



Contexte
ADEO a développé une vaste Graphique de connaissances qui englobe l'ensemble de son catalogue de produits. Parallèlement, l'entreprise publie une multitude d'articles de bricolage sur son site web. Cependant, ces articles restent déconnectés du Knowledge Graph, ce qui nous empêche d'identifier précisément quels produits ou entités de la taxonomie sont référencés dans le contenu. En reliant ces articles au Knowledge Graph, ADEO pourrait considérablement améliorer l'expérience de l'utilisateur grâce à des capacités de recherche plus intelligentes, des recommandations personnalisées et un contenu enrichi plus attrayant.
Cette initiative marque le dernier chapitre d'une collaboration fructueuse et durable entre Adeo, Google et Artefact. S'appuyant sur une expertise commune en matière de data, de commerce de détail et de technologie de pointe, ce projet représente une évolution naturelle dans notre quête d'innovation dans le domaine du commerce de détail numérique. L'alignement stratégique avec Google a été déterminant pour fournir les outils et l'infrastructure nécessaires à la réalisation de cet ambitieux projet.
La pierre angulaire : Le Knowledge Graph d'Adeo et le potentiel des articles de bricolage
Au cœur de ce projet se trouve le robuste Knowledge Graph d'Adeo - un graphique sophistiqué database contenant la taxonomie de l'entreprise - qui est une manière structurée de classer et de catégoriser l'information. Ce réseau de points data interconnectés, qui comprend actuellement environ 500 000 relations avec 23 000 sujets uniques, 41 prédicats, et 225 000 objets, représente une mine d'informations sur les produits, les catégories et leurs relations. Voici des exemples simples de relations que vous pourriez trouver dans ce graphe de connaissances :
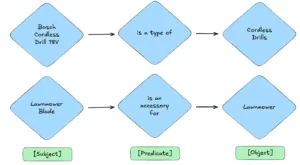
Exemples d'entités et de relations
Cependant, une grande partie des informations précieuses se trouve dans les nombreux documents de la Commission européenne. Articles de bricolage publiés sur le site de Leroy Merlin. Ces articles, riches en conseils pratiques et en instructions, mentionnent souvent des entités déjà présentes dans le Knowledge Graph d'Adeo. Le défi ? Il y avait pas de moyen automatisé pour identifier ces mentions et forger les liens cruciaux entre le contenu textuel et la connaissance structurée.
Combler cette lacune permet de débloquer des valeur commerciale, En extrayant automatiquement des entités d'articles et d'autres textes et en les reliant dans le graphe de connaissances, et donc en l'enrichissant, nous pouvons En extrayant automatiquement des entités à partir d'articles et d'autres data textes et en les reliant dans le graphe de connaissances, et donc en l'enrichissant, nous pouvons :
- Améliorez la pertinence des recherches : Activer recherche sémantique, Les utilisateurs peuvent ainsi trouver des articles en se basant sur les concepts sous-jacents plutôt que sur de simples mots-clés.
- Améliorez les recommandations de produits : Comprendre les entités dont il est question dans un article afin de recommander directement au lecteur des produits, des outils et des matériaux pertinents.
- Enrichir et personnaliser le contenu : Enrichir dynamiquement les articles avec des liens vers des entités pertinentes dans le Knowledge Graph, en fournissant aux utilisateurs un contexte plus approfondi et des informations connexes.
Naviguer dans le paysage : NER & NEL avec les LLM
La tâche à accomplir - identifier et relier les mentions d'entités dans un texte à une base de connaissances prédéfinie - relève des domaines bien établis suivants Reconnaissance des entités nommées (NER) et Lien entre les entités nommées (NEL). Traditionnellement, pour obtenir des performances élevées, il fallait entraîner des modèles spécialisés sur de grands ensembles de data étiquetés. Bien qu'il existe des modèles NER/NEL puissants, leur nature intensive en data présenté un défi pour nos besoins de déploiement rapide.
C'est pourquoi nous avons choisi un approche différente: tirer parti de la puissance de la Grands modèles linguistiques (LLM) pour construire notre pipeline d'extraction. Bien que les LLM ne nécessitent que peu ou pas de formation spécifique à la tâche data - ce qui permet une mise en œuvre et une itération plus rapides - ils exigent tout de même annoté data pour l'évaluation. À cette fin, l'équipe d'Adeo a mis au point un système complet d'évaluation de la qualité de l'eau. ensemble de validation, qui a nécessité des efforts humains considérables et une expertise commerciale approfondie. Cet ensemble data est essentiel pour mesurer de manière fiable la performance du gazoduc.
Notre objectif premier n'était pas d'obtenir une précision parfaite dès le départ. Nous nous sommes plutôt concentrés sur la création d'un pipeline fonctionnel pour fournir texte préannoté aux étiqueteurs humains. Le processus d'annotation s'en trouve considérablement accéléré, ce qui rendra beaucoup plus efficace l'affinement futur des modèles spécialisés.
Notre modèle innovant en deux étapes
Pour traiter les problèmes de NER et de NEL, nous avons développé un pipeline robuste en deux étapes
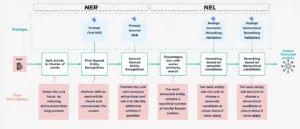
La filière NER/NEL à deux niveaux
1. Reconnaissance des entités nommées (NER) : Repérer les entités candidates
Cette étape permet d'identifier les mentions d'entités pertinentes dans les articles de bricolage à l'aide d'un LLM. Nous traitons la longueur de l'article avec Le découpage du texte : Les articles longs sont divisés en morceaux gérables (500 mots) pour un contexte LLM cohérent et une meilleure performance. Notre processus NER utilise une stratégie à deux niveaux :
- Entités locales : Pour les mentions spécifiques au contexte, chaque morceau de 500 mots fait l'objet d'une double extraction en vue d'un affinage (type de Chaîne de pensées ) à l'aide d'un LLM. Les résultats de tous les blocs sont ensuite combinés.
- Entités mondiales : Pour les thèmes généraux, le texte intégral est traité (à nouveau avec une double extraction à l'aide d'un LLM) pour une couverture complète.
Cette approche à deux niveaux garantit que nous saisissons efficacement les détails granulaires et les concepts généraux.
2. Liens entre les entités nommées (NEL) : Relier les points au graphe de connaissances
Une fois les entités extraites, NEL les désambiguïse et les relie à l'entrée la plus pertinente du Knowledge Graph. Cela implique
🤝 Génération de candidats
Pour chaque entité extraite, nous générons des correspondances potentielles à partir du KG à l'aide d'un magasin de vecteurs et d'enchâssements de texte. Seuls les candidats les plus sémantiquement similaires sont conservés. Nous avons utilisé GCP texte-multilingue-embedding-002 avec un vecteur database pour cette tâche.
Pour illustrer cela, imaginez que l'étape NER extrait l'entité candidate “gants de toile légers” d'un extrait de texte :
“[...] vous pouvez choisir gants légers en toile. Si vous travaillez la terre avec vos mains [...]”.
Lors de l'étape de génération des candidats, le système extrait les correspondances potentielles du graphique de connaissances sur la base de la similarité sémantique. Il peut en résulter une liste classée de candidats tels que “gants jetables” (rang 1), “gants de travail” (rang 2), ..., “gants de jardinage” (rang 9) et “gants pour la manipulation du verre” (rang 10), entre autres.
🧠 Reranking sémantique
Les candidats présélectionnés sont reclassés par un LLM qui analyse le contexte de l'entité dans l'article. Seule la meilleure correspondance est retenue. Nous avons constaté que 25 candidats constituaient le nombre optimal pour le reclassement.
En poursuivant notre exemple, le LLM analyserait maintenant le texte environnant “...Si vous travaillez avec les mains dans la terre...” et utiliserait ce contexte pour classer les candidats. En raison de la mention du travail dans la terre, “gants de jardinage” serait probablement promu en tête de liste en tant que candidat le plus pertinent d'un point de vue sémantique.
🌳 Classement hiérarchique
Le candidat sélectionné est positionné dans la hiérarchie du KG. Un autre LLM peut soit conserver la sélection, soit la remplacer par un parent, un enfant ou un frère ou une sœur plus approprié(e) en fonction du contexte. Un seuil de reclassement hiérarchique de 100 garantit la prise en compte de l'ensemble de la hiérarchie.
Considérez la hiérarchie simplifiée suivante dans le graphe de connaissances :

Dans cette étape, le système vérifie si “gants de jardinage” est le niveau de spécificité le plus approprié. Bien qu'il s'agisse d'une bonne correspondance dans notre exemple, si le contexte avait été plus large, mentionnant simplement la nécessité de se protéger les mains sans le contexte du jardinage, le classement hiérarchique pourrait promouvoir l'entité ancêtre “gants” et la relier à l'entrée KG correspondante.
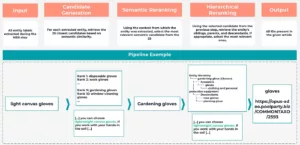
Ce processus NEL en plusieurs étapes garantit un ancrage précis et significatif dans le graphe de connaissances.
Mesurer le succès : Notre méthode d'évaluation
Pour garantir l'efficacité de notre pipeline d'enrichissement des graphes de connaissances pour les articles de bricolage de Leroy Merlin, nous avons mis en œuvre une évaluation robuste à partir d'une base de données d'articles de bricolage soigneusement construite. vérité terrain dataset contenant des entités du graphe de connaissances Adeo.
Cette évaluation se concentre spécifiquement sur la capacité du pipeline à identifier et à relier quatre classes d'entités clés, à savoir ProductSet, HomeSpace, DIYActivity et Color, au niveau global et local dans les articles : ProductSet, HomeSpace, DIYActivity et Color, tant au niveau global que local dans les articles :
- Ensemble de produits : Il s'agit d'outils, de matériaux ou de produits achetables utilisés pour l'amélioration de la maison, le jardinage ou les tâches de bricolage. Exemples: Meuleuse à béton, Pompe à chaleur air-air, Tablier de jardinage, Lampe de bureau, Thermostat intelligent
- Espace personnel : Il s'agit de zones ou de pièces d'une maison ou d'un jardin où se déroulent généralement les activités de bricolage. Exemples: Garage, Jardin, Cuisine, Salle de bain, Balcon
- DIYActivité : Il s'agit des tâches ou opérations liées au bricolage et à l'amélioration de l'habitat. Exemples: Peinture, Installation, Nettoyage, Jardinage, Travaux d'isolation
- Couleur : Cette catégorie comprend toute couleur ou nuance mentionnée. Exemples: Blanc crème, Bleu sarcelle, Gris clair, Noir mat, Jaune vif
Évaluation de l'ensemble du pipeline (NER et NEL)
Nous avons évalué la performance globale à l'aide de
- Précision : Entités correctement identifiées et liées / toutes identifiées et liées.
- Rappel : Entités correctement identifiées et liées / toutes les entités réelles.
- Score F1 : Une mesure équilibrée de la précision et du rappel.
- Mesures de correspondance floue (distances 1, 2, 3) : Nous classons les erreurs en fonction de leur distance hiérarchique par rapport à la véritable étiquette : distance 1 pour les voisins directs, distance 2 pour le niveau suivant, etc. Une prédiction erronée est toujours “acceptée” si elle se situe dans le rayon autorisé, ce qui permet de rendre compte plus équitablement des quasi-erreurs.
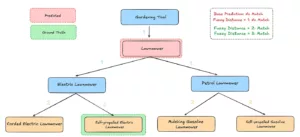
Évaluation à l'aide d'une métrique floue
Évaluation de la NER : Nous avons comparé les entités extraites avec la vérité de base (insensible à la casse). Notre NER sur-extrait intentionnellement pour un rappel élevé.
Évaluation de la NEL : En supposant que le NER est parfait, nous nous sommes concentrés sur la précision du processus de liaison en utilisant les mêmes mesures que le pipeline complet, y compris la correspondance floue.
Principales conclusions : Résultats prometteurs et domaines de croissance
Voici les indicateurs de performance de notre pipeline
Pipeline complet (correspondance exacte)
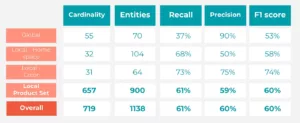
Mesures de performance du pipeline NER/NEL (Exact Match)
- Entités mondiales : Forte précision, faible rappel (F1 équilibré).
- Entités locales : Des performances variées. ProductSet (catégorie clé) a montré un équilibre solide (précision : 58,9%, rappel : 61,74%, F1 : 60,29%). Couleur a également obtenu de bons résultats. Espace personnel La précision doit être améliorée.
Pipeline complet (Fuzzy Match)
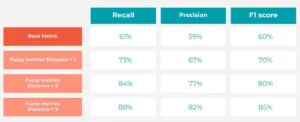
Performance à l'aide de différentes mesures floues
Les mesures floues s'améliorent considérablement à mesure que la distance augmente. Cela montre clairement que les prédictions considérées comme incorrectes dans la correspondance exacte sont encore relativement proches de la valeur réelle dans la hiérarchie des graphes.
NER :
Comme prévu, nous avons obtenu rappel élevé mais une précision moindre en raison de notre stratégie de surextraction.
NEL :
Le volet NEL est efficace liaison d'entités affinées 🔗 après NER.
Conclusion : Construire un écosystème de bricolage plus intelligent
Ce projet marque une étape importante dans l'utilisation de l'IA pour enrichir l'expérience de bricolage sur le site web de Leroy Merlin. En réussissant à construire un pipeline pour relier les articles de bricolage au Knowledge Graph d'Adeo, nous avons posé les bases d'une recherche plus intelligente, de recommandations personnalisées et d'un contenu plus riche.
Bien que les premiers résultats soient prometteurs (en particulier pour ProductSet), nous avons identifié des domaines à optimiser, comme l'amélioration de la précision de HomeSpace. Notre décision d'utiliser les LLM pour une annotation initiale rapide a été une stratégie précieuse, accélérant la génération de data pour la formation et les améliorations futures du modèle.
La collaboration entre Adeo, Google et Artefact continue de stimuler l'innovation dans le domaine de la vente au détail. Cette initiative d'enrichissement du Knowledge Graph illustre la puissance de la combinaison de l'expertise du domaine avec l'IA de pointe pour créer une expérience plus intuitive et plus précieuse pour les amateurs de bricolage. Au fur et à mesure que notre pipeline évolue avec de nouveaux perfectionnements et des modèles potentiellement plus avancés comme Gemini 2.5 Pro, le lien entre le contenu et la connaissance ne fera que se renforcer, donnant encore plus de pouvoir aux clients de Leroy Merlin dans leur parcours de rénovation.
