
")




Les graphes de connaissance transforment les tableaux data en réseaux de sens navigables.
Contrairement aux tables SQL, qui se concentrent sur des entités et des faits isolés, les graphes de connaissances révèlent des informations cachées dans les relations.
Les bases SQL data traditionnelles organisent l'information en tables d'entités et de faits, reliées par des clés explicites. Ce modèle est robuste pour les transactions mais fragile lorsqu'il s'agit d'explorer la complexité du monde réel et son réseau d'interconnexions. Dans la pratique, de nombreuses questions commerciales recoupent plusieurs domaines : Quelle est la corrélation entre les réclamations des clients dans les journaux de service et les défaillances de composants signalées par la R&D ? Quels sont les projets antérieurs qui ont réutilisé la même pile technologique et qui pourraient accélérer une nouvelle initiative ? Ces questions ne portent pas sur des dossiers individuels, mais sur des relations.
Les graphes de connaissances comblent cette lacune en modélisant data comme un réseau d'entités interconnectées et liées par des relations significatives. Au lieu de reconstruire le contexte au moment de la requête, les graphes le stockent de manière native. Chaque entité (une personne, un produit, un document ou un projet) devient un nœud, et ses connexions (dépend de, auteur de, fourni par...) forment les bords. Ensemble, ils créent une carte vivante et interrogeable de l'entreprise.
Cette approche basée sur les graphes est à la base de certains des systèmes data les plus sophistiqués au monde. Le Knowledge Graph de Google permet une recherche sémantique en connectant des milliards d'entités et de faits. Le graphe économique de LinkedIn modélise les relations professionnelles mondiales pour faire apparaître des informations sur les compétences et les opportunités. Les graphes de produits et d'entités d'Amazon enrichissent les réponses d'Alexa, alimentent les recommandations et maintiennent un catalogue de produits cohérent. Le même principe s'applique désormais aux entreprises de toutes tailles : des banques qui tracent l'exposition au risque à travers les instruments financiers aux fabricants qui cartographient les dépendances des fournisseurs.
Ces systèmes démontrent comment le contexte se compose : à mesure que davantage d'entités et de relations se connectent, le graphe devient exponentiellement plus perspicace. Les entreprises peuvent désormais tisser des data structurées et non structurées en un seul tissu sémantique, une carte vivante de la façon dont les informations sont connectées.
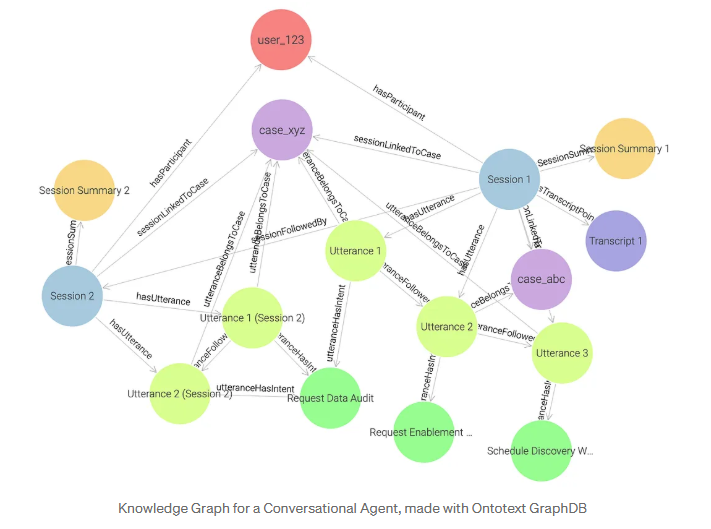
Les requêtes graphiques remplacent les jointures de tableaux complexes par une exploration intuitive des relations, ce qui permet de débloquer des cas d'utilisation à forte valeur ajoutée.
La puissance d'un graphe de connaissances se concrétise lorsqu'il est interrogé. Dans un système relationnel, les relations ne sont pas inhérentes ; elles doivent être reconstruites au moyen de jointures complexes entre plusieurs tables. Ce processus est lent, complexe et difficile à étendre au raisonnement multi-sauts. Dans un graphe, les relations sont intégrées dans le data. L'interrogation devient une traversée : suivre les arêtes d'un nœud à l'autre devient un acte simple à l'aide de langages expressifs tels que Cypher ou SPARQL.
Si les graphes modifient la façon dont nous représentons l'information, les requêtes de graphes modifient la façon dont nous raisonnons avec elle, permettant des cas d'utilisation à fort impact qui sont encombrants ou inefficaces dans les systèmes tabulaires :
- Recommandations : Trouver des éléments similaires en fonction de leurs relations : par exemple, des produits achetés par d'autres personnes qui ont des achats historiques similaires ou des documents liés à des sujets, des périodes, des auteurs, etc. similaires.
- Fraude et détection des risques : Détectez les schémas cachés tels que les connexions entre les comptes, les appareils partagés ou les chemins de transaction inhabituels qui sont difficiles à repérer de manière isolée.
- Traçabilité et conformité : Suivez l'évolution d'un composant, d'un fournisseur ou d'une décision dans les différents systèmes.
Au-delà de ces exemples classiques, la traversée de graphes est particulièrement bien adaptée aux requêtes générées par l'intelligence artificielle. Alors que les grands modèles de langage doivent encore comprendre le schéma sous-jacent pour générer des requêtes SPARQL ou Cypher, les langages d'interrogation de graphes sont beaucoup plus compacts et expressifs que leurs équivalents SQL. Les requêtes basées sur le parcours sont plus courtes, plus cohérentes sur le plan sémantique et plus faciles à interpréter, à la fois par les humains et par les LLM. Cette simplicité réduit les erreurs de génération et fait des graphes de connaissances un substrat plus robuste pour les systèmes d'information. l'interrogation automatisée ou assistée par l'IA, une propriété qui deviendra essentielle au fur et à mesure que les agents autonomes commence à interagir directement avec l'entreprise data.

Notes techniques :
- Dans le graphe database, la requête SPARQL tire parti de l'inférence intégrée : le moteur peut automatiquement déduire de nouvelles relations (faits) à partir des liens existants dans le modèle data. Par exemple, si un énoncé est lié à la fois à un cas et à une session, le moteur peut déduire et créer automatiquement la relation dérivée mem:sessionLinkedToCase, liant directement la session au cas sans qu'il soit nécessaire de la stocker explicitement.
- L'expression de chemin SPARQL (^mem:hasParticipant/mems:sessionFollowedBy*) effectue un parcours récursif : elle suit toutes les sessions connectées dans une séquence à partir de l'utilisateur. Cela correspond à l'ETC récursif (WITH RECURSIVE ... UNION ALL ...) en SQL, qui suit itérativement la chaîne next_session_id pour récupérer toutes les sessions appartenant à l'utilisateur.
- Les relations étant des arêtes natives dans un graphe, SPARQL exprime la même logique avec beaucoup moins de jointures. Le motif ?session mem:sessionLinkedToCase data:case_xyz capture directement ce que SQL doit reconstruire à travers de multiples jointures de tables (JOIN utterances, JOIN cases), montrant comment la traversée remplace la complexité relationnelle par la simplicité sémantique.
Les graphes de connaissances confèrent à l'IA agentique à la fois flexibilité et ancrage
Les systèmes d'IA agentique ne se contenteront pas de prédire ou de classer, mais raisonneront, planifieront et agiront dans le cadre des processus d'entreprise. Ces systèmes agentiques prendront des décisions de manière autonome, orchestreront des flux de travail et communiqueront avec des humains et d'autres agents. Mais l'autonomie sans fondement comporte des risques : un agent qui agit sur la base d'inférences non vérifiées ou d'un contexte mal interprété peut produire des résultats néfastes. C'est là que les graphes de connaissances offrent le bon compromis entre data flexibilité de la modélisation et mise à la terre fiable.
Flexibilité pour un raisonnement complexe et dynamique
Les tables traditionnelles offrent de la précision mais peu d'adaptabilité. Toute modification du schéma se répercute sur l'ensemble du système. Les graphes de connaissances, quant à eux, offrent une modèle sémantiquement flexible où de nouveaux types d'entités ou de relations peuvent être introduits de manière incrémentale, sans briser les structures existantes. Ils sont donc particulièrement adaptés aux systèmes agentiques qui doivent intégrer des informations hétérogènes et volatiles, et mettre à jour leur compréhension en permanence.
Cette flexibilité s'étend également à la fusion de textes structurés data et non structurés. Par exemple, un graphe peut relier un nœud de contrat (avec des attributs tels que contract_id) à des segments de texte non structurés et à leurs enchâssements. Ces nœuds de texte sont ensuite reliés à des concepts sémantiques de plus haut niveau ou à des classifications de documents. Dans cette architecture, un agent peut effectuer des recherches (“trouver des contrats liés au sujet X et extraire leurs segments de texte pertinents”) par le biais de requêtes déterministes sur les graphes plutôt que de s'appuyer sur des pipelines RAG ad hoc. L'inverse est également possible : un agent peut enrichir les morceaux récupérés via une recherche de similarité vectorielle à partir d'un entrepôt de vecteurs en utilisant le graphe de connaissances. Le résultat est une recherche plus fiable et explicable qui combine la structure symbolique et la sémantique des vecteurs dans un modèle unique et cohérent.
Fonder l'autonomie sur une vérité vérifiable
Les graphes de connaissances fournissent le épine dorsale sémantique dont les systèmes agentiques ont besoin pour agir en toute confiance. Ils codent des relations explicites, traitées, qui peuvent être interrogé de manière déterministe, Le système d'évaluation de la qualité de l'eau, qui produit la même réponse à chaque fois, selon une logique bien définie, est un système d'évaluation de la qualité de l'eau. Cela s'oppose à Génération améliorée par récupération (RAG), où les réponses dépendent d'un classement probabiliste et de la génération d'un texte. Si le RAG reste utile pour l'exploration ouverte, ses résultats ne sont pas garantis comme étant exhaustifs et sont difficiles à vérifier. Un graphe de connaissances, en revanche, offre les avantages suivants rappel complet dans le cadre de son champ d'application et une provenance transparente pour chaque résultat.
Lorsqu'un agent travaille sur un graphe de connaissances, il n'assemble pas une réponse à partir de correspondances textuelles approximatives. traversant des connexions vérifiables fondées sur une signification structurée. Cette distinction est essentielle pour la gouvernance : elle permet aux agents de planifier en toute confiance des actions à plusieurs étapes, de déduire de nouvelles relations à partir de data fiables et d'expliquer leur raisonnement par des voies vérifiables.
Les ontologies rendent les connaissances de l'entreprise compréhensibles par les machines
La fiabilité d'un graphe de connaissances dépend en fin de compte de la qualité et de la fiabilité des data qui l'alimentent, mais la plupart des connaissances de l'entreprise restent piégées dans des data. formats non structurésLes documents, les courriels, les journaux de discussion, les notes de projet. C'est en extrayant un sens structuré de ce “dark data” que les ontologies deviennent des atouts stratégiques.
Du langage commun à la logique commune
Une ontologie est un modèle formel du domaine des affaires : un vocabulaire partagé d'entités (par exemple, “projet”, “fournisseur”, “risque”) et les relations qui les relient (“fournit”, “dépend de”, “causé par”). Il encode les concepts et les règles de base qui sous-tendent les processus d'entreprise. Elle peut être utilisée comme plan architectural permettant de transformer le langage brut en connaissances lisibles par la machine, en évitant toute ambiguïté dans les concepts (tels que “client”, “compte” ou “partenaire”) et en garantissant que chaque agent parle le même langage conceptuel. Une ontologie n'est pas une architecture figée : c'est un artefact de gouvernance vivant. À mesure que l'entreprise évolue, le maintien de sa pertinence fait partie de la maturité sémantique de l'organisation.
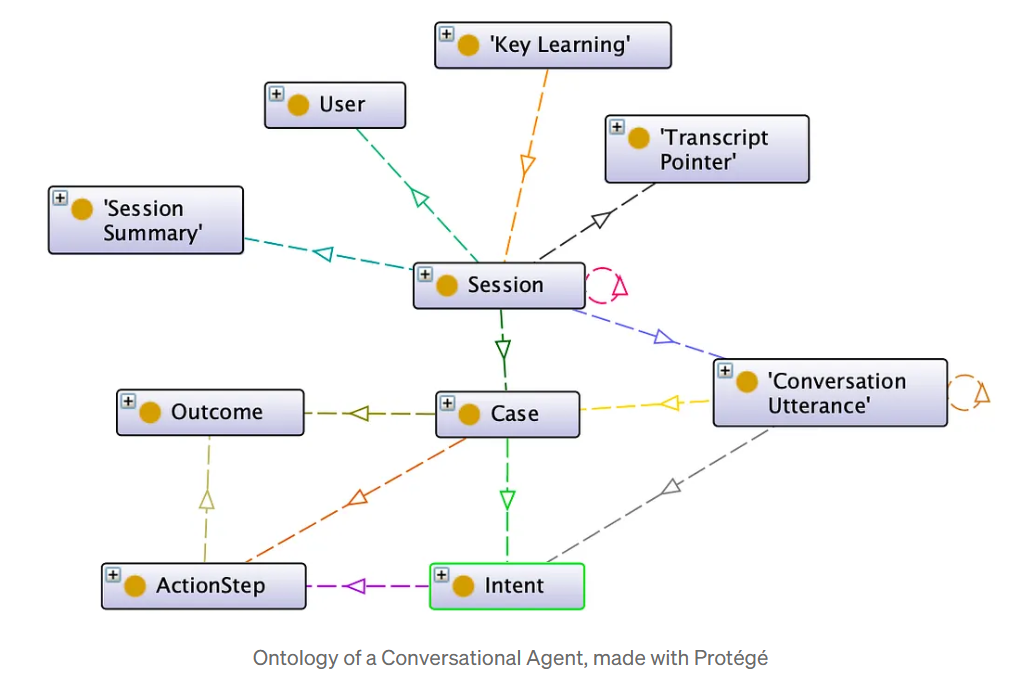
Intégrer du texte non structuré dans le graphique
Pipelines texte-graphique utiliser le traitement du langage naturel (NLP) et l'extraction d'entités guidée par l'ontologie pour remplir automatiquement le graphe de connaissances. A titre d'exemple :
- Collecte centralisée - mémoire à long terme des agents : Les journaux opérationnels et l'historique des conversations peuvent être consolidés dans un graphe partagé, ce qui permet aux assistants d'IA de se souvenir du contexte et des décisions passées. Cela garantit l'exhaustivité et la précision des requêtes sur les actions historiques, plus fiables que la recherche probabiliste sur du texte brut.
- Contribution décentralisée - découverte future des projets : Un graphe de connaissances partagé peut progressivement centraliser les informations sur tous les projets de l'entreprise, tandis que les équipes de projet contribuent directement en attachant des métadata lisibles par machine aux documents stockés dans les lecteurs partagés. Cela les encourage également à traiter les informations clés relatives à leurs projets dans l'ensemble des documents, en construisant un index sémantique que les équipes et agents futurs pourront facilement explorer par le biais de requêtes dans le graphe.
Maintenir le sens, la qualité et la confiance
La validation humaine reste essentielle dans les scénarios à fort enjeu, les rapports financiers, les audits réglementaires, mais l'automatisation peut gérer la plupart des cas à faible risque, tels que les assistants conversationnels. Les contraintes de l'ontologie agissent comme un portail de qualité, Le nouveau data s'aligne sur la sémantique de l'organisation et les systèmes d'intelligence artificielle en aval peuvent s'en servir en toute confiance.
Bien sûr, le maintien de cette flexibilité a un coût : les ontologies doivent évoluer en même temps que l'entreprise. Mais cette maintenance est bien plus légère que l'effort récurrent de nettoyage et de réassemblage de tables disparates. Le retour est un cohérent, explicable data tissu que chaque agent d'intelligence artificielle peut interroger en toute confiance.
Sémantique : La colle de gouvernance du Data et du maillage agentique
À mesure que les organisations déploient de multiples agents d'IA dans des domaines tels que le service à la clientèle, les opérations et la R&D, la coordination devient le prochain défi. Sans sémantique partagée et connectée, les agents risquent d'être dupliqués, de prendre des décisions incohérentes et d'avoir un comportement opaque.
C'est là que la sémantique et les ontologies peuvent devenir le ciment de la gouvernance du réseau Data & Agentic Mesh émergent. Ce ‘Data & Agentic Mesh’ émergent étend le principe du Data Mesh, en décentralisant non seulement la propriété du data, mais aussi le raisonnement de l'IA à travers des agents interopérables et sémantiquement connectés. Imaginez que chaque département entretienne son propre petit réseau de connaissances, interconnecté par des ponts ontologiques partagés, un réseau sémantique qui se développe comme un organisme vivant plutôt que comme une base data centralisée. Au lieu de construire un seul graphe de connaissances monolithique dont la maintenance devient exponentiellement complexe, les organisations devraient créer des graphes à plusieurs échelles qui coexistent à différents niveaux, chacun étant optimisé pour des problèmes spécifiques mais aligné grâce à une sémantique partagée. En stockant les métadata du produit data et les métadata de l'agent dans un graphe de connaissances d'entreprise partagé, les entreprises s'assurent que chaque actif, qu'il s'agisse d'un dataset, d'une API ou d'un agent autonome, est décrit dans le même langage conceptuel et peut interopérer de manière transparente. Enrichi d'ontologies, le graphe de connaissances de l'entreprise agit comme un catalogue fiable de Data et d'agents, reliant les ontologies locales à une épine dorsale partagée et alignant les produits Data et les comportements des agents sur des règles cohérentes et un contexte partagé.

Dans un écosystème basé sur les graphes :
- Routage et découverte d'intentions sémantiques : Les demandes sont dirigées vers le bon agent, dataset ou service en fonction de leur signification et de règles, et non de mots-clés fragiles ou d'une orchestration manuelle. Les équipes et les agents peuvent localiser les capacités pertinentes (“Quel agent surveille les performances des fournisseurs ?”) en parcourant le graphe plutôt qu'en récupérant des connaissances stockées dans des magasins vectoriels.
- Traçabilité et auditabilité dès la conception : Chaque action d'un agent et chaque dépendance de data sont liées dans le graphe, ce qui permet d'expliquer les décisions et de simplifier les contrôles de conformité. La correspondance sémantique et les règles mettent également en évidence les chevauchements entre les nouveaux agents ou les produits data et ceux qui existent déjà, ce qui permet d'éviter les efforts redondants et les comportements incohérents avant qu'ils ne prennent de l'ampleur.
La sémantique rend data et les agents interopérables par défaut, ce qui permet aux agents IA de naviguer dans l'entreprise avec la même clarté que celle que les humains attendent des organigrammes et des processus. Le graphe de connaissances de l'entreprise devient le tissu conjonctif qui permet aux agents non seulement d'accéder à l'information, mais aussi de la comprendre et de la coordonner.
Pour conclure
La question n'est plus de savoir si les agents d'IA peuvent raisonner et agir, mais s'ils peuvent comprendre et exploiter votre “sauce secrète” de manière fiable. À mesure que les entreprises adoptent des agents d'IA qui doivent coordonner et décider, le besoin d'une colonne vertébrale fiable devient indéniable ; une colonne vertébrale qui évolue avec l'entreprise tout en restant ancrée dans la vérité. Les graphes de connaissances offrent cet équilibre et une voie pratique, en connectant les systèmes existants par le sens plutôt que par le code. Guidés par des ontologies, ils transforment data en connaissances durables et explicables, fondement de l'intelligence agentique.
Dans un monde où l'intelligence devient une marchandise, où les LLM et les algorithmes sont largement disponibles, les connaissances structurées, interprétables et exclusives apparaissent comme le véritable atout différenciateur. Là où data décrit ce qui s'est passé, la connaissance saisit le pourquoi : la compréhension causale et relationnelle qui confère aux décisions une valeur durable. Contrairement à l'intelligence générique, cette connaissance encode les processus, les relations et l'expertise uniques de l'organisation, qui sont des actifs qui ne peuvent pas être facilement reproduits ou commercialisés. Même si d'autres architectures, telles que les bases vectorielles data ou les systèmes d'intégration hybrides, sont appelées à jouer un rôle, les ontologies et les graphes de connaissances restent parmi les moyens les plus mûrs et les plus explicables que nous connaissions pour capturer et préserver les connaissances sous une forme sur laquelle les humains et les machines peuvent raisonner. Ils rendent la mémoire d'entreprise calculable, permettant aux agents non seulement d'accéder à l'information, mais aussi de l'exploiter, d'en tirer des enseignements et de l'étendre.
L'avenir de l'IA agentique ne reposera pas uniquement sur les graphes de connaissances, mais sur les principes qu'ils incarnent : signification structurée, raisonnement vérifiable et connaissances lisibles par la machine. Les entreprises qui investissent aujourd'hui dans cette base sémantique et la maintiennent grâce à une gouvernance efficace ne se contenteront pas de déployer des systèmes plus intelligents. Elles définiront la couche de connaissances qui façonne la manière dont ces systèmes pensent, raisonnent et se développent. Ce faisant, elles protégeront ce qui leur appartient vraiment : les connaissances qui les rendent uniques.
