


Resumen ejecutivo
MotherDuck amplía el rendimiento analítico de DuckDB al cloud con funciones de colaboración, ofreciendo un rendimiento 4 veces más rápido que BigQuery y un ahorro de costes con respecto a los almacenes data tradicionales gracias a unos precios de pago por uso sin servidor. Tras el anuncio de la nueva región europea cloud de MotherDuck, quedamos impresionados por su rendimiento y su atractivo precio. MotherDuck ya puede integrarse en sus capas de oro para acelerar el servicio de casos de uso data y ahorrar costes al mismo tiempo. Vea la comparativa de rendimiento.
Introducción
En el panorama en rápida evolución de la analítica data, un nuevo actor está desafiando el orden establecido de los almacenes cloud data. MotherDuck, construido sobre la base de DuckDB‘promete ofrecer un rendimiento de nivel empresarial con la sencillez y rentabilidad que anhelan los equipos data modernos. Pero, ¿puede este pato competir realmente con los gigantes establecidos?
Sometimos a MotherDuck a rigurosas pruebas frente a competidores establecidos para ver si está a la altura de las expectativas. Lo que descubrimos desafía el statu quo actual de las bases data analíticas y sugiere un cambio fundamental en la forma de enfocar el procesamiento data basado en cloud. Esta es la historia de cómo una database embebida aprendió a volar, y por qué podría revolucionar su pila data.
Para captar a este cliente en evolución, los minoristas deben adaptarse rápidamente.
Un pato incubando
MotherDuck se describe a sí mismo como un “almacén DuckDB cloud data escalable a terabytes para análisis y BI de cara al cliente”. Para entender qué hace especial a este almacén cloud data, primero tenemos que fijarnos en DuckDB, el sistema database de código abierto que ha estado revolucionando silenciosamente la pila data en los últimos años. En términos sencillos, DuckDB es un sistema database OLAP SQL en memoria. Para aquellos que no viven y respiran la jerga database, vamos a desentrañar lo que eso significa en realidad:
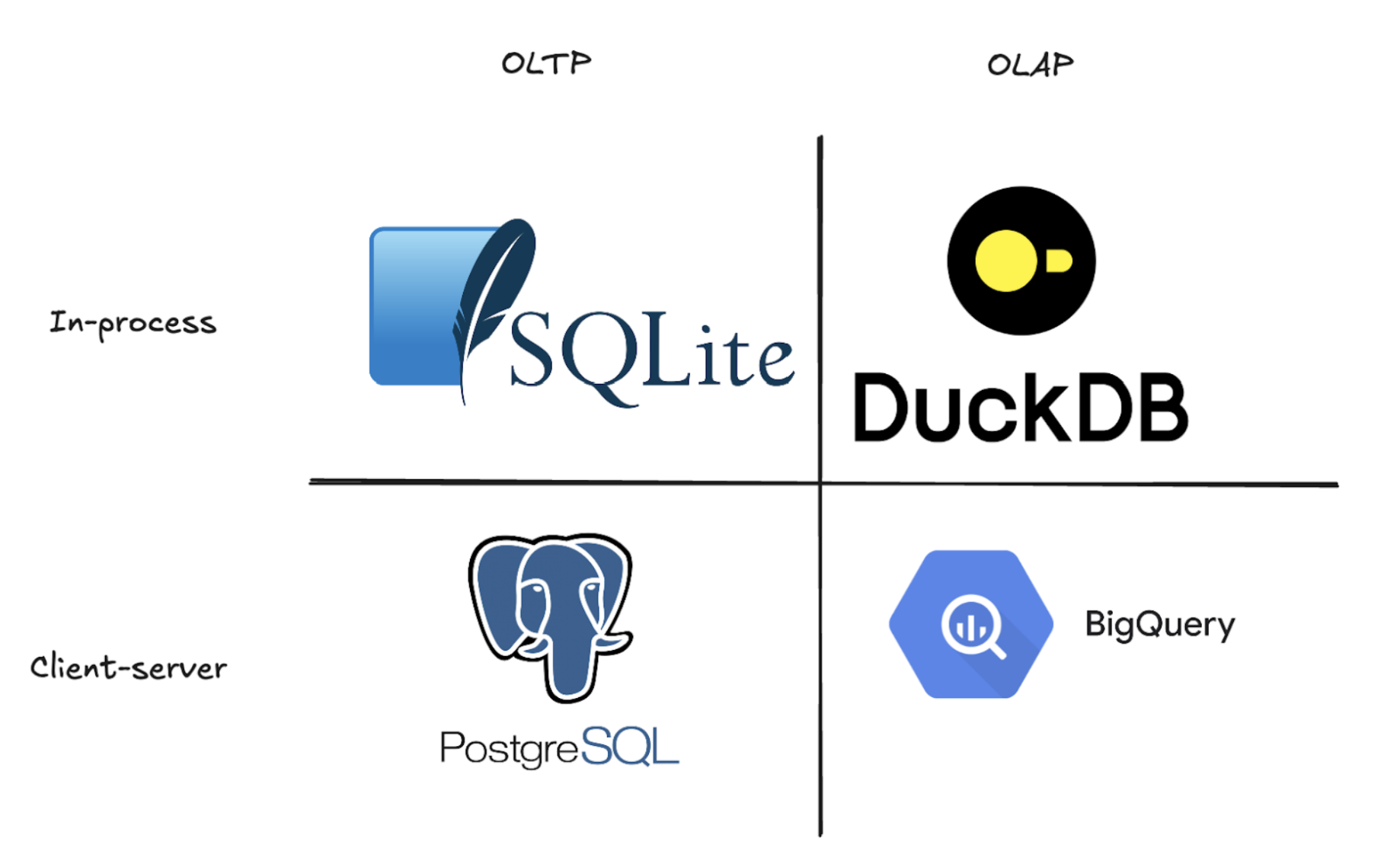
OLAP significa procesamiento analítico en línea. Piense en ella como una database diseñada para analizar cantidades masivas de data y responder rápidamente a preguntas empresariales complejas. A diferencia de las bases data tradicionales, que destacan en la búsqueda de registros individuales (como buscar el pedido de un cliente), las bases data OLAP están construidas para escanear millones de filas y realizar cálculos pesados en cuestión de segundos. Consiguen esta velocidad almacenando data en columnas en lugar de en filas, lo que hace que sea rapidísimo analizar tendencias, calcular medias o sumar ventas en conjuntos enteros de data. Este es el mismo enfoque que utilizan los almacenes data modernos como BigQuery o Snowflake. En el lado opuesto, están las bases data OLTP (procesamiento de transacciones en línea) como PostgreSQL, SQLite o MySQL. Estos son los caballos de batalla que impulsan sus aplicaciones, manejando miles de lecturas y escrituras individuales por segundo para mantener su aplicación funcionando sin problemas. Ver más sobre OLAP vs OLTP.
Para entender lo revolucionario que es realmente el enfoque de DuckDB, tenemos que dar un paso atrás y mirar cómo hemos llegado hasta aquí. A mediados de los noventa, cuando gigantes de la web como Yahoo y Amazon irrumpieron en escena, se toparon con un muro que remodelaría todo el panorama del data. Estas empresas se estaban ahogando en data, lo que más tarde llamaríamos “gran data”, y sus sistemas existentes simplemente no podían seguirles el ritmo. ¿La solución? Caras infraestructuras monolíticas que pudieran manejar la escala. Pero cuando los costes del hardware cayeron en picado en la década de 2000, surgió una nueva filosofía: en lugar de comprar máquinas más grandes, ¿por qué no utilizar muchas más pequeñas y baratas? Este pensamiento dio origen a sistemas distribuidos como MapReduce y Apache Hadoop, tecnologías diseñadas para repartir las cargas de trabajo entre clusters de hardware básico. Amazon capitalizó esta tendencia, empaquetando estas tecnologías distribuidas como servicios y lanzando Amazon Web Services, la primera gran plataforma cloud. Durante años, esto se convirtió en el libro de jugadas por defecto: cuando se planteaba un problema data, se distribuía entre más máquinas (Fundamentals of Data Engineering, Joe Reis & Matt Housley).
Pero he aquí lo fascinante: mientras todo el mundo estaba ocupado construyendo sistemas distribuidos, algo más ocurría silenciosamente en segundo plano. Las mismas fuerzas que hicieron que la informática distribuida fuera económica, también hicieron que las máquinas individuales fueran increíblemente potentes. Su ordenador portátil de hoy en día se ha vuelto increíblemente potente con más RAM, procesadores más rápidos y mejor almacenamiento. Los desarrolladores detrás de DuckDB reconocieron esta oportunidad pasada por alto: ¿y si, en lugar de escalar siempre hacia fuera, pudiéramos escalar hacia arriba de forma más inteligente? ¿Y si pudiéramos resolver muchos problemas data sin la complejidad de los sistemas distribuidos en absoluto?
Uno de los motores database más desplegados del mundo, SQLite adopta un enfoque radicalmente distinto al de las databases tradicionales. Mientras que PostgreSQL y MySQL se ejecutan como servidores independientes a los que las aplicaciones se conectan a través de una red, SQLite se integra directamente en su aplicación como una biblioteca ligera. No hay ningún servidor que configurar, ninguna sobrecarga de red ni ninguna configuración compleja, sólo funcionalidad database pura y local que se ejecuta dentro del proceso de su aplicación. Esta simplicidad, combinada con una notable fiabilidad y velocidad, ha hecho que SQLite sea omnipresente en todo tipo de aplicaciones, desde aplicaciones móviles hasta navegadores web.
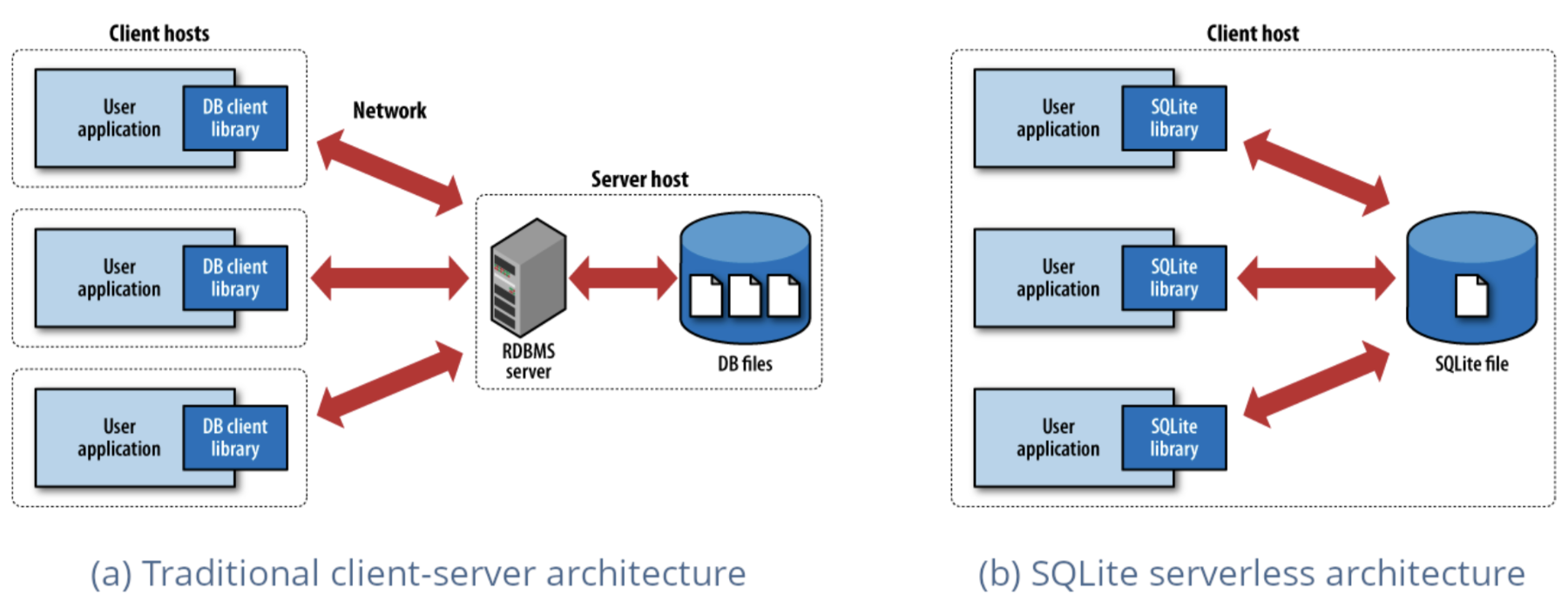
DuckDB aplica esta misma filosofía integrada a las cargas de trabajo analíticas, demostrando que no siempre se necesita un sistema distribuido para hacer crujir grandes conjuntos de data. Al igual que SQLite revolucionó el almacenamiento local de data, DuckDB aprovecha la potencia bruta de su máquina local para que la analítica vuelva a ser sencilla. La instalación se realiza en cuestión de segundos, no hay dependencias externas con las que luchar y, de repente, estará ejecutando consultas analíticas complejas en gigabytes de data sin necesidad de poner en marcha una sola instancia de cloud.
Lo que hace que DuckDB sea especialmente convincente es cómo se encuentra con los desarrolladores allí donde están. ¿Necesita analizar un DataFrame de Python? DuckDB puede consultarlo directamente. ¿Quiere analizar un archivo CSV? No hay problema. Esta perfecta integración, combinada con su rapidísimo motor columnar, ha convertido a DuckDB en uno de los sistemas database de más rápido crecimiento en el espacio analítico. Las ganancias de rendimiento son a menudo lo suficientemente espectaculares como para hacerle cuestionarse por qué utilizaba sistemas distribuidos en primer lugar. Si desea profundizar en la filosofía técnica que subyace a este enfoque, le recomendamos encarecidamente la lectura de “Gestión analítica en proceso Data con DuckDB” por el co-creador de DuckDB, Hannes Mühleisen.
Ahora que entiende lo que es DuckDB, hablemos de sus limitaciones. Toda tecnología tiene sus limitaciones. DuckDB sólo puede funcionar en una única máquina y sólo acepta una conexión a la vez. En un mundo en el que los equipos data construyen soluciones cloud-nativas que sirven a organizaciones enteras, ésta es una limitación bastante importante. No puede tener varios analistas consultando simultáneamente la misma instancia de DuckDB y, desde luego, no puede compartir datasets entre equipos como lo haría con un almacén data tradicional. A pesar de toda su velocidad y simplicidad, DuckDB encierra esencialmente su data en una sola máquina, accesible a una sola persona a la vez. Entonces, ¿cómo tomar esta base data increíblemente rápida pero inherentemente monousuario y convertirla en un almacén cloud data que pueda servir a toda una organización?
El pato que aprendió a volar
Aquí es donde entra en escena MotherDuck. MotherDuck es un almacén data sin servidor que tiende un puente entre el rendimiento bruto de DuckDB y las necesidades de colaboración de los equipos data modernos. MotherDuck crea lo que ellos denominan un “almacén data de análisis individualizado” que proporciona a cada usuario su propia instancia DuckDB de alto rendimiento al tiempo que mantiene la capacidad de compartir data en toda la organización. He aquí cómo funciona la arquitectura:
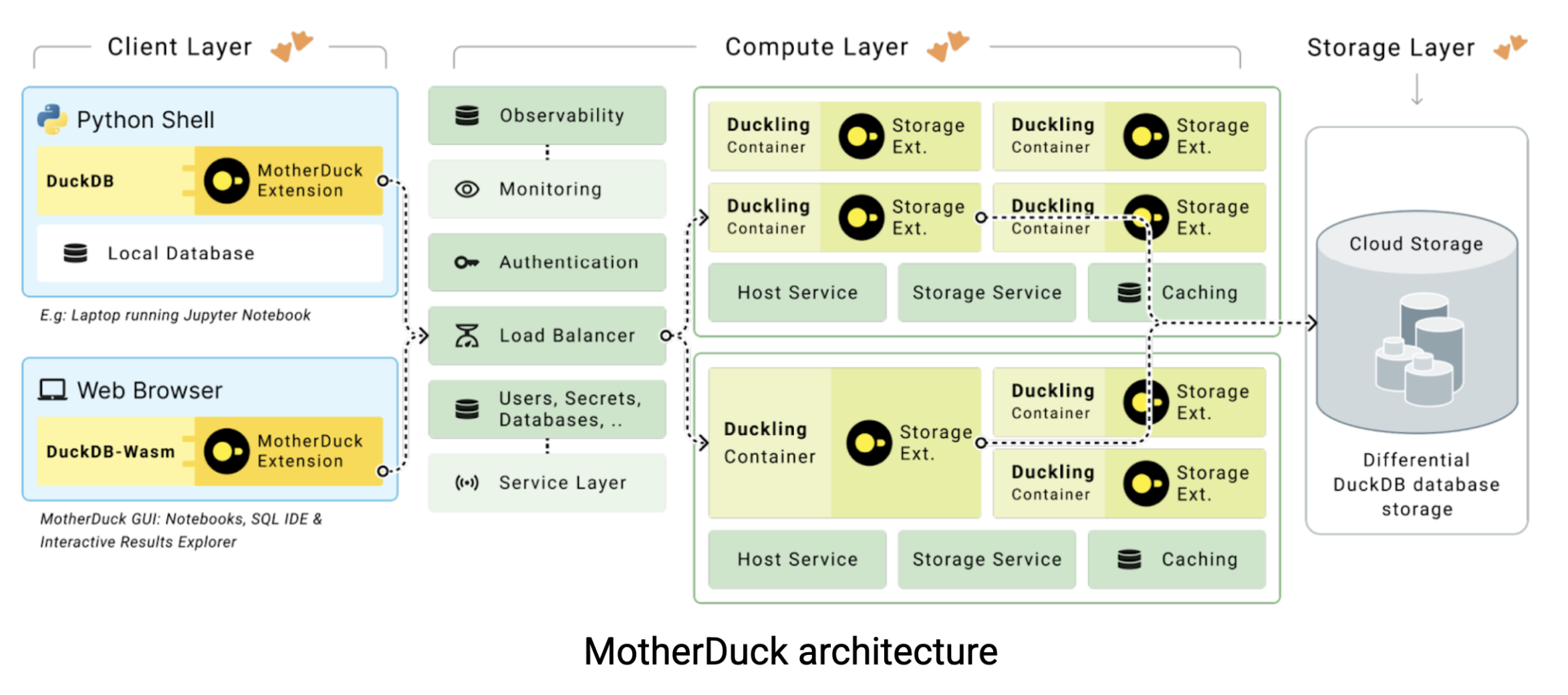
En los almacenes tradicionales cloud data, su portátil no es más que un terminal tonto. Todo el trabajo pesado se realiza en servidores remotos por los que usted paga por horas. Pero he aquí la cuestión: su MacBook es probablemente más rápido que una instancia de almacén $20-60 por hora data. MotherDuck intenta aprovechar esta potencia de cálculo con dos enfoques innovadores:
- Análisis basados en el navegador que acercan el cálculo directamente al usuario.
- Doble ejecución que combina de forma inteligente la potencia de procesamiento de su máquina local con los recursos del cloud para ofrecer resultados más rápidos de lo que cualquiera de los dos enfoques podría lograr por sí solo.
Antes de sumergirme en estos dos métodos, me gustaría afirmar que la potencia de cálculo de MotherDuck brilla realmente cuando se aplica a su capa de oro. Para quienes no estén familiarizados con el término, la capa de oro es el data final, listo para el negocio, que se ha limpiado, agregado y enriquecido. Esencialmente son los data pulidos que impulsan sus análisis, informes y aprendizaje automático. Este es el data que impulsa sus decisiones empresariales más críticas, lo que hace que el rendimiento aquí sea absolutamente crucial. Todas las partes interesadas han sufrido con cuadros de mando dolorosamente lentos, y todos los miembros del equipo data se han quedado mirando la rueda giratoria de la muerte mientras esperaban a que terminaran las consultas complejas. MotherDuck aborda esta frustración de frente.
Análisis en el navegador
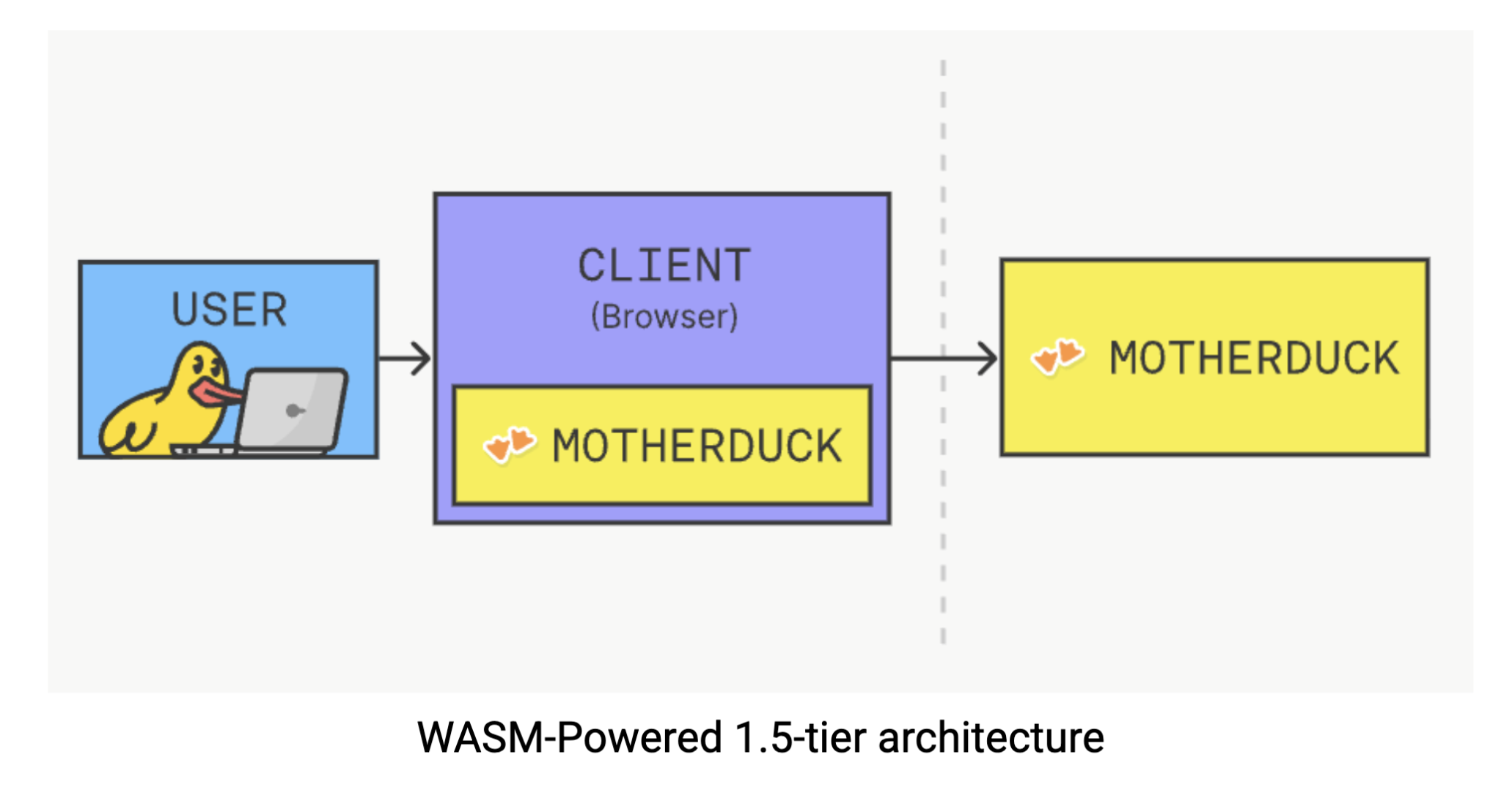
Esta solución aprovecha el diseño ligero y portátil de DuckDB, permitiéndole ejecutarse directamente en su navegador a través de WebAssembly (Wasm). Piense en Wasm como una tecnología que permite ejecutar software complejo de forma nativa en su navegador: sin plugins, sin descargas, sólo potencia de cálculo donde más la necesita. Con DuckDB ejecutándose en el lado del cliente, puede ejecutar consultas analíticas complejas sin el baile habitual de enviar peticiones a un servidor y esperar las respuestas. El procesamiento data tiene lugar directamente en su navegador, eliminando la latencia de la red y reduciendo por completo las dependencias de la infraestructura. Puede experimentar esta magia usted mismo probando DuckDB en su navegador.
Aunque no profundizaremos aquí en la implementación técnica, vale la pena señalar que DuckDB-Wasm sobresale. La investigación detallada en este documento demuestra que supera con creces a las soluciones existentes basadas en navegador, como la versión Wasm de SQLite o Lovefield, una database basada en JavaScript. Esta ingeniosa demostración técnica señala un cambio fundamental en nuestra forma de pensar sobre la ubicación del cálculo analítico.
MotherDuck ofrece esta arquitectura impulsada por Wasm, como explica Mehdi Ouazza en este artículo. Este enfoque es especialmente potente para los análisis de la capa de oro. Su equipo data se pone a trabajar con data limpios y listos para el negocio sin preocuparse de la infraestructura de backend, el procesamiento tiene lugar localmente para lograr la máxima velocidad y usted consigue algunos de los tiempos de respuesta más rápidos posibles al eliminar por completo la latencia de la red. Además, evitará los elevados costes de cálculo que a los almacenes tradicionales cloud data les encanta cobrarle por cada consulta. Es una propuesta convincente: análisis más rápidos, costes más bajos y una arquitectura más sencilla, todo en uno.
Doble ejecución
Otra forma de aprovechar MotherDuck en su capa gold es a través de su capacidad de ejecución dual, que combina de forma inteligente la potencia de procesamiento local con la escala cloud. En lugar de obligar a todo su equipo data a compartir los mismos recursos computacionales, MotherDuck da a cada usuario su propio “patito”: una instancia computacional individual, sin servidor, que escala en función de sus necesidades.
La verdadera potencia de la ejecución dual brilla cuando se trabaja con data dispersos en distintas fuentes. Imagine que necesita realizar consultas data almacenadas en MotherDuck, combinarlas con archivos en S3 y unirlas con un conjunto data que se encuentra localmente en su ordenador portátil. Los sistemas cloud tradicionales le obligarían a cargarlo todo en un único lugar antes de poder ejecutar consultas entre fuentes. La ejecución híbrida de MotherDuck es más inteligente. Analiza su consulta, conserva sólo el data necesario de cada fuente y realiza uniones inteligentes entre ubicaciones, ahorrándole tiempo y costes de transferencia de data.
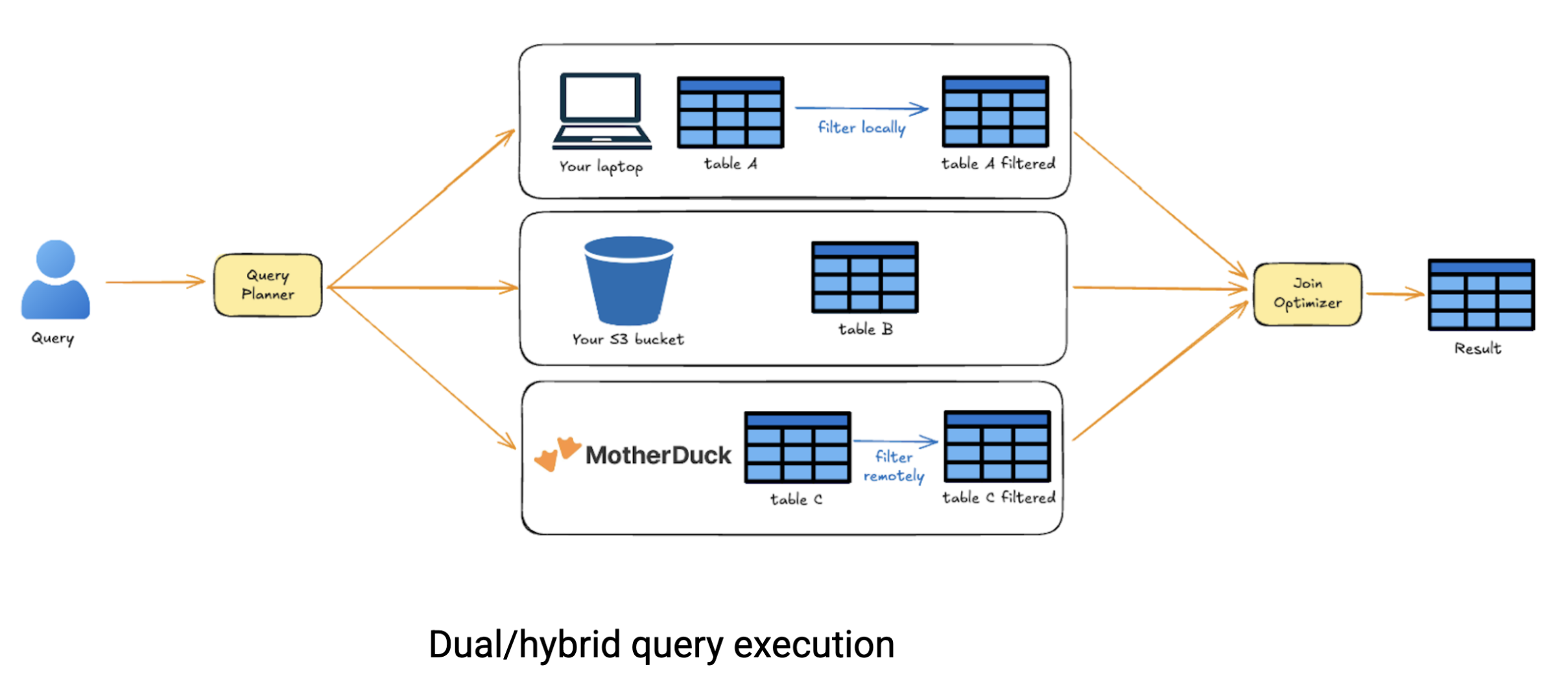
Bajo el capó, el optimizador de MotherDuck descompone su consulta en un DAG (grafo acíclico dirigido) de operaciones, estima el coste de ejecutar cada nodo localmente frente a remotamente y gestiona el movimiento data automáticamente. Usted sólo tiene que escribir SQL; MotherDuck calcula la estrategia de ejecución óptima. Este enfoque redefine fundamentalmente la analítica cloud. Ya no estamos atascados eligiendo entre la simplicidad local y la escalabilidad cloud, cada una con su propia complejidad en torno a la compartición data y la orquestación del flujo de trabajo. Con MotherDuck, obtendrá lo mejor de ambos mundos: ejecútelo localmente cuando su máquina pueda soportarlo, escale al cloud cuando sea necesario y comparta sin esfuerzo en todo momento. Es una solución sin servidor que reduce los costes de computación cloud porque sólo paga por lo que realmente computa.
Pero aquí es donde se pone interesante: compartir data se hace sin esfuerzo. ¿Recuerda cómo la naturaleza monousuario de DuckDB hacía penosa la colaboración? Si un analista de data creaba un análisis asombroso, tenía que exportarlo todo y subirlo a un sistema de almacenamiento compartido sólo para que sus compañeros de equipo pudieran acceder a él. Con MotherDuck, compartir es tan sencillo como pulsar un botón o ejecutar una única línea de código para crear una instantánea de copia cero con los controles de acceso adecuados. Sin movimiento de data, sin duplicación de almacenamiento, sólo colaboración instantánea.
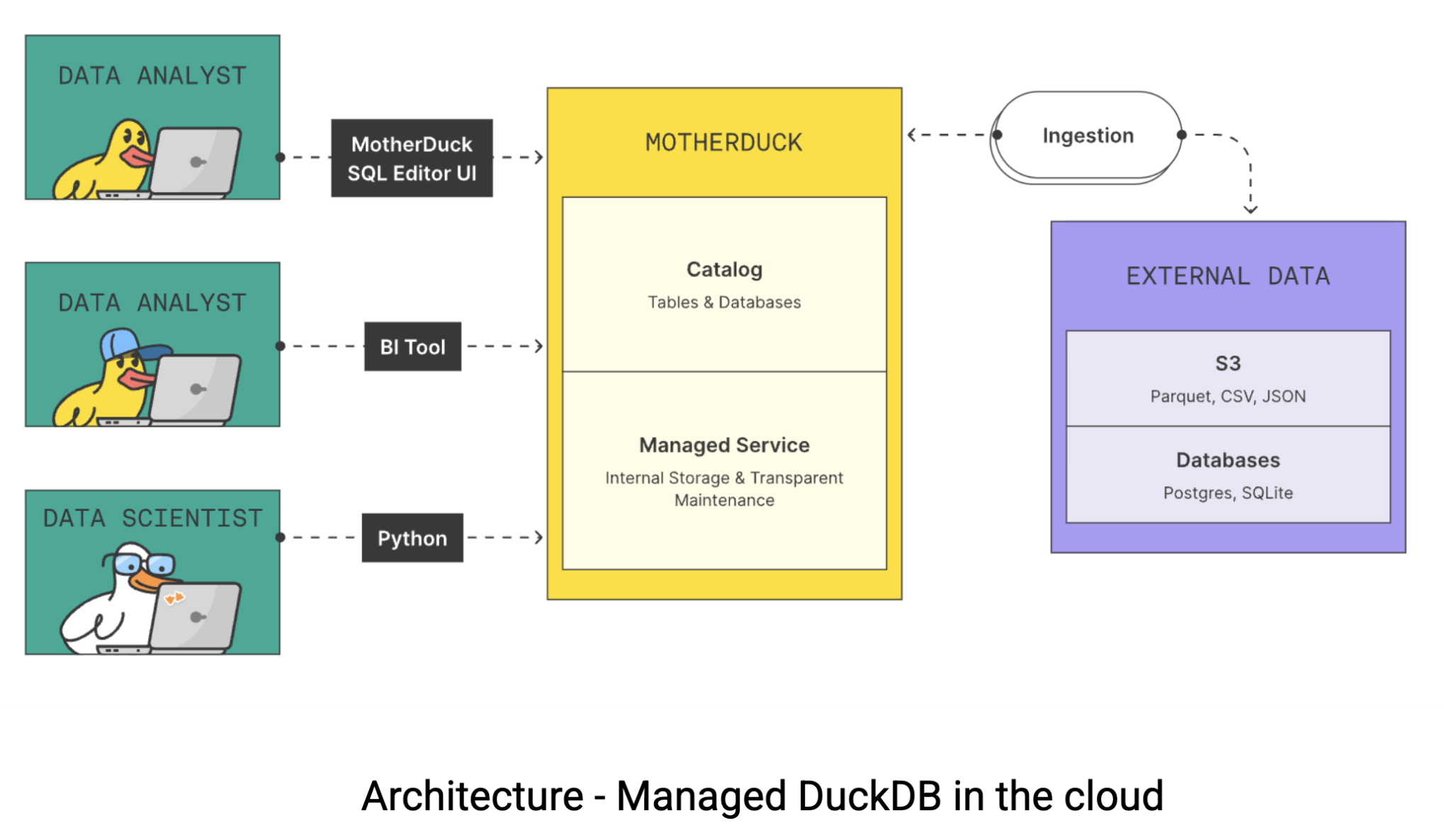
Obtenga más información sobre la ejecución de consultas duales/híbridas en el documento de MotherDuck de la Conferencia sobre Investigación Innovadora en Sistemas Data (CIDR). También puede ver esto dbt Coalescer hablar por Jordan Tigani, cofundador y director general de MotherDuck.
Patos en libertad
Hemos visto cómo MotherDuck elimina una importante sobrecarga de los equipos data a la vez que ofrece potentes capacidades analíticas para su capa de oro. Pero la teoría sólo llega hasta cierto punto. Queríamos poner a prueba a MotherDuck frente a jugadores establecidos en el espacio de almacenes cloud data. Observando el Informe sobre la pila Data de 2025 publicado por Metabase, encontramos algo sorprendente: PostgreSQL sigue siendo la opción database más popular, incluso para cargas de trabajo analíticas, seguida de Snowflake y BigQuery entre las empresas encuestadas. Esto nos dio nuestros objetivos de comparación.
Decidimos comparar MotherDuck con PostgreSQL alojado en Google Cloud y BigQuery, utilizando Superset Apache como nuestra herramienta de BI elegida. Superset tenía sentido por varias razones: es de código abierto, está ampliamente adoptada y tiene compatibilidad nativa con MotherDuck junto con la mayoría de las demás bases databases principales. Nuestro entorno de pruebas consistió en Apache Superset desplegado en Google Cloud Kubernetes Engine, conectado a tres backends diferentes: BigQuery, PostgreSQL en Cloud SQL y MotherDuck.
Estructuramos nuestras pruebas en dos fases. En primer lugar, ejecutamos el benchmark TPC-H: un benchmark estandarizado de apoyo a la toma de decisiones que nos mostraría el rendimiento de MotherDuck en un entorno controlado y teórico. Después nos acercamos más a la realidad, probando cómo la relación entre Superset y MotherDuck se comparaba con los almacenes tradicionales data en escenarios de cuadros de mando del mundo real.
Evaluación comparativa TPC-H
TPC-H es el estándar para probar el rendimiento analítico database. Es un punto de referencia de apoyo a la toma de decisiones diseñado para examinar grandes volúmenes de data, ejecutar consultas complejas y ofrecer respuestas a preguntas empresariales críticas en diferentes sectores. Puede encontrar la especificación completa en documentación oficial. El punto de referencia consta de 22 consultas que simulan cargas de trabajo analíticas del mundo real, desde simples agregaciones hasta complejas uniones de varias tablas.
Ejecutamos cada consulta individualmente a través del SQL Lab de Superset para las tres bases data: MotherDuck, BigQuery y PostgreSQL. También probamos las consultas directamente en la interfaz gráfica de MotherDuck para eliminar la latencia cliente-servidor y porque, francamente, cualquier empresa que utilice MotherDuck probablemente tendría a sus analistas data trabajando en la interfaz inspirada en el bloc de notas de MotherDuck en lugar de en el SQL Lab de Superset. Además, la aplicación de MotherDuck puede aprovechar la arquitectura WebAssembly de la que hemos hablado antes, y teníamos curiosidad por ver cómo se comportaría esta ejecución basada en navegador en comparación con los modelos tradicionales servidor-cliente. Para garantizar unas pruebas justas, la caché de Superset se desactivó en todas las pruebas comparativas.
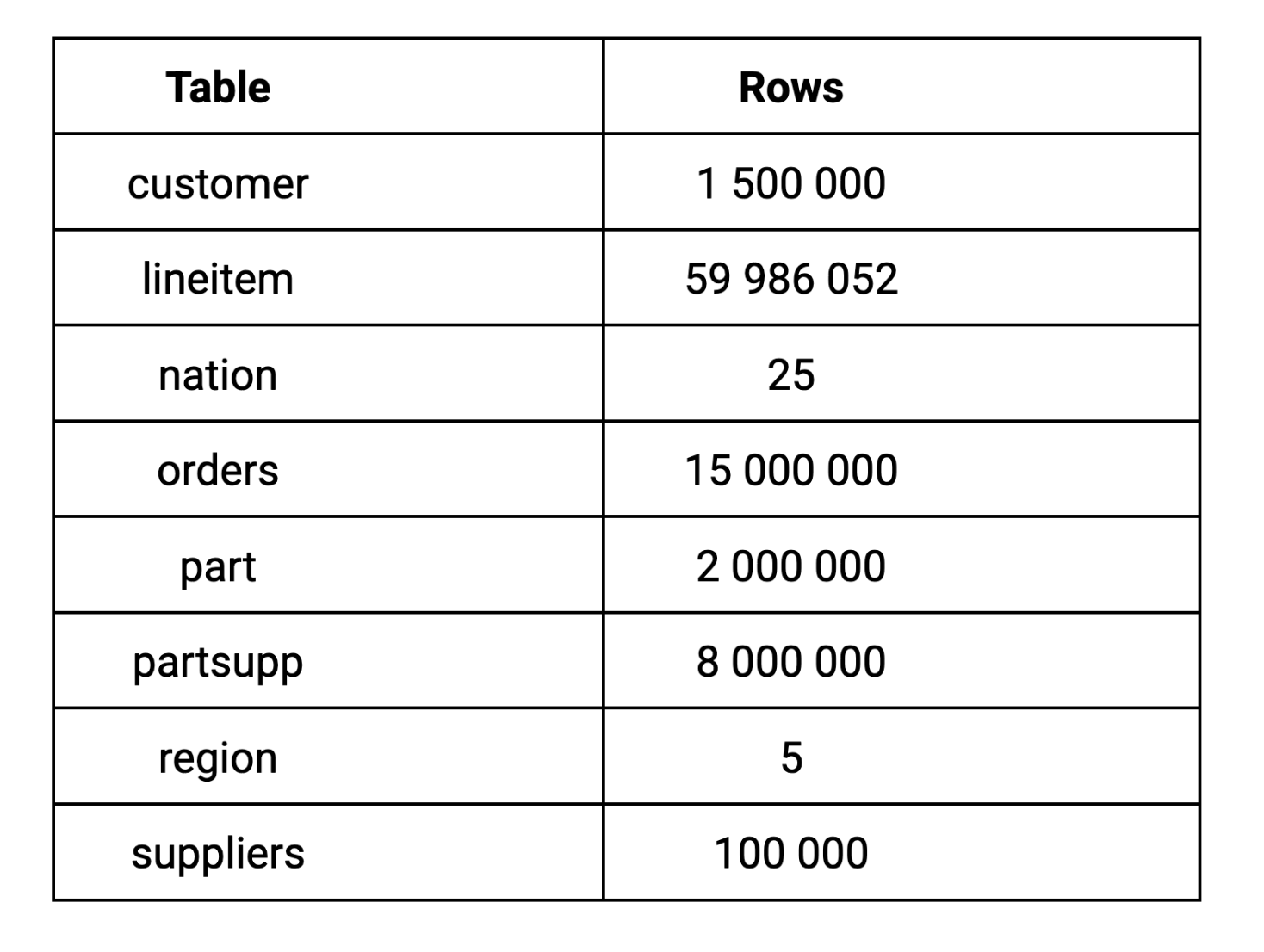
Para este punto de referencia, utilizamos el factor de escala 10 (SF-10) de TPC-H, que genera un dataset de 10 GB. Elegimos el factor de escala 10 porque 10GB representa un tamaño de dataset realista para las cargas de trabajo analíticas de la mayoría de las empresas, lo suficientemente grande como para revelar diferencias de rendimiento significativas sin requerir una infraestructura a escala empresarial. He aquí cómo se desglosa el data en las tablas clave:
Utilizamos la extensión DuckDB TPC-H para generar el data localmente y luego lo cargamos sin problemas en MotherDuck. El proceso duró sólo unos minutos gracias a la capacidad de carga de data de MotherDuck.
Aquí están los resultados de TPC-H SF-10 en segundos. La columna amarilla muestra los resultados de la interfaz de usuario nativa de la aplicación MotherDuck, mientras que las otras columnas representan el rendimiento a través del SQL Lab de Superset (SST):
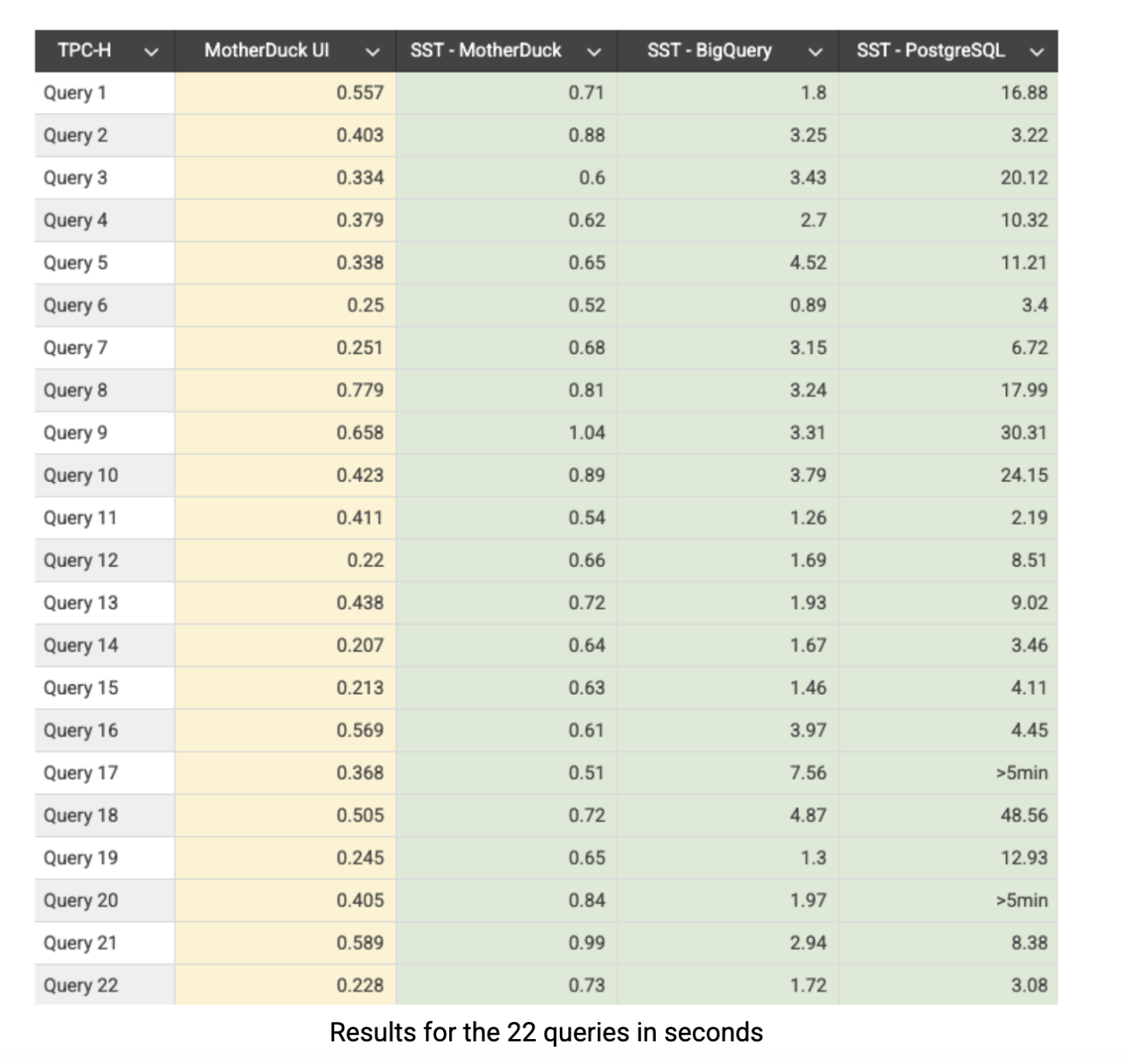
MotherDuck ofrece sistemáticamente un rendimiento por debajo del segundo en todos los ámbitos: 21 de 22 consultas a través de Superset terminan en menos de un segundo, con todas las consultas completándose por debajo del segundo cuando se ejecutan directamente a través de la aplicación de MotherDuck. BigQuery muestra un rendimiento respetable pero promedia aproximadamente 4 veces más lento que MotherDuck en todo el conjunto de pruebas comparativas. PostgreSQL cuenta una historia totalmente diferente, con un rendimiento significativamente más lento y claras dificultades en agregaciones y uniones complejas. Esto era previsible ya que PostgreSQL está diseñado fundamentalmente para cargas de trabajo OLTP más que para procesamiento analítico, pero lo incluimos en nuestra comparación porque sigue siendo ampliamente utilizado por las empresas para tareas analíticas. Cabe señalar que PostgreSQL podría conseguir un rendimiento mucho mejor con técnicas de optimización adecuadas como la indexación, el particionado o las vistas materializadas, pero incluso así, seguiría luchando contra su arquitectura basada en filas. La brecha de rendimiento pone de relieve exactamente por qué existen los sistemas OLAP construidos a propósito como MotherDuck: cuando se ejecutan consultas analíticas complejas en conjuntos data sustanciales, la arquitectura importa enormemente.
Mientras que TPC-H muestra el rendimiento bruto de las consultas, la verdadera prueba es cómo se traduce esto en la experiencia real del usuario en las herramientas de inteligencia empresarial.
Rendimiento del cuadro de mandos
Vimos que el rendimiento era excelente para los analistas data que trabajaban con SQL en su almacén data, pero queríamos comprobar si esta mejora se trasladaría a la creación de cuadros de mando, donde las partes interesadas del negocio interactúan realmente con el data. Después de todo, unas consultas SQL rapidísimas no importan mucho si sus cuadros de mando siguen tardando una eternidad en cargarse.
Para comprobarlo, utilizamos un conjunto realista de comercio electrónico data de Kaggle que contiene 67,5 millones de filas en 9 GB de data, el tipo de escala con el que trabajan muchas empresas para sus análisis mensuales de clientes. Utilizando esta única tabla, construimos un cuadro de mandos exhaustivo que pondría a prueba la capacidad de cada sistema para manejar cargas de trabajo de inteligencia empresarial del mundo real:
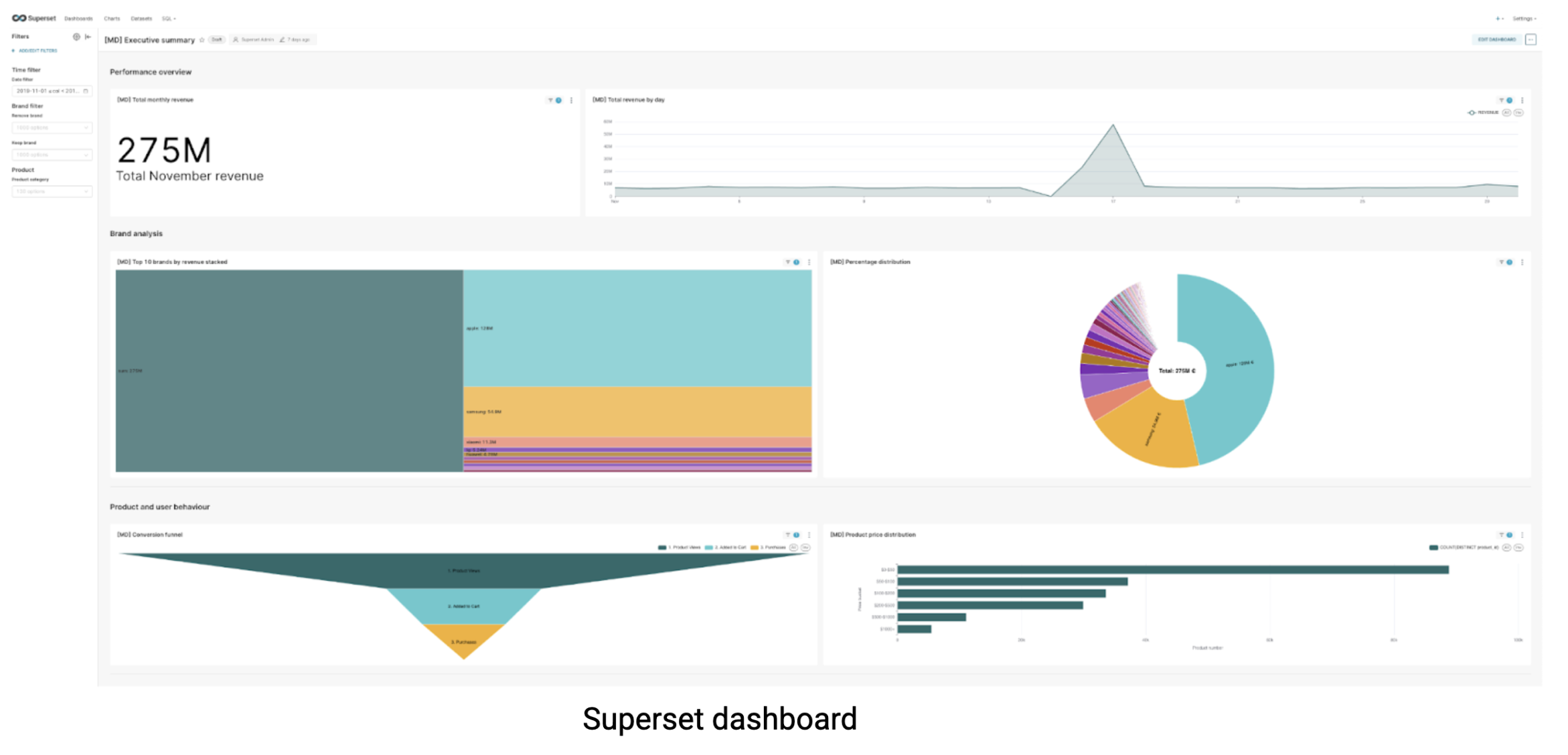
Probé el salpicadero exhaustivamente a través de múltiples ejecuciones, aplicando varios filtros, midiendo los tiempos de carga, desactivando la caché y monitorizando los tiempos de respuesta a través de las herramientas para desarrolladores de mi navegador. Después de múltiples ciclos de prueba para asegurar resultados consistentes, aquí están las métricas de rendimiento del salpicadero en segundos:
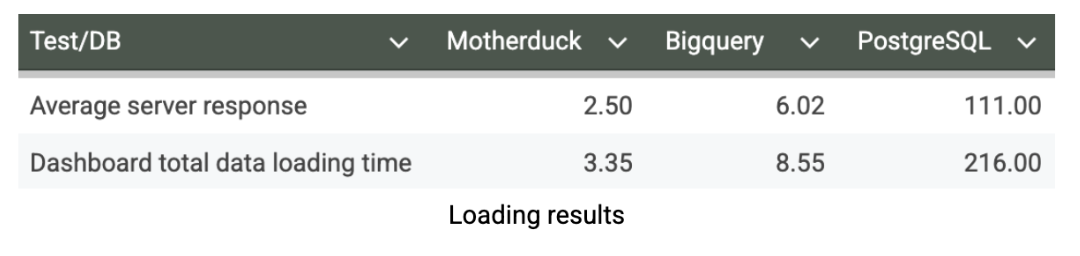
Nuestras pruebas de carga de cuadros de mando revelan las implicaciones prácticas del rendimiento de database en la experiencia del usuario. MotherDuck ofrece una capacidad de respuesta excepcional en los cuadros de mando, con un tiempo medio de carga de sólo 3,35 segundos, lo que permite una analítica realmente interactiva en la que los usuarios pueden explorar data con fluidez y sin fricciones. Por el contrario, BigQuery necesita 8,55 segundos para cargar el mismo cuadro de mandos. Sigue siendo aceptable para la elaboración de informes planificados, pero crea retrasos notables que pueden desalentar el análisis exploratorio. El tiempo de carga de 216 segundos de PostgreSQL (>3 minutos) lo hace completamente impracticable para el uso de cuadros de mando. Esta ventaja de rendimiento que representa MotherDuck puede transformar fundamentalmente la forma en que los usuarios empresariales interactúan con data. Cuando los cuadros de mando se cargan en segundos en lugar de minutos, la adopción por parte de los usuarios se dispara, los analistas pueden iterar rápidamente sobre las perspectivas y el análisis se convierte en una ventaja competitiva en lugar de un cuello de botella.
Comparación de precios
MotherDuck combina el almacenamiento con pago por uso computación, optimizado para el análisis interactivo. Como se escala en una sola máquina en lugar de distribuirse en un clúster, se evitan los gastos generales que los usuarios acaban pagando. Una sesión de docenas de consultas puede costar sólo $0,05-$0,10, mientras que un equipo que ejecute miles de consultas al mes puede gastar sólo $20-$40. En cambio, las bases data siempre activas pueden gastar $300-$500/mes sólo para mantenerse activas, y los almacenes cloud suelen cobrar $5-$10 por TB escaneado. Gracias a su diseño escalable, MotherDuck mantiene unos precios sencillos, predecibles y rentables.

MotherDuck puede parecer inicialmente más caro debido a su cuota de organización y a un modelo de precios de computación diferente. Sin embargo, ambos sistemas utilizan modelos de precios que favorecen diferentes patrones de uso: BigQuery destaca en el procesamiento de grandes lotes, mientras que MotherDuck está optimizado para el análisis interactivo. Para nuestra comparativa TPC-H, ejecutar 22 consultas en SF-10 costó $0,03 para MotherDuckversus $0,60-$1,00 para BigQuery. Cuando se tienen en cuenta los gastos generales de infraestructura, nuestra configuración PostgreSQL requirió 14 euros/día sólo para mantenerse en línea, el enfoque sin servidor de MotherDuck ofrece a menudo un coste total de propiedad superior para las cargas de trabajo analíticas interactivas.
A escala empresarial, la economía cambia en función de los patrones de uso. BigQuery resulta más rentable para el procesamiento por lotes de gran volumen, mientras que MotherDuck mantiene su ventaja para los análisis interactivos y los flujos de trabajo exploratorios. La idea clave: elija su modelo de precios basándose en cómo trabaja realmente su equipo con data, no sólo en los costes brutos por unidad.
Nota: Todos los ejemplos de precios se basan en la región europa-oeste4 y deben considerarse ilustrativos y no exactos, ya que los costes reales dependen en gran medida de los patrones de uso específicos y de las características del data.
Conclusión
MotherDuck representa un cambio fundamental en la forma de pensar sobre las bases analíticas data, que desafía la suposición de que se necesitan sistemas complejos y distribuidos para manejar cargas de trabajo data serias. Al tomar la filosofía integrada de DuckDB y extenderla al cloud, MotherDuck ofrece las capacidades de colaboración que requieren los equipos data modernos, manteniendo al mismo tiempo el rendimiento bruto que hace que DuckDB sea excepcional.
Nuestros resultados de las pruebas comparativas cuentan una historia convincente: MotherDuck superó sistemáticamente tanto a BigQuery como a PostgreSQL por márgenes significativos, ofreciendo un rendimiento de consulta de menos de un segundo en conjuntos de data de 10 GB y tiempos de carga de cuadros de mando que permiten una analítica verdaderamente interactiva. La ventaja de rendimiento sobre BigQuery y la gran ventaja sobre PostgreSQL en escenarios de cuadros de mando no se trata sólo de consultas más rápidas, sino de transformar la analítica en una experiencia más interactiva y exploratoria que fomente la toma de decisiones data-driven.
Y lo que es más importante, MotherDuck consigue este rendimiento al tiempo que reduce drásticamente la complejidad y los costes de la infraestructura. Donde las configuraciones tradicionales de cloud requieren una infraestructura siempre activa que cuesta cientos de dólares al mes, el modelo sin servidor de MotherDuck cobra sólo por el uso real, lo que a menudo reduce los costes. El precio de pago por ordenador se alinea perfectamente con la forma en que trabajan realmente los analistas: ejecutando múltiples consultas en sesiones de exploración en lugar de peticiones aisladas y poco frecuentes.
Las implicaciones van más allá del rendimiento y el coste. El modelo de ejecución dual de MotherDuck y las capacidades analíticas basadas en el navegador sugieren un futuro en el que la frontera entre la informática local y la cloud será cada vez más fluida. En lugar de obligar a los equipos a elegir entre la simplicidad local y la escalabilidad cloud, MotherDuck ofrece ambas, dirigiendo de forma inteligente la computación hacia donde tenga más sentido.
Lo que realmente me impresionó durante las pruebas fue la sencillez de uso y configuración de MotherDuck. El modelo de ejecución dual me permitió consultar el data tanto localmente como en el cloud de forma simultánea, mientras que la configuración de la conexión entre Superset y MotherDuck fue notablemente sencilla.
Para las organizaciones que buscan modernizar sus capacidades analíticas empezando por la capa gold, MotherDuck ofrece una propuesta muy atractiva: rendimiento de nivel empresarial, flujos de trabajo colaborativos y rentabilidad, todo ello sin la sobrecarga operativa de la infraestructura de almacén data tradicional. En un mundo en el que las decisiones data-driven determinan cada vez más la ventaja competitiva, la capacidad de explorar data de forma interactiva a velocidades inferiores al segundo no es sólo un "nice-to-have"; se está convirtiendo en algo esencial.
¿Listo para experimentar por sí mismo la actuación de MotherDuck? Puede empezar con un 21 días de prueba gratuita o con su plan gratuito de 10 GB para probarlo con sus propios conjuntos data y cargas de trabajo. Si busca orientación sobre si MotherDuck se adapta a su pila data específica o necesita ayuda con la implementación, póngase en contacto con nuestro equipo en Artefact, estaremos encantados de evaluar sus necesidades analíticas y ayudarle a navegar por la transición hacia una infraestructura analítica más eficiente y rentable.
