
")




Os gráficos de conhecimento transformam as tabelas data em redes navegáveis de significado
Diferentemente das tabelas SQL, que se concentram em entidades e fatos isolados, os Knowledge Graphs revelam insights ocultos nos relacionamentos
As bases SQL data tradicionais organizam as informações em tabelas de entidades e fatos, unidas por chaves explícitas. Esse modelo é robusto para transações, mas frágil quando a complexidade do mundo real e sua rede de interconexões precisam ser exploradas. Na prática, muitas questões comerciais abrangem vários domínios: Como as reclamações dos clientes nos registros de serviço se correlacionam com as falhas de componentes relatadas em P&D? Quais projetos anteriores reutilizaram a mesma pilha de tecnologia e poderiam acelerar uma nova iniciativa? Essas perguntas não se referem a registros individuais, mas a relacionamentos.
Os gráficos de conhecimento abordam essa lacuna ao modelar o data como uma rede de entidades interconectadas ligadas por meio de relacionamentos significativos. Em vez de reconstruir o contexto no momento da consulta, os gráficos o armazenam nativamente. Cada entidade (uma pessoa, um produto, um documento ou um projeto) torna-se um nó e suas conexões (depende de, é de autoria de, é fornecido por meio de...) formam as bordas. Juntos, eles criam um mapa vivo e consultável da empresa.
Essa abordagem baseada em gráficos é a base de alguns dos sistemas data mais sofisticados do mundo. O Knowledge Graph do Google permite a pesquisa semântica ao conectar bilhões de entidades e fatos. O Economic Graph do LinkedIn modela as relações profissionais globais para revelar percepções sobre habilidades e oportunidades. Os gráficos de produtos e de entidades da Amazon enriquecem as respostas da Alexa, potencializam as recomendações e mantêm um catálogo de produtos coerente. O mesmo princípio agora pode ser aplicado a empresas de todos os portes: de bancos que rastreiam a exposição a riscos em instrumentos financeiros a fabricantes que mapeiam as dependências de fornecedores.
Esses sistemas demonstram como o contexto se compõe: à medida que mais entidades e relacionamentos se conectam, o gráfico se torna exponencialmente mais perspicaz. Agora, as empresas podem entrelaçar data estruturados e não estruturados em um único tecido semântico, um mapa vivo de como as informações se conectam.
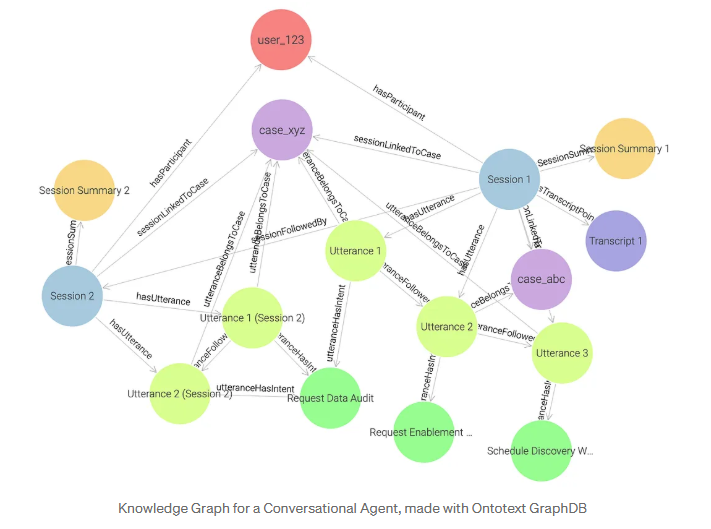
As consultas de gráficos substituem as complexas uniões de tabelas por uma passagem de relacionamento intuitiva, desbloqueando casos de uso de alto valor
O poder de um Knowledge Graph é percebido quando ele é consultado. Em um sistema relacional, as relações não são inerentes; elas precisam ser reconstruídas por meio de JOINs complexos e com várias tabelas. Esse processo é lento, complexo e difícil de ser estendido ao raciocínio multihop. Em um gráfico, as relações são incorporadas no data. A consulta se torna uma travessia: seguir as bordas de um nó para outro se torna um ato simples usando linguagens expressivas como Cypher ou SPARQL.
Se os gráficos mudam a forma como representamos as informações, as consultas em gráficos mudam a forma como raciocinamos com elas, permitindo casos de uso de alto impacto que são complicados ou ineficientes em sistemas tabulares:
- Recomendações: Localizar itens semelhantes em relação a seus relacionamentos: por exemplo, produtos comprados por outras pessoas que tenham histórico de compras semelhante ou documentos vinculados a tópicos, períodos, autores etc. semelhantes.
- Detecção de fraudes e riscos: Detecte padrões ocultos, como conexões entre contas, dispositivos compartilhados ou caminhos de transações incomuns que são difíceis de detectar isoladamente.
- Rastreabilidade e conformidade: Acompanhar a linhagem de um componente, fornecedor ou decisão em todos os sistemas.
Além desses exemplos clássicos, a travessia de gráficos é particularmente adequada para consultas geradas por IA. Embora os grandes modelos de linguagem ainda precisem entender o esquema subjacente para gerar consultas SPARQL ou Cypher, as linguagens de consulta de gráficos são muito mais compactas e expressivas do que seus equivalentes em SQL. As consultas baseadas em travessia são mais curtas, semanticamente mais consistentes e mais fáceis de interpretar, tanto por humanos quanto por LLMs. Essa simplicidade reduz os erros de geração e torna os gráficos de conhecimento um substrato mais robusto para consulta automatizada ou assistida por IA, A propriedade que se tornará essencial à medida que o agentes autônomos começar a interagir diretamente com a empresa data.

Notas técnicas:
- No gráfico database, a consulta SPARQL aproveita a inferência integrada: o mecanismo pode deduzir automaticamente novos relacionamentos (fatos) a partir de links existentes no modelo data. Por exemplo, se um enunciado estiver conectado a um caso e a uma sessão, o mecanismo pode inferir e criar automaticamente o relacionamento derivado mem:sessionLinkedToCase, vinculando a sessão diretamente ao caso sem a necessidade de armazená-la explicitamente.
- A expressão de caminho SPARQL (^mem:hasParticipant/mems:sessionFollowedBy*) executa uma passagem recursiva: ela segue todas as sessões conectadas em uma sequência que começa com o usuário. Isso corresponde ao CTE recursivo (WITH RECURSIVE ... UNION ALL ...) no SQL, que segue iterativamente a cadeia next_session_id para recuperar todas as sessões pertencentes ao usuário.
- Como os relacionamentos são bordas nativas em um gráfico, o SPARQL expressa a mesma lógica com muito menos uniões. O padrão ?session mem:sessionLinkedToCase data:case_xyz captura diretamente o que o SQL deve reconstruir por meio de várias uniões de tabelas (enunciados JOIN, casos JOIN), mostrando como a passagem substitui a complexidade relacional pela simplicidade semântica.
Os gráficos de conhecimento proporcionam à IA agêntica flexibilidade e embasamento
Os sistemas de IA agêntica não apenas preveem ou classificam, mas raciocinam, planejam e agem nos processos de negócios. Esses sistemas agênticos tomarão decisões de forma autônoma, orquestrarão fluxos de trabalho e se comunicarão com humanos e outros agentes. Mas a autonomia sem embasamento traz riscos: um agente que age com base em inferências não verificadas ou em um contexto mal interpretado pode produzir resultados prejudiciais. É nesse ponto que os gráficos de conhecimento oferecem o equilíbrio certo entre Flexibilidade de modelagem do data e aterramento confiável.
Flexibilidade para raciocínio complexo e dinâmico
As tabelas tradicionais oferecem precisão, mas pouca adaptabilidade. Qualquer alteração no esquema repercute em todo o sistema. Os gráficos de conhecimento, por outro lado, oferecem uma modelo semanticamente flexível onde novos tipos de entidades ou relações podem ser introduzidos de forma incremental, sem quebrar as estruturas existentes. Isso os torna particularmente adequados para sistemas agênticos que precisam integrar informações heterogêneas e voláteis e atualizar seu entendimento continuamente.
Essa flexibilidade também se estende à fusão de data estruturado e texto não estruturado. Por exemplo, um gráfico pode vincular um nó de contrato (com atributos como contract_id) a segmentos de texto não estruturados e suas incorporações. Esses nós de texto se conectam a conceitos semânticos de nível superior ou a classificações de documentos. Nessa arquitetura, um agente pode executar a recuperação (“encontre contratos relacionados ao tópico X e recupere seus segmentos de texto relevantes”) por meio de consultas determinísticas a gráficos em vez de depender de pipelines RAG ad-hoc. O inverso também é possível: um agente pode enriquecer pedaços recuperados por meio de pesquisa de similaridade vetorial de um armazenamento de vetores usando o Knowledge Graph. O resultado é uma recuperação mais confiável e explicável que combina a estrutura simbólica com a semântica do vetor em um modelo único e coerente.
Fundamentar a autonomia em uma verdade verificável
Os gráficos de conhecimento fornecem a espinha dorsal semântica que os sistemas agênticos precisam para agir com confiança. Eles codificam relacionamentos explícitos e com curadoria que podem ser consultado de forma determinística, O senhor pode usar a lógica bem definida, produzindo sempre a mesma resposta. Isso contrasta com a Geração Aumentada por Recuperação (RAG), O RAG é uma ferramenta de pesquisa de dados, em que as respostas dependem da classificação probabilística e da geração de texto. Embora o RAG continue valioso para a exploração aberta, seus resultados não têm garantia de serem exaustivos e são difíceis de verificar. Um Knowledge Graph, por outro lado, oferece recall completo dentro de seu escopo e procedência transparente para cada resultado.
Quando um agente opera em um Knowledge Graph, ele não está montando uma resposta a partir de correspondências textuais aproximadas: ele está atravessando conexões verificáveis fundamentado em um significado estruturado. Essa distinção é fundamental para a governança: ela permite que os agentes planejem ações de várias etapas com confiança, inferindo novos relacionamentos a partir de data confiáveis e explicando seu raciocínio por meio de caminhos auditáveis.
As ontologias tornam o conhecimento empresarial compreensível para as máquinas
A confiabilidade de um Knowledge Graph depende, em última análise, da qualidade e da confiabilidade do data que o preenche, mas a maior parte do conhecimento empresarial permanece presa em formatos não estruturadosdocumentos, e-mails, registros de bate-papo, anotações de projetos. Extrair o significado estruturado desse “dark data” é onde as ontologias se tornam ativos estratégicos.
Da linguagem compartilhada à lógica compartilhada
Uma ontologia é um modelo formal do domínio comercial: um vocabulário compartilhado de entidades (por exemplo, “Projeto”, “Fornecedor”, “Risco”) e os relacionamentos que as conectam (“entrega”, “depende de”, “causado por”). Ele codifica os principais conceitos e regras por trás dos processos de negócios. Ela pode ser usada como o projeto arquitetônico que permite a transformação da linguagem bruta em conhecimento legível por máquina, evitando a ambiguidade de conceitos (como “cliente”, “conta” ou “parceiro”) e garantindo que todos os agentes falem a mesma linguagem conceitual. Uma ontologia não é uma arquitetura congelada: é um artefato de governança vivo. À medida que os negócios evoluem, manter sua relevância torna-se parte da maturidade semântica da organização.
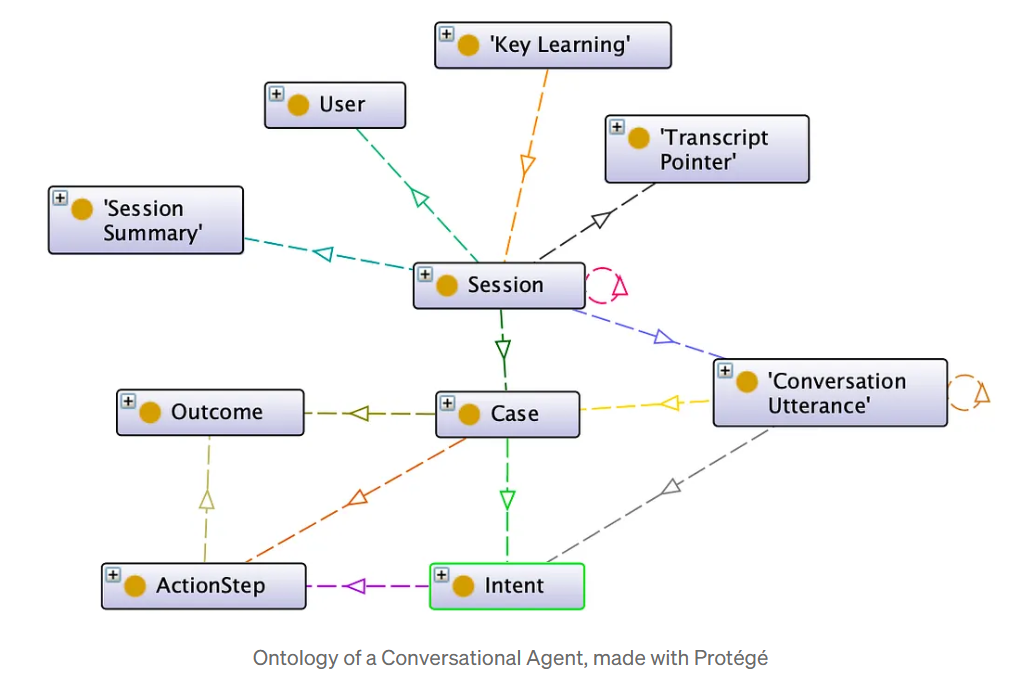
Trazendo texto não estruturado para o gráfico
Pipelines de texto para gráfico usar o processamento de linguagem natural (NLP) e a extração de entidades orientada pela ontologia para preencher automaticamente o gráfico de conhecimento. Por exemplo:
- Coleta centralizada - memória de longo prazo dos agentes: Os registros operacionais e os históricos de conversas podem ser consolidados em um gráfico compartilhado, dando aos assistentes de IA uma lembrança persistente do contexto e das decisões passadas. Isso garante a integridade e a precisão das consultas sobre ações históricas, mais confiáveis do que a recuperação probabilística de texto bruto.
- Contribuição descentralizada - possibilidade de descoberta de projetos no futuro: Um gráfico de conhecimento compartilhado pode centralizar gradualmente as informações sobre todos os projetos da empresa, enquanto as equipes de projeto contribuem diretamente anexando metadata legível por máquina aos documentos armazenados em unidades compartilhadas. Isso também os incentiva a processar as principais informações sobre seus projetos em todos os documentos, criando um índice semântico que as futuras equipes e agentes poderão explorar facilmente por meio de consultas ao gráfico.
Manter vivo o significado, a qualidade e a confiança
A validação humana continua sendo essencial em cenários de alto risco, relatórios financeiros, auditoria regulatória, mas a automação pode lidar com a maioria dos casos de baixo risco, como assistentes de conversação. As restrições da ontologia funcionam como um portão de qualidade, O senhor pode garantir que o novo data se alinhe à semântica organizacional e seja confiável para os sistemas de IA posteriores.
É claro que manter essa flexibilidade tem um custo: as ontologias devem evoluir junto com os negócios. No entanto, essa manutenção é muito mais leve do que o esforço recorrente de limpar e unir novamente tabelas diferentes. O retorno é um autoconsistente, explicável data tecido que todo agente de IA pode consultar com confiança.
Semântica: A cola de governança do Data e da malha agêntica
À medida que as organizações implementam vários agentes de IA em domínios como atendimento ao cliente, operações e P&D, a coordenação se torna o próximo desafio. Sem uma semântica compartilhada e conectada, os agentes correm o risco de duplicação, decisões inconsistentes e comportamento opaco.
É nesse ponto que a semântica e as ontologias podem se tornar a cola de governança da Data & Agentic Mesh emergente. Esse emergente ‘Data & Agentic Mesh’ amplia o princípio do Data Mesh, descentralizando não apenas a propriedade do data, mas também o raciocínio de IA em agentes interoperáveis e semanticamente conectados. Imagine cada departamento mantendo sua própria pequena rede de conhecimento, interconectada por meio de pontes ontológicas compartilhadas, uma rede semântica que cresce como um organismo vivo em vez de uma base data centralizada. Em vez de construir um único gráfico de conhecimento monolítico cuja manutenção se torna exponencialmente complexa, as organizações devem criar gráficos em várias escalas que coexistam em diferentes níveis, cada um otimizado para problemas específicos, mas alinhados por meio de semântica compartilhada. Ao armazenar tanto o metadata do produto data quanto o metadata do agente em um Enterprise Knowledge Graph compartilhado, as empresas garantem que cada ativo, seja um dataset, uma API ou um agente autônomo, seja descrito na mesma linguagem conceitual e possa interoperar perfeitamente. Enriquecido com ontologias, o Enterprise Knowledge Graph atua como um catálogo confiável Data & Agentic Catalog, conectando ontologias locais a um backbone compartilhado e alinhando os comportamentos de produtos Data e agentes sob regras consistentes e contexto compartilhado.

Em um ecossistema baseado em gráficos:
- Roteamento de intenção semântica e capacidade de descoberta: As solicitações são direcionadas ao agente, dataset ou serviço correto com base no significado e nas regras, e não em palavras-chave frágeis ou orquestração manual. As equipes e os agentes podem localizar recursos relevantes (“Qual agente monitora o desempenho do fornecedor?”) por meio da passagem pelo gráfico, em vez de recuperar o conhecimento armazenado em repositórios vetoriais.
- Rastreabilidade e auditabilidade por projeto: Cada ação do agente e dependência do data é vinculada por meio do gráfico, tornando as decisões explicáveis e as revisões de conformidade simples. A correspondência semântica e as regras também destacam quando novos agentes ou produtos data se sobrepõem aos existentes, evitando esforços redundantes e comportamentos inconsistentes antes que eles cresçam.
A semântica torna o data e os agentes interoperáveis por padrão, permitindo que os agentes de IA naveguem pela empresa com a mesma clareza que os humanos esperam dos organogramas e processos. O Enterprise Knowledge Graph torna-se o tecido conectivo que permite que os agentes não apenas acessem as informações, mas também entendam e se coordenem em torno delas.
Conclusão
A questão não é mais se os agentes de IA podem raciocinar e agir, mas sim se eles podem entender e aproveitar de forma confiável o seu “molho secreto”. À medida que as empresas adotam agentes de IA que precisam coordenar e decidir, a necessidade de um backbone confiável torna-se inegável; um que evolua com os negócios, mas que permaneça fundamentado na verdade. Os gráficos de conhecimento oferecem esse equilíbrio e um caminho prático, conectando sistemas existentes por meio de significado em vez de código. Orientados por ontologias, eles transformam o data em conhecimento durável e explicável, a base da inteligência agêntica.
Em um mundo onde a inteligência se torna uma commodity, onde LLMs e algoritmos estão amplamente disponíveis, o conhecimento estruturado, interpretável e proprietário surge como o verdadeiro ativo diferenciador. Enquanto o data descreve o que aconteceu, o conhecimento captura o porquê: o entendimento causal e relacional que dá às decisões um valor duradouro. Diferentemente da inteligência genérica, esse conhecimento codifica os processos, os relacionamentos e a experiência exclusivos da organização, que são ativos que não podem ser facilmente replicados ou comercializados. Embora as arquiteturas alternativas, como as bases vetoriais data ou os sistemas híbridos de incorporação, venham a desempenhar um papel importante, as ontologias e os gráficos de conhecimento continuam sendo uma das formas mais maduras e explicáveis que conhecemos para capturar e preservar o conhecimento em uma forma que tanto os seres humanos quanto as máquinas possam usar para raciocinar. Elas tornam a memória corporativa computável, permitindo que os agentes não apenas acessem as informações, mas também as desenvolvam, aprendam com elas e as ampliem.
O futuro da IA agêntica não dependerá apenas dos gráficos de conhecimento, mas dos princípios que eles incorporam: significado estruturado, raciocínio verificável e conhecimento legível por máquina. As empresas que investirem nessa base semântica hoje e a mantiverem por meio de uma governança eficaz não apenas implementarão sistemas mais inteligentes. Elas definirão a camada de conhecimento que molda a forma como esses sistemas pensam, raciocinam e crescem. Ao fazer isso, elas protegerão o que é verdadeiramente delas: o conhecimento que as torna únicas.
