



Contexto
A ADEO desenvolveu uma extensa Gráfico de conhecimento que engloba todo o seu catálogo de produtos. Ao mesmo tempo, a empresa publica uma grande quantidade de artigos de bricolagem em seu site. No entanto, esses artigos permanecem desconectados do Knowledge Graph, o que nos impede de identificar com precisão quais produtos ou entidades da taxonomia são referenciados no conteúdo. Ao vincular esses artigos ao Knowledge Graph, a ADEO poderia elevar significativamente a experiência do usuário por meio de recursos de pesquisa mais inteligentes, recomendações personalizadas e conteúdo mais envolvente e enriquecido.
Essa iniciativa marca o mais recente capítulo de uma colaboração bem-sucedida e duradoura entre a Adeo, o Google e o Artefact. Construído sobre uma base de conhecimento compartilhado em data, varejo e tecnologia de ponta, esse projeto representa uma evolução natural em nossa jornada para inovar o cenário do varejo digital. O alinhamento estratégico com o Google tem sido fundamental para fornecer as ferramentas e a infraestrutura necessárias para enfrentar esse ambicioso empreendimento.
A pedra angular: O potencial do Knowledge Graph e do artigo DIY da Adeo
No centro desse projeto está o robusto Knowledge Graph da Adeo, uma sofisticada base gráfica que abriga a taxonomia da empresa, que é uma forma estruturada de classificar e categorizar informações. Essa rede de pontos data interconectados, atualmente composta por cerca de 500.000 relações com 23.000 assuntos exclusivos, 41 predicados, e 225.000 objetos, O gráfico de conhecimento, que representa uma grande quantidade de informações sobre produtos, categorias e seus relacionamentos. Aqui estão exemplos simples de relações que o senhor pode encontrar nesse gráfico de conhecimento:
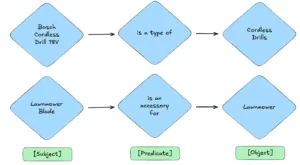
Exemplos de entidades e relacionamentos
No entanto, uma parte significativa das informações valiosas reside nos inúmeros Artigos do tipo "faça você mesmo" (DIY) publicados no site da Leroy Merlin. Esses artigos, repletos de conselhos e instruções práticas, frequentemente mencionam entidades já presentes no Knowledge Graph do Adeo. O desafio? Havia nenhuma forma automatizada para identificar essas menções e criar os vínculos essenciais entre o conteúdo textual e o conhecimento estruturado.
A superação dessa lacuna abre caminho para valor comercial, O senhor pode usar o Knowledge Graph, especialmente no contexto de uma transformação contínua da IA e da IA Gen. Ao extrair automaticamente entidades de artigos e outros data textos e vinculá-las ao Knowledge Graph e, portanto, enriquecê-lo, podemos:
- Melhorar a relevância da pesquisa: Habilitar pesquisa semântica, permitindo que os usuários encontrem artigos com base nos conceitos subjacentes e não apenas em palavras-chave.
- Aprimorar as recomendações de produtos: Compreender as entidades discutidas em um artigo para recomendar produtos, ferramentas e materiais relevantes diretamente ao leitor.
- Enriqueça e personalize o conteúdo: Enriqueça dinamicamente os artigos com links para entidades relevantes no Knowledge Graph, fornecendo aos usuários um contexto mais profundo e informações relacionadas.
Navegando pelo cenário: NER e NEL com LLMs
A tarefa em questão - identificar e vincular menções de entidades no texto a uma base de conhecimento predefinida - se enquadra nos domínios bem estabelecidos de Reconhecimento de entidades nomeadas (NER) e Ligação de entidades nomeadas (NEL). Tradicionalmente, o alto desempenho exigia o treinamento de modelos especializados em conjuntos grandes e rotulados de data. Embora existam modelos NER/NEL poderosos, sua natureza intensiva em data apresentado um desafio para nossas necessidades de implantação rápida.
Portanto, escolhemos um abordagem diferente: aproveitando o poder do Modelos de linguagem grandes (LLMs) para construir nosso pipeline de extração. Embora os LLMs exijam pouco ou nenhum treinamento específico para a tarefa data - o que permite uma implementação e iteração mais rápidas - eles ainda exigem anotado data para avaliação. Para isso, a equipe da Adeo criou um conjunto de validação, que exigiu um esforço humano significativo e profundo conhecimento comercial. Esse dataset é essencial para medir de forma confiável o desempenho do pipeline.
Nosso objetivo principal não era a precisão perfeita desde o início. Em vez disso, nos concentramos em criar um pipeline funcional para fornecer texto pré-anotado para rotuladores humanos. Isso acelera significativamente o processo de anotação, tornando o ajuste fino futuro de modelos especializados muito mais eficiente.
Nosso modelo inovador de dois estágios
Para lidar com NER e NEL, desenvolvemos um pipeline robusto de dois estágios
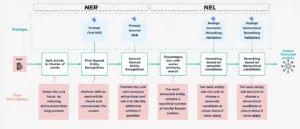
O pipeline NER/NEL de duas camadas
1. Reconhecimento de entidades nomeadas (NER): Identificar entidades candidatas
Essa etapa identifica menções de entidades relevantes em artigos de bricolagem usando um LLM. Lidamos com o comprimento do artigo com Agrupamento de texto: Os artigos longos são divididos em partes gerenciáveis (500 palavras) para um contexto LLM consistente e melhor desempenho. Nosso processo de NER usa uma estratégia de dois níveis:
- Entidades locais: Para menções específicas do contexto, cada pedaço de 500 palavras passa por uma extração de dupla passagem para refinamento (tipo de Cadeia de pensamentos ) usando um LLM. Em seguida, os resultados de todos os blocos são combinados.
- Entidades globais: Para temas abrangentes, o texto completo é processado (novamente com extração dupla usando um LLM) para obter uma cobertura abrangente.
Essa abordagem em duas camadas garante a captura eficaz de detalhes granulares e conceitos amplos.
2. Ligação de entidades nomeadas (NEL): Conectando os pontos ao gráfico de conhecimento
Depois que as entidades são extraídas, a NEL as desambigua e as vincula à entrada mais relevante do Knowledge Graph. Isso envolve:
🤝 Geração de candidatos
Para cada entidade extraída, geramos possíveis correspondências do KG usando um armazenamento de vetores e incorporação de texto. Apenas os candidatos mais semelhantes semanticamente são mantidos. Usamos o GCP texto-multilíngue-embedding-002 com um vetor database para essa tarefa.
Para ilustrar isso, imagine que o estágio NER extraia a entidade candidata “luvas de lona leves” de um trecho de texto:
“[...] o senhor pode escolher Luvas de lona leve. Se o senhor trabalhar com as mãos no solo [...]”.
Na etapa de geração de candidatos, o sistema recupera possíveis correspondências do Knowledge Graph com base na similaridade semântica. Isso pode gerar uma lista classificada de candidatos, como “luvas descartáveis” (classificação 1), “luvas de trabalho” (classificação 2), ..., “luvas de jardinagem” (classificação 9) e “luvas para manuseio de vidro” (classificação 10), entre outros.
🧠 Reranking semântico
Os candidatos pré-selecionados são ranqueados novamente por um LLM que analisa o contexto da entidade no artigo. Apenas a melhor correspondência continua. Descobrimos que 25 candidatos é o número ideal para a reclassificação.
Continuando com o nosso exemplo, o LLM agora analisaria o texto ao redor “...Se o senhor trabalha com as mãos no solo...” e usaria esse contexto para classificar os candidatos. Devido à menção do trabalho com o solo, “gardening gloves” (luvas de jardinagem) provavelmente seria promovido ao topo da lista como o candidato semanticamente mais relevante.
🌳 Classificação hierárquica
O candidato selecionado é posicionado na hierarquia do KG. Outro LLM pode manter a seleção ou substituí-la por um pai, filho ou irmão mais adequado com base no contexto. Um limite de reranking hierárquico de 100 garante que toda a hierarquia seja considerada.
Considere a seguinte hierarquia simplificada no Knowledge Graph:

Nessa etapa, o sistema verifica se “gardening gloves” (luvas de jardinagem) é o nível de especificidade mais adequado. Embora seja uma boa correspondência em nosso exemplo, se o contexto tivesse sido mais amplo, simplesmente mencionando a necessidade de proteção das mãos sem o contexto de jardinagem, a classificação hierárquica poderia promover a entidade ancestral “gloves” (luvas) e vinculá-la à entrada KG correspondente.
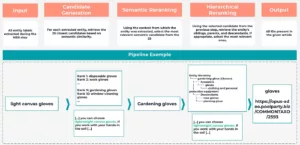
Esse processo de NEL em várias etapas garante uma ancoragem precisa e significativa no Knowledge Graph.
Medindo o sucesso: Nossa metodologia de avaliação
Para garantir a eficácia do nosso pipeline de enriquecimento do Knowledge Graph para os artigos de bricolagem da Leroy Merlin, implementamos uma avaliação robusta com base em um banco de dados cuidadosamente construído. verdade terrestre dataset contendo entidades do gráfico de conhecimento Adeo.
Essa avaliação se concentra especificamente na capacidade do pipeline de identificar e vincular quatro classes de entidades importantes: ProductSet, HomeSpace, DIYActivity e Color, tanto em nível global quanto local nos artigos:
- Conjunto de produtos: São ferramentas, materiais ou produtos compráveis usados para melhoria da casa, jardinagem ou tarefas de bricolagem. Exemplos: Moedor de concreto, Bomba de calor ar-ar, Avental de jardinagem, Lâmpada de mesa, Termostato inteligente
- HomeSpace: Eles representam áreas ou cômodos em uma casa ou jardim onde normalmente ocorrem atividades de bricolagem. Exemplos: Garagem, Jardim, Cozinha, Banheiro, Varanda
- DIYActivity: Essas são as tarefas ou operações relacionadas ao "faça você mesmo" e à melhoria da casa. Exemplos: Pintura, instalação, limpeza, jardinagem, trabalho de isolamento
- Cor: Essa categoria inclui qualquer cor ou tonalidade mencionada. Exemplos: Branco cremoso, azul-petróleo, cinza claro, preto fosco, amarelo brilhante
Avaliação do pipeline completo (NER e NEL)
Avaliamos o desempenho geral usando:
- Precisão: Entidades corretamente identificadas e vinculadas / todas identificadas e vinculadas.
- Recall: Entidades corretamente identificadas e vinculadas / todas as entidades reais.
- Pontuação da F1: Uma medida equilibrada de precisão e recuperação.
- Fuzzy Match Metrics (distâncias 1, 2, 3): Pontuamos os erros pela distância hierárquica do rótulo verdadeiro: distância 1 para vizinhos diretos, distância 2 para o próximo nível, etc. Uma previsão errada ainda “passa” se estiver dentro do raio permitido, capturando os quase erros de forma mais justa.
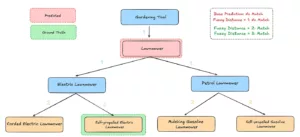
Avaliação usando uma métrica Fuzzy
Avaliação do NER: Comparamos as entidades extraídas com haste com a verdade terrestre com haste (sem distinção entre maiúsculas e minúsculas). Nosso NER extrai intencionalmente mais do que o necessário para obter uma alta recuperação.
Avaliação da NEL: Partindo do pressuposto de que o NER é perfeito, nos concentramos na precisão do processo de vinculação usando as mesmas métricas do pipeline completo, incluindo a correspondência difusa.
Principais conclusões: Resultados promissores e áreas de crescimento
Aqui estão as métricas de desempenho de nosso pipeline
Pipeline completo (correspondência exata)
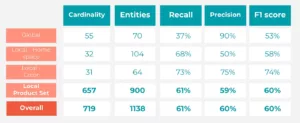
Métricas de desempenho do pipeline NER/NEL (correspondência exata)
- Entidades globais: Forte precisão, menor recuperação (F1 equilibrada).
- Entidades locais: Desempenho variado. Conjunto de produtos (categoria principal) apresentou um equilíbrio sólido (Precisão: 58,9%, Recuperação: 61,74%, F1: 60,29%). Cor também tiveram um bom desempenho. HomeSpace precisa melhorar a precisão.
Pipeline completo (Fuzzy Match)
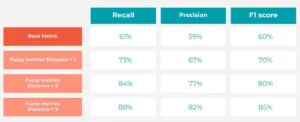
Desempenho usando diferentes métricas fuzzy
As métricas difusas melhoram significativamente à medida que a distância aumenta. Isso mostra claramente que as previsões consideradas incorretas na correspondência exata ainda estão relativamente próximas do valor real na hierarquia do gráfico.
NER:
Como esperado, alcançamos alta recordação mas com menor precisão devido à nossa estratégia de extração excessiva.
NEL:
O componente NEL efetivamente vinculação refinada de entidades 🔗 após o NER.
Conclusão: Construindo um ecossistema DIY mais inteligente
Esse projeto marca um passo significativo no uso da IA para enriquecer a experiência de bricolagem no site da Leroy Merlin. Ao criar com sucesso um pipeline para vincular artigos de bricolagem ao Knowledge Graph da Adeo, lançamos as bases para uma pesquisa mais inteligente, recomendações personalizadas e conteúdo mais rico.
Embora os resultados iniciais sejam promissores (especialmente para o ProductSet), identificamos áreas de otimização, como o aprimoramento da precisão do HomeSpace. Nossa decisão de usar LLMs para anotação inicial rápida foi uma estratégia valiosa, acelerando a geração de data para treinamento e aprimoramentos futuros do modelo.
A colaboração contínua entre Adeo, Google e Artefact continua a impulsionar a inovação no varejo. Essa iniciativa de enriquecimento do Knowledge Graph mostra o poder da combinação de conhecimento especializado com IA de ponta para criar uma experiência mais intuitiva e valiosa para os entusiastas da bricolagem. À medida que nosso pipeline evolui com mais refinamentos e modelos potencialmente mais avançados, como o Gemini 2.5 Pro, a conexão entre conteúdo e conhecimento só se fortalecerá, capacitando ainda mais os clientes da Leroy Merlin em suas jornadas de melhoria doméstica.
