
")




Kennisgrafieken veranderen data tabellen in navigeerbare betekenisnetwerken
In tegenstelling tot SQL-tabellen, die zich richten op geïsoleerde entiteiten en feiten, onthullen kennisgrafieken inzichten die verborgen zijn in relaties
Traditionele SQL data-bases organiseren informatie in tabellen van entiteiten en feiten, verbonden door expliciete sleutels. Dit model is robuust voor transacties, maar kwetsbaar wanneer de complexiteit van de echte wereld en zijn web van onderlinge verbindingen onderzocht moeten worden. In de praktijk zijn veel bedrijfsvragen domeinoverschrijdend: Hoe verhouden klachten van klanten in servicelogs zich tot storingen van onderdelen die in R&D worden gerapporteerd? Welke projecten uit het verleden hergebruikten dezelfde technologiestapel en zouden een nieuw initiatief kunnen versnellen? Deze vragen gaan niet over individuele records, maar over relaties.
Kennisgrafieken pakken deze leemte aan door data te modelleren als een netwerk van onderling verbonden entiteiten die verbonden zijn door betekenisvolle relaties. In plaats van de context te reconstrueren tijdens het opvragen, wordt deze in grafieken opgeslagen. Elke entiteit (een persoon, product, document of project) wordt een knooppunt, en zijn verbindingen (hangt af van, geschreven door, geleverd door...) vormen de randen. Samen vormen ze een levende, doorzoekbare kaart van de onderneming.
Deze op grafieken gebaseerde benadering ligt ten grondslag aan enkele van de meest geavanceerde data systemen ter wereld. Google's Knowledge Graph maakt semantisch zoeken mogelijk door miljarden entiteiten en feiten met elkaar te verbinden. De Economic Graph van LinkedIn modelleert wereldwijde professionele relaties om inzichten over vaardigheden en kansen te verkrijgen. De product- en entiteitsgrafieken van Amazon verrijken de antwoorden van Alexa, geven aanbevelingen en zorgen voor een coherente productcatalogus. Hetzelfde principe kan nu worden toegepast op ondernemingen van alle groottes: van banken die risicoposities in financiële instrumenten traceren tot fabrikanten die de afhankelijkheid van leveranciers in kaart brengen.
Deze systemen laten zien hoe context zich samenvoegt: naarmate meer entiteiten en relaties met elkaar verbonden worden, wordt de grafiek exponentieel inzichtelijker. Bedrijven kunnen nu gestructureerde en ongestructureerde data verweven tot één semantisch weefsel, een levende kaart van hoe informatie met elkaar verbonden is.
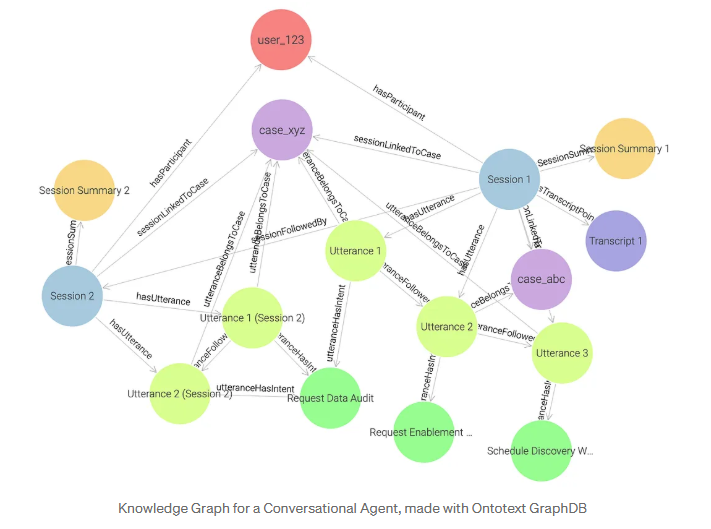
Graph-query's vervangen complexe tabeljoins door intuïtieve relatietraversal en ontsluiten hoogwaardige gebruikssituaties
De kracht van een Kennisgrafiek komt pas tot uiting als deze wordt opgevraagd. In een relationeel systeem zijn relaties niet inherent; ze moeten gereconstrueerd worden door middel van complexe, multi-tabel JOIN's. Dit proces is traag, complex en moeilijk uit te breiden naar multi-hop redeneren. Dit proces is traag, complex en moeilijk uit te breiden naar multi-hop redeneren. In een grafiek zijn relaties ingebed in de data. Query's worden traversal: het volgen van randen van het ene knooppunt naar het andere wordt een eenvoudige handeling met behulp van expressieve talen zoals Cypher of SPARQL.
Als grafieken de manier veranderen waarop we informatie weergeven, dan veranderen grafiekquery's de manier waarop we met die informatie redeneren, waardoor gebruiksscenario's met hoge impact mogelijk worden die in systemen met tabellen omslachtig of inefficiënt zijn:
- Aanbevelingen: Vergelijkbare items vinden met betrekking tot hun relaties: bijvoorbeeld producten gekocht door andere mensen met vergelijkbare historische aankopen of documenten gekoppeld aan vergelijkbare onderwerpen, periode, auteurs, enz.
- Fraude- en risicodetectie: Detecteer verborgen patronen zoals verbindingen tussen accounts, gedeelde apparaten of ongebruikelijke transactiepaden die moeilijk afzonderlijk te ontdekken zijn.
- Traceerbaarheid en naleving: Volg de afkomst van een onderdeel, leverancier of beslissing in verschillende systemen.
Naast deze klassieke voorbeelden is graph traversal bijzonder geschikt voor AI-gegenereerde queries. Hoewel grote taalmodellen nog steeds het onderliggende schema moeten begrijpen om SPARQL- of Cypher-query's te genereren, grafische querytalen zijn veel compacter en expressiever dan hun SQL-equivalenten. Op traversal gebaseerde query's zijn korter, semantisch consistenter en gemakkelijker te interpreteren, zowel door mensen als door LLM's. Deze eenvoud vermindert generatiefouten en maakt van kennisgrafieken een robuuster substraat voor geautomatiseerd of AI-ondersteund zoeken, een eigenschap die essentieel zal worden als autonome agenten direct beginnen te communiceren met Enterprise data.

Technische opmerkingen:
- In de grafiek database maakt de SPARQL query gebruik van ingebouwde inferentie: de engine kan automatisch nieuwe relaties (feiten) afleiden uit bestaande koppelingen in het data model. Als een uiting bijvoorbeeld verbonden is met zowel een zaak als een sessie, kan de engine de afgeleide relatie mem:sessionLinkedToCase afleiden en automatisch aanmaken, waardoor de sessie direct aan de zaak wordt gekoppeld zonder dat deze expliciet hoeft te worden opgeslagen.
- De SPARQL pad expressie (^mem:hasParticipant/mems:sessionFollowedBy*) voert recursieve traversal uit: het volgt alle sessies die in een volgorde verbonden zijn, beginnend bij de gebruiker. Dit komt overeen met de recursieve CTE (WITH RECURSIVE ... UNION ALL ...) in SQL, die iteratief de next_session_id keten volgt om alle sessies op te halen die bij de gebruiker horen.
- Omdat relaties eigen randen in een grafiek zijn, drukt SPARQL dezelfde logica uit met veel minder joins. Het patroon ?session mem:sessionLinkedToCase data:case_xyz legt direct vast wat SQL moet reconstrueren door meerdere tabelverbindingen (JOIN-uitingen, JOIN-gevallen), en laat zien hoe traversal relationele complexiteit vervangt door semantische eenvoud.
Kennisgrafieken geven Agentic AI zowel flexibiliteit als gronding
Agent-AI systemen zullen niet alleen voorspellen of classificeren, maar ook redeneren, plannen en handelen binnen bedrijfsprocessen. Deze agentgebaseerde systemen zullen autonoom beslissingen nemen, workflows orkestreren en communiceren met mensen en andere agenten. Maar autonomie zonder fundering brengt risico's met zich mee: een agent die handelt op basis van niet-geverifieerde conclusies of verkeerd geïnterpreteerde context kan schadelijke gevolgen hebben. Dit is waar kennisgrafieken de juiste afweging bieden tussen data modelleerflexibiliteit en betrouwbare aarding.
Flexibiliteit voor complexe & dynamische redeneringen
Traditionele tabellen bieden precisie maar weinig aanpassingsvermogen. Elke wijziging in het schema heeft gevolgen voor het hele systeem. Kennisgrafieken daarentegen bieden een semantisch flexibel model waar nieuwe entiteittypes of relaties incrementeel geïntroduceerd kunnen worden, zonder bestaande structuren te verbreken. Dit maakt ze bijzonder geschikt voor agentiële systemen die heterogene en vluchtige informatie moeten integreren en hun begrip voortdurend moeten bijwerken.
Deze flexibiliteit strekt zich ook uit tot de fusie van gestructureerde data en ongestructureerde tekst. Een grafiek kan bijvoorbeeld een contractknooppunt (met attributen zoals contract_id) koppelen aan ongestructureerde tekstsegmenten en hun inbeddingen. Deze tekstknooppunten worden dan gekoppeld aan semantische concepten of documentclassificaties van een hoger niveau. In deze architectuur kan een agent opzoekingen uitvoeren (“zoek contracten met betrekking tot onderwerp X en haal hun relevante tekstsegmenten op”) via deterministische grafiekquery's in plaats van te vertrouwen op ad-hoc RAG-pijplijnen. Andersom is ook mogelijk: een agent kan chunks die via vector similarity search uit een vectoropslag zijn opgehaald, verrijken met behulp van de Kennisgrafiek. Het resultaat is een betrouwbaarder, verklaarbaar ophalen dat symbolische structuur combineert met vectorsemantiek in een enkel, coherent model.
Autonomie gronden in verifieerbare waarheid
Kennisgrafieken bieden de semantische ruggengraat die agentische systemen nodig hebben om met vertrouwen te handelen. Ze coderen expliciete, gecureerde relaties die kunnen worden deterministisch opgevraagd, en levert telkens hetzelfde antwoord op, volgens een goed gedefinieerde logica. Dit staat in contrast met Ophalen-Gecontroleerde Generatie (RAG), waarbij de antwoorden afhankelijk zijn van probabilistische rangschikking en tekstgeneratie. Hoewel RAG waardevol blijft voor open exploratie, is de uitvoer ervan niet gegarandeerd volledig en moeilijk te verifiëren. Een kennisgrafiek biedt daarentegen volledige terugroeping binnen haar bereik en transparante herkomst voor elk resultaat.
Wanneer een agent een kennisgrafiek gebruikt, is hij niet bezig met het samenstellen van een antwoord uit tekstuele overeenkomsten die bij benadering overeenkomen: hij is bezig met doorkruisen van controleerbare verbindingen gegrond in gestructureerde betekenis. Dit onderscheid is cruciaal voor bestuur: het stelt agenten in staat om acties in meerdere stappen vol vertrouwen te plannen, nieuwe relaties af te leiden uit vertrouwde data en hun redenering uit te leggen via controleerbare paden.
Ontologieën maken bedrijfskennis begrijpelijk voor machines
De betrouwbaarheid van een kennisgrafiek hangt uiteindelijk af van de kwaliteit en betrouwbaarheid van de data die erin staat, maar de meeste bedrijfskennis blijft gevangen in ongestructureerde formatenDocumenten, e-mails, chatlogs, projectnotities. Gestructureerde betekenis halen uit deze “donkere data” is waar ontologieën strategische activa worden.
Van gedeelde taal naar gedeelde logica
Een ontologie is een formeel model van het bedrijfsdomein: een gedeelde woordenschat van entiteiten (bijv. “Project”, “Leverancier”, “Risico”) en de relaties die ze met elkaar verbinden (“levert”, “hangt af van”, “veroorzaakt door”). Het codeert de kernconcepten en regels achter bedrijfsprocessen. Het kan worden gebruikt als de architecturale blauwdruk die de transformatie van ruwe taal in machineleesbare kennis mogelijk maakt, ambiguïteit in concepten (zoals “klant”, “account” of “partner”) voorkomt en ervoor zorgt dat elke agent dezelfde conceptuele taal spreekt. Een ontologie is geen bevroren architectuur: het is een levend bestuursartefact. Naarmate het bedrijf zich ontwikkelt, wordt het onderhouden van de relevantie ervan onderdeel van de semantische volwassenheid van de organisatie.
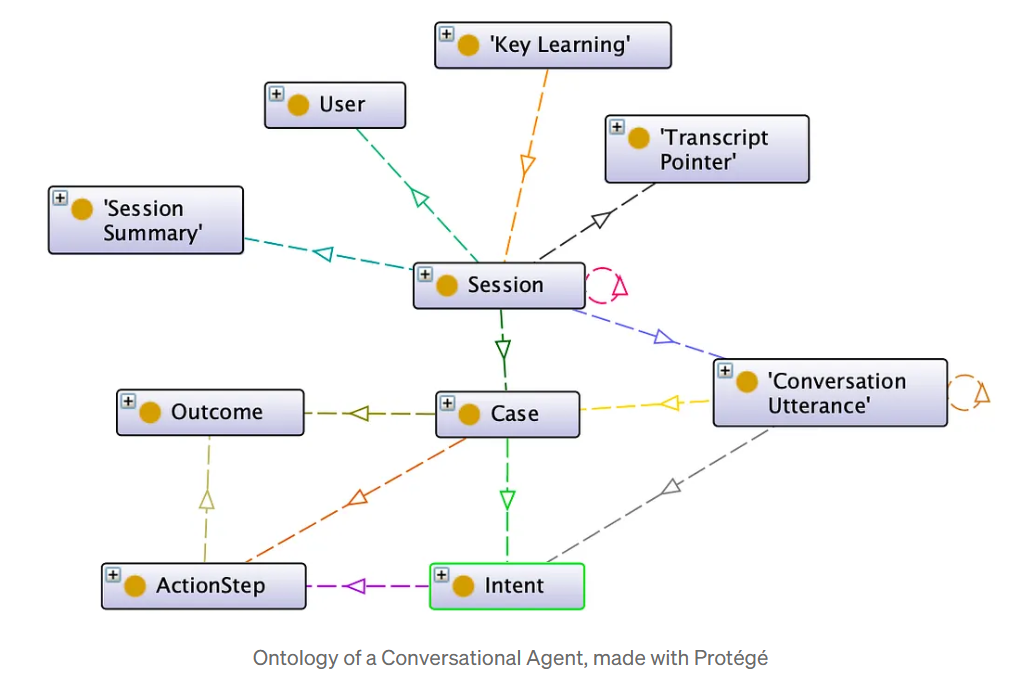
Ongestructureerde tekst in de grafiek brengen
Tekst-naar-grafiek pijplijnen Natural Language Processing (NLP) en entiteitextractie gebruiken op basis van de ontologie om de kennisgrafiek automatisch te vullen. Bijvoorbeeld:
- Gecentraliseerde verzameling - langetermijngeheugen van agenten: Operationele logboeken en gesprekshistorieken kunnen worden geconsolideerd in een gedeelde grafiek, waardoor AI-assistenten blijvende herinneringen hebben aan eerdere contexten en beslissingen. Dit zorgt voor volledigheid en nauwkeurigheid bij query's over historische acties, betrouwbaarder dan probabilistische retrieval via onbewerkte tekst.
- Gedecentraliseerde bijdrage - toekomstige vindbaarheid van projecten: Een gedeelde kennisgrafiek kan geleidelijk informatie over alle bedrijfsprojecten centraliseren, terwijl projectteams rechtstreeks bijdragen door machineleesbare metadata toe te voegen aan documenten die zijn opgeslagen op gedeelde schijven. Dit moedigt hen ook aan om belangrijke informatie over hun projecten in documenten te verwerken en zo een semantische index op te bouwen die toekomstige teams en agents gemakkelijk kunnen verkennen door middel van grafiekquery's.
Betekenis, kwaliteit en vertrouwen levend houden
Menselijke validatie blijft essentieel in scenario's waar veel op het spel staat, financiële verslaglegging, wettelijke controle, maar automatisering kan de meeste gevallen met een laag risico aan, zoals conversatieassistenten. De beperkingen van de ontologie fungeren als een kwaliteitspoort, en zorgt ervoor dat de nieuwe data overeenkomt met de semantiek van de organisatie en vertrouwd kan worden door AI-systemen verderop in de keten.
Natuurlijk brengt het behoud van deze flexibiliteit kosten met zich mee: ontologieën moeten samen met het bedrijf evolueren. Toch is dit onderhoud veel lichter dan de terugkerende inspanning van het opschonen en opnieuw samenvoegen van ongelijksoortige tabellen. Het rendement is een zelfconsistent, verklaarbaar data weefsel die elke AI-agent met vertrouwen kan bevragen.
Semantiek: De bestuurlijke lijm van de Data & Agentic Mesh
Naarmate organisaties meerdere AI-agenten inzetten in domeinen zoals klantenservice, operations en R&D, wordt coördinatie de volgende uitdaging. Zonder gedeelde en verbonden semantiek riskeren agents duplicatie, inconsistente beslissingen en ondoorzichtig gedrag.
Dit is waar Semantiek en Ontologieën de bestuurlijke lijm kunnen worden van de opkomende Data & Agentic Mesh. Deze opkomende ‘Data & Agentic Mesh’ breidt het principe van de Data Mesh uit door niet alleen het eigendom van data te decentraliseren, maar ook het AI-redeneren over interoperabele, semantisch verbonden agenten. Stelt u zich eens voor dat elke afdeling zijn eigen kleine web van kennis onderhoudt, onderling verbonden door gedeelde ontologische bruggen, een semantisch netwerk dat groeit als een levend organisme in plaats van een gecentraliseerde data-basis. In plaats van één enkele monolithische kennisgrafiek te bouwen die exponentieel complex wordt om te onderhouden, zouden organisaties grafieken op meerdere schaal moeten creëren die naast elkaar bestaan op verschillende niveaus, elk geoptimaliseerd voor specifieke problemen maar op elkaar afgestemd via gedeelde semantiek. Door zowel data product metadata als agent metadata op te slaan in een gedeelde Enterprise Knowledge Graph, zorgen bedrijven ervoor dat elk bedrijfsmiddel, of het nu een dataset, een API of een autonome agent is, wordt beschreven in dezelfde conceptuele taal en naadloos kan samenwerken. Verrijkt met ontologieën, fungeert de Enterprise Knowledge Graph als een Betrouwbare Data & Agentic Catalogus, die lokale ontologieën verbindt met een gedeelde ruggengraat, en die Data Producten en Agentgedrag afstemt op consistente regels en een gedeelde context.

In een op grafieken gebaseerd ecosysteem:
- Semantische intentierouting en vindbaarheid: Verzoeken worden naar de juiste agent, dataset of service geleid op basis van betekenis en regels, niet op basis van fragiele trefwoorden of handmatige orkestratie. Teams en agenten kunnen relevante mogelijkheden vinden (“Welke agent bewaakt de prestaties van de leverancier?”) via grafiektraversal in plaats van het ophalen van kennis die is opgeslagen in vectoropslagplaatsen.
- Traceerbaarheid en controleerbaarheid door ontwerp: Elke agentactie en data-afhankelijkheid is gekoppeld via de grafiek, waardoor beslissingen verklaarbaar zijn en nalevingscontroles eenvoudig zijn. Semantische matching en regels geven ook aan wanneer nieuwe agents of data producten overlappen met bestaande agents, waardoor overbodige inspanningen en inconsistent gedrag worden voorkomen voordat ze groter worden.
Semantiek maakt data en agents standaard interoperabel, waardoor AI-agents door de onderneming kunnen navigeren met dezelfde duidelijkheid die mensen verwachten van organigrammen en processen. De Enterprise Knowledge Graph wordt het verbindende weefsel dat agenten niet alleen toegang geeft tot informatie, maar ook in staat stelt om deze te begrijpen en te coördineren.
Conclusie
De vraag is niet langer of AI-agenten kunnen redeneren en handelen, maar of ze uw “geheime saus” op betrouwbare wijze kunnen begrijpen en gebruiken. Naarmate bedrijven AI-agenten gaan gebruiken die moeten coördineren en beslissen, wordt de behoefte aan een betrouwbare ruggengraat onmiskenbaar; een ruggengraat die met het bedrijf mee evolueert, maar toch gegrond blijft in de waarheid. Kennisgrafieken bieden dat evenwicht en een praktisch pad, door bestaande systemen met elkaar te verbinden door middel van betekenis in plaats van code. Geleid door ontologieën zetten ze data om in duurzame, verklaarbare kennis, de basis van agentic intelligence.
In een wereld waar intelligentie handelswaar wordt, waar LLM's en algoritmen alom beschikbaar zijn, komt gestructureerde, interpreteerbare en bedrijfseigen kennis naar voren als het echte onderscheidende vermogen. Waar data beschrijft wat er is gebeurd, legt kennis vast waarom: het causale, relationele begrip dat beslissingen blijvende waarde geeft. In tegenstelling tot algemene intelligentie, omvat deze kennis de unieke processen, relaties en expertise van de organisatie, activa die niet gemakkelijk kunnen worden gekopieerd of verhandeld. Hoewel alternatieve architecturen zoals vector databases of hybride inbeddingsystemen een rol zullen spelen, blijven Ontologieën en Kennisgrafieken de meest volwassen en verklaarbare manieren die we kennen om kennis vast te leggen en te bewaren in een vorm waar zowel mensen als machines over kunnen redeneren. Ze maken het bedrijfsgeheugen berekenbaar, zodat agenten niet alleen toegang hebben tot informatie, maar er ook op kunnen bouwen, ervan kunnen leren en het kunnen uitbreiden.
De toekomst van agentische AI zal niet alleen gebaseerd zijn op kennisgrafieken, maar wel op de principes die ze belichamen: gestructureerde betekenis, verifieerbare redenering en machineleesbare kennis. Ondernemingen die vandaag in dit semantische fundament investeren en het onderhouden door middel van effectief bestuur, zullen niet alleen slimmere systemen implementeren. Ze zullen de kennislaag definiëren die vorm geeft aan hoe die systemen denken, redeneren en groeien. Hierdoor beschermen ze wat echt van hen is: de kennis die hen uniek maakt.
