


Samenvatting
MotherDuck breidt de analytische prestaties van DuckDB uit naar de cloud met samenwerkingsfuncties, levert 4x snellere prestaties dan BigQuery en kostenbesparingen ten opzichte van traditionele data magazijnen via serverloze, pay-per-use prijzen. Na de aankondiging van de nieuwe Europese cloud regio van MotherDuck waren we onder de indruk van de prestaties en de aantrekkelijke prijsstelling. MotherDuck kan al in uw gouden lagen worden geïntegreerd om het serveren van data use cases te versnellen en tegelijkertijd kosten te besparen. Bekijk de prestatiebenchmark.
Inleiding
In het snel evoluerende landschap van data analytics is er een nieuwe speler die de gevestigde orde van cloud data magazijnen uitdaagt. MotherDuck, gebouwd op het fundament van DuckDB‘de bliksemsnelle analytische engine, belooft prestaties op bedrijfsniveau te leveren met de eenvoud en kosteneffectiviteit waar moderne data teams naar hunkeren. Maar kan deze eend echt concurreren met de gevestigde giganten?
We hebben MotherDuck streng getest ten opzichte van gevestigde concurrenten om te zien of het de hype waarmaakt. Wat we ontdekten daagt de huidige status quo van analytische databases uit en suggereert een fundamentele verschuiving in de manier waarop we cloud-gebaseerde data-verwerking benaderen. Dit is het verhaal van hoe een embedded database leerde vliegen, en waarom het uw data stack zou kunnen revolutioneren.
Om deze veranderende klant te vangen, moeten retailers zich snel aanpassen.
Een broedende eend
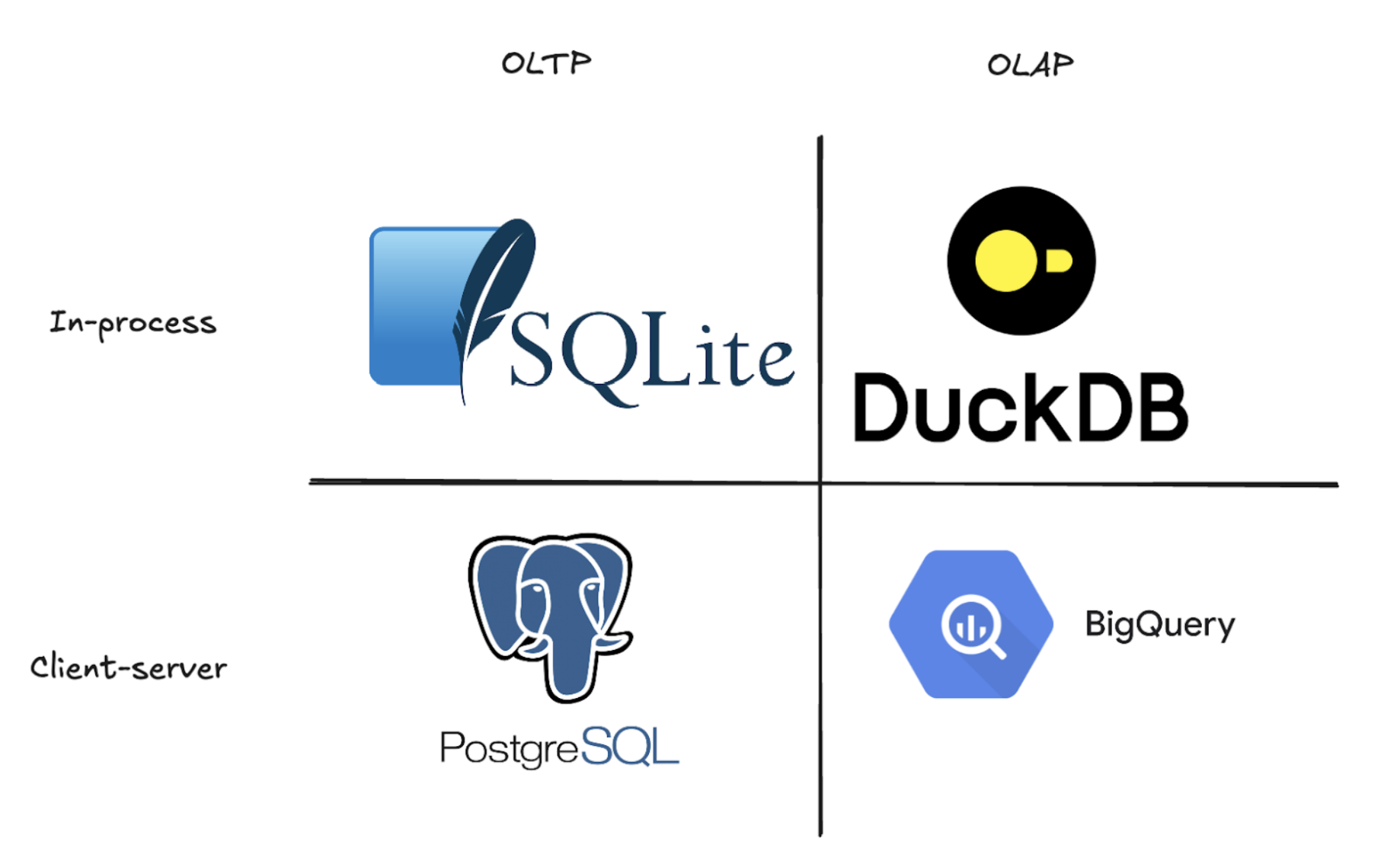
MotherDuck beschrijft zichzelf als een “DuckDB cloud data magazijn dat schaalt tot terabytes voor klantgerichte analyses en BI.” Om te begrijpen wat dit cloud data pakhuis speciaal maakt, moeten we eerst kijken naar DuckDB, DuckDB, het open-source database systeem dat de afgelopen jaren een stille revolutie teweeg heeft gebracht in de data stack. Eenvoudig gezegd is DuckDB een in-memory OLAP SQL database systeem. Voor diegenen die het database jargon niet kennen, laten we eens uitpakken wat dat eigenlijk betekent:
OLAP staat voor Online Analytical Processing. Zie het als een database die ontworpen is om door enorme hoeveelheden data te crunchen en snel antwoord te geven op complexe bedrijfsvragen. In tegenstelling tot traditionele databases die uitblinken in het vinden van individuele records (zoals het opzoeken van een bestelling van een klant), zijn OLAP databases gebouwd om miljoenen rijen te scannen en zware berekeningen in seconden uit te voeren. Ze bereiken deze snelheid door data op te slaan in kolommen in plaats van rijen, waardoor het bliksemsnel is om trends te analyseren, gemiddelden te berekenen of verkopen over hele datasets bij elkaar op te tellen. Dit is dezelfde aanpak die gebruikt wordt door moderne data warehouses zoals BigQuery of Snowflake. Aan de andere kant zijn er OLTP (Online Transaction Processing) databases zoals PostgreSQL, SQLite of MySQL. Dit zijn de werkpaarden die uw toepassingen aandrijven, die duizenden individuele lees- en schrijfbewerkingen per seconde uitvoeren om uw toepassingen soepel te laten draaien. Meer informatie over OLAP vs OLTP.
Om te begrijpen hoe revolutionair de aanpak van DuckDB werkelijk is, moeten we een stapje terug doen en kijken hoe we hier gekomen zijn. In het midden van de jaren negentig, toen webgiganten als Yahoo en Amazon hun intrede deden, liepen ze tegen een muur op die het hele data landschap zou veranderen. Deze bedrijven verdronken in data, wat we later “grote data” zouden noemen, en hun bestaande systemen konden het gewoon niet bijhouden. De oplossing? Dure, monolithische infrastructuren die de schaal aankonden. Maar toen de hardwarekosten in de jaren 2000 daalden, ontstond er een nieuwe filosofie: in plaats van grotere machines te kopen, waarom zouden we niet veel kleinere, goedkopere machines gebruiken? Uit deze denkwijze ontstonden gedistribueerde systemen zoals MapReduce en Apache Hadoop, technologieën die ontworpen zijn om werklasten te verspreiden over clusters van standaard hardware. Amazon kapitaliseerde op deze trend, verpakte deze gedistribueerde technologieën als diensten en lanceerde Amazon Web Services, het eerste grote cloud platform. Jarenlang werd dit het standaard draaiboek: als u een data probleem tegenkwam, verdeelde u het over meer machines (Fundamentals of Data Engineering, Joe Reis & Matt Housley).
Maar dit is fascinerend: terwijl iedereen druk bezig was met het bouwen van gedistribueerde systemen, gebeurde er stilletjes op de achtergrond iets anders. Dezelfde krachten die gedistribueerd computergebruik economisch maakten, maakten ook individuele machines ongelooflijk krachtig. Uw laptop van vandaag is ongelooflijk krachtig geworden met meer RAM, snellere processoren en betere opslag. De ontwikkelaars achter DuckDB zagen deze over het hoofd geziene kans: wat als we, in plaats van altijd maar uit te schalen, intelligenter konden opschalen? Wat als we veel data problemen konden oplossen zonder de complexiteit van gedistribueerde systemen?
Een van de meest ingezette database motoren ter wereld, SQLite heeft een radicaal andere aanpak dan traditionele data-bases. Terwijl PostgreSQL en MySQL draaien als aparte servers waarmee applicaties verbinding maken via een netwerk, wordt SQLite direct in uw applicatie geïntegreerd als een lichtgewicht bibliotheek. Er is geen server die geconfigureerd moet worden, geen netwerkoverhead en geen complexe setup, alleen pure, lokale database functionaliteit die binnen het proces van uw applicatie draait. Deze eenvoud, gecombineerd met een opmerkelijke betrouwbaarheid en snelheid, heeft SQLite alomtegenwoordig gemaakt in alles van mobiele apps tot webbrowsers.
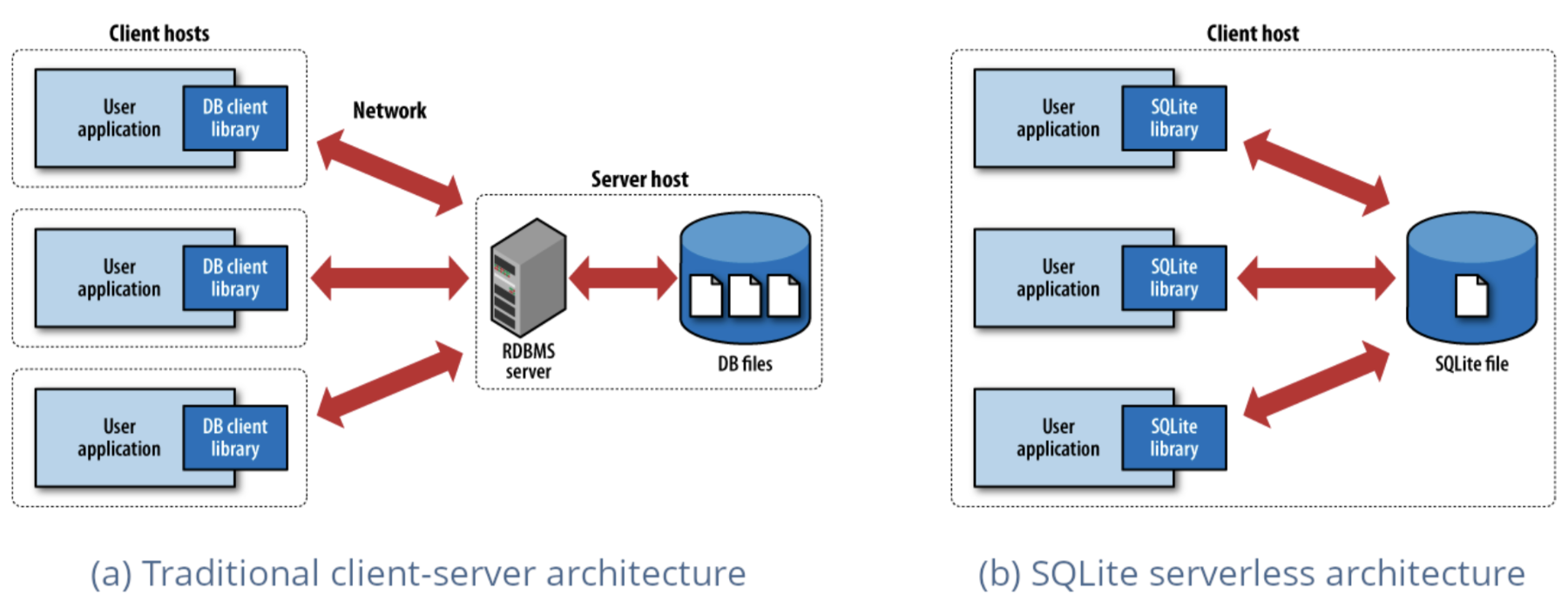
DuckDB past dezelfde embedded filosofie toe op analytische werklasten, en bewijst dat u niet altijd een gedistribueerd systeem nodig hebt om grote datasets te doorzoeken. Net zoals SQLite een revolutie betekende voor lokale data opslag, maakt DuckDB gebruik van de ruwe kracht van uw lokale machine om analyse weer eenvoudig te maken. De installatie duurt slechts enkele seconden, er zijn geen externe afhankelijkheden om mee te worstelen, en plots kunt u complexe analytische queries uitvoeren op gigabytes van data zonder ook maar één cloud instantie op te starten.
Wat DuckDB bijzonder aantrekkelijk maakt, is hoe het ontwikkelaars tegemoet komt waar ze zijn. Moet u een Python DataFrame analyseren? DuckDB kan het rechtstreeks opvragen. Wilt u een CSV bestand doorzoeken? Geen probleem. Deze naadloze integratie, in combinatie met zijn razendsnelle columnar engine, heeft van DuckDB één van de snelst groeiende database systemen in de analyseruimte gemaakt. De prestatiewinst is vaak zo dramatisch dat u zich afvraagt waarom u eigenlijk gedistribueerde systemen gebruikt. Als u dieper wilt ingaan op de technische filosofie achter deze aanpak, raden wij u ten zeerste aan om het volgende te lezen “In-proces analytisch Data beheer met DuckDB”.” door de medebedenker van DuckDB, Hannes Mühleisen.
Nu u begrijpt wat DuckDB is, laten we het hebben over de beperkingen ervan. Elke technologie heeft nadelen. DuckDB kan slechts op één machine werken en accepteert slechts één verbinding per keer. In een wereld waar data teams cloud-native oplossingen bouwen die hele organisaties bedienen, is dit een behoorlijke beperking. Je kunt niet meerdere analisten tegelijkertijd dezelfde DuckDB-instantie laten bevragen, en je kunt zeker geen datasets delen tussen teams zoals je zou doen met een traditioneel data magazijn. Ondanks al zijn snelheid en eenvoud, sluit DuckDB uw data in wezen op op één machine, toegankelijk voor één persoon per keer. Dus hoe neem je deze ongelooflijk snelle maar inherent single-user database en maak je er een cloud data pakhuis van dat een hele organisatie kan bedienen?
De eend die leerde vliegen
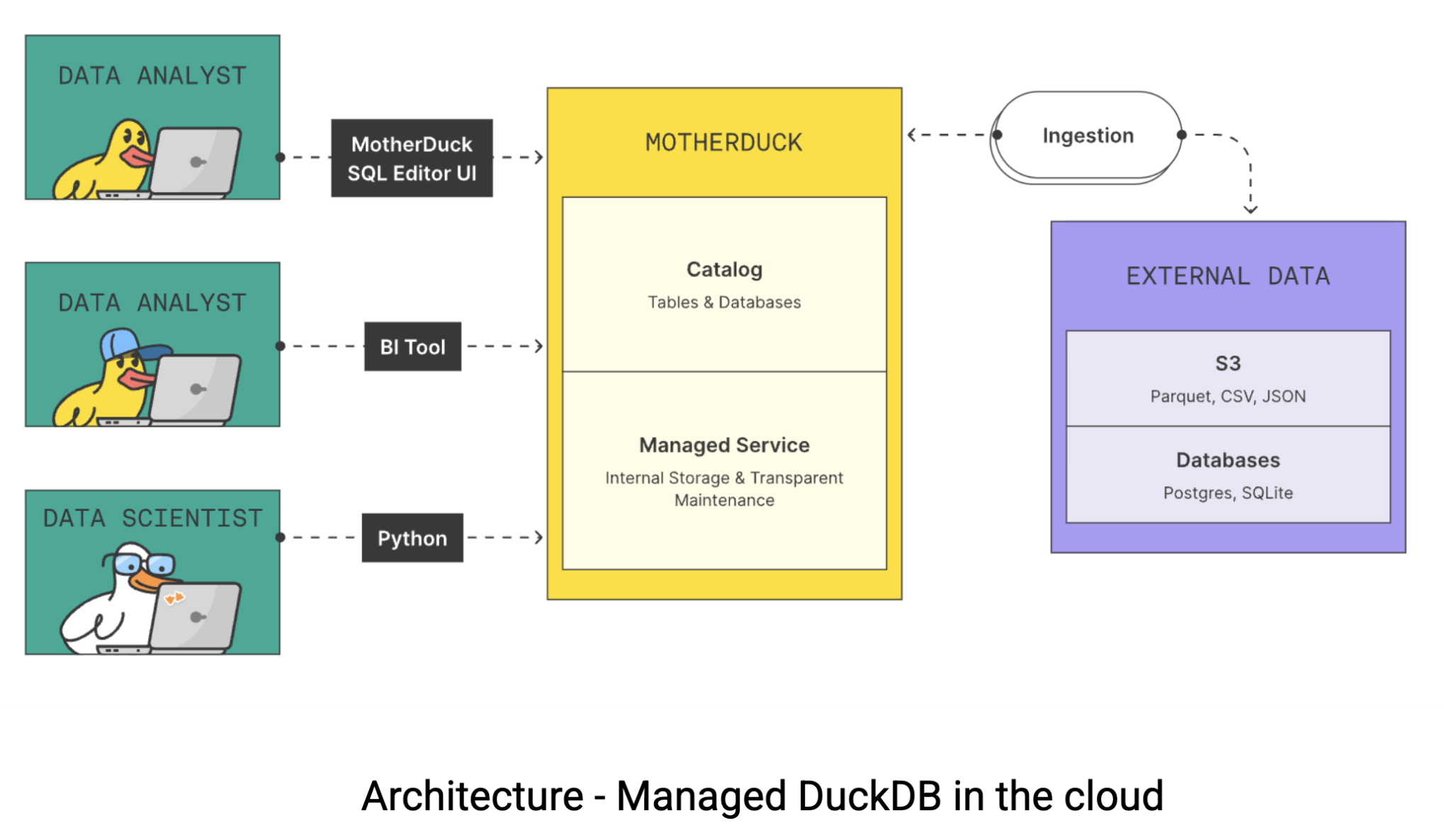
Hier komt MotherDuck in beeld. MotherDuck is een serverloos data pakhuis dat de kloof overbrugt tussen de ruwe prestaties van DuckDB en de samenwerkingsbehoeften van moderne data teams. MotherDuck creëert wat zij noemen een “geïndividualiseerd analytisch data pakhuis” dat elke gebruiker zijn eigen hoogperformante DuckDB instance geeft, terwijl het toch mogelijk blijft om data te delen binnen de organisatie. Dit is hoe de architectuur werkt:
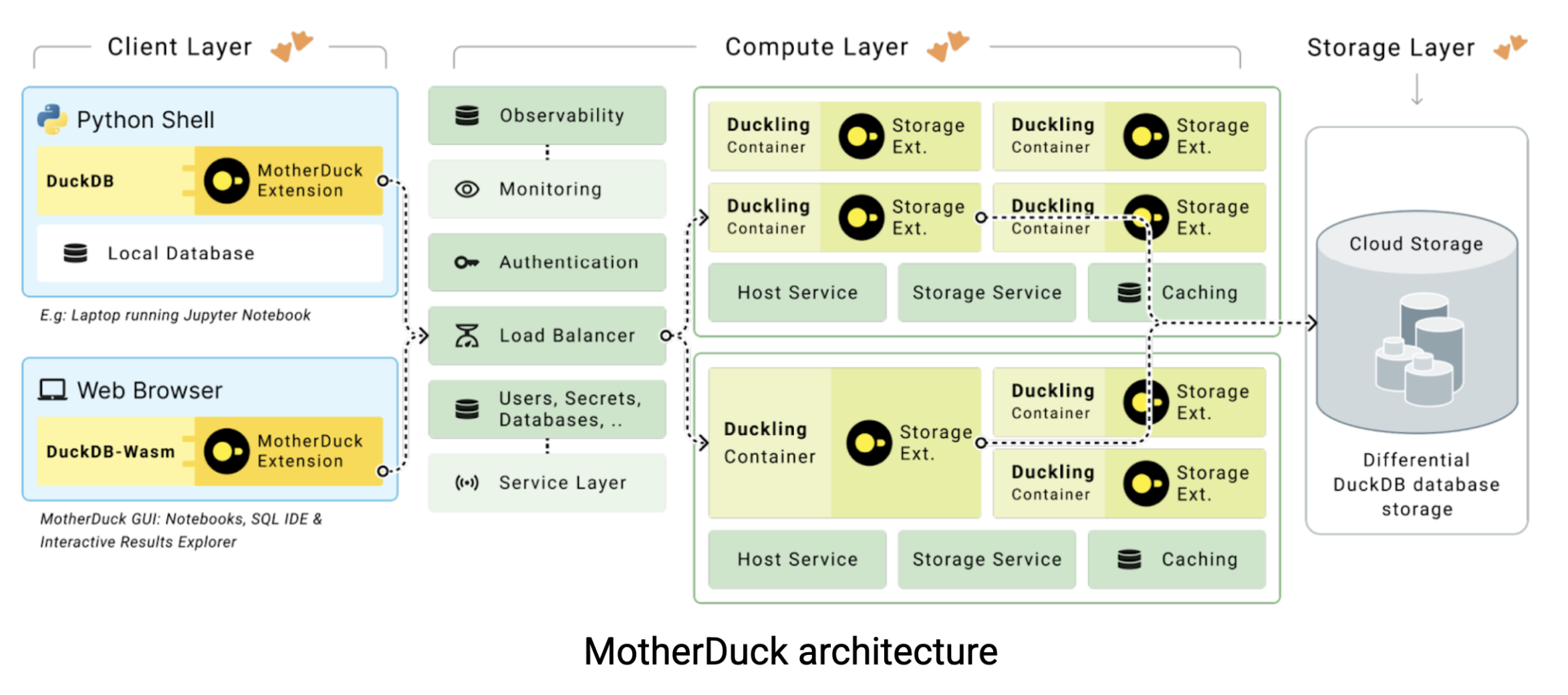
In traditionele cloud data magazijnen is uw laptop slechts een domme terminal. Al het zware werk gebeurt op externe servers waarvoor u per uur betaalt. Maar het zit zo: uw MacBook is waarschijnlijk sneller dan een $20-60 per uur data magazijninstantie. MotherDuck probeert deze rekenkracht te benutten met twee innovatieve benaderingen:
- Browser-gebaseerde analyses die berekeningen direct naar de gebruiker brengen.
- Dubbele uitvoering die op intelligente wijze de verwerkingskracht van uw lokale machine combineert met cloud bronnen om sneller resultaten te leveren dan beide benaderingen alleen zouden kunnen bereiken.
Voordat ik in deze beide methoden duik, wil ik graag zeggen dat de rekenkracht van MotherDuck echt uitblinkt wanneer deze wordt toegepast op uw goudlaag. Voor degenen die de term niet kennen: de gouden laag is de uiteindelijke, bedrijfsklare data die is opgeschoond, samengevoegd en verrijkt. In wezen zijn dit de opgepoetste datasets die uw analyses, rapportages en machine learning aansturen. Dit is de data die uw meest kritieke bedrijfsbeslissingen aanstuurt, waardoor prestaties hier absoluut cruciaal zijn. Elke stakeholder heeft wel eens geleden onder pijnlijk trage dashboards, en elk data teamlid heeft wel eens naar het draaiende rad des doods gestaard terwijl hij wachtte tot complexe query's klaar waren. MotherDuck pakt deze frustratie frontaal aan.
In-browser analyses
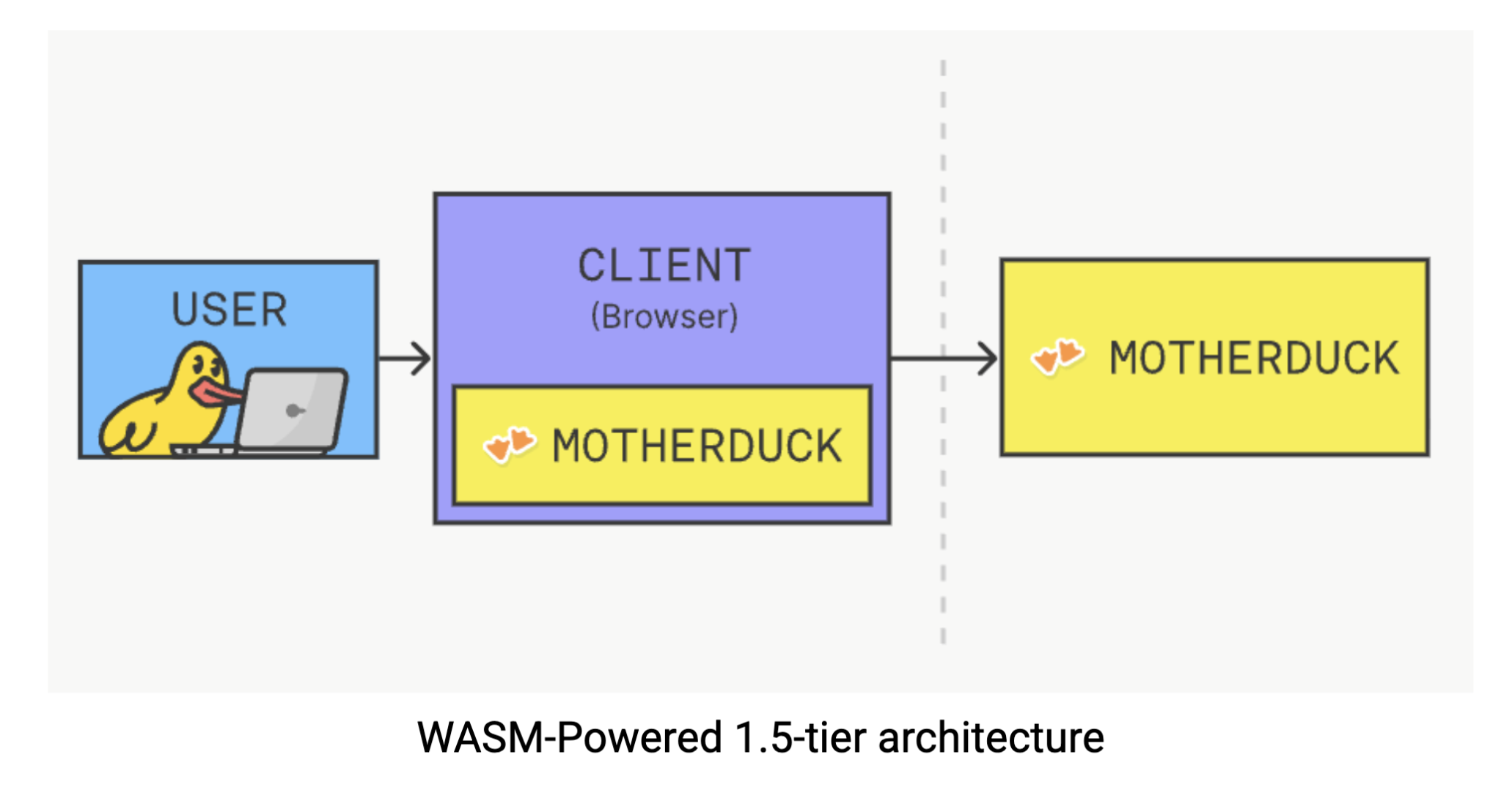
Deze oplossing maakt gebruik van het lichtgewicht en draagbare ontwerp van DuckDB, waardoor het direct in uw browser kan draaien via WebAssembly (Wasm). Zie Wasm als een technologie die complexe software direct in uw browser laat draaien: geen plugins, geen downloads, alleen rekenkracht waar u die het meest nodig hebt. Met DuckDB die client-side draait, kunt u complexe analytische queries uitvoeren zonder de gebruikelijke dans van het verzenden van verzoeken naar een server en het wachten op antwoorden. De data verwerking gebeurt direct in uw browser, waardoor de netwerklatentie wegvalt en de afhankelijkheid van de infrastructuur volledig wordt verminderd. U kunt deze magie zelf ervaren door DuckDB in uw browser.
Hoewel we hier niet diep zullen ingaan op de technische implementatie, is het de moeite waard om op te merken dat DuckDB-Wasm uitblinkt. Onderzoek gedetailleerd in dit document laat zien dat het aanzienlijk beter presteert dan bestaande browsergebaseerde oplossingen zoals de Wasm-versie van SQLite of Lovefield, een JavaScript-gebaseerde database. Deze slimme technische demo geeft een fundamentele verschuiving aan in hoe we denken over de locatie van analytische berekeningen.
MotherDuck biedt deze door Wasm aangedreven architectuur zoals uitgelegd door Mehdi Ouazza in dit artikel. Deze aanpak is bijzonder krachtig voor analytics in de gouden laag. Uw data team gaat aan de slag met schone, bedrijfsklare data zonder zich zorgen te hoeven maken over de backend infrastructuur, de verwerking gebeurt lokaal voor maximale snelheid, en u bereikt enkele van de snelst mogelijke responstijden door netwerklatentie volledig te elimineren. Bovendien vermijdt u de forse rekenkosten die traditionele cloud data warehouses u graag in rekening brengen voor elke query. Het is een aantrekkelijk voorstel: snellere analyses, lagere kosten en een eenvoudigere architectuur in één.
Dubbele uitvoering
Een andere manier om gebruik te maken van MotherDuck in uw gold layer is door middel van haar dual execution mogelijkheid, die op intelligente wijze lokale rekenkracht combineert met cloud schaal. In plaats van uw hele data team te dwingen om dezelfde rekenkracht te delen, geeft MotherDuck elke gebruiker zijn eigen “eendje”: een individuele, serverloze rekeninstantie die schaalt met hun behoeften.
De echte kracht van dubbele uitvoering komt naar voren wanneer u werkt met data die verspreid is over verschillende bronnen. Stel u voor dat u queries moet uitvoeren op data die opgeslagen is in MotherDuck, deze moet combineren met bestanden in S3 en deze moet combineren met een dataset die lokaal op uw laptop staat. Traditionele cloud systemen zouden u dwingen om alles naar één plaats te uploaden voordat u cross-source queries zou kunnen uitvoeren. MotherDuck's hybride uitvoering is slimmer. Het analyseert uw query, bewaart alleen de benodigde data van elke bron en voert intelligente verbindingen uit tussen locaties, waardoor u tijd en data overdrachtskosten bespaart.
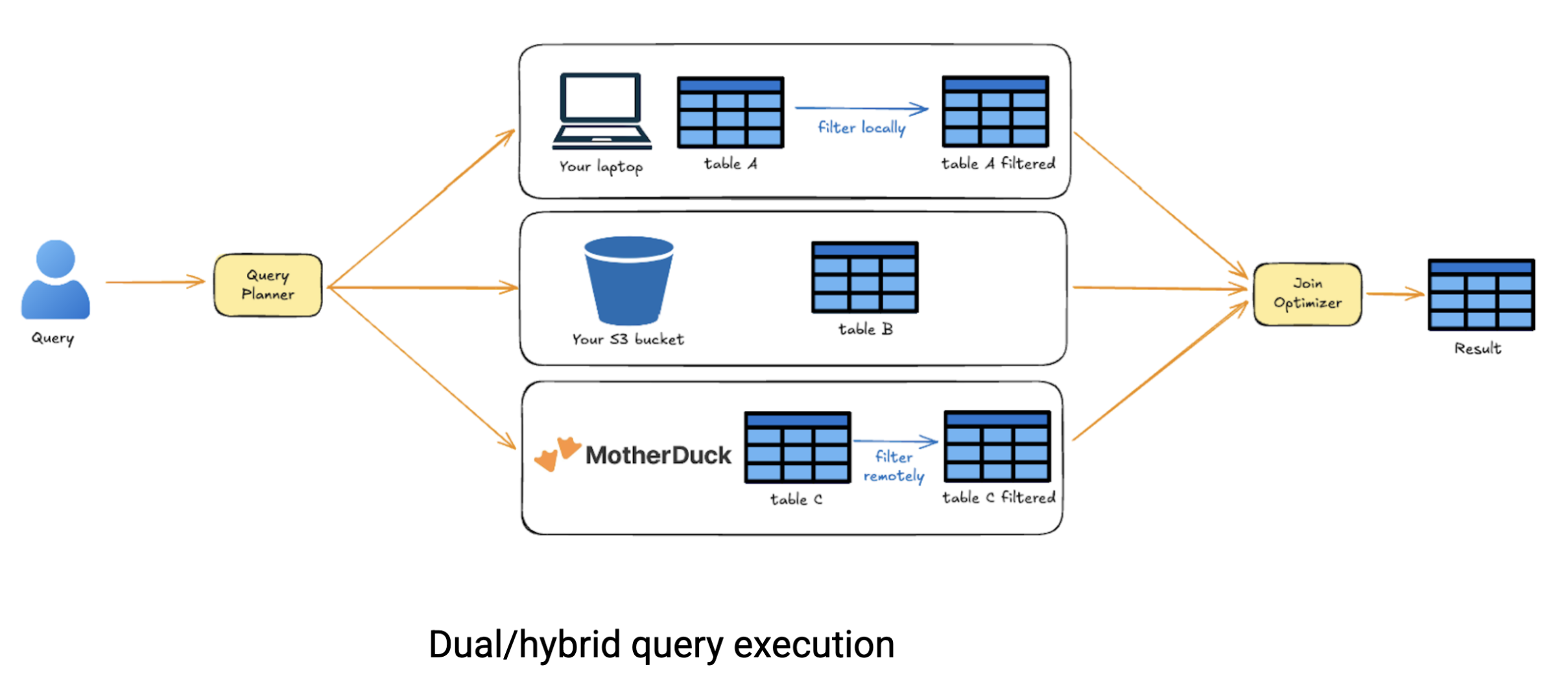
Onder de motorkap splitst de optimalisator van MotherDuck uw query op in een DAG (directed acyclic graph) van bewerkingen, schat de kosten in van het lokaal uitvoeren van elk knooppunt versus het op afstand uitvoeren en verwerkt automatisch data-bewegingen. U schrijft gewoon SQL; MotherDuck zoekt de optimale uitvoeringsstrategie uit. Deze aanpak herdefinieert cloud analytics fundamenteel. We zitten niet langer vast aan de keuze tussen lokale eenvoud en cloud schaalbaarheid, elk met hun eigen complexiteit rond data delen en workflow orkestratie. Met MotherDuck krijgt u het beste van twee werelden: draai lokaal wanneer uw machine het aankan, schaal naar de cloud wanneer dat nodig is en deel moeiteloos overal. Het is een serverloze oplossing die de cloud berekeningskosten verlaagt omdat u alleen betaalt voor wat u daadwerkelijk berekent.
Maar hier wordt het interessant: het delen van data wordt een fluitje van een cent. Weet u nog hoe het feit dat DuckDB een single-user systeem was, samenwerking pijnlijk maakte? Als een data analist een verbazingwekkende analyse maakte, moest hij alles exporteren en uploaden naar een gedeeld opslagsysteem om teamgenoten er toegang toe te geven. Met MotherDuck is delen net zo eenvoudig als klikken op een knop of het uitvoeren van een enkele regel code om een snapshot zonder kopieën te maken met de juiste toegangscontrole. Geen data verplaatsing, geen duplicatie van opslag, gewoon directe samenwerking.
Lees meer over Dual/Hybrid Query Execution in MotherDuck's paper van de Conferentie over Innovatief Data Systeemonderzoek (CIDR). U kunt dit ook bekijken dbt Samenvoegen praten door Jordan Tigani, medeoprichter en CEO van MotherDuck.
Eenden in het wild
We hebben gezien hoe MotherDuck aanzienlijke overhead van data teams wegneemt en tegelijkertijd krachtige analysemogelijkheden voor uw gouden laag levert. Maar theorie gaat maar zo ver. We wilden MotherDuck op de proef stellen tegen gevestigde spelers in de cloud data magazijnruimte. Kijken naar de Data Stapelverslag van 2025 gepubliceerd door Metabase, vonden we iets verrassends: PostgreSQL blijft de populairste database keuze, zelfs voor analytische workloads, gevolgd door Snowflake en BigQuery onder de ondervraagde bedrijven. Dit gaf ons onze vergelijkingsdoelen.
We besloten om MotherDuck te vergelijken met gehoste PostgreSQL op Google Cloud en BigQuery, met behulp van Apache Superset als onze BI-tool van keuze. Superset was om verschillende redenen zinvol: het is open source, wordt op grote schaal gebruikt en is compatibel met MotherDuck, samen met de meeste andere grote data-bases. Onze testomgeving bestond uit Apache Superset ingezet op Google Cloud Kubernetes Engine, verbonden met drie verschillende backends: BigQuery, PostgreSQL op Cloud SQL en MotherDuck.
We hebben onze tests in twee fasen ingedeeld. Eerst voerden we de TPC-H benchmark uit: een gestandaardiseerde beslissingsondersteunende benchmark die ons zou laten zien hoe MotherDuck presteert in een gecontroleerde, theoretische omgeving. Daarna gingen we dichter bij de werkelijkheid staan en testten we hoe de relatie tussen Superset en MotherDuck zich verhield tot traditionele data magazijnen in echte dashboarding scenario's.
TPC-H benchmarking
TPC-H is de standaard voor het testen van analytische database prestaties. Het is een beslissingsondersteunende benchmark die ontworpen is om grote volumes data te onderzoeken, complexe queries uit te voeren en antwoorden te geven op kritieke bedrijfsvragen in verschillende industrieën. U kunt de volledige specificatie vinden in de officiële documentatie. De benchmark bestaat uit 22 query's die analytische workloads uit de echte wereld simuleren, van eenvoudige aggregaties tot complexe joins in meerdere tabellen.
We hebben elke query afzonderlijk uitgevoerd in Superset's SQL Lab voor alle drie de data-bases: MotherDuck, BigQuery en PostgreSQL. We hebben de query's ook direct in de GUI van MotherDuck getest om client-server latentie te elimineren en omdat eerlijk gezegd elk bedrijf dat MotherDuck gebruikt, hun data analisten waarschijnlijk in de op MotherDuck's notebook geïnspireerde interface zou laten werken in plaats van in het SQL Lab van Superset. Bovendien kan MotherDuck's app gebruik maken van de WebAssembly architectuur die we eerder bespraken, en we waren benieuwd hoe deze browser-gebaseerde uitvoering zou presteren in vergelijking met traditionele server-client modellen. Om eerlijk te kunnen testen, was de cache van Superset uitgeschakeld in alle benchmarks.
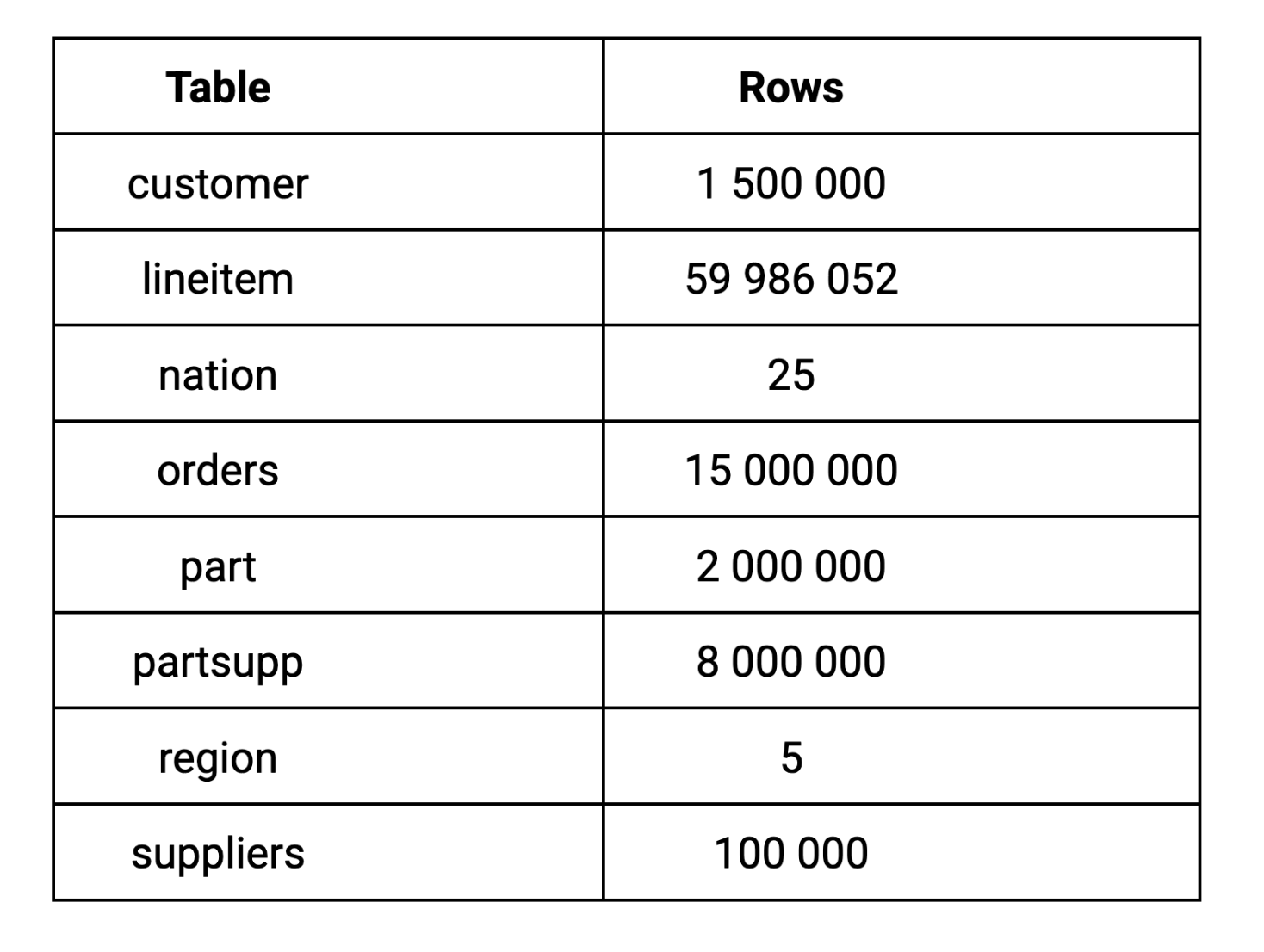
Voor deze benchmark hebben we TPC-H schaalfactor 10 (SF-10) gebruikt, die een dataset van 10GB genereert. We hebben schaalfactor 10 gekozen omdat 10GB een realistische grootte van de dataset is voor de analytische workloads van de meeste bedrijven, groot genoeg om zinvolle prestatieverschillen aan het licht te brengen zonder een infrastructuur op bedrijfsschaal te vereisen. Hier ziet u hoe de data zich over de sleuteltabellen verdeelt:
We gebruikten de DuckDB TPC-H extensie om de data lokaal te genereren en vervolgens naadloos te uploaden naar MotherDuck. Het proces nam slechts enkele minuten in beslag dankzij de data laadmogelijkheden van MotherDuck.
Hier zijn de TPC-H SF-10 resultaten in seconden. De gele kolom toont resultaten van de native UI van de MotherDuck app, terwijl de andere kolommen de prestaties via het SQL Lab van Superset (SST) weergeven:
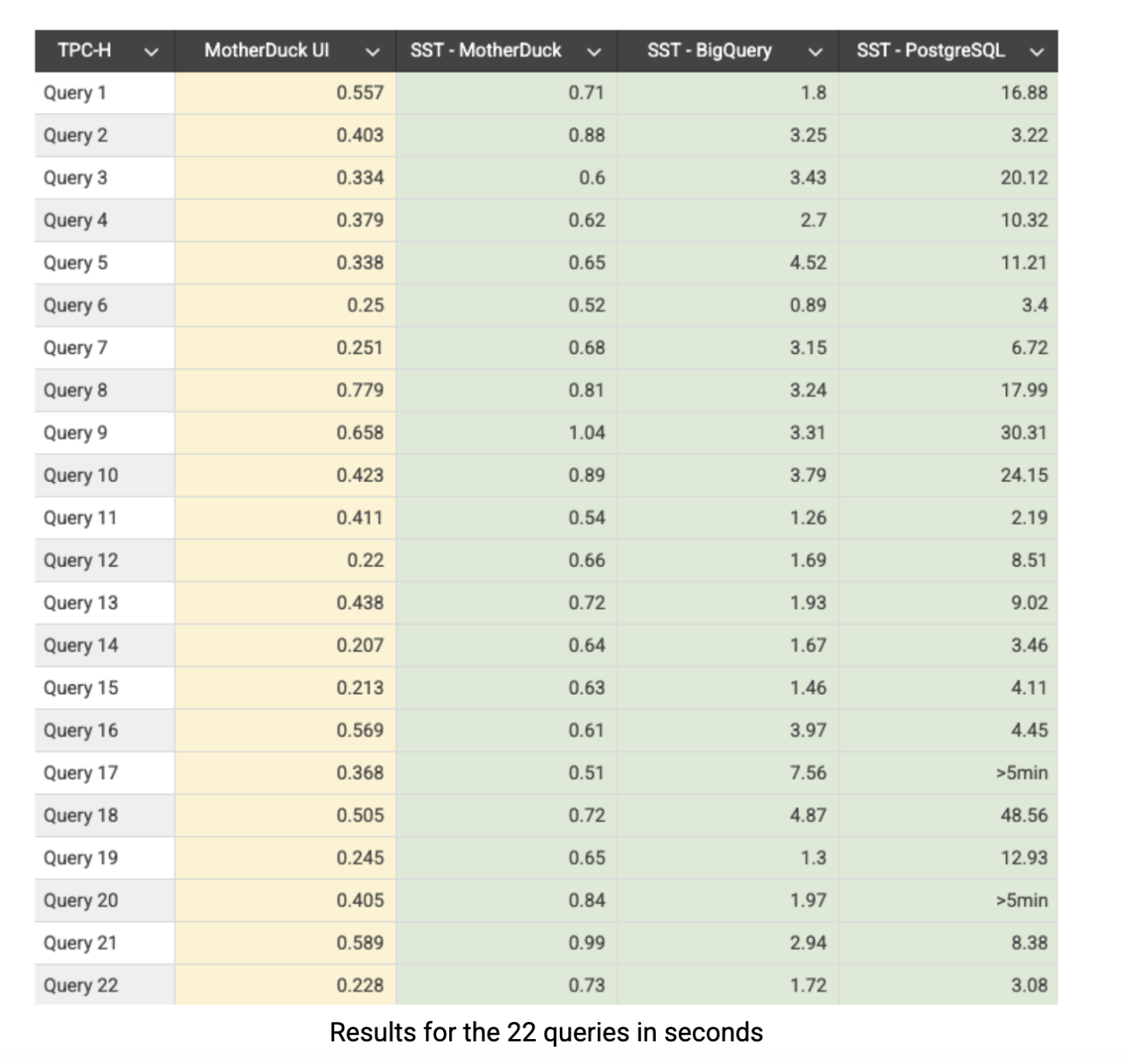
MotherDuck levert over de hele linie consistent prestaties onder de seconde: 21 van de 22 zoekopdrachten door Superset eindigen in minder dan een seconde, Alle query's voltooien binnen een seconde wanneer ze rechtstreeks via de app van MotherDuck worden uitgevoerd. BigQuery laat respectabele prestaties zien, maar gemiddeld ruwweg 4x langzamer dan MotherDuck in de hele benchmarksuite. PostgreSQL vertelt een heel ander verhaal, met aanzienlijk tragere prestaties en duidelijke problemen met complexe aggregaties en joins. Dit was voorspelbaar omdat PostgreSQL fundamenteel ontworpen is voor OLTP workloads in plaats van analytische verwerking, maar we hebben het in onze vergelijking opgenomen omdat het nog steeds veel gebruikt wordt door bedrijven voor analytische taken. Het is de moeite waard om op te merken dat PostgreSQL veel betere prestaties zou kunnen behalen met de juiste optimalisatietechnieken, zoals indexering, partitionering of gematerialiseerde weergaven, maar zelfs dan zou het nog steeds vechten tegen zijn rij-gebaseerde architectuur. De prestatiekloof laat precies zien waarom er speciaal gebouwde OLAP-systemen zoals MotherDuck bestaan: wanneer u complexe analytische queries uitvoert op substantiële datasets, is de architectuur enorm belangrijk.
Hoewel TPC-H de ruwe queryprestaties laat zien, is de echte test hoe dit zich vertaalt naar de daadwerkelijke gebruikerservaring in business intelligence tools.
Prestaties dashboard
We zagen dat de prestaties uitstekend waren voor data analisten die met SQL werkten op hun data magazijn, maar we wilden testen of deze verbetering zich ook zou vertalen naar dashboarding, waar zakelijke belanghebbenden daadwerkelijk interactie hebben met de data. Razendsnelle SQL-query's maken immers niet veel uit als het laden van uw dashboards een eeuwigheid duurt.
Om dit te testen, gebruikten we een realistische e-commerce dataset van Kaggle met 67,5 miljoen rijen op 9 GB data, het soort schaal waar veel bedrijven mee werken voor hun maandelijkse klantanalyses. Met behulp van deze enkele tabel bouwden we een uitgebreid dashboard dat het vermogen van elk systeem om echte business intelligence workloads aan te kunnen, aan een stresstest zou onderwerpen:
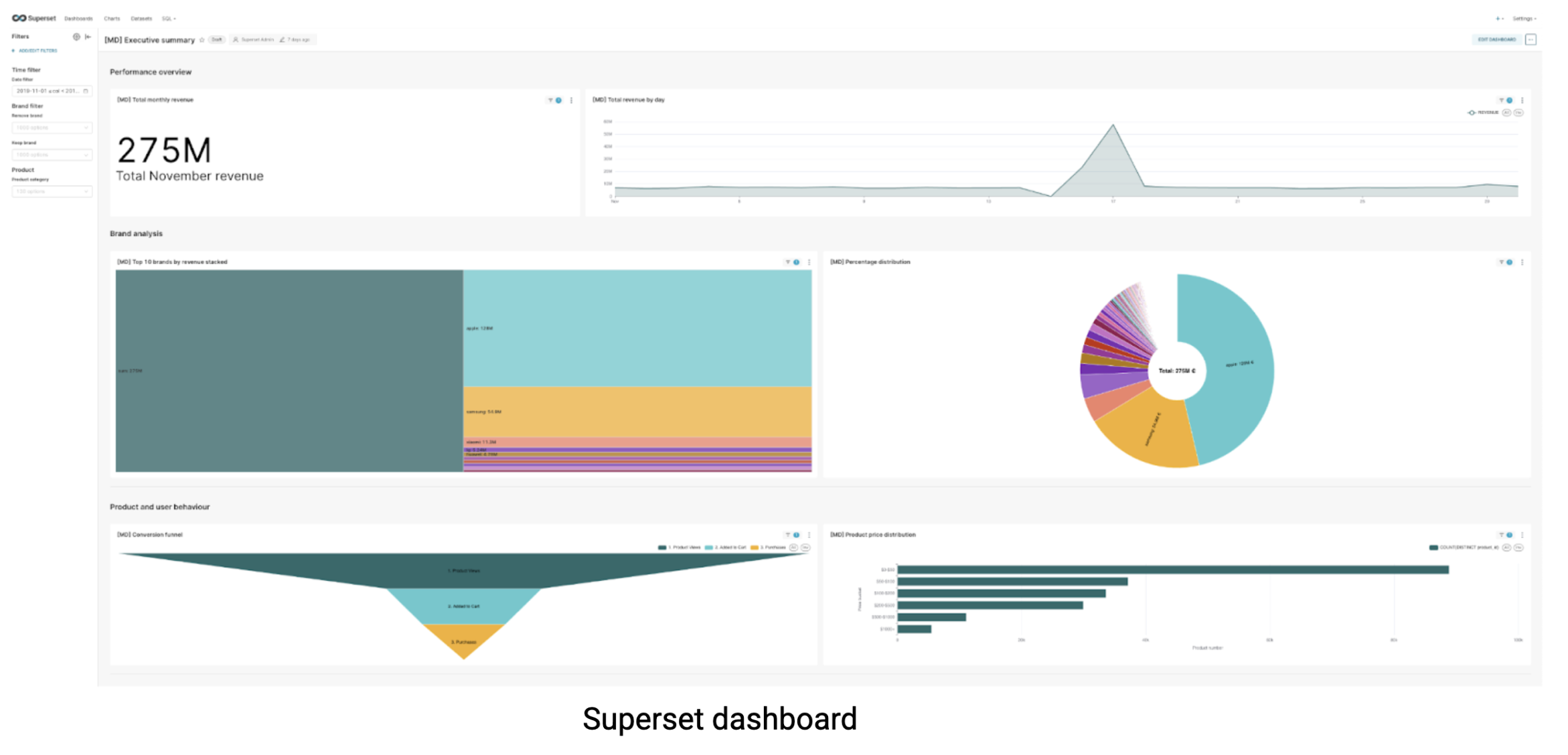
Ik heb het dashboard uitgebreid getest door het meerdere keren uit te voeren, door verschillende filters toe te passen, laadtijden te meten, cache uit te schakelen en reactietijden te controleren via de ontwikkelaarstools van mijn browser. Na meerdere testcycli om consistente resultaten te garanderen, zijn hier de prestatiecijfers van het dashboard in seconden:
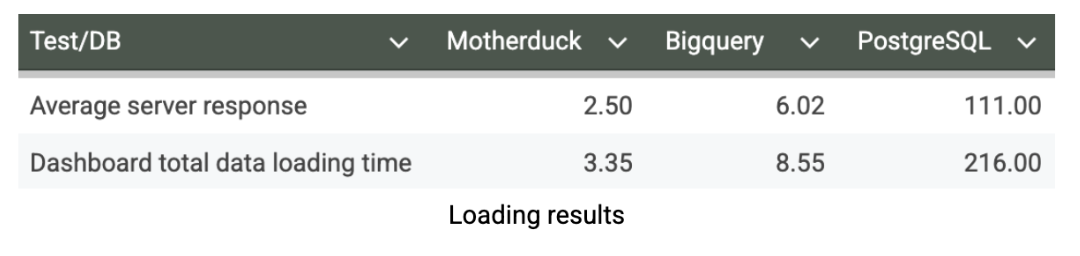
Onze dashboard laadtests onthullen de praktische implicaties van database prestaties op de gebruikerservaring. MotherDuck levert een uitzonderlijke respons op dashboards met een gemiddelde laadtijd van slechts 3,35 seconden, wat echt interactieve analyses mogelijk maakt waarbij gebruikers data vloeiend en zonder wrijving kunnen verkennen. BigQuery heeft daarentegen 8,55 seconden nodig om hetzelfde dashboard te laden. Dit is nog steeds acceptabel voor geplande rapportages, maar zorgt voor merkbare vertragingen die verkennende analyses kunnen ontmoedigen. PostgreSQL's laadtijd van 216 seconden (>3 minuten) maakt het volledig onpraktisch voor dashboardgebruik. Dit prestatievoordeel voor MotherDuck kan de manier waarop zakelijke gebruikers met data omgaan fundamenteel veranderen. Wanneer dashboards in seconden laden in plaats van minuten, stijgt de gebruikersadoptie, kunnen analisten inzichten snel itereren en wordt analyse een concurrentievoordeel in plaats van een knelpunt.
Prijsvergelijking
MotherDuck combineert opslag met pay-as-you-go rekenkracht, geoptimaliseerd voor interactieve analyses. Omdat het schaalt op een enkele machine in plaats van het te verdelen over een cluster, vermijdt het overhead waar gebruikers uiteindelijk voor betalen. Een sessie van tientallen query's kost misschien maar $0.05-$0.10, terwijl een team dat maandelijks duizenden query's uitvoert misschien maar $20-$40 uitgeeft. Daarentegen kunnen always-on data-bases $300-$500/maand kosten alleen al om live te blijven, en cloud-opslagplaatsen rekenen vaak $5-$10 per gescande TB. Met haar scale-up ontwerp houdt MotherDuck de prijzen eenvoudig, voorspelbaar en kostenefficiënt.

MotherDuck lijkt in eerste instantie duurder vanwege de organisatiekosten en het andere prijsmodel voor computing. Beide systemen gebruiken echter prijsmodellen die verschillende gebruikspatronen bevorderen: BigQuery blinkt uit in grote batchverwerking, terwijl MotherDuck geoptimaliseerd is voor interactieve analyses. Voor onze TPC-H benchmark kostte het uitvoeren van 22 queries op SF-10 $0,03 voor MotherDuckversus $0,60-$1,00 voor BigQuery. Als de overheadkosten van de infrastructuur worden meegerekend (onze PostgreSQL setup kostte €14/dag alleen al om online te blijven), levert de serverloze aanpak van MotherDuck vaak superieure totale eigendomskosten voor interactieve analytische werklasten.
Op bedrijfsschaal verschuiven de kosten afhankelijk van de gebruikspatronen. BigQuery wordt rendabeler voor batchverwerking in zeer grote volumes, terwijl MotherDuck zijn voordeel behoudt voor interactieve analyses en verkennende workflows. Het belangrijkste inzicht: kies uw prijsmodel op basis van hoe uw team daadwerkelijk met data werkt, niet alleen op basis van de ruwe kosten per eenheid.
Opmerking: Alle prijsvoorbeelden zijn gebaseerd op de regio europa-west4 en moeten eerder als illustratief dan als exact worden beschouwd, aangezien de werkelijke kosten sterk afhankelijk zijn van specifieke gebruikspatronen en kenmerken van de data.
Conclusie
MotherDuck vertegenwoordigt een fundamentele verschuiving in de manier waarop we denken over analytische data-bases, een die de veronderstelling uitdaagt dat je complexe, gedistribueerde systemen nodig hebt om serieuze data werklasten aan te kunnen. Door de embedded filosofie van DuckDB uit te breiden naar de cloud, levert MotherDuck de samenwerkingsmogelijkheden die moderne data teams nodig hebben, met behoud van de ruwe prestaties die DuckDB uitzonderlijk maken.
Onze benchmarkresultaten vertellen een overtuigend verhaal: MotherDuck presteerde consistent aanzienlijk beter dan zowel BigQuery als PostgreSQL, met queryprestaties van subseconden op 10GB datasets en laadtijden van dashboards die echt interactieve analyses mogelijk maken. Het prestatievoordeel ten opzichte van BigQuery en het zeer grote voordeel ten opzichte van PostgreSQL in dashboardscenario's gaat niet alleen over snellere query's, het gaat over het transformeren van analyses in een meer interactieve, verkennende ervaring die data-driven besluitvorming aanmoedigt.
Het belangrijkste is misschien wel dat MotherDuck deze prestaties bereikt terwijl de complexiteit en kosten van de infrastructuur drastisch worden verminderd. Waar traditionele cloud setups een infrastructuur vereisen die altijd aanstaat en maandelijks honderden dollars kost, brengt het serverloze model van MotherDuck alleen het werkelijke gebruik in rekening, waardoor de kosten vaak lager uitvallen. De pay-per-compute prijsstelling sluit perfect aan bij hoe analisten in werkelijkheid werken: meerdere queries uitvoeren in onderzoekssessies in plaats van geïsoleerde, onregelmatige verzoeken.
De implicaties gaan verder dan alleen prestaties en kosten. MotherDuck's dual execution model en browsergebaseerde analysemogelijkheden suggereren een toekomst waarin de grens tussen lokaal en cloud computing steeds vloeibaarder wordt. In plaats van teams te dwingen om te kiezen tussen lokale eenvoud en schaalbaarheid op cloud, biedt MotherDuck beide, waarbij berekeningen op intelligente wijze worden gerouteerd naar waar dat het meest zinvol is.
Waar ik tijdens het testen echt van onder de indruk was, was de eenvoud van het gebruik en de installatie van MotherDuck. Dankzij het dubbele uitvoeringsmodel kon ik de data zowel lokaal als in de cloud tegelijkertijd bevragen, terwijl het opzetten van de verbinding tussen Superset en MotherDuck opmerkelijk eenvoudig was.
Voor organisaties die hun analytische mogelijkheden willen moderniseren, te beginnen bij de gouden laag, biedt MotherDuck een zeer aantrekkelijk voorstel: enterprise-grade prestaties, collaboratieve workflows en kostenefficiëntie, allemaal zonder de operationele overhead van de traditionele data magazijninfrastructuur. In een wereld waarin data-driven beslissingen in toenemende mate het concurrentievoordeel bepalen, is de mogelijkheid om data interactief te onderzoeken met subseconden snelheid niet alleen een nice-to-have, maar wordt het essentieel.
Klaar om het optreden van MotherDuck zelf te ervaren? U kunt beginnen met een 21 dagen gratis uitproberen of met hun gratis 10GB-abonnement om het te testen met uw eigen datasets en workloads. Als u wilt weten of MotherDuck bij uw specifieke data stack past of hulp nodig hebt bij de implementatie, neem dan contact op met ons team op Artefact, Wij beoordelen graag uw analytische behoeften en helpen u bij de overgang naar een efficiëntere, kosteneffectieve analyse-infrastructuur.
