
")




Los grafos de conocimiento convierten las tablas data en redes navegables de significado
A diferencia de las tablas SQL, que se centran en entidades y hechos aislados, los grafos de conocimiento revelan perspectivas ocultas en las relaciones
Las bases SQL data tradicionales organizan la información en tablas de entidades y hechos, unidas por claves explícitas. Este modelo es robusto para las transacciones pero frágil cuando hay que explorar la complejidad del mundo real y su red de interconexiones. En la práctica, muchas cuestiones empresariales atraviesan varios dominios: ¿Cómo se correlacionan las quejas de los clientes en los registros de servicio con los fallos de los componentes notificados en I+D? ¿Qué proyectos pasados reutilizaron la misma pila tecnológica y podrían acelerar una nueva iniciativa? Estas preguntas no se refieren a registros individuales, sino a relaciones.
Los grafos de conocimiento abordan esta carencia modelando data como una red de entidades interconectadas vinculadas a través de relaciones significativas. En lugar de reconstruir el contexto en el momento de la consulta, los grafos lo almacenan de forma nativa. Cada entidad (una persona, un producto, un documento o un proyecto) se convierte en un nodo, y sus conexiones (depende de, autoría de, suministrado a través de...) forman los bordes. Juntos crean un mapa vivo y consultable de la empresa.
Este enfoque basado en grafos sustenta algunos de los sistemas data más sofisticados del mundo. El Knowledge Graph de Google permite la búsqueda semántica conectando miles de millones de entidades y hechos. El Gráfico Económico de LinkedIn modela las relaciones profesionales globales para hacer aflorar ideas sobre habilidades y oportunidades. Los gráficos de productos y entidades de Amazon enriquecen las respuestas de Alexa, potencian las recomendaciones y mantienen un catálogo de productos coherente. El mismo principio se aplica ahora a empresas de todos los tamaños: desde bancos que rastrean la exposición al riesgo a través de instrumentos financieros hasta fabricantes que mapean las dependencias de los proveedores.
Estos sistemas demuestran cómo se compone el contexto: a medida que se conectan más entidades y relaciones, el gráfico se vuelve exponencialmente más perspicaz. Las empresas pueden ahora tejer data estructurados y no estructurados en un único tejido semántico, un mapa vivo de cómo se conecta la información.
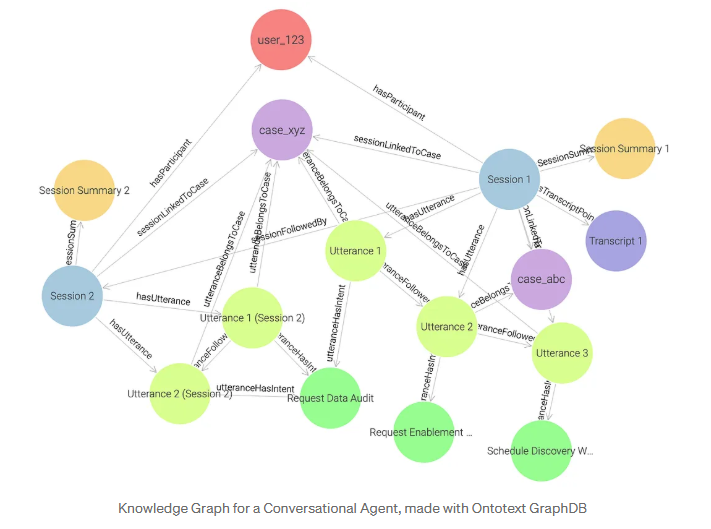
Las consultas gráficas sustituyen a las complejas uniones de tablas con un recorrido intuitivo por las relaciones que desbloquea casos de uso de gran valor
La potencia de un grafo de conocimiento se materializa cuando se consulta. En un sistema relacional, las relaciones no son inherentes; deben reconstruirse mediante JOINs complejos de varias tablas. Este proceso es lento, complejo y difícil de extender al razonamiento multi-salto. En un grafo, las relaciones están incrustadas en el data. La consulta se convierte en travesía: seguir las aristas de un nodo a otro se convierte en un acto sencillo utilizando lenguajes expresivos como Cypher o SPARQL.
Si los grafos cambian la forma en que representamos la información, las consultas de grafos cambian la forma en que razonamos con ella, permitiendo casos de uso de gran impacto que resultan engorrosos o ineficaces en los sistemas tabulares:
- Recomendaciones: Encontrar artículos similares en cuanto a sus relaciones: por ejemplo, productos adquiridos por otras personas que tengan compras históricas parecidas o documentos vinculados a temas, época, autores, etc. similares.
- Detección de fraudes y riesgos: Detecte patrones ocultos como conexiones entre cuentas, dispositivos compartidos o rutas de transacciones inusuales que son difíciles de detectar de forma aislada.
- Trazabilidad y conformidad: Siga el linaje de un componente, proveedor o decisión a través de los sistemas.
Más allá de estos ejemplos clásicos, el recorrido de grafos es especialmente adecuado para las consultas generadas por la IA. Aunque los grandes modelos lingüísticos siguen necesitando comprender el esquema subyacente para generar consultas SPARQL o Cypher, los lenguajes de consulta de grafos son mucho más compactos y expresivos que sus equivalentes SQL. Las consultas basadas en recorridos son más cortas, más coherentes desde el punto de vista semántico y más fáciles de interpretar, tanto por humanos como por LLM. Esta simplicidad reduce los errores de generación y hace de los grafos de conocimiento un sustrato más robusto para consultas automatizadas o asistidas por IA, una propiedad que se convertirá en esencial a medida que agentes autónomos empezar a interactuar directamente con la empresa data.

Notas técnicas:
- En el grafo database, la consulta SPARQL aprovecha la inferencia incorporada: el motor puede deducir automáticamente nuevas relaciones (hechos) a partir de los vínculos existentes en el modelo data. Por ejemplo, si un enunciado está conectado tanto a un caso como a una sesión, el motor puede inferir y crear automáticamente la relación derivada mem:sessionLinkedToCase, vinculando la sesión directamente al caso sin necesidad de almacenarla explícitamente.
- La expresión de recorrido SPARQL (^mem:hasParticipant/mems:sessionFollowedBy*) realiza un recorrido recursivo: sigue todas las sesiones conectadas en una secuencia a partir del usuario. Esto corresponde al CTE recursivo (WITH RECURSIVE ... UNION ALL ...) en SQL, que sigue iterativamente la cadena next_session_id para recuperar todas las sesiones pertenecientes al usuario.
- Dado que las relaciones son aristas nativas en un grafo, SPARQL expresa la misma lógica con muchas menos uniones. El patrón ?session mem:sessionLinkedToCase data:case_xyz captura directamente lo que SQL debe reconstruir a través de múltiples uniones de tablas (enunciados JOIN, casos JOIN), mostrando cómo la travesía sustituye la complejidad relacional por la simplicidad semántica.
Los grafos de conocimiento dan a la IA agéntica tanto flexibilidad como fundamento
Los sistemas de IA agéntica no sólo predecirán o clasificarán, sino que razonarán, planificarán y actuarán dentro de los procesos empresariales. Estos sistemas agénticos tomarán decisiones de forma autónoma, orquestarán flujos de trabajo y se comunicarán con humanos y otros agentes. Pero la autonomía sin base conlleva riesgos: un agente que actúe basándose en inferencias no verificadas o en un contexto mal interpretado puede producir resultados perjudiciales. Aquí es donde los grafos de conocimiento proporcionan el equilibrio adecuado entre data flexibilidad de modelado y conexión a tierra fiable.
Flexibilidad para razonamientos complejos y dinámicos
Las tablas tradicionales ofrecen precisión pero poca adaptabilidad. Cualquier cambio de esquema se propaga por todo el sistema. Los grafos de conocimiento, en cambio, proporcionan una modelo semánticamente flexible donde pueden introducirse nuevos tipos de entidades o relaciones de forma incremental, sin romper las estructuras existentes. Esto los hace especialmente adecuados para los sistemas agénticos que deben integrar información heterogénea y volátil, y actualizar su comprensión continuamente.
Esta flexibilidad también se extiende a la fusión de texto estructurado data y no estructurado. Por ejemplo, un grafo puede enlazar un nodo de contrato (con atributos como contract_id) con segmentos de texto no estructurado y sus incrustaciones. A continuación, estos nodos de texto se conectan a conceptos semánticos de nivel superior o a clasificaciones de documentos. En esta arquitectura, un agente puede realizar la recuperación (“encontrar contratos relacionados con el tema X y recuperar sus segmentos de texto relevantes”) mediante consultas deterministas al grafo en lugar de depender de canalizaciones RAG ad hoc. El camino inverso también es posible: un agente puede enriquecer los trozos recuperados mediante una búsqueda de similitud vectorial desde un almacén de vectores utilizando el grafo de conocimiento. El resultado es una recuperación más fiable y explicable que combina la estructura simbólica con la semántica vectorial en un modelo único y coherente.
Basar la autonomía en una verdad verificable
Los grafos de conocimiento proporcionan la columna vertebral semántica que los sistemas agénticos necesitan para actuar con confianza. Codifican relaciones explícitas y curadas que pueden ser consultado de forma determinista, produciendo siempre la misma respuesta, bajo una lógica bien definida. Esto contrasta con Generación mejorada por recuperación (RAG), donde las respuestas dependen de la clasificación probabilística y la generación de texto. Aunque el GAR sigue siendo valioso para la exploración abierta, no se garantiza que sus resultados sean exhaustivos y son difíciles de verificar. Un grafo de conocimiento, por el contrario, ofrece retirada completa dentro de su ámbito y procedencia transparente para cada resultado.
Cuando un agente opera sobre un grafo de conocimiento, no está ensamblando una respuesta a partir de coincidencias textuales aproximadas: está atravesando conexiones verificables basados en un significado estructurado. Esta distinción es fundamental para la gobernanza: permite a los agentes planificar acciones de varios pasos con confianza, inferir nuevas relaciones a partir de data de confianza y explicar su razonamiento a través de vías auditables.
Las ontologías hacen que el conocimiento empresarial sea comprensible para las máquinas
La fiabilidad de un grafo de conocimiento depende en última instancia de la calidad y fiabilidad del data que lo puebla, pero la mayor parte del conocimiento empresarial permanece atrapado en formatos no estructurados: documentos, correos electrónicos, registros de chat, notas de proyectos. Extraer un significado estructurado de esta “oscuridad data” es donde las ontologías se convierten en activos estratégicos.
Del lenguaje compartido a la lógica compartida
Una ontología es un modelo formal del dominio empresarial: un vocabulario compartido de entidades (por ejemplo, “Proyecto”, “Proveedor”, “Riesgo”) y las relaciones que las conectan (“entrega”, “depende de”, “causado por”). Codifica los conceptos centrales y las reglas que subyacen a los procesos empresariales. Puede utilizarse como el plano arquitectónico que permite transformar el lenguaje bruto en conocimiento legible por máquinas, evitando la ambigüedad en los conceptos (como “cliente”, “cuenta” o “socio”) y garantizando que todos los agentes hablen el mismo lenguaje conceptual. Una ontología no es una arquitectura congelada: es un artefacto de gobernanza vivo. A medida que el negocio evoluciona, mantener su relevancia se convierte en parte de la madurez semántica de la organización.
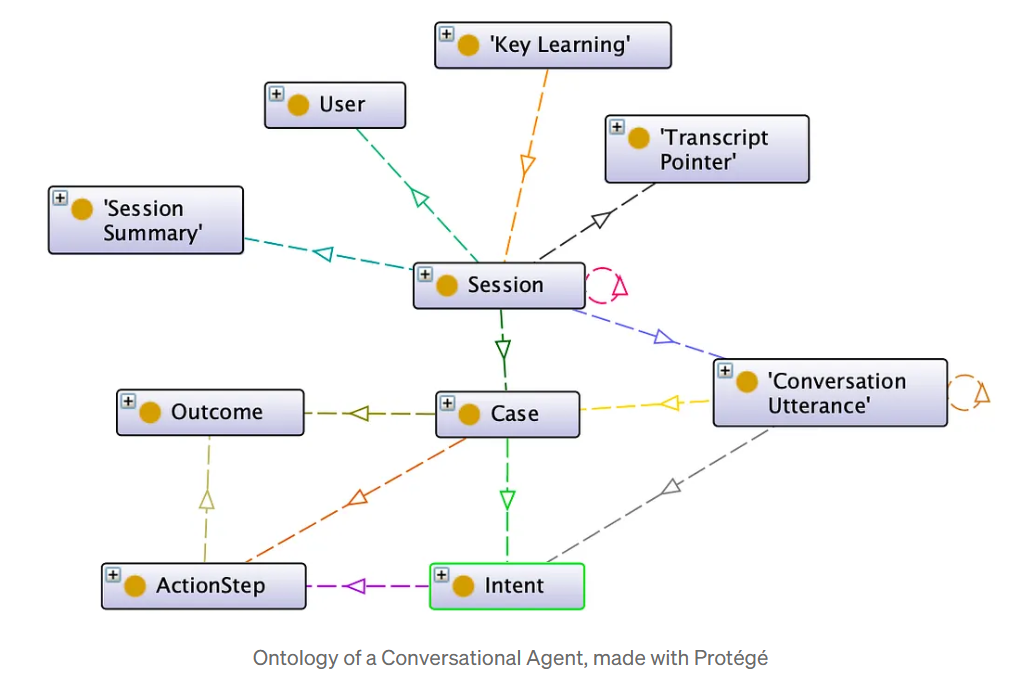
Introducir texto no estructurado en el gráfico
Canalizaciones de texto a gráficos utilizar el Procesamiento del Lenguaje Natural (PLN) y la extracción de entidades guiada por la ontología para poblar automáticamente el Grafo de Conocimientos. Por ejemplo:
- Recogida centralizada - memoria a largo plazo de los agentes: Los registros de operaciones y los historiales de conversaciones pueden consolidarse en un gráfico compartido, lo que proporciona a los asistentes de IA un recuerdo persistente del contexto y las decisiones pasadas. Esto garantiza la exhaustividad y la precisión en las consultas sobre acciones históricas, más fiables que la recuperación probabilística sobre texto sin procesar.
- Contribución descentralizada: futura descubribilidad de los proyectos: Un grafo de conocimiento compartido puede centralizar gradualmente la información sobre todos los proyectos de la empresa, mientras que los equipos de proyecto contribuyen directamente adjuntando metadata legibles por máquina a los documentos almacenados en unidades compartidas. Esto también les anima a procesar la información clave sobre sus proyectos a través de los documentos, construyendo un índice semántico que los futuros equipos y agentes puedan explorar fácilmente mediante consultas al grafo.
Mantener vivos el significado, la calidad y la confianza
La validación humana sigue siendo esencial en escenarios de alto riesgo, informes financieros, auditoría reglamentaria, pero la automatización puede ocuparse de la mayoría de los casos de bajo riesgo, como los asistentes conversacionales. Las restricciones de la ontología actúan como un puerta de calidad, garantizando que el nuevo data se ajusta a la semántica de la organización y que los sistemas de IA posteriores pueden confiar en él.
Por supuesto, mantener esta flexibilidad tiene un coste: las ontologías deben evolucionar junto con el negocio. Sin embargo, este mantenimiento es mucho más ligero que el esfuerzo recurrente de limpiar y volver a unir tablas dispares. El retorno es un tejido autoconsistente y explicable data que todo agente de la IA pueda consultar con confianza.
La semántica: El pegamento de la gobernanza del Data y la malla agenética
A medida que las organizaciones despliegan múltiples agentes de IA en ámbitos como el servicio al cliente, las operaciones y la I+D, la coordinación se convierte en el siguiente reto. Sin una semántica compartida y conectada, los agentes corren el riesgo de duplicarse, tomar decisiones incoherentes y tener un comportamiento opaco.
Aquí es donde la semántica y las ontologías pueden convertirse en el pegamento de gobernanza de la emergente malla Data y Agentic. Este emergente ‘Data & Agentic Mesh’ amplía el principio del Data Mesh, descentralizando no sólo la propiedad del data, sino también el razonamiento de la IA a través de agentes interoperables y conectados semánticamente. Imagine que cada departamento mantiene su propia pequeña red de conocimientos, interconectada a través de puentes ontológicos compartidos, una red semántica que crece como un organismo vivo en lugar de una database centralizada. En lugar de construir un único grafo de conocimiento monolítico cuyo mantenimiento se vuelve exponencialmente complejo, las organizaciones deberían crear grafos multiescala que coexistan a distintos niveles, cada uno optimizado para problemas específicos pero alineados a través de una semántica compartida. Al almacenar tanto la metadata del producto como la metadata del agente en un grafo de conocimiento empresarial compartido, las empresas se aseguran de que cada activo, ya sea un dataset, una API o un agente autónomo, esté descrito en el mismo lenguaje conceptual y pueda interoperar sin problemas. Enriquecido con ontologías, el Grafo de Conocimiento Empresarial actúa como un Catálogo Data y Agenético fiable, conectando las ontologías locales a una columna vertebral compartida, y alineando los productos Data y los comportamientos de los agentes bajo reglas coherentes y un contexto compartido.

En un ecosistema basado en grafos:
- Enrutamiento y descubribilidad de la intención semántica: Las solicitudes se dirigen al agente, dataset o servicio adecuado en función del significado y las reglas, no de frágiles palabras clave u orquestación manual. Los equipos y los agentes pueden localizar las capacidades relevantes (“¿Qué agente supervisa el rendimiento de los proveedores?”) mediante el recorrido del gráfico en lugar de recuperar los conocimientos almacenados en almacenes vectoriales.
- Trazabilidad y auditabilidad por diseño: Cada acción de los agentes y cada dependencia del data está vinculada a través del gráfico, lo que hace que las decisiones sean explicables y las revisiones de cumplimiento, sencillas. La concordancia semántica y las reglas también ponen de relieve cuándo los nuevos agentes o productos data se solapan con los ya existentes, evitando esfuerzos redundantes y comportamientos incoherentes antes de que crezcan.
La semántica hace que data y los agentes sean interoperables por defecto, lo que permite a los agentes de IA navegar por la empresa con la misma claridad que los humanos esperan de los organigramas y los procesos. El grafo de conocimiento de la empresa se convierte en el tejido conectivo que permite a los agentes no sólo acceder a la información, sino comprenderla y coordinarse en torno a ella.
Conclusión
La cuestión ya no es si los agentes de IA pueden razonar y actuar, sino si pueden comprender y aprovechar de forma fiable su “salsa secreta”. A medida que las empresas adoptan agentes de IA que deben coordinarse y decidir, la necesidad de una columna vertebral fiable se hace innegable; una que evolucione con el negocio pero que siga basada en la verdad. Los grafos de conocimiento ofrecen ese equilibrio y un camino práctico, conectando los sistemas existentes a través del significado en lugar del código. Guiados por ontologías, convierten el data en conocimiento duradero y explicable, la base de la inteligencia agéntica.
En un mundo en el que la inteligencia se convierte en una mercancía, en el que los LLM y los algoritmos están ampliamente disponibles, el conocimiento estructurado, interpretable y propio emerge como el verdadero activo diferenciador. Mientras que el data describe lo que ha ocurrido, el conocimiento capta el porqué: la comprensión causal y relacional que confiere a las decisiones un valor duradero. A diferencia de la inteligencia genérica, este conocimiento codifica los procesos, las relaciones y la experiencia únicos de la organización, que son activos que no pueden reproducirse ni comercializarse fácilmente. Aunque las arquitecturas alternativas, como las bases vectoriales data o los sistemas de incrustación híbridos, desempeñarán un papel, las ontologías y los grafos de conocimiento siguen estando entre las formas más maduras y explicables que conocemos para capturar y preservar el conocimiento en una forma sobre la que tanto los humanos como las máquinas puedan razonar. Hacen que la memoria corporativa sea computable, permitiendo a los agentes no sólo acceder a la información, sino construir sobre ella, aprender de ella y ampliarla.
El futuro de la IA agéntica no dependerá sólo de los grafos de conocimiento, sino de los principios que encarnan: significado estructurado, razonamiento verificable y conocimiento legible por máquina. Las empresas que inviertan hoy en esta base semántica y la mantengan mediante una gobernanza eficaz no sólo desplegarán sistemas más inteligentes. Definirán la capa de conocimiento que da forma a cómo piensan, razonan y crecen esos sistemas. Al hacerlo, protegerán lo que es verdaderamente suyo: el conocimiento que las hace únicas.
