



Kontext
ADEO hat ein umfangreiches Wissensgraf die den gesamten Produktkatalog des Unternehmens umfasst. Gleichzeitig veröffentlicht das Unternehmen eine Fülle von Heimwerkerartikeln auf seiner Website. Diese Artikel sind jedoch nicht mit dem Knowledge Graph verknüpft, so dass wir nicht genau erkennen können, auf welche Produkte oder Entitäten innerhalb der Taxonomie in den Inhalten Bezug genommen wird. Durch die Verknüpfung dieser Artikel mit dem Knowledge Graph könnte ADEO die Benutzererfahrung durch intelligentere Suchfunktionen, personalisierte Empfehlungen und ansprechendere, angereicherte Inhalte erheblich verbessern.
Diese Initiative ist das jüngste Kapitel in einer erfolgreichen und dauerhaften Zusammenarbeit zwischen Adeo, Google und Artefact. Aufbauend auf der gemeinsamen Expertise in den Bereichen data, Einzelhandel und Spitzentechnologie stellt dieses Projekt eine natürliche Entwicklung auf unserem Weg zur Innovation der digitalen Einzelhandelslandschaft dar. Die strategische Zusammenarbeit mit Google hat entscheidend dazu beigetragen, die Tools und die Infrastruktur bereitzustellen, die für dieses ehrgeizige Unterfangen notwendig sind.
Der Eckpfeiler: Adeo's Knowledge Graph & DIY Artikel Potential
Das Herzstück dieses Projekts ist der robuste Knowledge Graph von Adeo - ein ausgeklügeltes Diagramm database, das die Taxonomie des Unternehmens enthält - eine strukturierte Art, Informationen zu klassifizieren und zu kategorisieren. Dieses Netzwerk aus miteinander verbundenen data-Punkten, das derzeit etwa 500.000 Beziehungen mit 23.000 einzigartige Themen, 41 Prädikate, und 225.000 Objekte, stellt eine Fülle von Informationen über Produkte, Kategorien und deren Beziehungen dar. Hier sind einfache Beispiele für Beziehungen, die Sie in diesem Wissensdiagramm finden können:
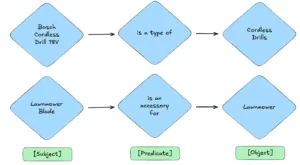
Beispiele für Entitäten und Beziehungen
Ein großer Teil der wertvollen Informationen befindet sich jedoch in den zahlreichen Do-It-Yourself (DIY) Artikel die auf der Website von Leroy Merlin veröffentlicht werden. Diese Artikel, die reich an praktischen Ratschlägen und Anleitungen sind, erwähnen oft Entitäten, die bereits im Knowledge Graph von Adeo vorhanden sind. Die Herausforderung? Es gab kein automatischer Weg um diese Erwähnungen zu identifizieren und die entscheidenden Verbindungen zwischen dem Textinhalt und dem strukturierten Wissen herzustellen.
Die Überbrückung dieser Lücke ermöglicht bedeutende Geschäftswert, insbesondere im Rahmen einer laufenden KI- und Gen-KI-Transformation. Durch die automatische Extraktion von Entitäten aus Artikeln und anderen textuellen data und deren Verknüpfung im Knowledge Graph, und somit durch dessen Anreicherung, können wir:
- Verbessern Sie die Suchrelevanz: Aktivieren Sie semantische Suche, Damit können Benutzer Artikel anhand der zugrunde liegenden Konzepte und nicht nur anhand von Schlüsselwörtern finden.
- Verbessern Sie die Produktempfehlungen: Verstehen Sie die in einem Artikel besprochenen Einheiten, um dem Leser relevante Produkte, Tools und Materialien direkt zu empfehlen.
- Inhalte anreichern und personalisieren: Reichern Sie Artikel dynamisch mit Links zu relevanten Entitäten im Knowledge Graph an und bieten Sie Benutzern so einen tieferen Kontext und verwandte Informationen.
Navigieren in der Landschaft: NER & NEL mit LLMs
Die Aufgabe, um die es hier geht - die Identifizierung und Verknüpfung von Erwähnungen von Entitäten im Text mit einer vordefinierten Wissensbasis - fällt in die gut etablierten Bereiche von Erkennung von benannten Entitäten (NER) und Verknüpfung von benannten Entitäten (NEL). Traditionell erforderte eine hohe Leistung das Training spezialisierter Modelle auf großen, beschrifteten data-Sets. Es gibt zwar leistungsstarke NER/NEL-Modelle, aber ihre data-intensive Natur präsentiert eine Herausforderung für unseren schnellen Einsatzbedarf.
Daher haben wir eine anderer Ansatz: Nutzen Sie die Macht der Große Sprachmodelle (LLMs) um unsere Extraktionspipeline aufzubauen. LLMs erfordern zwar wenig bis gar kein aufgabenspezifisches Training data - was eine schnellere Implementierung und Iteration ermöglicht -, aber sie erfordern dennoch annotiert data für die Bewertung. Zu diesem Zweck hat das Adeo-Team eine umfassende Validierungssatz, was einen erheblichen personellen Aufwand und fundiertes Fachwissen erforderte. Dieses dataset ist für die zuverlässige Messung der Leistung der Pipeline unerlässlich.
Unser primäres Ziel war nicht von Anfang an eine perfekte Genauigkeit. Stattdessen konzentrierten wir uns darauf, eine funktionale Pipeline zu erstellen, die vorkommentierter Text für menschliche Beschrifter. Dies beschleunigt den Annotationsprozess erheblich und macht die künftige Feinabstimmung von spezialisierten Modellen viel effizienter.
Unser innovatives zweistufiges Modell
Um NER und NEL zu bewältigen, haben wir eine robuste zweistufige Pipeline entwickelt
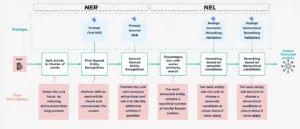
Die zweistufige NER/NEL-Pipeline
1. Erkennung von benannten Entitäten (NER): Aufspüren von Entitätskandidaten
In dieser Phase werden Erwähnungen relevanter Entitäten in DIY-Artikeln mithilfe eines LLM identifiziert. Wir behandeln die Artikellänge mit Text Chunking: lange Artikel werden in überschaubare Abschnitte (500 Wörter) aufgeteilt, um einen konsistenten LLM-Kontext und eine bessere Leistung zu erzielen. Unser NER-Prozess verwendet eine zweistufige Strategie:
- Lokale Entitäten: Bei kontextspezifischen Erwähnungen wird jedes 500-Wort-Stück in zwei Durchgängen extrahiert, um es zu verfeinern ( Art der Gedankenkette ) unter Verwendung eines LLM. Die Ergebnisse aus allen Chunks werden dann kombiniert.
- Globale Entitäten: Für übergreifende Themen wird der Volltext verarbeitet (wiederum mit doppelter Extraktion unter Verwendung eines LLM), um eine umfassende Abdeckung zu gewährleisten.
Dieser zweistufige Ansatz stellt sicher, dass wir sowohl detaillierte Details als auch umfassende Konzepte effektiv erfassen.
2. Named Entity Linking (NEL): Die Punkte mit dem Wissensgraphen verbinden
Sobald die Entitäten extrahiert sind, disambiguiert und verknüpft NEL sie mit dem relevantesten Knowledge Graph-Eintrag. Dies beinhaltet:
🤝 Kandidat Generation
Für jede extrahierte Entität generieren wir mithilfe eines Vektorspeichers und Texteinbettungen potenzielle Übereinstimmungen aus der KG. Nur die semantisch ähnlichsten Kandidaten werden beibehalten. Wir verwenden GCP text-multilingual-embedding-002 Modell mit einem Vektor database für diese Aufgabe.
Um dies zu veranschaulichen, stellen Sie sich vor, die NER-Stufe extrahiert die Kandidatenentität “leichte Leinwandhandschuhe” aus einem Textausschnitt:
“[...] Sie können wählen leichte Canvas-Handschuhe. Wenn Sie mit Ihren Händen in der Erde arbeiten [...]”.
Im Schritt Kandidatengenerierung ruft das System auf der Grundlage der semantischen Ähnlichkeit potenzielle Übereinstimmungen aus dem Knowledge Graph ab. Dies könnte eine Rangliste von Kandidaten ergeben, wie z.B. “Einweghandschuhe” (Rang 1), “Arbeitshandschuhe” (Rang 2), ..., “Gartenhandschuhe” (Rang 9) und “Handschuhe für den Umgang mit Glas” (Rang 10), unter anderem.
🧠 Semantisches Reranking
Die in die engere Wahl gezogenen Kandidaten werden von einem LLM, der den Kontext der Entität in dem Artikel analysiert, neu bewertet. Nur die beste Übereinstimmung wird weiterverfolgt. Wir haben festgestellt, dass 25 Kandidaten die optimale Anzahl für das Reranking sind.
Um unser Beispiel fortzusetzen, würde der LLM nun den umgebenden Text “...Wenn Sie mit den Händen in der Erde arbeiten...” analysieren und diesen Kontext nutzen, um die Kandidaten neu zu ordnen. Aufgrund der Erwähnung der Arbeit mit Erde würde “Gartenhandschuhe” wahrscheinlich als der semantisch relevanteste Kandidat an die Spitze der Liste befördert werden.
🌳 Hierarchisches Ranking
Der ausgewählte Kandidat wird innerhalb der Hierarchie der KG positioniert. Ein anderer LLM kann die Auswahl entweder beibehalten oder durch ein geeigneteres Elternteil, Kind oder Geschwisterteil ersetzen, je nach Kontext. Ein Schwellenwert von 100 für hierarchisches Reranking stellt sicher, dass die gesamte Hierarchie berücksichtigt wird.
Betrachten Sie die folgende vereinfachte Hierarchie im Knowledge Graph:

In diesem Schritt prüft das System, ob “Gartenhandschuhe” die am besten geeignete Spezifitätsebene ist. In unserem Beispiel ist dies eine gute Übereinstimmung. Wäre der Kontext jedoch breiter gefasst und würde lediglich die Notwendigkeit eines Handschutzes ohne den Kontext der Gartenarbeit erwähnt, könnte das hierarchische Ranking die Vorgängerentität “Handschuhe” aufwerten und sie mit dem entsprechenden KG-Eintrag verknüpfen.
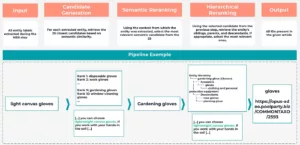
Dieser mehrstufige NEL-Prozess gewährleistet eine genaue und sinnvolle Verankerung im Knowledge Graph.
Erfolg messen: Unsere Bewertungsmethodik
Um die Effektivität unserer Knowledge Graph-Anreicherungspipeline für die Heimwerkerartikel von Leroy Merlin sicherzustellen, haben wir eine robuste Bewertung anhand einer sorgfältig erstellten Bodenwahrheit dataset mit Entitäten aus dem Adeo-Wissensgraphen.
Diese Bewertung konzentriert sich insbesondere auf die Fähigkeit der Pipeline, vier wichtige Entitätsklassen zu identifizieren und zu verknüpfen: ProductSet, HomeSpace, DIYActivity und Color, sowohl auf globaler als auch auf lokaler Ebene innerhalb der Artikel:
- ProduktSet: Dies sind Werkzeuge, Materialien oder käufliche Produkte, die für Heimwerker-, Garten- oder Heimwerkerarbeiten verwendet werden. Beispiele: Betonschleifer, Luft-Luft-Wärmepumpe, Gartenschürze, Schreibtischlampe, Smart Thermostat
- HomeSpace: Dies sind Bereiche oder Räume in einem Haus oder Garten, in denen typischerweise Heimwerkeraktivitäten stattfinden. Beispiele: Garage, Garten, Küche, Badezimmer, Balkon
- DIYActivity: Dies sind die Aufgaben oder Vorgänge, die mit Heimwerken und Heimwerken verbunden sind. Beispiele: Malerarbeiten, Installation, Reinigung, Gartenarbeit, Isolierung
- Farbe: Diese Kategorie umfasst alle erwähnten Farben und Schattierungen. Beispiele: Cremeweiß, Türkisblau, Hellgrau, Mattschwarz, Hellgelb
Bewertung der gesamten Pipeline (NER & NEL)
Wir bewerteten die Gesamtleistung anhand von:
- Präzision: Korrekt identifizierte & verknüpfte Entitäten / alle identifizierten & verknüpften.
- Rückruf: Korrekt identifizierte & verknüpfte Entitäten / alle tatsächlichen Entitäten.
- F1 Ergebnis: Ein ausgewogenes Maß für Präzision und Recall.
- Fuzzy Match Metrics (Entfernungen 1, 2, 3): Wir bewerten die Fehler nach ihrem hierarchischen Abstand zur wahren Bezeichnung: Abstand 1 für direkte Nachbarn, Abstand 2 für die nächste Ebene usw. Eine falsche Vorhersage gilt immer noch als “bestanden”, wenn sie innerhalb des erlaubten Radius liegt, wodurch Beinahe-Fehler fairer erfasst werden.
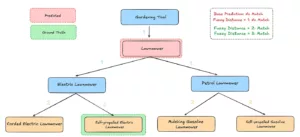
Bewertung mit einer Fuzzy-Metrik
NER auswerten: Wir haben die extrahierten Entitäten mit gesammelten Entitäten mit der Grundwahrheit verglichen (Groß- und Kleinschreibung nicht berücksichtigt). Unsere NER extrahiert absichtlich zu viel, um eine hohe Trefferquote zu erzielen.
NEL auswerten: Unter der Annahme einer perfekten NER haben wir uns auf die Genauigkeit des Verknüpfungsprozesses konzentriert und dabei dieselben Metriken wie bei der gesamten Pipeline verwendet, einschließlich Fuzzy Matching.
Die wichtigsten Ergebnisse: Vielversprechende Ergebnisse & Wachstumsbereiche
Hier sind die Leistungskennzahlen unserer Pipeline
Vollständige Pipeline (genaue Übereinstimmung)
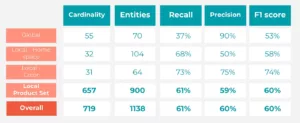
Leistungsmetriken der NER/NEL-Pipeline (Exact Match)
- Globale Entitäten: Hohe Präzision, geringerer Rückruf (ausgeglichenes F1).
- Lokale Entitäten: Abwechslungsreiche Leistung. ProduktSet (Schlüsselkategorie) zeigte eine solide Bilanz (Präzision: 58.9%, Recall: 61.74%, F1: 60.29%). Farbe hat ebenfalls gut abgeschnitten. HomeSpace muss die Präzision verbessert werden.
Vollständige Pipeline (Fuzzy Match)
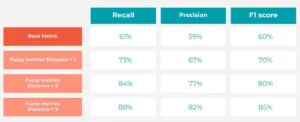
Leistung mit verschiedenen Fuzzy-Metriken
Die Fuzzy-Metriken verbessern sich deutlich, wenn der Abstand zunimmt. Dies zeigt deutlich, dass Vorhersagen, die bei exakter Übereinstimmung als falsch angesehen werden, innerhalb der Graphenhierarchie immer noch relativ nahe am tatsächlichen Wert liegen.
NER:
Wie erwartet, haben wir hohe Wiedererkennung aber geringere Präzision aufgrund unserer Überextraktionsstrategie.
NEL:
Die NEL-Komponente ist effektiv Verfeinerte Verknüpfung von Entitäten 🔗 nach NER.
Schlussfolgerung: Aufbau eines intelligenteren DIY-Ökosystems
Dieses Projekt ist ein wichtiger Schritt bei der Nutzung von KI, um das Heimwerker-Erlebnis auf der Website von Leroy Merlin zu bereichern. Durch den erfolgreichen Aufbau einer Pipeline zur Verknüpfung von Heimwerkerartikeln mit dem Knowledge Graph von Adeo haben wir den Grundstein für eine intelligentere Suche, personalisierte Empfehlungen und reichhaltigere Inhalte gelegt.
Während die ersten Ergebnisse vielversprechend sind (insbesondere für ProductSet), haben wir Bereiche mit Optimierungsbedarf identifiziert, wie z. B. die Verbesserung der Präzision von HomeSpace. Unsere Entscheidung, LLMs für eine schnelle erste Annotation zu verwenden, hat sich als wertvolle Strategie erwiesen, die die Generierung von data für zukünftiges Modelltraining und Verbesserungen beschleunigt.
Die laufende Zusammenarbeit zwischen Adeo, Google und Artefact treibt die Innovation im Einzelhandel weiter voran. Diese Initiative zur Anreicherung des Knowledge Graphs zeigt, wie gut es ist, Fachwissen mit modernster KI zu kombinieren, um ein intuitives und wertvolles Erlebnis für Heimwerker zu schaffen. Im Zuge der Weiterentwicklung unserer Pipeline mit weiteren Verfeinerungen und potenziell fortschrittlicheren Modellen wie Gemini 2.5 Pro wird die Verbindung zwischen Inhalt und Wissen nur noch stärker werden und die Kunden von Leroy Merlin bei ihren Heimwerkerprojekten noch besser unterstützen.
