



Context
ADEO has developed an extensive Knowledge Graph that encompasses its entire product catalog. Simultaneously, the company publishes a wealth of DIY articles on its website. However, these articles remain disconnected from the Knowledge Graph, preventing us from accurately identifying which products or entities within the taxonomy are referenced in the content. By linking these articles to the Knowledge Graph, ADEO could significantly elevate the user experience through smarter search capabilities, personalized recommendations, and more engaging, enriched content.
This initiative marks the latest chapter in a successful and enduring collaboration between Adeo, Google, and Artefact. Building on a foundation of shared expertise in data, retail, and cutting-edge technology, this project represents a natural evolution in our journey to innovate the digital retail landscape. The strategic alignment with Google has been instrumental in providing the tools and infrastructure necessary to tackle this ambitious endeavor.
The Cornerstone: Adeo’s Knowledge Graph & DIY Article Potential
At the heart of this project lies Adeo’s robust Knowledge Graph — a sophisticated graph database housing the company’s taxonomy — which is a structured way of classifying and categorizing information. This network of interconnected data points, currently comprising around 500,000 relations with 23,000 unique subjects, 41 predicates, and 225,000 objects, represents a wealth of information about products, categories, and their relationships. Here are simple examples of relations you might find in this knowledge graph:
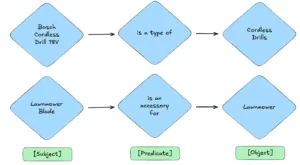
Examples of entities and relationships
However, a significant portion of valuable information resides within the numerous Do-It-Yourself (DIY) articles published on the Leroy Merlin website. These articles, rich with practical advice and instructions, often mention entities already present within Adeo’s Knowledge Graph. The challenge? There was no automated way to identify these mentions and forge the crucial links between the textual content and the structured knowledge.
Bridging this gap unlocks significant business value, especially within the context of an ongoing AI and Gen AI transformation. By automatically extracting entities from articles and other textual data and linking them in the Knowledge Graph, and thus by enriching it, we can:
- Improve Search Relevance: Enable semantic search, allowing users to find articles based on the underlying concepts rather than just keywords.
- Enhance Product Recommendations: Understand the entities discussed in an article to recommend relevant products, tools, and materials directly to the reader.
- Enrich and Personalize Content: Dynamically enrich articles with links to relevant entities in the Knowledge Graph, providing users with deeper context and related information.
Navigating the Landscape: NER & NEL with LLMs
The task at hand — identifying and linking mentions of entities within text to a predefined knowledge base — falls under the well-established domains of Named Entity Recognition (NER) and Named Entity Linking (NEL). Traditionally, high performance required training specialized models on large, labeled datasets. While powerful NER/NEL models exist, their data-intensive nature presented a challenge for our rapid deployment needs.
Therefore, we chose a different approach: leveraging the power of Large Language Models (LLMs) to build our extraction pipeline. While LLMs require little to no task-specific training data — allowing for faster implementation and iteration — they still demand annotated data for evaluation. To this end, the Adeo team built a comprehensive validation set, which required significant human effort and deep business expertise. This dataset is essential for reliably measuring the pipeline’s performance.
Our primary goal wasn’t perfect accuracy out of the gate. Instead, we focused on creating a functional pipeline to provide pre-annotated text to human labelers. This significantly accelerates the annotation process, making future fine-tuning of specialized models much more efficient.
Our Innovative Two-Stage Model
To tackle NER and NEL, we developed a robust two-stage pipeline
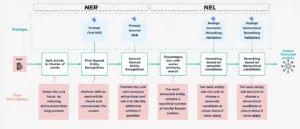
The two-tiered NER/NEL pipeline
1. Named Entity Recognition (NER): Spotting candidate entities
This stage identifies mentions of relevant entities within DIY articles using an LLM. We handle article length with Text Chunking: long articles are split into manageable chunks (500 words) for consistent LLM context and better performance. Our NER process uses a dual-level strategy:
- Local Entities: For context-specific mentions, each 500-word chunk undergoes double pass extraction for refinement ( kind of Chain of Thoughts ) using an LLM. Results from all chunks are then combined.
- Global Entities: For overarching themes, the full text is processed (again with double extraction using an LLM) for comprehensive coverage.
This two-tiered approach ensures we capture both granular details and broad concepts effectively.
2. Named Entity Linking (NEL): Connecting the Dots to the Knowledge Graph
Once entities are extracted, NEL disambiguates and links them to the most relevant Knowledge Graph entry. This involves:
🤝 Candidate Generation
For each extracted entity, we generate potential matches from the KG using a vector store and text embeddings. Only the most semantically similar candidates are kept. We used GCP text-multilingual-embedding-002 model with a vector database for this task.
To illustrate this, imagine the NER stage extracts the candidate entity “lightweight canvas gloves” from a text snippet:
“[…] you can choose lightweight canvas gloves. If you work with your hands in the soil […]”.
In the Candidate Generation step, the system retrieves potential matches from the Knowledge Graph based on semantic similarity. This might yield a ranked list of candidates such as “disposable gloves” (Rank 1), “work gloves” (Rank 2), …, “gardening gloves” (Rank 9), and “glass handling gloves” (Rank 10), among others.
🧠 Semantic Reranking
Shortlisted candidates are reranked by an LLM analyzing the entity’s context in the article. Only the top match proceeds. We found 25 candidates to be the optimal number for reranking.
Continuing our example, the LLM would now analyze the surrounding text “…If you work with your hands in the soil…” and use this context to rerank the candidates. Due to the mention of working with soil, “gardening gloves” would likely be promoted to the top of the list as the most semantically relevant candidate.
🌳 Hierarchical Ranking
The selected candidate is positioned within the KG’s hierarchy. Another LLM can either keep the selection or replace it with a more suitable parent, child, or sibling based on context. A hierarchical reranking threshold of 100 ensures the full hierarchy is considered.
Consider the following simplified hierarchy in the Knowledge Graph:

In this step, the system verifies if “gardening gloves” is the most appropriate level of specificity. While it’s a good match in our example, if the context had been broader, simply mentioning the need for hand protection without the gardening context, the hierarchical ranking might promote the ancestor entity “gloves” and link it to the corresponding KG entry.
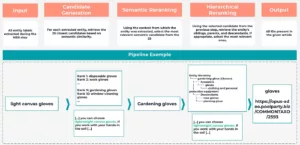
This multi-step NEL process ensures accurate and meaningful anchoring within the Knowledge Graph.
Measuring Success: Our Evaluation Methodology
To ensure the effectiveness of our Knowledge Graph enrichment pipeline for Leroy Merlin’s DIY articles, we implemented a robust evaluation against a carefully built ground truth dataset containing entities from the Adeo knowledge graph.
This evaluation specifically focuses on the pipeline’s ability to identify and link four key entity classes: ProductSet, HomeSpace, DIYActivity, and Color, at both global and local levels within the articles:
- ProductSet: These are tools, materials, or purchasable products used for home improvement, gardening, or DIY tasks. Examples: Concrete grinder, Air-to-air heat pump, Gardening apron, Desk lamp, Smart thermostat
- HomeSpace: These represent areas or rooms in a home or garden where DIY activities typically occur. Examples: Garage, Garden, Kitchen, Bathroom, Balcony
- DIYActivity: These are the tasks or operations related to Do-It-Yourself and home improvement. Examples: Painting, Installation, Cleaning, Gardening, Insulation work
- Color: This category includes any mentioned color or shade. Examples: Creamy white, Teal blue, Light grey, Matt black, Bright yellow
Evaluating the Full Pipeline (NER & NEL)
We assessed overall performance using:
- Precision: Correctly identified & linked entities / all identified & linked.
- Recall: Correctly identified & linked entities / all actual entities.
- F1 Score: A balanced measure of precision and recall.
- Fuzzy Match Metrics (distances 1, 2, 3): We score errors by their hierarchical distance from the true label: distance 1 for direct neighbors, distance 2 for the next level, etc. A wrong prediction still “passes” if it lies within the allowed radius, capturing near-misses more fairly.
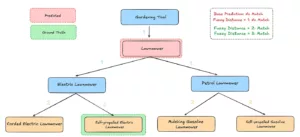
Evaluation using a Fuzzy Metric
Evaluating NER: We compared stemmed extracted entities with stemmed ground truth (case-insensitive). Our NER intentionally over-extracts for high recall.
Evaluating NEL: Assuming perfect NER, we focused on the accuracy of the linking process using the same metrics as the full pipeline, including fuzzy matching.
Key Findings: Promising Results & Growth Areas
Here are the performance metrics of our pipeline
Full Pipeline (Exact Match)
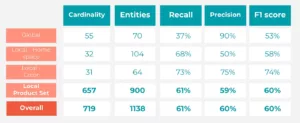
Performance metrics of the NER/NEL pipeline (Exact Match)
- Global Entities: Strong precision, lower recall (balanced F1).
- Local Entities: Varied performance. ProductSet (key category) showed a solid balance (Precision: 58.9%, Recall: 61.74%, F1: 60.29%). Color also performed well. HomeSpace needs improvement in precision.
Full Pipeline (Fuzzy Match)
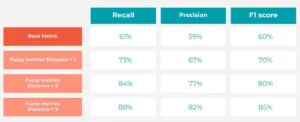
Performance using different fuzzy metrics
Fuzzy metrics improve significantly as the distance increases. This clearly shows that predictions considered incorrect in exact match are still relatively close to the actual value within the graph hierarchy.
NER:
As expected, we achieved high recall but lower precision due to our over-extraction strategy.
NEL:
The NEL component effectively refined entity linking 🔗 after NER.
Conclusion: Building a Smarter DIY Ecosystem
This project marks a significant step in using AI to enrich the DIY experience on Leroy Merlin’s website. By successfully building a pipeline to link DIY articles to Adeo’s Knowledge Graph, we’ve laid the groundwork for smarter search, personalized recommendations, and richer content.
While initial results are promising (especially for ProductSet), we’ve identified areas for optimization, like improving HomeSpace precision. Our decision to use LLMs for rapid initial annotation has been a valuable strategy, accelerating data generation for future model training and improvements.
The ongoing collaboration between Adeo, Google, and Artefact continues to drive retail innovation. This Knowledge Graph enrichment initiative showcases the power of combining domain expertise with cutting-edge AI to create a more intuitive and valuable experience for DIY enthusiasts. As our pipeline evolves with further refinements and potentially more advanced models like Gemini 2.5 Pro, the connection between content and knowledge will only strengthen, further empowering Leroy Merlin’s customers in their home improvement journeys.
