



Context
ADEO heeft een uitgebreid Kennisgrafiek die de hele productcatalogus omvat. Tegelijkertijd publiceert het bedrijf een schat aan doe-het-zelf-artikelen op zijn website. Deze artikelen zijn echter niet gekoppeld aan de kennisgrafiek, waardoor we niet nauwkeurig kunnen vaststellen naar welke producten of entiteiten binnen de taxonomie in de inhoud wordt verwezen. Door deze artikelen aan de kennisgrafiek te koppelen, zou ADEO de gebruikerservaring aanzienlijk kunnen verbeteren door slimmere zoekmogelijkheden, gepersonaliseerde aanbevelingen en interessantere, verrijkte inhoud.
Dit initiatief is het nieuwste hoofdstuk in een succesvolle en duurzame samenwerking tussen Adeo, Google en Artefact. Dit project bouwt voort op een fundament van gedeelde expertise in data, retail en geavanceerde technologie en is een natuurlijke evolutie in onze reis om het digitale retaillandschap te innoveren. De strategische afstemming met Google is van groot belang geweest bij het leveren van de tools en infrastructuur die nodig zijn om deze ambitieuze onderneming aan te pakken.
De hoeksteen: Adeo's Kennisgrafiek & DIY Artikel Potentieel
Het hart van dit project wordt gevormd door Adeo's robuuste Knowledge Graph - een geavanceerde data-grafiekbasis waarin de taxonomie van het bedrijf is ondergebracht - een gestructureerde manier om informatie te classificeren en categoriseren. Dit netwerk van onderling verbonden data punten, dat momenteel ongeveer 500.000 relaties met 23.000 unieke onderwerpen, 41 predikaten, en 225.000 objecten, vertegenwoordigt een schat aan informatie over producten, categorieën en hun relaties. Hier volgen eenvoudige voorbeelden van relaties die u in deze kennisgrafiek kunt vinden:
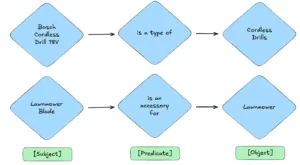
Voorbeelden van entiteiten en relaties
Een aanzienlijk deel van de waardevolle informatie bevindt zich echter in de talrijke Doe-Het-Zelf (DIY) artikelen gepubliceerd op de website van Leroy Merlin. Deze artikelen, die vol staan met praktisch advies en instructies, vermelden vaak entiteiten die al aanwezig zijn in Adeo's Knowledge Graph. De uitdaging? Er was geen geautomatiseerde manier om deze vermeldingen te identificeren en de cruciale verbanden te leggen tussen de tekstuele inhoud en de gestructureerde kennis.
Door deze kloof te overbruggen, kunnen belangrijke bedrijfswaarde, vooral binnen de context van een voortdurende AI- en Gen-AI-transformatie. Door automatisch entiteiten uit artikelen en andere tekstuele data te halen en deze in de Kennisgrafiek te koppelen, en dus te verrijken, kunnen we:
- Verbeter de zoekrelevantie: inschakelen semantisch zoeken, waardoor gebruikers artikelen kunnen vinden op basis van de onderliggende concepten in plaats van alleen trefwoorden.
- Productaanbevelingen verbeteren: Begrijp de entiteiten die in een artikel worden besproken om relevante producten, hulpmiddelen en materialen rechtstreeks aan de lezer aan te bevelen.
- Inhoud verrijken en personaliseren: Artikelen dynamisch verrijken met links naar relevante entiteiten in de Knowledge Graph, zodat gebruikers diepere context en gerelateerde informatie krijgen.
Navigeren door het landschap: NER & NEL met LLM's
De taak in kwestie - het identificeren en koppelen van vermeldingen van entiteiten in tekst aan een vooraf gedefinieerde kennisbank - valt onder de gevestigde domeinen van Named Entity Recognition (NER) en Named Entity Linking (NEL). Traditioneel vereiste hoge prestaties het trainen van gespecialiseerde modellen op grote, gelabelde datasets. Hoewel er krachtige NER/NEL-modellen bestaan, is hun data-intensieve aard gepresenteerd een uitdaging voor onze snelle inzetbaarheid.
Daarom kozen we voor een andere aanpak: de kracht van Grote taalmodellen (LLM's) om onze extractiepijplijn te bouwen. Hoewel LLM's weinig tot geen taakspecifieke training data vereisen - wat snellere implementatie en iteratie mogelijk maakt - vereisen ze nog steeds geannoteerd data voor evaluatie. Hiertoe bouwde het Adeo-team een uitgebreide validatieset, waarvoor aanzienlijke menselijke inspanningen en diepgaande bedrijfsexpertise nodig waren. Deze dataset is essentieel voor het betrouwbaar meten van de prestaties van de pijplijn.
Ons primaire doel was niet een perfecte nauwkeurigheid vanaf het begin. In plaats daarvan richtten we ons op het creëren van een functionele pijplijn om vooraf genoteerde tekst aan menselijke labelaars. Dit versnelt het annotatieproces aanzienlijk, waardoor toekomstige fijnafstemming van gespecialiseerde modellen veel efficiënter wordt.
Ons innovatieve tweefasenmodel
Om NER en NEL aan te pakken, ontwikkelden we een robuuste tweefasige pijplijn
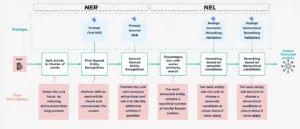
De NER/NEL-pijplijn met twee niveaus
1. Named Entity Recognition (NER): Kandidaat-entiteiten opsporen
Deze fase identificeert vermeldingen van relevante entiteiten in doe-het-zelfartikelen met behulp van een LLM. We behandelen de lengte van artikelen met Tekst samenvoegen: Lange artikelen worden opgesplitst in hanteerbare stukken (500 woorden) voor een consistente LLM-context en betere prestaties. Ons NER-proces gebruikt een strategie op twee niveaus:
- Lokale entiteiten: Voor contextspecifieke vermeldingen ondergaat elke chunk van 500 woorden een dubbele extractie voor verfijning (soort Ketting van gedachten ) met behulp van een LLM. De resultaten van alle chunks worden vervolgens gecombineerd.
- Wereldwijde entiteiten: Voor overkoepelende thema's wordt de volledige tekst verwerkt (opnieuw met dubbele extractie met behulp van een LLM) voor een uitgebreide dekking.
Deze tweeledige aanpak zorgt ervoor dat we zowel details als brede concepten effectief vastleggen.
2. Named Entity Linking (NEL): De puntjes verbinden met de kennisgrafiek
Zodra entiteiten zijn geëxtraheerd, desambigueert NEL ze en koppelt ze aan de meest relevante Knowledge Graph-vermelding. Dit houdt in:
🤝 Genereren van kandidaten
Voor elke geëxtraheerde entiteit genereren wij potentiële overeenkomsten uit de KG met behulp van een vectoropslag en tekstinbeddingen. Alleen de semantisch meest vergelijkbare kandidaten worden bewaard. We gebruikten GCP tekst-meertalig-insluiten-002 model met een vector database voor deze taak.
Om dit te illustreren, stelt u zich voor dat de NER-fase de kandidaat-entiteit “lichtgewicht canvas handschoenen” uit een tekstfragment haalt:
“[...] u kunt kiezen lichtgewicht canvas handschoenen. Als u met uw handen in de grond werkt [...]”.
In de stap “Kandidaten genereren” haalt het systeem potentiële overeenkomsten uit de kennisgrafiek op basis van semantische gelijkenis. Dit kan een gerangschikte lijst van kandidaten opleveren, zoals “wegwerphandschoenen” (rang 1), “werkhandschoenen” (rang 2), ..., “tuinhandschoenen” (rang 9) en "handschoenen voor het hanteren van glas" (rang 10), enz.
🧠 Semantisch herrangschikken
De kandidaten op de shortlist worden opnieuw gerangschikt door een LLM die de context van de entiteit in het artikel analyseert. Alleen de beste overeenkomst gaat door. Wij vonden 25 kandidaten het optimale aantal voor herrangschikking.
Om ons voorbeeld voort te zetten, zou de LLM nu de omringende tekst “...Als u met uw handen in de grond werkt...” analyseren en deze context gebruiken om de kandidaten te rangschikken. Door de vermelding van het werken met aarde, zou “tuinhandschoenen” waarschijnlijk naar de top van de lijst gepromoveerd worden als de semantisch meest relevante kandidaat.
🌳 Hiërarchische rangschikking
De geselecteerde kandidaat wordt gepositioneerd binnen de hiërarchie van de KG. Een andere LLM kan op basis van de context de selectie behouden of vervangen door een geschiktere ouder, kind of broer of zus. Een hiërarchische herklasseringsdrempel van 100 zorgt ervoor dat de volledige hiërarchie in aanmerking wordt genomen.
Beschouw de volgende vereenvoudigde hiërarchie in de Kennisgrafiek:

In deze stap controleert het systeem of “tuinhandschoenen” het meest geschikte specificiteitsniveau is. Hoewel het in ons voorbeeld een goede overeenkomst is, zou de hiërarchische rangschikking, als de context breder was geweest en alleen de noodzaak van handbescherming had vermeld zonder de tuiniercontext, de voorouderentiteit “handschoenen” kunnen promoten en aan de overeenkomstige KG-vermelding kunnen koppelen.
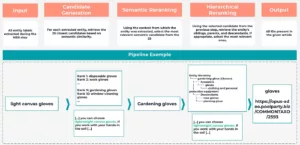
Dit NEL-proces in meerdere stappen zorgt voor een nauwkeurige en zinvolle verankering in de Kennisgrafiek.
Succes meten: Onze evaluatiemethode
Om de effectiviteit van onze kennisgrafiekverrijkingspijplijn voor de doe-het-zelfartikelen van Leroy Merlin te garanderen, hebben we een robuuste evaluatie uitgevoerd tegen een zorgvuldig opgebouwde grondwaarheid dataset met entiteiten uit de Adeo-kennisgrafiek.
Deze evaluatie richt zich specifiek op het vermogen van de pijplijn om vier belangrijke entiteitklassen te identificeren en te koppelen: ProductSet, HomeSpace, DIYActivity en Color, zowel op globaal als lokaal niveau binnen de artikelen:
- ProductSet: Dit zijn gereedschappen, materialen of te kopen producten die gebruikt worden voor huisverbetering, tuinieren of doe-het-zelftaken. Voorbeelden: Betonmolen, Lucht-lucht warmtepomp, Tuinschort, Bureaulamp, Slimme thermostaat
- Thuisruimte: Dit zijn ruimtes of kamers in een huis of tuin waar gewoonlijk doe-het-zelf-activiteiten plaatsvinden. Voorbeelden: Garage, Tuin, Keuken, Badkamer, Balkon
- Doe-het-zelf activiteit: Dit zijn de taken of handelingen die te maken hebben met doe-het-zelven en woningverbetering. Voorbeelden: Schilderen, Installatie, Schoonmaken, Tuinieren, Isolatiewerk
- Kleur: Deze categorie omvat elke vermelde kleur of tint. Voorbeelden: Crèmewit, Blauwgroen, Lichtgrijs, Matzwart, Heldergeel
De volledige pijplijn evalueren (NER & NEL)
We beoordeelden de algemene prestaties aan de hand van:
- Nauwkeurig: Correct geïdentificeerde en gekoppelde entiteiten / alle geïdentificeerde en gekoppelde entiteiten.
- Terugroepen: Correct geïdentificeerde en gekoppelde entiteiten / alle werkelijke entiteiten.
- F1 Score: Een evenwichtige meting van precisie en recall.
- Fuzzy Match Metrics (afstanden 1, 2, 3): Wij scoren fouten aan de hand van hun hiërarchische afstand tot het ware label: afstand 1 voor directe buren, afstand 2 voor het volgende niveau, enz. Een foute voorspelling “slaagt” nog steeds als deze binnen de toegestane straal ligt, waardoor bijna-fouten eerlijker worden weergegeven.
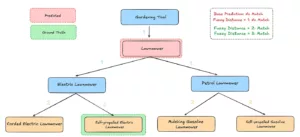
Evaluatie met behulp van een Fuzzy Metric
NER evalueren: We hebben de stammen van geëxtraheerde entiteiten vergeleken met de stammen van de grondwaarheid (hoofdletterongevoelig). Onze NER extraheert opzettelijk voor een hoge recall.
NEL evalueren: Ervan uitgaande dat NER perfect is, hebben we ons gericht op de nauwkeurigheid van het koppelingsproces met behulp van dezelfde meetgegevens als de volledige pijplijn, inclusief fuzzy matching.
Belangrijkste bevindingen: Veelbelovende resultaten en groeigebieden
Hier zijn de prestatiecijfers van onze pijplijn
Volledige pijplijn (Exacte match)
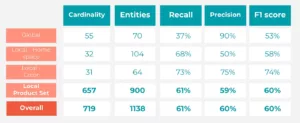
Prestatiecijfers van de NER/NEL-pijplijn (Exacte match)
- Wereldwijde entiteiten: Sterke precisie, lagere recall (gebalanceerde F1).
- Lokale entiteiten: Gevarieerde prestaties. ProductSet (hoofdcategorie) vertoonde een solide balans (Precisie: 58,9%, Recall: 61,74%, F1: 60,29%). Kleur presteerde ook goed. HomeSpace moet nauwkeuriger worden.
Volledige pijplijn (Fuzzy Match)
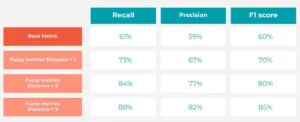
Prestaties met behulp van verschillende fuzzy-metrieken
De fuzzy metriek verbetert aanzienlijk naarmate de afstand toeneemt. Dit laat duidelijk zien dat voorspellingen die als onjuist worden beschouwd bij een exacte match nog steeds relatief dicht bij de werkelijke waarde liggen binnen de grafiekhiërarchie.
NER:
Zoals verwacht bereikten we hoge terugroepfunctie maar een lagere precisie door onze over-extractie strategie.
NEL:
De NEL-component is effectief verfijnde entiteitkoppeling 🔗 na NER.
Conclusie: Een slimmer doe-het-zelf ecosysteem bouwen
Dit project markeert een belangrijke stap in het gebruik van AI om de doe-het-zelf ervaring op de website van Leroy Merlin te verrijken. Door met succes een pijplijn te bouwen om DIY-artikelen te koppelen aan Adeo's Knowledge Graph, hebben we de basis gelegd voor slimmer zoeken, gepersonaliseerde aanbevelingen en rijkere inhoud.
Hoewel de eerste resultaten veelbelovend zijn (vooral voor ProductSet), hebben we gebieden geïdentificeerd die voor optimalisatie in aanmerking komen, zoals het verbeteren van de precisie van HomeSpace. Onze beslissing om LLM's te gebruiken voor snelle initiële annotatie is een waardevolle strategie geweest, die het genereren van data voor toekomstige modeltraining en verbeteringen heeft versneld.
De voortdurende samenwerking tussen Adeo, Google en Artefact blijft retailinnovatie stimuleren. Dit initiatief om de kennisgrafiek te verrijken laat de kracht zien van het combineren van domeinkennis met geavanceerde AI om een intuïtievere en waardevollere ervaring te creëren voor doe-het-zelvers. Naarmate onze pijplijn zich verder ontwikkelt met verdere verfijningen en mogelijk meer geavanceerde modellen zoals Gemini 2.5 Pro, zal de verbinding tussen inhoud en kennis alleen maar sterker worden, waardoor de klanten van Leroy Merlin nog beter in staat zullen zijn om hun huis te verbeteren.
