
")




Knowledge Graphs turn data tables into navigable networks of meaning
Unlike SQL tables, which focus on isolated entities and facts, Knowledge Graphs reveal insights hidden in relationships
Traditional SQL databases organize information into tables of entities and facts, joined by explicit keys. This model is robust for transactions but fragile when the real world’s complexity and its web of interconnections need to be explored. In practice, many business questions cut across domains: How do customer complaints in service logs correlate with component failures reported in R&D? Which past projects reused the same technology stack and could accelerate a new initiative? These questions are not about individual records; they are about relationships.
Knowledge Graphs address this gap by modeling data as a network of interconnected entities linked through meaningful relationships. Instead of reconstructing context at query time, graphs store it natively. Each entity (a person, product, document, or project) becomes a node, and its connections (depends on, authored by, supplied through…) form the edges. Together they create a living, queryable map of the enterprise.
This graph-based approach underpins some of the most sophisticated data systems in the world. Google’s Knowledge Graph enables semantic search by connecting billions of entities and facts. LinkedIn’s Economic Graph models global professional relationships to surface insights about skills and opportunities. Amazon’s product and entity graphs enrich Alexa’s answers, power recommendations, and maintain a coherent product catalog. The same principle now scales to enterprises of all sizes: from banks tracing risk exposure across financial instruments to manufacturers mapping supplier dependencies.
These systems demonstrate how context compounds: as more entities and relationships connect, the graph becomes exponentially more insightful. Enterprises can now weave structured and unstructured data into a single semantic fabric, a living map of how information connects.
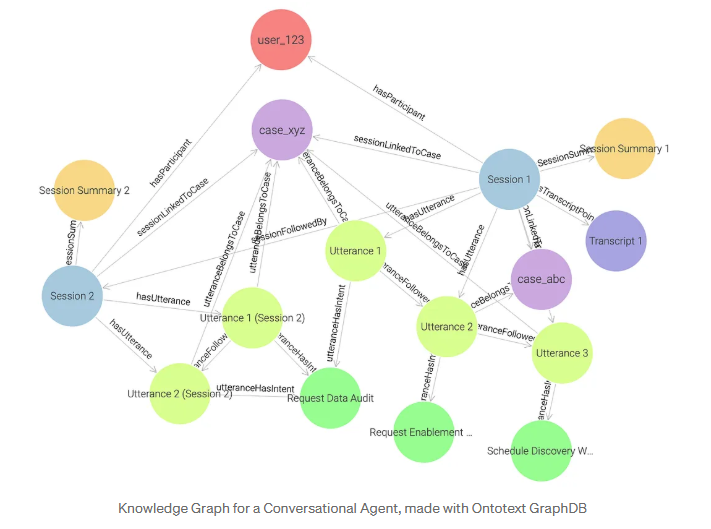
Graph queries replace complex table joins with intuitive relationship traversal unlocking high-value use-cases
The power of a Knowledge Graph is realized when it is queried. In a relational system, relationships are not inherent; they must be reconstructed through complex, multi-table JOINs. This process is slow, complex, and hard to extend to multi-hop reasoning. In a graph, relationships are embedded in the data. Querying becomes traversal: following edges from one node to another becomes a straightforward act using expressive languages such as Cypher or SPARQL.
If graphs change how we represent information, graph queries change how we reason with it, enabling high-impact use cases that are cumbersome or inefficient in tabular systems:
- Recommendations: Find similar items regarding their relationships: for example, products purchased by other people that have similar historical purchases or documents linked to similar topics, period, authors, etc.
- Fraud and risk detection: Detect hidden patterns such as connections between accounts, shared devices, or unusual transaction paths that are hard to spot in isolation.
- Traceability and compliance: Follow the lineage of a component, supplier, or decision across systems.
Beyond these classical examples, graph traversal is particularly well-suited to AI-generated queries. While large language models still need to understand the underlying schema to generate SPARQL or Cypher queries, graph query languages are far more compact and expressive than their SQL equivalents. Traversal-based queries are shorter, more semantically consistent, and easier to interpret, both by humans and by LLMs. This simplicity reduces generation errors and makes Knowledge Graphs a more robust substrate for automated or AI-assisted querying, a property that will become essential as autonomous agents begin to interact directly with enterprise data.

Technical notes:
- In the graph database, the SPARQL query leverages built-in inference: the engine can automatically deduce new relationships (facts) from existing links in the data model. For example, if an utterance is connected to both a case and a session, the engine can infer and automatically create the derived relationship mem:sessionLinkedToCase, linking the session directly to the case without needing to store it explicitly.
- The SPARQL path expression (^mem:hasParticipant/mems:sessionFollowedBy*) performs recursive traversal: it follows all sessions connected in a sequence starting from the user. This corresponds to the recursive CTE (WITH RECURSIVE … UNION ALL …) in SQL, which iteratively follows the next_session_id chain to retrieve all sessions belonging to the user.
- Because relationships are native edges in a graph, SPARQL expresses the same logic with far fewer joins. The pattern ?session mem:sessionLinkedToCase data:case_xyz directly captures what SQL must reconstruct through multiple table joins (JOIN utterances, JOIN cases), showing how traversal replaces relational complexity with semantic simplicity.
Knowledge Graphs give Agentic AI both flexibility and grounding
Agentic AI systems will not only predict or classify but reason, plan, and act within business processes. These agentic systems will make decisions autonomously, orchestrate workflows, and communicate with humans and other agents. But autonomy without grounding comes with risks: an agent that acts on unverified inferences or misinterpreted context can produce harmful outcomes. This is where Knowledge Graphs provide the right trade-off between data modeling flexibility and reliable grounding.
Flexibility for complex & dynamic reasoning
Traditional tables offer precision but little adaptability. Any schema change ripples across the system. Knowledge Graphs, on the other hand, provide a semantically flexible model where new entity types or relations can be introduced incrementally, without breaking existing structures. This makes them particularly suited for agentic systems that must integrate heterogeneous and volatile information, and update their understanding continuously.
This flexibility also extends to the fusion of structured data and unstructured text. For example, a graph can link a Contract node (with attributes like contract_id) to unstructured text segments and their embeddings. These text nodes then connect to higher-level semantic concepts or document classifications. In this architecture, an agent can perform retrieval (“find contracts related to topic X and retrieve their relevant text segments”) via deterministic graph queries rather than relying on ad-hoc RAG pipelines. The other way around is also possible: an agent can enrich chunks retrieved via vector similarity search from a vector store using the Knowledge Graph. The result is more reliable, explainable retrieval that combines symbolic structure with vector semantics in a single, coherent model.
Grounding autonomy in verifiable truth
Knowledge Graphs provide the semantic backbone that agentic systems need to act with confidence. They encode explicit, curated relationships that can be queried deterministically, producing the same answer every time, under well-defined logic. This stands in contrast to Retrieval-Augmented Generation (RAG), where responses depend on probabilistic ranking and text generation. While RAG remains valuable for open-ended exploration, its outputs are not guaranteed to be exhaustive and are difficult to verify. A Knowledge Graph, by contrast, offers complete recall within its scope and transparent provenance for every result.
When an agent operates over a Knowledge Graph, it is not assembling an answer from approximate textual matches: it is traversing verifiable connections grounded in structured meaning. This distinction is critical for governance: it enables agents to plan multi-step actions confidently, infer new relationships from trusted data, and explain their reasoning through auditable paths.
Ontologies make Enterprise Knowledge understandable by machines
The reliability of a Knowledge Graph ultimately depends on the quality and trustworthiness of the data that populates it, yet most enterprise knowledge remains trapped in unstructured formats: documents, emails, chat logs, project notes. Extracting structured meaning from this “dark data” is where ontologies become strategic assets.
From shared language to shared logic
An ontology is a formal model of the business domain: a shared vocabulary of entities (e.g., “Project,” “Supplier,” “Risk”) and the relationships that connect them (“delivers,” “depends on,” “caused by”). It encodes the core concepts and rules behind business processes. It can be used as the architectural blueprint that enables the transformation of raw language into machine-readable knowledge, preventing ambiguity in concepts (like “customer,” “account,” or “partner”) and ensuring that every agent speaks the same conceptual language. An ontology is not frozen architecture: it’s a living governance artifact. As the business evolves, maintaining its relevance becomes part of the organization’s semantic maturity.
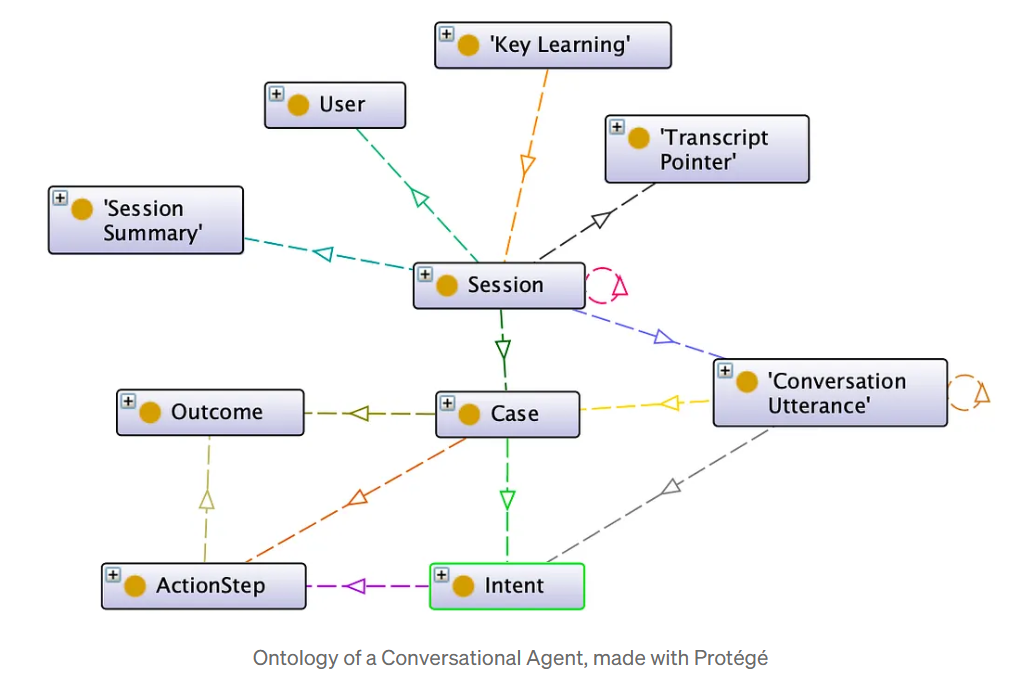
Bringing unstructured text into the graph
Text-to-graph pipelines use Natural Language Processing (NLP) and entity extraction guided by the ontology to populate the Knowledge Graph automatically. For example:
- Centralized collection – long-term memory of agents: Operational logs and conversation histories can be consolidated into a shared graph, giving AI assistants persistent recall of past context and decisions. This ensures completeness and accuracy in queries about historical actions, more reliable than probabilistic retrieval over raw text.
- Decentralized contribution – future discoverability of projects: A shared knowledge graph can gradually centralize information on all company projects, while project teams contribute directly by attaching machine-readable metadata to documents stored in shared drives. This also encourages them to process key information about their projects across documents, building a semantic index that future teams and agents can easily explore through graph queries.
Keeping meaning, quality, and trust alive
Human validation remains essential in high-stakes scenarios, financial reporting, regulatory audit, but automation can handle most low-risk cases, such as conversational assistants. The ontology’s constraints act as a quality gate, ensuring that new data aligns with organizational semantics and can be trusted by downstream AI systems.
Of course, maintaining this flexibility has a cost: ontologies must evolve alongside the business. Yet this maintenance is far lighter than the recurring effort of cleaning and re-joining disparate tables. The return is a self-consistent, explainable data fabric that every AI agent can query confidently.
Semantics: The Governance Glue of the Data & Agentic Mesh
As organizations deploy multiple AI agents across domains such as customer service, operations, and R&D, coordination becomes the next challenge. Without shared and connected semantics, agents risk duplication, inconsistent decisions, and opaque behavior.
This is where Semantics and Ontologies may become the governance glue of the emerging Data & Agentic Mesh. This emerging ‘Data & Agentic Mesh’ extends the Data Mesh principle, decentralizing not just data ownership, but also AI reasoning across interoperable, semantically connected agents. Imagine each department maintaining its own small web of knowledge, interconnected through shared ontological bridges, a semantic network that grows like a living organism rather than a centralized database. Instead of building a single monolithic knowledge graph that becomes exponentially complex to maintain, organizations should create multi-scale graphs that coexist at different levels, each optimized for specific problems yet aligned through shared semantics. By storing both data product metadata and agent metadata in a shared Enterprise Knowledge Graph, enterprises ensure that every asset, whether a dataset, an API, or an autonomous agent, is described in the same conceptual language and can interoperate seamlessly. Enriched with ontologies, the Enterprise Knowledge Graph acts as a Reliable Data & Agentic Catalog, connecting local ontologies to a shared backbone, and aligning Data Products and Agent behaviors under consistent rules and shared context.

In a graph-based ecosystem:
- Semantic intent routing and discoverability: Requests are directed to the right agent, dataset, or service based on meaning and rules, not fragile keywords or manual orchestration. Teams and agents can locate relevant capabilities (“Which agent monitors supplier performance?”) through graph traversal rather than retrieving knowledge stored in vector stores.
- Traceability and auditability by design: Every agent action and data dependency is linked through the graph, making decisions explainable and compliance reviews straightforward. Semantic matching and rules also highlight when new agents or data products overlap with existing ones, preventing redundant effort and inconsistent behavior before they grow.
Semantics make data and agents interoperable by default, enabling AI Agents to navigate the enterprise with the same clarity humans expect from organizational charts and processes. The Enterprise Knowledge Graph becomes the connective fabric that allows agents not only to access information, but to understand and coordinate around it.
Conclusion
The question is no longer whether AI agents can reason and act, it is whether they can reliably understand and leverage your “secret sauce”. As enterprises adopt AI agents that must coordinate and decide, the need for a reliable backbone becomes undeniable; one that evolves with the business yet remains grounded in truth. Knowledge Graphs offer that balance and a practical path, connecting existing systems through meaning instead of code. Guided by ontologies, they turn data into durable, explainable knowledge, the foundation of agentic intelligence.
In a world where intelligence becomes a commodity, where LLMs and algorithms are widely available, structured, interpretable, and proprietary knowledge emerges as the true differentiating asset. Where data describes what happened, knowledge captures why: the causal, relational understanding that gives decisions lasting value. Unlike generic intelligence, this knowledge encodes the organization’s unique processes, relationships, and expertise, which are assets that cannot be easily replicated or commoditized. While alternative architectures such as vector databases or hybrid embedding systems will play a role, Ontologies and Knowledge Graphs remain among the most mature and explainable ways we know to capture and preserve knowledge in a form both humans and machines can reason over. They make corporate memory computable, enabling agents not only to access information but to build upon it, learn from it, and extend it.
The future of agentic AI won’t rely only on Knowledge Graphs, but it will rely on the principles they embody: structured meaning, verifiable reasoning, and machine-readable knowledge. Enterprises that invest in this semantic foundation today and sustain it through effective governance will not just deploy smarter systems. They will define the knowledge layer that shapes how those systems think, reason, and grow. In doing so, they will protect what is truly theirs: the knowledge that makes them unique.
