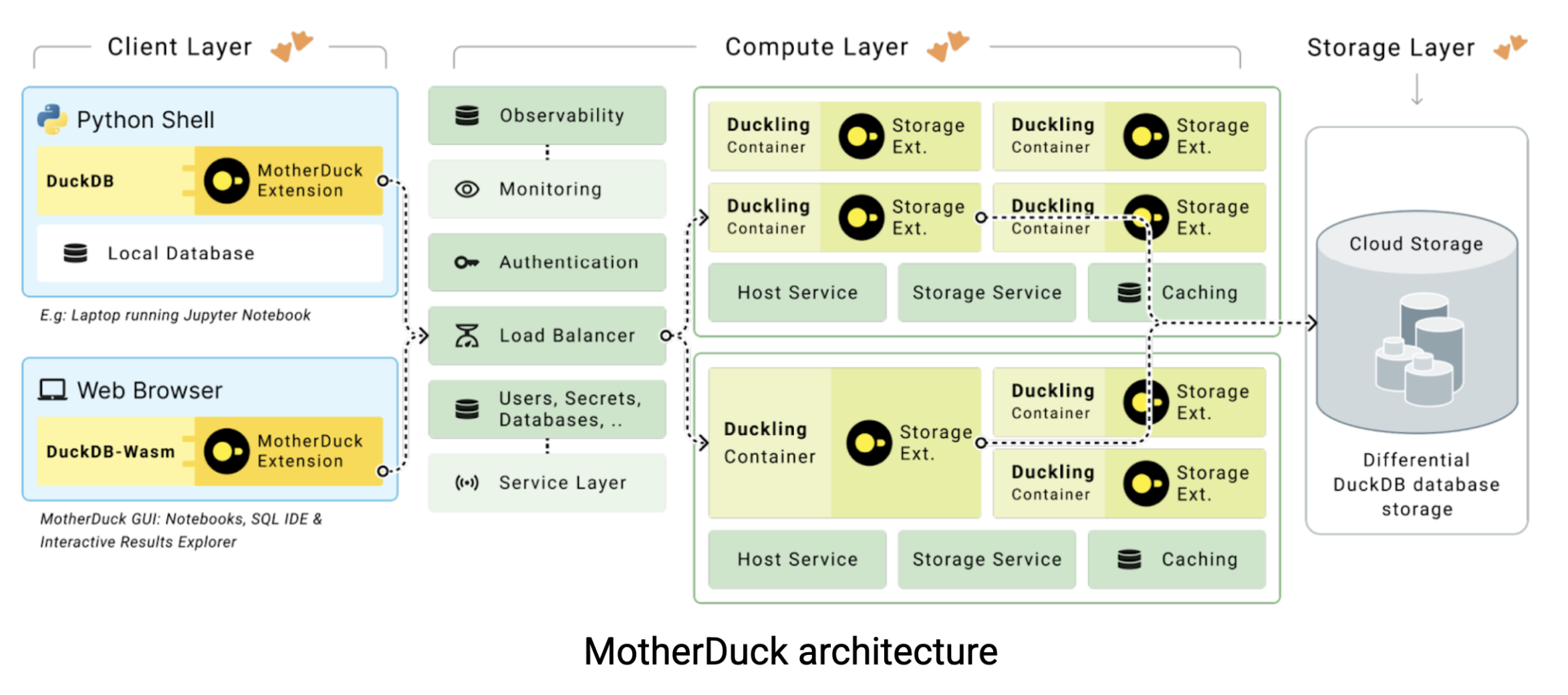
Dans les entrepôts traditionnels cloud data, votre ordinateur portable n'est qu'un simple terminal. Toutes les opérations lourdes sont effectuées sur des serveurs distants que vous payez à l'heure. Mais voilà : votre MacBook est probablement plus rapide qu'une instance d'entrepôt $20-60 par heure data. MotherDuck tente de tirer parti de cette puissance de calcul grâce à deux approches innovantes :
- Analyse par navigateur qui mettent le calcul directement à la portée de l'utilisateur.
- Double exécution qui combine intelligemment la puissance de traitement de votre machine locale avec les ressources de cloud afin d'obtenir des résultats plus rapidement qu'avec l'une ou l'autre de ces approches.
Avant de plonger dans ces deux méthodes, j'aimerais préciser que la puissance de calcul de MotherDuck brille vraiment lorsqu'elle est appliquée à votre couche d'or. Pour ceux qui ne sont pas familiers avec ce terme, la couche d'or est la data finale, prête à l'emploi, qui a été nettoyée, agrégée et enrichie. Il s'agit essentiellement des ensembles de data polis qui alimentent vos analyses, vos rapports et votre apprentissage automatique. Il s'agit du data qui alimente vos décisions commerciales les plus critiques, ce qui rend les performances ici absolument cruciales. Chaque partie prenante a souffert de tableaux de bord douloureusement lents, et chaque membre de l'équipe data a regardé la roue de la mort tourner en attendant que des requêtes complexes se terminent. MotherDuck s'attaque de front à cette frustration.
Analyse en cours de navigation
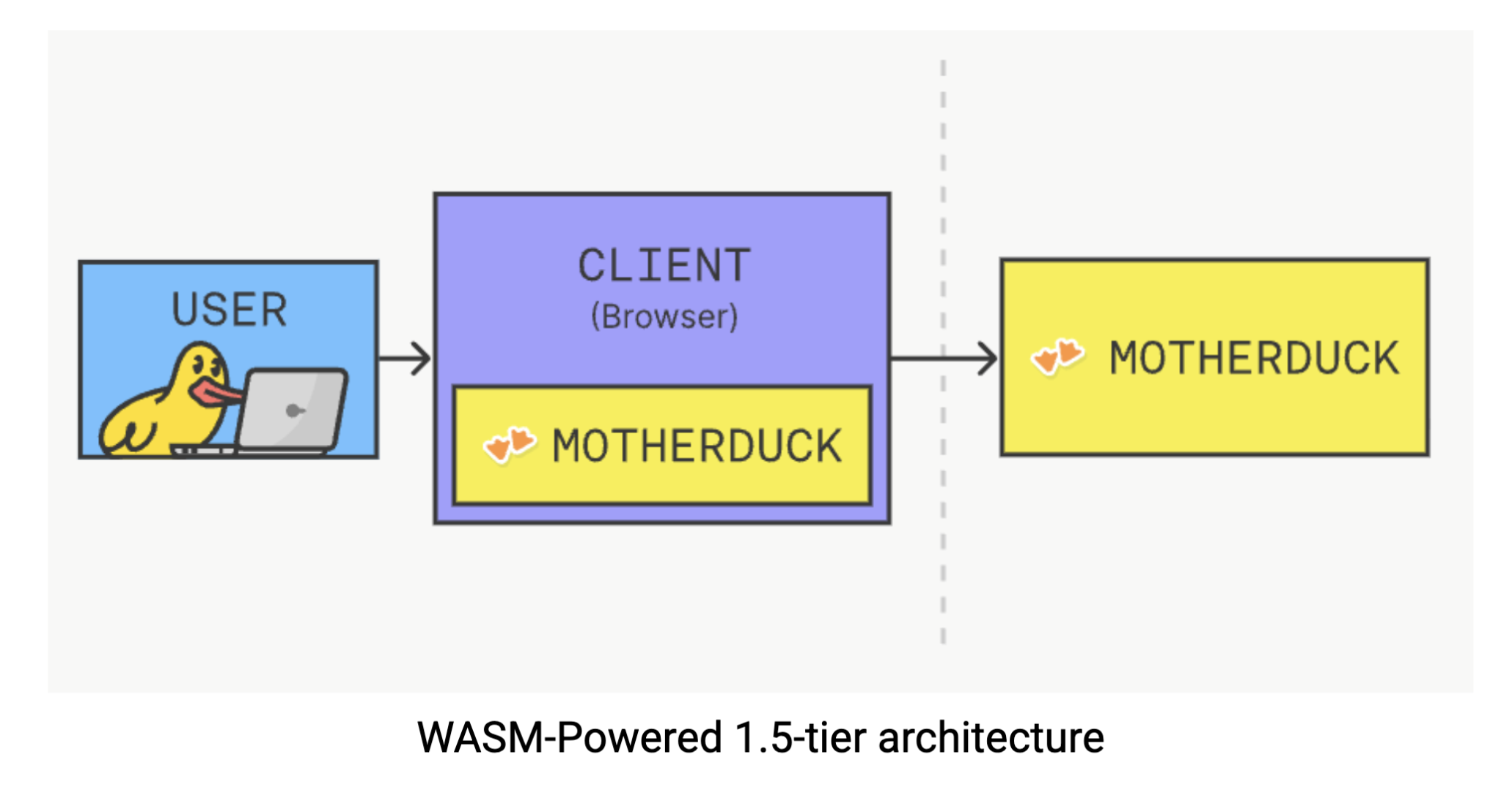
Cette solution tire parti de la conception légère et portable de DuckDB, ce qui lui permet de s'exécuter directement dans votre navigateur grâce à WebAssembly (Wasm). Wasm est une technologie qui permet à des logiciels complexes de s'exécuter nativement dans votre navigateur : pas de plugins, pas de téléchargements, juste de la puissance de calcul là où vous en avez le plus besoin. Avec DuckDB fonctionnant côté client, vous pouvez exécuter des requêtes analytiques complexes sans avoir à envoyer des requêtes à un serveur et à attendre les réponses. Le traitement data s'effectue directement dans votre navigateur, ce qui élimine la latence du réseau et réduit entièrement les dépendances de l'infrastructure. Vous pouvez faire l'expérience de cette magie en essayant DuckDB dans votre navigateur.
Nous ne nous pencherons pas ici sur la mise en œuvre technique, mais il convient de noter que DuckDB-Wasm excelle. Des recherches détaillées dans ce document montre qu'il est nettement plus performant que les solutions existantes basées sur un navigateur, telles que la version Wasm de SQLite ou Lovefield, une base data basée sur JavaScript. Cette démonstration technique intelligente est le signe d'un changement fondamental dans la manière dont nous envisageons la localisation des calculs analytiques.
MotherDuck propose cette architecture alimentée par Wasm, comme l'explique Mehdi Ouazza dans cet article. Cette approche est particulièrement efficace pour l'analyse de la couche d'or. Votre équipe data travaille avec des données propres et prêtes à l'emploi sans se soucier de l'infrastructure dorsale, le traitement s'effectue localement pour une vitesse maximale et vous obtenez des temps de réponse parmi les plus rapides possibles en éliminant totalement la latence du réseau. De plus, vous évitez les coûts de calcul élevés que les entrepôts traditionnels cloud data aiment vous facturer pour chaque requête. Il s'agit d'une proposition convaincante : des analyses plus rapides, des coûts réduits et une architecture plus simple, le tout réuni en une seule solution.
Double exécution
Une autre façon de tirer parti de MotherDuck dans votre couche d'or est sa capacité d'exécution double, qui combine intelligemment la puissance de traitement locale avec l'échelle cloud. Au lieu de forcer toute votre équipe data à partager les mêmes ressources de calcul, MotherDuck donne à chaque utilisateur son propre “canard” : une instance de calcul individuelle, sans serveur, qui évolue en fonction de ses besoins.
La puissance réelle de la double exécution se révèle lorsque vous travaillez avec data dispersé dans différentes sources. Imaginez que vous ayez besoin d'interroger data stockée dans MotherDuck, de la combiner avec des fichiers dans S3 et de la joindre à un ensemble data situé localement sur votre ordinateur portable. Les systèmes cloud traditionnels vous obligeraient à tout télécharger en un seul endroit avant de pouvoir exécuter des requêtes intersources. L'exécution hybride de MotherDuck est plus intelligente. Elle analyse votre requête, ne conserve que les data nécessaires de chaque source et effectue des jointures intelligentes entre les emplacements, ce qui vous permet d'économiser du temps et des coûts de transfert de data.
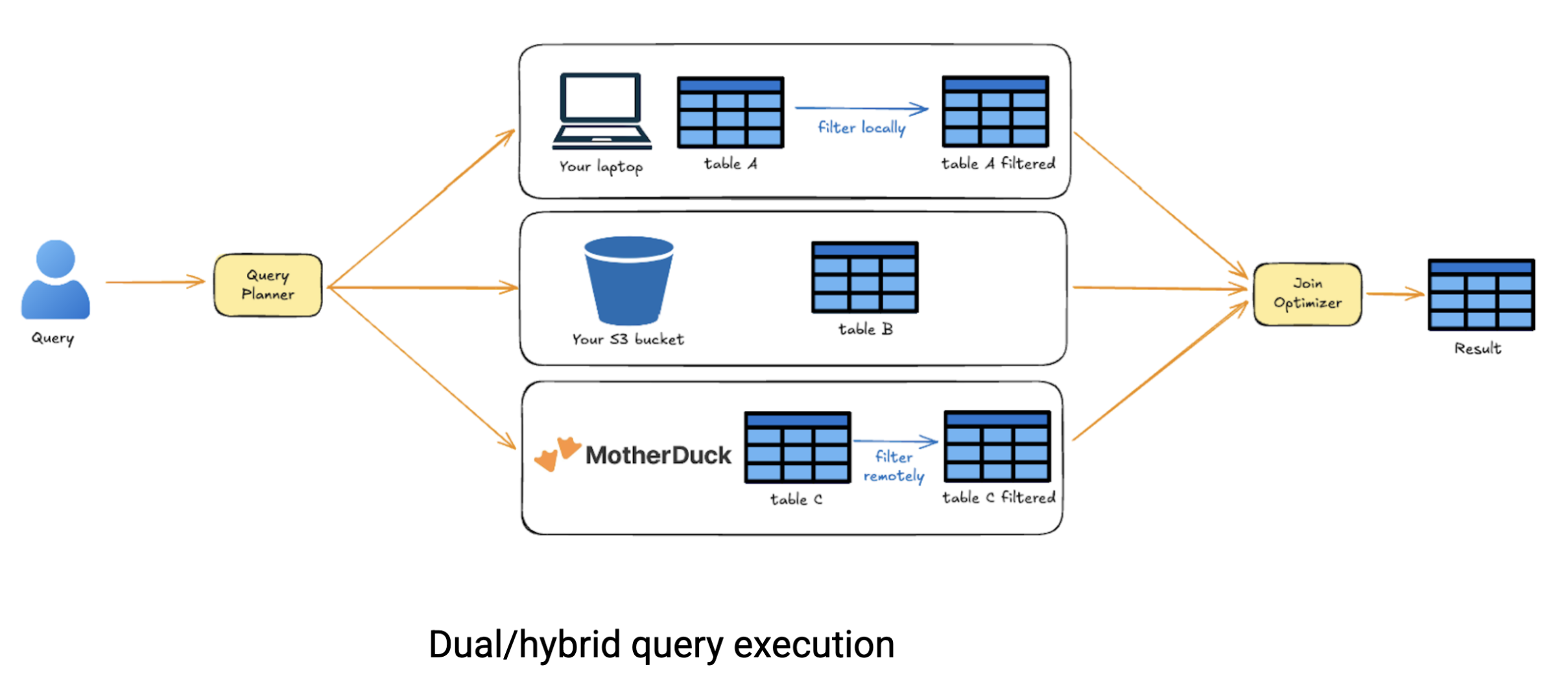
Sous le capot, l'optimiseur de MotherDuck décompose votre requête en un DAG (graphe acyclique dirigé) d'opérations, estime le coût d'exécution de chaque nœud localement ou à distance et gère automatiquement les mouvements data. Il vous suffit d'écrire du code SQL ; MotherDuck détermine la stratégie d'exécution optimale. Cette approche redéfinit fondamentalement l'analyse cloud. Nous ne sommes plus obligés de choisir entre la simplicité locale et l'extensibilité à cloud, chacune avec sa propre complexité en matière de partage data et d'orchestration du flux de travail. Avec MotherDuck, vous obtenez le meilleur des deux mondes : exécutez localement lorsque votre machine peut le supporter, passez à l'échelle cloud lorsque c'est nécessaire, et partagez sans effort tout au long du processus. Il s'agit d'une solution sans serveur qui réduit les coûts de calcul du cloud car vous ne payez que pour ce que vous calculez réellement.
Mais c'est là que les choses deviennent intéressantes : le partage de data se fait sans effort. Vous souvenez-vous que la nature mono-utilisateur de DuckDB rendait la collaboration pénible ? Si un analyste de data créait une analyse étonnante, il devait tout exporter et le télécharger vers un système de stockage partagé juste pour permettre à ses coéquipiers d'y accéder. Avec MotherDuck, le partage est aussi simple que de cliquer sur un bouton ou d'exécuter une seule ligne de code pour créer un instantané sans copie avec les contrôles d'accès appropriés. Pas de déplacement de data, pas de duplication du stockage, juste une collaboration instantanée.
Pour en savoir plus sur l'exécution de requêtes doubles/hybrides, consultez l'article de MotherDuck (en anglais). la Conférence sur la recherche en matière de systèmes Data innovants (CIDR). Vous pouvez également regarder ceci dbt Coalesce talk par Jordan Tigani, cofondateur et directeur général de MotherDuck.
Les canards en liberté
Nous avons vu comment MotherDuck supprime une part importante des frais généraux des équipes data tout en offrant de puissantes capacités d'analyse pour votre couche d'or. Mais la théorie n'a qu'une portée limitée. Nous avons voulu mettre MotherDuck à l'épreuve face à des acteurs établis dans le domaine des entrepôts cloud data. En examinant les Data Rapport sur les piles de 2025 publié par Metabase, nous avons trouvé quelque chose de surprenant : PostgreSQL reste le choix database le plus populaire, même pour les charges de travail analytiques, suivi par Snowflake et BigQuery parmi les entreprises interrogées. Cela nous a donné nos cibles de comparaison.
Nous avons décidé de comparer MotherDuck à PostgreSQL hébergé sur Google Cloud et à BigQuery, en utilisant les outils suivants Superset Apache comme notre outil de BI de prédilection. Superset avait du sens pour plusieurs raisons : il est open source, largement adopté, et il a une compatibilité native avec MotherDuck ainsi qu'avec la plupart des autres bases data majeures. Notre environnement de test était composé d'Apache Superset déployé sur Google Cloud Kubernetes Engine, connecté à trois backends différents : BigQuery, PostgreSQL sur Cloud SQL, et MotherDuck.
Nous avons structuré nos tests en deux phases. Tout d'abord, nous avons exécuté le benchmark TPC-H : un benchmark standardisé d'aide à la décision qui nous montrerait comment MotherDuck se comporte dans un environnement contrôlé et théorique. Ensuite, nous nous sommes rapprochés de la réalité, en testant la relation entre Superset et MotherDuck par rapport aux entrepôts traditionnels data dans des scénarios de tableaux de bord réels.
Analyse comparative TPC-H
TPC-H est la norme pour tester les performances analytiques de database. Il s'agit d'un benchmark d'aide à la décision conçu pour examiner de grands volumes de data, exécuter des requêtes complexes et fournir des réponses à des questions commerciales critiques dans différents secteurs d'activité. Vous pouvez trouver la spécification complète dans le documentation officielle. Le benchmark se compose de 22 requêtes qui simulent des charges de travail analytiques réelles, allant de simples agrégations à des jointures complexes entre plusieurs tables.
Nous avons exécuté chaque requête individuellement dans le laboratoire SQL de Superset pour les trois bases data : MotherDuck, BigQuery et PostgreSQL.. Nous avons également testé les requêtes directement dans l'interface graphique de MotherDuck afin d'éliminer la latence client-serveur et parce que, franchement, toute entreprise utilisant MotherDuck ferait probablement travailler ses analystes data dans l'interface inspirée du carnet de notes de MotherDuck plutôt que dans le laboratoire SQL de Superset. En outre, l'application MotherDuck peut exploiter l'architecture WebAssembly dont nous avons parlé précédemment, et nous étions curieux de voir comment cette exécution basée sur un navigateur se comporterait par rapport aux modèles serveur-client traditionnels. Pour garantir des tests équitables, le cache de Superset a été désactivé dans tous les benchmarks.
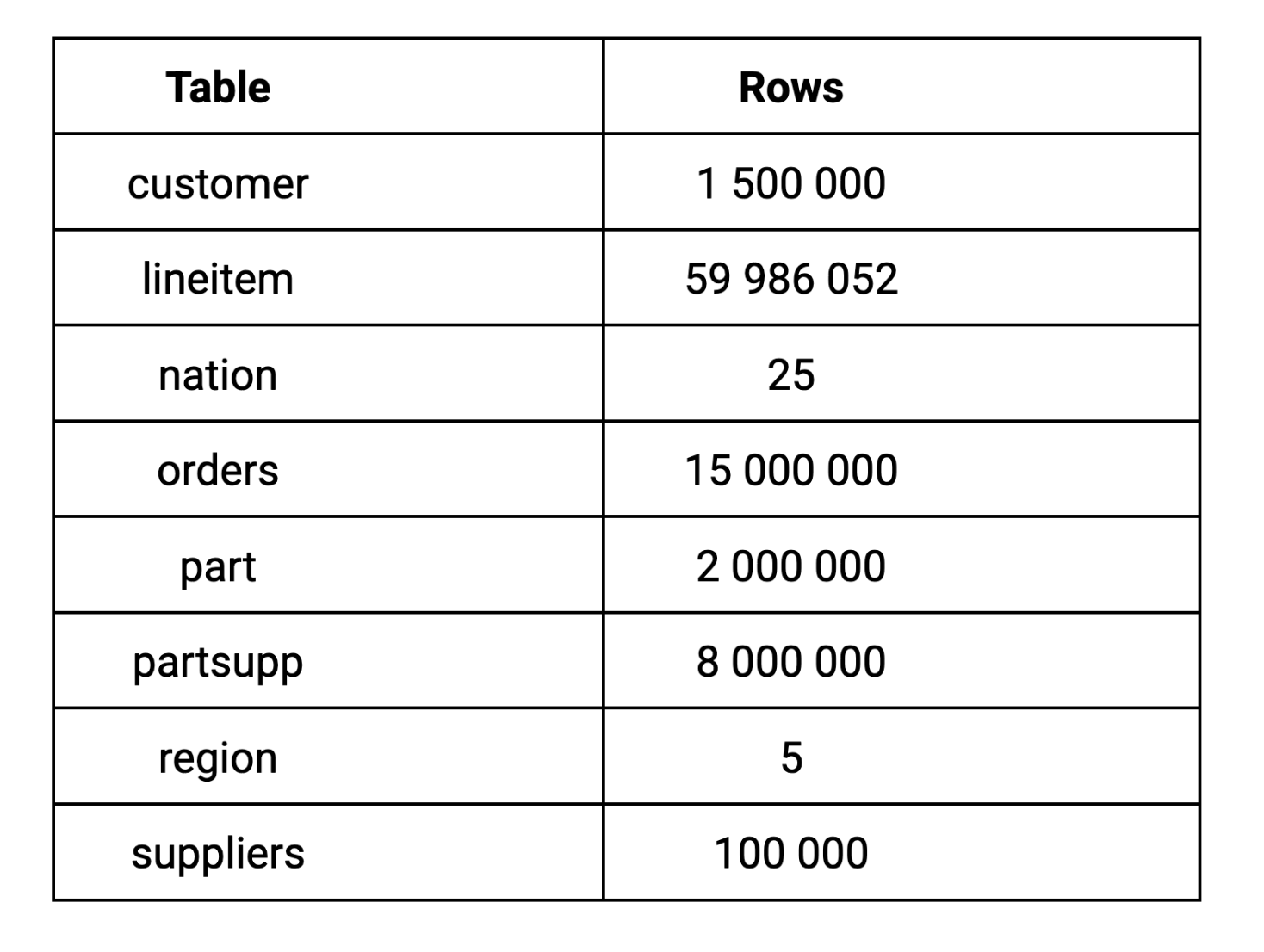
Pour ce benchmark, nous avons utilisé le facteur d'échelle 10 (SF-10) de TPC-H, qui génère un dataset de 10 Go. Nous avons choisi le facteur d'échelle 10 parce que 10 Go représente une taille de dataset réaliste pour les charges de travail analytiques de la plupart des entreprises, suffisamment importante pour révéler des différences de performances significatives sans nécessiter une infrastructure à l'échelle de l'entreprise. Voici comment le data se décompose dans les tables clés :
Nous avons utilisé l'extension TPC-H de DuckDB pour générer le data localement, puis nous l'avons téléchargé en toute transparence sur MotherDuck. Le processus n'a pris que quelques minutes grâce aux capacités de chargement du data de MotherDuck.
Voici les résultats TPC-H SF-10 en secondes. La colonne jaune montre les résultats de l'interface native de l'application MotherDuck, tandis que les autres colonnes représentent les performances à travers le laboratoire SQL de Superset (SST) :
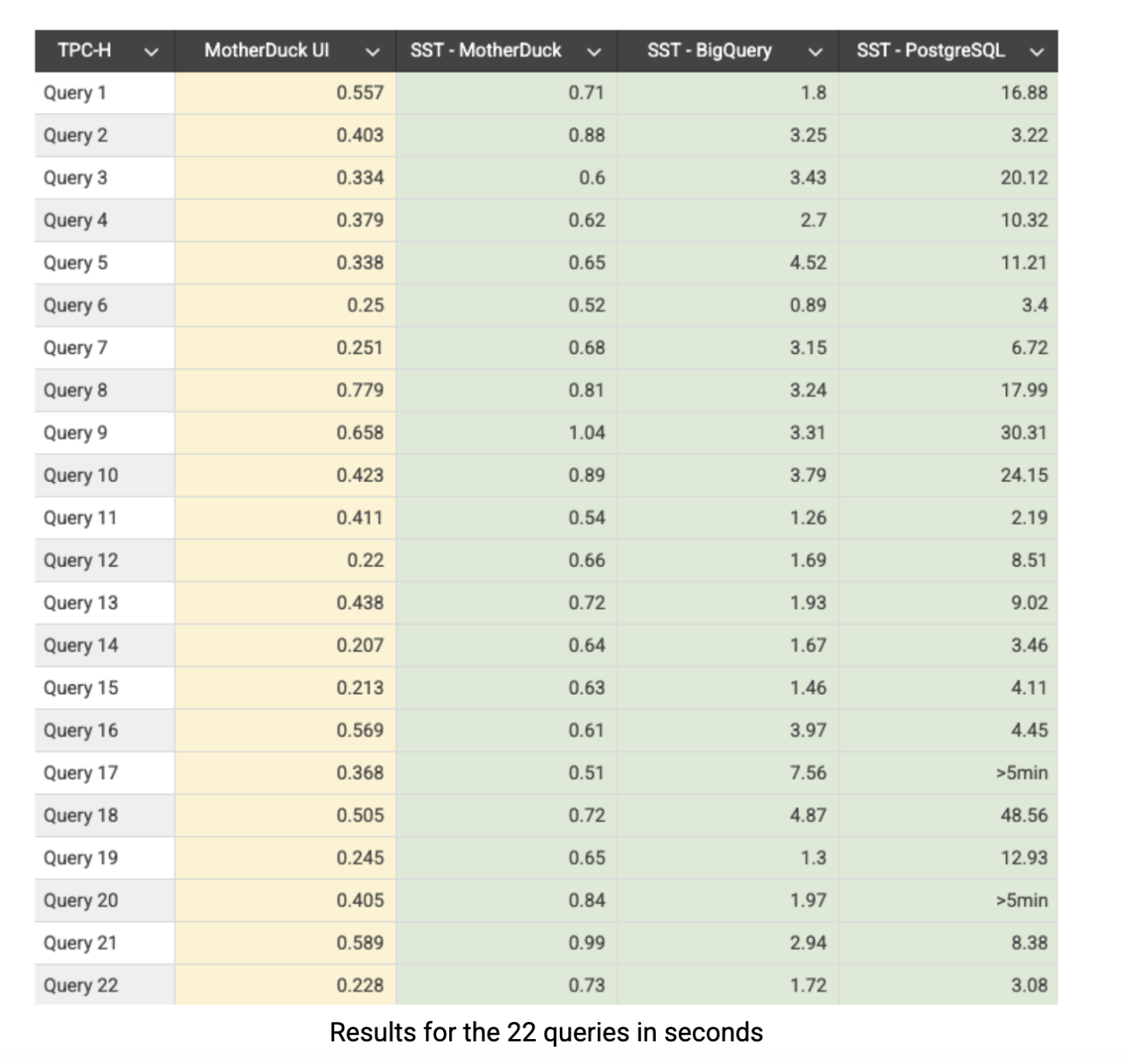
MotherDuck offre constamment des performances inférieures à la seconde dans tous les domaines : 21 des 22 requêtes effectuées par Superset se terminent en moins d'une seconde, Toutes les requêtes sont effectuées en moins d'une seconde lorsqu'elles sont exécutées directement via l'application MotherDuck. BigQuery affiche des performances respectables, mais avec une moyenne de environ 4x plus lent que MotherDuck sur l'ensemble des tests. L'histoire de PostgreSQL est tout à fait différente, avec des performances nettement plus lentes et des difficultés évidentes pour les agrégations et les jointures complexes. C'était prévisible puisque PostgreSQL est fondamentalement conçu pour les charges de travail OLTP plutôt que pour le traitement analytique, mais nous l'avons inclus dans notre comparaison parce qu'il reste largement utilisé par les entreprises pour les tâches analytiques. Il convient de noter que PostgreSQL pourrait atteindre de bien meilleures performances avec des techniques d'optimisation appropriées telles que l'indexation, le partitionnement ou les vues matérialisées, mais même dans ce cas, il devrait encore se battre contre son architecture basée sur les lignes. L'écart de performance souligne exactement la raison d'être des systèmes OLAP spécialisés comme MotherDuck : lorsque vous exécutez des requêtes analytiques complexes sur des ensembles data substantiels, l'architecture a une importance considérable.
Si le TPC-H indique les performances brutes des requêtes, le véritable test est de savoir comment elles se traduisent en termes d'expérience utilisateur dans les outils de veille économique.
Tableau de bord des performances
Nous avons constaté que les performances étaient excellentes pour les analystes data travaillant avec SQL sur leur entrepôt data, mais nous voulions vérifier si cette amélioration se traduirait par des tableaux de bord, là où les acteurs de l'entreprise interagissent réellement avec le data. Après tout, des requêtes SQL ultra-rapides n'ont pas beaucoup d'importance si vos tableaux de bord mettent toujours une éternité à se charger.
Pour tester cela, nous avons utilisé un ensemble réaliste de commerce électronique dataset de Kaggle contient 67,5 millions de lignes sur 9 Go de data, le genre d'échelle avec laquelle de nombreuses entreprises travaillent pour leurs analyses mensuelles des clients. À partir de ce tableau unique, nous avons élaboré un tableau de bord complet permettant de tester la capacité de chaque système à gérer des charges de travail de veille stratégique dans le monde réel :
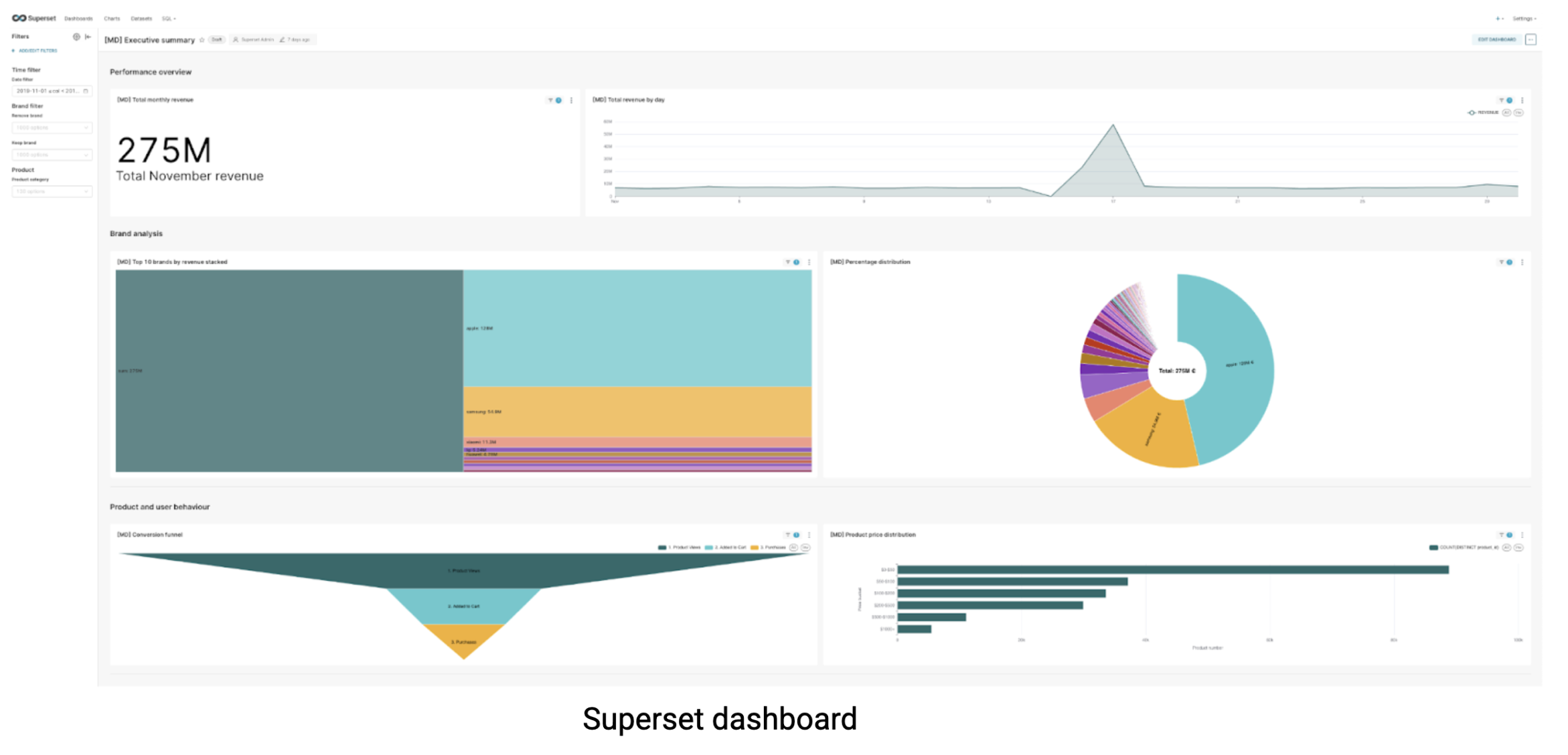
J'ai testé le tableau de bord à plusieurs reprises, en appliquant divers filtres, en mesurant les temps de chargement, en désactivant la mémoire cache et en surveillant les temps de réponse à l'aide des outils de développement de mon navigateur. Après plusieurs cycles de test pour garantir des résultats cohérents, voici les mesures de performance du tableau de bord en quelques secondes :
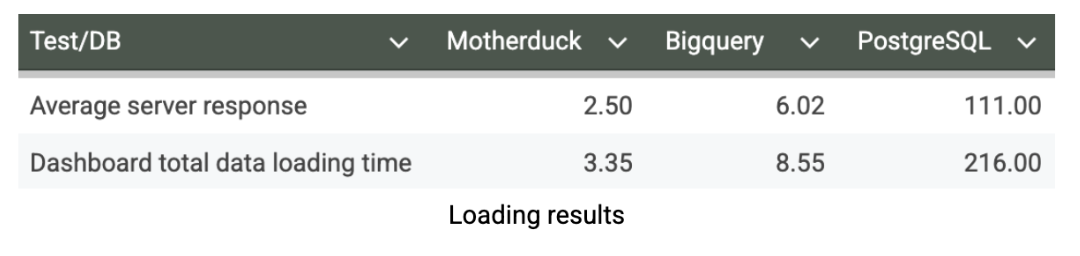
Nos tests de chargement des tableaux de bord révèlent les implications pratiques des performances de database sur l'expérience de l'utilisateur. MotherDuck offre une réactivité exceptionnelle des tableaux de bord avec un temps de chargement moyen de seulement 3,35 secondes, ce qui permet des analyses véritablement interactives où les utilisateurs peuvent explorer data de manière fluide et sans friction. En revanche, BigQuery nécessite 8,55 secondes pour charger le même tableau de bord. C'est encore acceptable pour les rapports planifiés, mais cela crée des retards notables qui peuvent décourager l'analyse exploratoire. Le temps de chargement de 216 secondes (>3 minutes) de PostgreSQL le rend totalement impraticable pour l'utilisation de tableaux de bord. Cet avantage en termes de performances que représente MotherDuck peut transformer fondamentalement la manière dont les utilisateurs professionnels interagissent avec data. Lorsque les tableaux de bord se chargent en quelques secondes plutôt qu'en quelques minutes, l'adoption par les utilisateurs monte en flèche, les analystes peuvent rapidement mettre en pratique leurs idées et l'analyse devient un avantage concurrentiel plutôt qu'un goulot d'étranglement.
Comparaison des prix
MotherDuck combine le stockage avec pay-as-you-go optimisé pour l'analyse interactive. Parce qu'il s'étend sur une seule machine au lieu d'être distribué sur un cluster, il évite les frais généraux que les utilisateurs finissent par payer. Une session de dizaines de requêtes peut ne coûter que $0,05-$0,10, tandis qu'une équipe exécutant des milliers de requêtes par mois peut ne dépenser que $20-$40. En revanche, les bases de data toujours actives peuvent coûter $300-$500/mois simplement pour rester en activité, et les entrepôts de cloud facturent souvent $5-$10 par TB scanné. Grâce à sa conception évolutive, MotherDuck maintient une tarification simple, prévisible et rentable.

MotherDuck peut sembler plus cher à première vue en raison de ses frais d'organisation et de son modèle de tarification informatique différent. Cependant, les deux systèmes utilisent des modèles de tarification qui favorisent des schémas d'utilisation différents : BigQuery excelle dans le traitement de gros lots, tandis que MotherDuck est optimisé pour les analyses interactives. Pour notre benchmark TPC-H, l'exécution de 22 requêtes sur SF-10 a coûté $0,03 pour MotherDuck contre $0,60-$1,00 pour BigQuery. Si l'on tient compte des frais généraux d'infrastructure (notre installation PostgreSQL nécessitait 14 €/jour pour rester en ligne), l'approche sans serveur de MotherDuck offre souvent un coût total de possession supérieur pour les charges de travail analytiques interactives.
À l'échelle de l'entreprise, les aspects économiques changent en fonction des schémas d'utilisation. BigQuery devient plus rentable pour le traitement par lots de très gros volumes, tandis que MotherDuck conserve son avantage pour les analyses interactives et les flux de travail exploratoires. L'idée clé : choisissez votre modèle de tarification en fonction de la manière dont votre équipe travaille réellement avec data, et pas seulement en fonction des coûts unitaires bruts.
Note : Tous les exemples de prix sont basés sur la région europe-west4 et doivent être considérés comme illustratifs plutôt qu'exacts, car les coûts réels dépendent fortement des modèles d'utilisation spécifiques et des caractéristiques du data.
Pour conclure
MotherDuck représente un changement fondamental dans la façon dont nous envisageons les bases analytiques de data, un changement qui remet en question l'hypothèse selon laquelle vous avez besoin de systèmes complexes et distribués pour gérer des charges de travail sérieuses de data. En reprenant la philosophie intégrée de DuckDB et en l'étendant au cloud, MotherDuck offre les capacités de collaboration dont les équipes data modernes ont besoin, tout en conservant les performances brutes qui rendent DuckDB exceptionnel.
Les résultats de nos analyses comparatives sont éloquents : MotherDuck a constamment surpassé BigQuery et PostgreSQL par des marges significatives, offrant des performances d'interrogation inférieures à la seconde sur des ensembles data de 10 Go et des temps de chargement de tableau de bord qui permettent des analyses véritablement interactives. L'avantage en termes de performances par rapport à BigQuery et le très large avantage par rapport à PostgreSQL dans les scénarios de tableaux de bord ne se limitent pas à des requêtes plus rapides, il s'agit de transformer l'analyse en une expérience plus interactive et exploratoire qui encourage la prise de décision data-driven.
Plus important encore, MotherDuck atteint ces performances tout en réduisant considérablement la complexité et les coûts de l'infrastructure. Alors que les configurations cloud traditionnelles nécessitent une infrastructure permanente coûtant des centaines de dollars par mois, le modèle sans serveur de MotherDuck ne facture que l'utilisation réelle, ce qui réduit souvent les coûts. La tarification à l'unité de calcul s'aligne parfaitement sur la façon dont les analystes travaillent réellement : exécution de plusieurs requêtes dans des sessions d'exploration plutôt que des requêtes isolées et peu fréquentes.
Les implications vont au-delà des performances et des coûts. Le double modèle d'exécution de MotherDuck et ses capacités d'analyse basées sur un navigateur suggèrent un avenir où la frontière entre l'informatique locale et l'informatique cloud devient de plus en plus fluide. Au lieu de forcer les équipes à choisir entre la simplicité locale et l'extensibilité à cloud, MotherDuck offre les deux, en acheminant intelligemment les calculs là où ils sont le plus utiles.
Ce qui m'a vraiment impressionné pendant les tests, c'est la simplicité d'utilisation et d'installation de MotherDuck. Le modèle d'exécution double m'a permis d'interroger le data à la fois localement et simultanément dans le cloud, tandis que l'établissement de la connexion entre Superset et MotherDuck a été remarquablement simple.
Pour les organisations qui cherchent à moderniser leurs capacités analytiques en commençant par la couche d'or, MotherDuck offre une proposition très attrayante : des performances de niveau entreprise, des flux de travail collaboratifs et une rentabilité, le tout sans les frais généraux opérationnels de l'infrastructure d'entrepôt data traditionnelle. Dans un monde où les décisions data-driven déterminent de plus en plus l'avantage concurrentiel, la capacité d'explorer data de manière interactive à des vitesses inférieures à la seconde n'est pas seulement un avantage, elle devient essentielle.
Prêt à vivre la performance de MotherDuck par vous-même ? Vous pouvez commencer par un Essai gratuit de 21 jours ou avec leur plan gratuit de 10GB pour le tester avec vos propres ensembles data et charges de travail. Si vous souhaitez savoir si MotherDuck convient à votre pile data spécifique ou si vous avez besoin d'aide pour la mise en œuvre, contactez notre équipe à l'adresse suivante Artefact, Si vous le souhaitez, nous nous ferons un plaisir d'évaluer vos besoins en matière d'analyse et de vous aider à passer à une infrastructure analytique plus efficace et plus rentable.
