
")




Knowledge Graphs verwandeln data-Tabellen in navigierbare Bedeutungsnetzwerke
Im Gegensatz zu SQL-Tabellen, die sich auf isolierte Entitäten und Fakten konzentrieren, enthüllen Knowledge Graphs Erkenntnisse, die in Beziehungen verborgen sind
Traditionelle SQL data-Datenbanken organisieren Informationen in Tabellen mit Entitäten und Fakten, die durch explizite Schlüssel verbunden sind. Dieses Modell ist robust für Transaktionen, aber anfällig, wenn die Komplexität der realen Welt und ihr Netz von Verbindungen erforscht werden muss. In der Praxis sind viele geschäftliche Fragen bereichsübergreifend: Wie korrelieren die Kundenbeschwerden in den Serviceprotokollen mit den in der Forschung und Entwicklung gemeldeten Komponentenausfällen? Bei welchen früheren Projekten wurde derselbe Technologie-Stack wiederverwendet und könnte eine neue Initiative beschleunigt werden? Bei diesen Fragen geht es nicht um einzelne Datensätze, sondern um Beziehungen.
Wissensgraphen schließen diese Lücke, indem sie data als ein Netzwerk miteinander verbundener Einheiten modellieren, die durch sinnvolle Beziehungen verknüpft sind. Anstatt den Kontext bei der Abfrage zu rekonstruieren, wird er in Graphen nativ gespeichert. Jede Entität (eine Person, ein Produkt, ein Dokument oder ein Projekt) wird zu einem Knoten, und die Verbindungen (hängt ab von, verfasst von, geliefert durch...) bilden die Ränder. Zusammen bilden sie eine lebendige, abfragbare Karte des Unternehmens.
Dieser graphenbasierte Ansatz bildet die Grundlage für einige der ausgefeiltesten data-Systeme der Welt. Der Knowledge Graph von Google ermöglicht eine semantische Suche, indem er Milliarden von Entitäten und Fakten miteinander verbindet. Der Economic Graph von LinkedIn modelliert globale berufliche Beziehungen, um Erkenntnisse über Fähigkeiten und Möglichkeiten zu gewinnen. Amazons Produkt- und Entitätsgraphen bereichern die Antworten von Alexa, ermöglichen Empfehlungen und sorgen für einen kohärenten Produktkatalog. Dasselbe Prinzip lässt sich nun auf Unternehmen jeder Größe übertragen: von Banken, die das Risiko von Finanzinstrumenten nachverfolgen, bis hin zu Herstellern, die Abhängigkeiten von Zulieferern abbilden.
Diese Systeme zeigen, wie sich Kontext zusammensetzt: Je mehr Entitäten und Beziehungen miteinander verbunden werden, desto aufschlussreicher wird der Graph. Unternehmen können jetzt strukturierte und unstrukturierte data zu einem einzigen semantischen Gewebe verweben, einer lebendigen Karte, die zeigt, wie Informationen zusammenhängen.
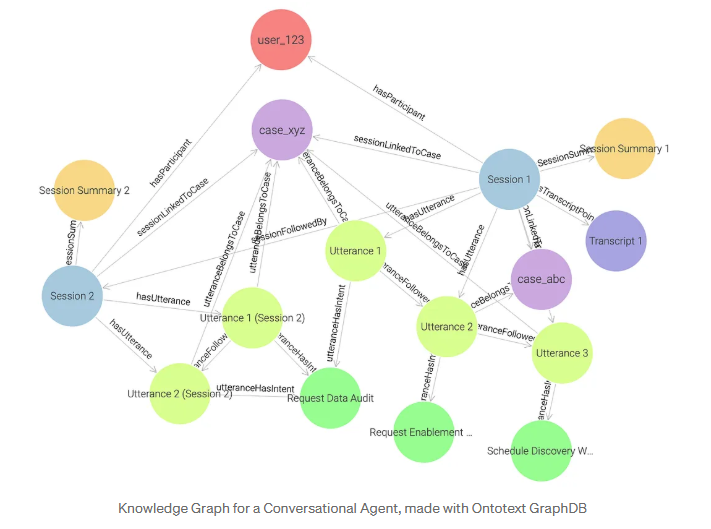
Graph-Abfragen ersetzen komplexe Tabellen-Joins durch intuitives Traversieren von Beziehungen und erschließen so hochwertige Anwendungsfälle
Die Leistungsfähigkeit eines Wissensgraphen zeigt sich, wenn er abgefragt wird. In einem relationalen System sind Beziehungen nicht inhärent. Sie müssen durch komplexe JOINs mit mehreren Tabellen rekonstruiert werden. Dieser Prozess ist langsam, komplex und lässt sich nur schwer auf Multi-Hop-Reasoning ausweiten. In einem Graphen sind die Beziehungen in die data eingebettet. Die Abfrage wird zum Traversal: Das Verfolgen von Kanten von einem Knoten zum anderen wird mit ausdrucksstarken Sprachen wie Cypher oder SPARQL zu einem einfachen Akt.
Wenn Graphen die Art und Weise verändern, wie wir Informationen darstellen, dann verändern auch Graphabfragen die Art und Weise, wie wir mit diesen Informationen umgehen, indem sie hochwirksame Anwendungsfälle ermöglichen, die in tabellarischen Systemen umständlich oder ineffizient sind:
- Empfehlungen: Finden Sie ähnliche Artikel in Bezug auf ihre Beziehungen: z.B. Produkte, die von anderen Personen gekauft wurden, die ähnliche historische Käufe haben oder Dokumente, die mit ähnlichen Themen, Zeiträumen, Autoren usw. verbunden sind.
- Aufdeckung von Betrug und Risiken: Erkennen Sie versteckte Muster wie Verbindungen zwischen Konten, gemeinsam genutzte Geräte oder ungewöhnliche Transaktionspfade, die isoliert nur schwer zu erkennen sind.
- Rückverfolgbarkeit und Konformität: Verfolgen Sie die Historie einer Komponente, eines Lieferanten oder einer Entscheidung systemübergreifend.
Abgesehen von diesen klassischen Beispielen eignet sich die Graphentraversierung besonders gut für KI-generierte Abfragen. Große Sprachmodelle müssen zwar immer noch das zugrunde liegende Schema verstehen, um SPARQL- oder Cypher-Abfragen zu generieren, Graphabfragesprachen sind viel kompakter und aussagekräftiger als ihre SQL-Entsprechungen. Traversal-basierte Abfragen sind kürzer, semantisch konsistenter und einfacher zu interpretieren, sowohl von Menschen als auch von LLMs. Diese Einfachheit reduziert Generierungsfehler und macht Knowledge Graphs zu einem robusteren Substrat für automatisierte oder KI-unterstützte Abfragen, eine Eigenschaft, die in Zukunft von entscheidender Bedeutung sein wird. autonome Agenten beginnen, direkt mit dem Unternehmen data zu interagieren.

Technische Hinweise:
- In dem Graphen database nutzt die SPARQL-Abfrage die eingebaute Inferenz: Die Engine kann automatisch neue Beziehungen (Fakten) aus den bestehenden Verbindungen im data-Modell ableiten. Wenn beispielsweise eine Äußerung sowohl mit einem Fall als auch mit einer Sitzung verknüpft ist, kann die Engine daraus die abgeleitete Beziehung mem:sessionLinkedToCase ableiten und automatisch erstellen, wodurch die Sitzung direkt mit dem Fall verknüpft wird, ohne dass sie explizit gespeichert werden muss.
- Der SPARQL-Pfadausdruck (^mem:hasParticipant/mems:sessionFollowedBy*) führt eine rekursive Traversierung durch: Er folgt allen Sitzungen, die in einer Sequenz ausgehend vom Benutzer verbunden sind. Dies entspricht der rekursiven CTE (WITH RECURSIVE ... UNION ALL ...) in SQL, die iterativ der Kette next_session_id folgt, um alle zum Benutzer gehörenden Sitzungen abzurufen.
- Da Beziehungen native Kanten in einem Graphen sind, drückt SPARQL die gleiche Logik mit viel weniger Joins aus. Das Muster ?session mem:sessionLinkedToCase data:case_xyz fängt direkt ein, was SQL durch mehrfache Tabellen-Joins (JOIN-Äußerungen, JOIN-Fälle) rekonstruieren muss, und zeigt, wie Traversal die relationale Komplexität durch semantische Einfachheit ersetzt.
Wissensgraphen verleihen der agentenbasierten KI sowohl Flexibilität als auch Bodenhaftung
Agentenbasierte KI-Systeme werden nicht nur vorhersagen oder klassifizieren, sondern innerhalb von Geschäftsprozessen denken, planen und handeln. Diese agentenbasierten Systeme werden eigenständig Entscheidungen treffen, Arbeitsabläufe orchestrieren und mit Menschen und anderen Agenten kommunizieren. Doch Autonomie ohne Grundlage birgt Risiken: Ein Agent, der auf der Grundlage von ungeprüften Schlussfolgerungen oder falsch interpretiertem Kontext handelt, kann schädliche Folgen haben. An dieser Stelle bieten Knowledge Graphs den richtigen Kompromiss zwischen data Flexibilität bei der Modellierung und zuverlässige Erdung.
Flexibilität für komplexe & dynamische Argumentation
Herkömmliche Tabellen bieten Präzision, aber wenig Anpassungsfähigkeit. Jede Schemaänderung wirkt sich auf das gesamte System aus. Wissensgraphen hingegen bieten eine semantisch flexibles Modell bei denen neue Entitätstypen oder Beziehungen schrittweise eingeführt werden können, ohne bestehende Strukturen zu zerstören. Dadurch eignen sie sich besonders gut für agentenbasierte Systeme, die heterogene und flüchtige Informationen integrieren und ihr Verständnis ständig aktualisieren müssen.
Diese Flexibilität erstreckt sich auch auf die Verschmelzung von strukturiertem data und unstrukturiertem Text. So kann ein Graph beispielsweise einen Vertragsknoten (mit Attributen wie contract_id) mit unstrukturierten Textsegmenten und deren Einbettungen verbinden. Diese Textknoten sind dann mit übergeordneten semantischen Konzepten oder Dokumentenklassifikationen verbunden. In dieser Architektur kann ein Agent die Abfrage (“Finde Verträge zum Thema X und rufe die entsprechenden Textsegmente ab”) über deterministische Graphenabfragen durchführen, anstatt sich auf Ad-hoc-RAG-Pipelines zu verlassen. Auch der umgekehrte Weg ist möglich: Ein Agent kann Chunks, die über eine Vektorähnlichkeitssuche aus einem Vektorspeicher abgerufen werden, mit dem Knowledge Graph anreichern. Das Ergebnis ist eine zuverlässigere, erklärbare Abfrage, die die symbolische Struktur mit der Vektorsemantik in einem einzigen, kohärenten Modell kombiniert.
Autonomie in überprüfbarer Wahrheit begründen
Wissensgraphen bieten die semantisches Grundgerüst die agentenbasierte Systeme benötigen, um vertrauensvoll zu handeln. Sie kodieren explizite, kuratierte Beziehungen, die deterministisch abgefragt, und liefert unter einer wohldefinierten Logik jedes Mal die gleiche Antwort. Dies steht im Gegensatz zu Retrieval-Augmented Generation (RAG), bei dem die Antworten von einer probabilistischen Einstufung und Texterstellung abhängen. RAG ist zwar für eine ergebnisoffene Erkundung wertvoll, aber seine Ergebnisse sind nicht garantiert vollständig und lassen sich nur schwer verifizieren. Ein Wissensgraph bietet im Gegensatz dazu vollständiger Rückruf innerhalb seines Geltungsbereichs und transparente Herkunft für jedes Ergebnis.
Wenn ein Agent einen Wissensgraphen bearbeitet, setzt er nicht eine Antwort aus ungefähren Textübereinstimmungen zusammen: Er ist Durchqueren von überprüfbaren Verbindungen die auf einer strukturierten Bedeutung beruhen. Diese Unterscheidung ist von entscheidender Bedeutung für die Unternehmensführung: Sie ermöglicht es den Agenten, mehrstufige Aktionen sicher zu planen, neue Beziehungen aus vertrauenswürdigen data abzuleiten und ihre Überlegungen durch überprüfbare Pfade zu erklären.
Ontologien machen Unternehmenswissen für Maschinen verständlich
Die Zuverlässigkeit eines Wissensgraphen hängt letztlich von der Qualität und Vertrauenswürdigkeit der data ab, die ihn bevölkern, doch das meiste Unternehmenswissen bleibt in unstrukturierte Formate: Dokumente, E-Mails, Chatprotokolle, Projektnotizen. Wenn Sie aus diesem “dunklen data” eine strukturierte Bedeutung extrahieren, werden Ontologien zu strategischen Assets.
Von der gemeinsamen Sprache zur gemeinsamen Logik
Eine Ontologie ist ein formales Modell des Geschäftsbereichs: ein gemeinsames Vokabular von Entitäten (z.B. “Projekt”, “Lieferant”, “Risiko”) und den Beziehungen, die sie verbinden (“liefert”, “hängt ab von”, “verursacht durch”). Es kodiert die zentralen Konzepte und Regeln hinter den Geschäftsprozessen. Sie kann als architektonische Blaupause verwendet werden, die die Umwandlung von Rohsprache in maschinenlesbares Wissen ermöglicht, wobei Mehrdeutigkeit von Konzepten (wie “Kunde”, “Konto” oder “Partner”) vermieden und sichergestellt wird, dass jeder Agent dieselbe konzeptionelle Sprache spricht. Eine Ontologie ist keine eingefrorene Architektur: Sie ist ein lebendiges Governance-Artefakt. Während sich das Unternehmen weiterentwickelt, wird die Aufrechterhaltung ihrer Relevanz Teil der semantischen Reife des Unternehmens.
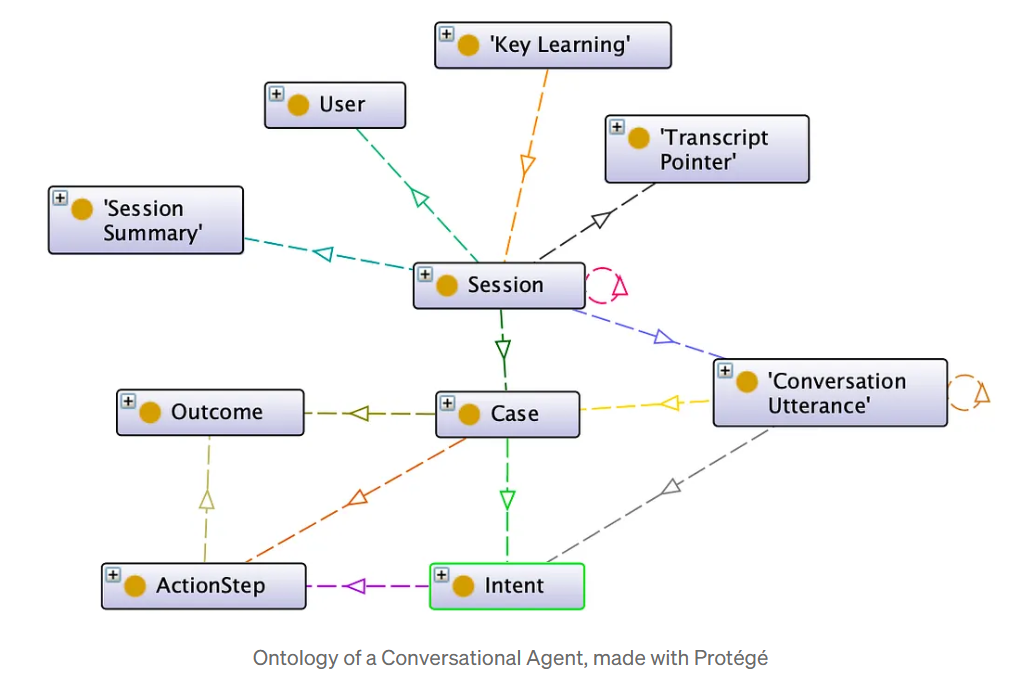
Bringen Sie unstrukturierten Text in das Diagramm
Text-zu-Grafik-Pipelines die Verarbeitung natürlicher Sprache (NLP) und die Extraktion von Entitäten anhand der Ontologie verwenden, um den Wissensgraphen automatisch aufzufüllen. Zum Beispiel:
- Zentralisierte Sammlung - Langzeitgedächtnis der Agenten: Betriebsprotokolle und Gesprächsverläufe können in einem gemeinsamen Graphen konsolidiert werden, so dass KI-Assistenten sich dauerhaft an vergangene Zusammenhänge und Entscheidungen erinnern können. Dies gewährleistet Vollständigkeit und Genauigkeit bei der Abfrage historischer Aktionen und ist zuverlässiger als eine probabilistische Abfrage über Rohtext.
- Dezentralisierte Beiträge - zukünftige Auffindbarkeit von Projekten: Ein gemeinsamer Wissensgraph kann nach und nach Informationen über alle Projekte des Unternehmens zentralisieren, während die Projektteams direkt dazu beitragen, indem sie maschinenlesbare Metadata an Dokumente anhängen, die auf gemeinsamen Laufwerken gespeichert sind. Dies ermutigt sie auch dazu, Schlüsselinformationen über ihre Projekte dokumentenübergreifend zu verarbeiten und so einen semantischen Index aufzubauen, den zukünftige Teams und Agenten durch Graphabfragen leicht erkunden können.
Bedeutung, Qualität und Vertrauen lebendig halten
Die menschliche Validierung bleibt in Szenarien, bei denen viel auf dem Spiel steht, wie z.B. bei der Finanzberichterstattung oder bei der Prüfung von Vorschriften, unverzichtbar, aber die meisten risikoarmen Fälle, wie z.B. Konversationsassistenten, können automatisiert werden. Die Einschränkungen der Ontologie wirken wie eine Qualitätstor, Dadurch wird sichergestellt, dass das neue data mit der organisatorischen Semantik übereinstimmt und von nachgelagerten KI-Systemen als vertrauenswürdig eingestuft werden kann.
Natürlich hat die Beibehaltung dieser Flexibilität ihren Preis: Ontologien müssen sich mit dem Unternehmen weiterentwickeln. Diese Wartung ist jedoch weitaus weniger aufwändig als das Bereinigen und Wiederzusammenführen unterschiedlicher Tabellen. Die Rendite ist ein selbstkonsistenter, erklärbarer data Stoff die jeder KI-Agent getrost abfragen kann.
Semantik: Der Governance-Kleber des Data & Agentic Mesh
Wenn Unternehmen mehrere KI-Agenten in Bereichen wie Kundenservice, Betrieb und F&E einsetzen, wird die Koordination zur nächsten Herausforderung. Ohne eine gemeinsame und verknüpfte Semantik riskieren die Agenten Doppelarbeit, inkonsistente Entscheidungen und undurchsichtiges Verhalten.
An dieser Stelle können Semantik und Ontologien der Governance-Kitt des entstehenden Data & Agentic Mesh werden. Dieses neu entstehende ‘Data & Agentic Mesh’ erweitert das Data Mesh-Prinzip und dezentralisiert nicht nur den Besitz von data, sondern auch die KI-Schlussfolgerungen über interoperable, semantisch verbundene Agenten. Stellen Sie sich vor, dass jede Abteilung ihr eigenes kleines Wissensnetz unterhält, das über gemeinsame ontologische Brücken miteinander verbunden ist. Ein semantisches Netzwerk, das wie ein lebender Organismus wächst und nicht wie eine zentralisierte data-Basis. Anstatt einen einzigen monolithischen Wissensgraphen zu erstellen, dessen Pflege exponentiell komplexer wird, sollten Unternehmen Graphen auf verschiedenen Ebenen erstellen, die jeweils für bestimmte Probleme optimiert und durch eine gemeinsame Semantik aufeinander abgestimmt sind. Durch die Speicherung von data-Produktmetadata und Agentenmetadata in einem gemeinsamen Enterprise Knowledge Graph stellen Unternehmen sicher, dass jedes Asset, ob ein data-Set, eine API oder ein autonomer Agent, in derselben konzeptionellen Sprache beschrieben wird und nahtlos zusammenarbeiten kann. Angereichert mit Ontologien fungiert der Enterprise Knowledge Graph als zuverlässiger Data- und Agentenkatalog, der lokale Ontologien mit einem gemeinsamen Backbone verbindet und das Verhalten von Data-Produkten und Agenten nach einheitlichen Regeln und in einem gemeinsamen Kontext abgleicht.

In einem graphbasierten Ökosystem:
- Semantisches Intent Routing und Auffindbarkeit: Anfragen werden an den richtigen Agenten, das richtige dataset oder den richtigen Service weitergeleitet, und zwar auf der Grundlage von Bedeutung und Regeln, nicht von fragilen Schlüsselwörtern oder manueller Orchestrierung. Teams und Agenten können relevante Fähigkeiten (“Welcher Agent überwacht die Leistung von Lieferanten?”) durch die Durchquerung des Graphen finden, anstatt das in Vektorspeichern gespeicherte Wissen abzurufen.
- Rückverfolgbarkeit und Auditierbarkeit durch Design: Jede Agentenaktion und jede data-Abhängigkeit ist mit dem Graphen verknüpft, so dass Entscheidungen erklärbar sind und die Überprüfung der Einhaltung der Vorschriften einfach ist. Der semantische Abgleich und die Regeln zeigen auch an, wenn sich neue Agenten oder data-Produkte mit bestehenden überschneiden. So werden überflüssiger Aufwand und inkonsistentes Verhalten verhindert, bevor sie wachsen.
Semantik macht data und Agenten standardmäßig interoperabel und ermöglicht es KI-Agenten, sich im Unternehmen mit der gleichen Klarheit zu bewegen, die Menschen von Organigrammen und Prozessen erwarten. Der Enterprise Knowledge Graph wird zum Bindeglied, das es den Agenten nicht nur ermöglicht, auf Informationen zuzugreifen, sondern diese auch zu verstehen und zu koordinieren.
Fazit
Die Frage ist nicht mehr, ob KI-Agenten denken und handeln können, sondern ob sie Ihre “geheime Soße” zuverlässig verstehen und nutzen können. Wenn Unternehmen KI-Agenten einsetzen, die koordinieren und Entscheidungen treffen müssen, ist die Notwendigkeit eines zuverlässigen Rückgrats unbestreitbar, der sich mit dem Unternehmen weiterentwickelt, aber dennoch auf der Wahrheit beruht. Knowledge Graphs bieten dieses Gleichgewicht und einen praktischen Weg, indem sie bestehende Systeme durch Bedeutung statt durch Code verbinden. Mit Hilfe von Ontologien verwandeln sie data in dauerhaftes, erklärbares Wissen, die Grundlage für agentenbasierte Intelligenz.
In einer Welt, in der Intelligenz zur Ware wird, in der LLMs und Algorithmen weithin verfügbar sind, wird strukturiertes, interpretierbares und proprietäres Wissen zum wahren Differenzierungsmerkmal. Während data beschreibt, was passiert ist, erfasst Wissen das Warum: das kausale, relationale Verständnis, das Entscheidungen einen dauerhaften Wert verleiht. Im Gegensatz zu allgemeiner Intelligenz kodiert dieses Wissen die einzigartigen Prozesse, Beziehungen und Fachkenntnisse des Unternehmens, die sich nicht so einfach replizieren oder vermarkten lassen. Auch wenn alternative Architekturen wie Vektor-data-Basen oder hybride Einbettungssysteme eine Rolle spielen werden, gehören Ontologien und Wissensgraphen nach wie vor zu den ausgereiftesten und am besten erklärbaren Methoden, die wir kennen, um Wissen in einer Form zu erfassen und zu bewahren, mit der sowohl Menschen als auch Maschinen umgehen können. Sie machen das Unternehmensgedächtnis berechenbar und ermöglichen es Agenten nicht nur, auf Informationen zuzugreifen, sondern auch darauf aufzubauen, daraus zu lernen und sie zu erweitern.
Die Zukunft der agentenbasierten KI wird sich nicht nur auf Knowledge Graphs stützen, sondern auch auf die Prinzipien, die sie verkörpern: strukturierte Bedeutung, überprüfbare Schlussfolgerungen und maschinenlesbares Wissen. Unternehmen, die heute in diese semantische Grundlage investieren und sie durch effektive Governance aufrechterhalten, werden nicht nur intelligentere Systeme einsetzen. Sie werden die Wissensschicht definieren, die bestimmt, wie diese Systeme denken, denken und wachsen. Auf diese Weise schützen sie das, was ihnen wirklich gehört: das Wissen, das sie einzigartig macht.
