



Contexto
ADEO ha desarrollado un amplio Gráfico del conocimiento que abarca todo su catálogo de productos. Simultáneamente, la empresa publica una gran cantidad de artículos de bricolaje en su sitio web. Sin embargo, estos artículos permanecen desconectados del Gráfico de conocimiento, lo que impide identificar con precisión a qué productos o entidades de la taxonomía se hace referencia en el contenido. Al vincular estos artículos al Gráfico de Conocimientos, ADEO podría elevar significativamente la experiencia del usuario mediante capacidades de búsqueda más inteligentes, recomendaciones personalizadas y contenidos más atractivos y enriquecidos.
Esta iniciativa marca el último capítulo de una exitosa y duradera colaboración entre Adeo, Google y Artefact. Partiendo de una base de experiencia compartida en data, comercio minorista y tecnología de vanguardia, este proyecto representa una evolución natural en nuestro viaje para innovar el panorama del comercio minorista digital. La alineación estratégica con Google ha sido decisiva para proporcionar las herramientas y la infraestructura necesarias para abordar esta ambiciosa empresa.
La piedra angular: El potencial de Knowledge Graph y DIY Article de Adeo
En el corazón de este proyecto se encuentra el robusto Gráfico del Conocimiento de Adeo, un sofisticado gráfico database que alberga la taxonomía de la empresa, que es una forma estructurada de clasificar y categorizar la información. Esta red de puntos data interconectados, que actualmente comprende alrededor de 500.000 relaciones con 23.000 sujetos únicos, 41 predicados, y 225.000 objetos, representa una gran cantidad de información sobre productos, categorías y sus relaciones. He aquí ejemplos sencillos de relaciones que puede encontrar en este grafo de conocimiento:
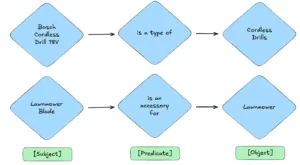
Ejemplos de entidades y relaciones
Sin embargo, una parte importante de la información valiosa reside en los numerosos Artículos de bricolaje publicados en el sitio web de Leroy Merlin. Estos artículos, ricos en consejos prácticos e instrucciones, mencionan a menudo entidades ya presentes en el grafo de conocimiento de Adeo. ¿El reto? Había ninguna forma automatizada para identificar estas menciones y forjar los vínculos cruciales entre el contenido textual y el conocimiento estructurado.
Salvar esta brecha desbloquea importantes valor empresarial, especialmente en el contexto de una transformación en curso de la IA y la Gen IA. Extrayendo automáticamente entidades de artículos y otros data textuales y vinculándolas en el grafo de conocimiento, y enriqueciéndolo así, podemos:
- Mejore la relevancia de la búsqueda: Habilite búsqueda semántica, lo que permite a los usuarios encontrar artículos basándose en los conceptos subyacentes y no sólo en palabras clave.
- Mejore las recomendaciones de productos: Comprender las entidades de las que se habla en un artículo para recomendar productos, herramientas y materiales relevantes directamente al lector.
- Enriquezca y personalice los contenidos: Enriquezca dinámicamente los artículos con enlaces a entidades relevantes en el grafo de conocimiento, proporcionando a los usuarios un contexto más profundo e información relacionada.
Navegando por el paisaje: NER y NEL con LLM
La tarea que nos ocupa -identificar y vincular las menciones de entidades dentro de un texto a una base de conocimientos predefinida- entra dentro de los dominios bien establecidos del Reconocimiento de entidades con nombre (NER) y Enlace de entidades con nombre (NEL). Tradicionalmente, un alto rendimiento requería el entrenamiento de modelos especializados en grandes conjuntos data etiquetados. Aunque existen potentes modelos NER/NEL, su naturaleza intensiva en data presentado un reto para nuestras necesidades de despliegue rápido.
Por lo tanto, elegimos un enfoque diferente: aprovechando el poder de Grandes modelos lingüísticos (LLM) para construir nuestra tubería de extracción. Aunque los LLM requieren poco o ningún entrenamiento específico de la tarea data -lo que permite una implementación e iteración más rápidas- siguen exigiendo anotado data para su evaluación. Para ello, el equipo de Adeo construyó un exhaustivo conjunto de validación, lo que requirió un importante esfuerzo humano y profundos conocimientos empresariales. Este dataset es esencial para medir con fiabilidad el rendimiento del oleoducto.
Nuestro objetivo principal no era una precisión perfecta desde el principio. En su lugar, nos centramos en crear una canalización funcional que proporcionara texto preanotado a los etiquetadores humanos. Esto acelera significativamente el proceso de anotación, haciendo mucho más eficiente el futuro ajuste de los modelos especializados.
Nuestro innovador modelo en dos fases
Para abordar la NER y la NEL, desarrollamos un robusto pipeline de dos etapas
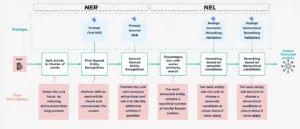
El conducto de dos niveles NER/NEL
1. Reconocimiento de entidades con nombre (NER): Detección de entidades candidatas
Esta etapa identifica las menciones de entidades relevantes dentro de los artículos de bricolaje utilizando un LLM. Manejamos la longitud del artículo con Agrupación de textos: Los artículos largos se dividen en trozos manejables (500 palabras) para obtener un contexto LLM coherente y un mejor rendimiento. Nuestro proceso NER utiliza una estrategia de doble nivel:
- Entidades locales: Para las menciones específicas del contexto, cada trozo de 500 palabras se somete a una extracción de doble pasada para su refinamiento ( tipo de Cadena de pensamientos ) utilizando un LLM. A continuación se combinan los resultados de todos los trozos.
- Entidades globales: Para los temas generales, se procesa el texto completo (de nuevo con doble extracción mediante un LLM) para obtener una cobertura exhaustiva.
Este enfoque a dos niveles garantiza que captemos eficazmente tanto los detalles granulares como los conceptos generales.
2. Enlace de entidades con nombre (NEL): Conectando los puntos con el grafo de conocimiento
Una vez extraídas las entidades, NEL las desambigua y las vincula a la entrada más relevante del Knowledge Graph. Esto implica
🤝 Generación de candidatos
Para cada entidad extraída, generamos posibles coincidencias a partir del KG utilizando un almacén de vectores e incrustaciones de texto. Sólo se conservan los candidatos más similares semánticamente. Utilizamos BPC texto-multilingüe-incorporado-002 modelo con un vector database para esta tarea.
Para ilustrarlo, imagine que la etapa NER extrae la entidad candidata “guantes de lona ligeros” de un fragmento de texto:
“[...] puede elegir guantes ligeros de lona. Si trabaja con las manos en la tierra [...]”.
En el paso de generación de candidatos, el sistema recupera posibles coincidencias del grafo de conocimiento basándose en la similitud semántica. Esto puede producir una lista clasificada de candidatos como “guantes desechables” (puesto 1), “guantes de trabajo” (puesto 2), ..., “guantes de jardinería” (puesto 9) y “guantes para manipular vidrio” (puesto 10), entre otros.
🧠 Recalificación semántica
Los candidatos preseleccionados son recalificados por un LLM que analiza el contexto de la entidad en el artículo. Sólo se procede con la mejor coincidencia. Encontramos que 25 candidatos es el número óptimo para el reranking.
Siguiendo con nuestro ejemplo, el LLM analizaría ahora el texto circundante “...Si trabaja con las manos en la tierra...” y utilizaría este contexto para volver a clasificar a los candidatos. Debido a la mención del trabajo con tierra, “guantes de jardinería” probablemente ascendería al primer puesto de la lista como el candidato semánticamente más relevante.
🌳 Clasificación jerárquica
El candidato seleccionado se posiciona dentro de la jerarquía del KG. Otro LLM puede mantener la selección o sustituirla por un padre, hijo o hermano más adecuado en función del contexto. Un umbral de reordenación jerárquica de 100 garantiza que se tenga en cuenta toda la jerarquía.
Considere la siguiente jerarquía simplificada en el grafo de conocimiento:

En este paso, el sistema verifica si “guantes de jardinería” es el nivel de especificidad más adecuado. Aunque en nuestro ejemplo es una buena coincidencia, si el contexto hubiera sido más amplio, mencionando simplemente la necesidad de protegerse las manos sin el contexto de la jardinería, la clasificación jerárquica podría promover la entidad antecesora “guantes” y vincularla a la entrada KG correspondiente.
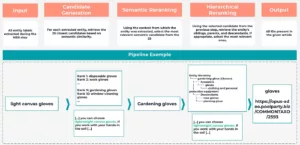
Este proceso NEL de varios pasos garantiza un anclaje preciso y significativo dentro del grafo de conocimiento.
Medir el éxito: Nuestra metodología de evaluación
Para garantizar la eficacia de nuestra canalización de enriquecimiento del grafo de conocimiento para los artículos de bricolaje de Leroy Merlin, llevamos a cabo una sólida evaluación comparándola con una base de datos cuidadosamente construida verdad sobre el terreno dataset que contiene entidades del grafo de conocimiento de Adeo.
Esta evaluación se centra específicamente en la capacidad de la canalización para identificar y vincular cuatro clases de entidades clave: ProductSet, HomeSpace, DIYActivity y Color, tanto a nivel global como local dentro de los artículos:
- ProductoSet: Se trata de herramientas, materiales o productos adquiribles que se utilizan para las mejoras del hogar, la jardinería o las tareas de bricolaje. Ejemplos: Amoladora de hormigón, Bomba de calor aire-aire, Delantal de jardinería, Lámpara de escritorio, Termostato inteligente
- HomeSpace: Representan las zonas o habitaciones de una casa o jardín donde suelen tener lugar las actividades de bricolaje. Ejemplos: Garaje, Jardín, Cocina, Baño, Balcón
- DIYActividad: Son las tareas u operaciones relacionadas con el bricolaje y las mejoras en el hogar. Ejemplos: Pintura, Instalación, Limpieza, Jardinería, Trabajos de aislamiento
- Color: Esta categoría incluye cualquier color o tono mencionado. Ejemplos: Blanco cremoso, Azul cerceta, Gris claro, Negro mate, Amarillo brillante
Evaluación de la tubería completa (NER y NEL)
Evaluamos el rendimiento global utilizando:
- Precisión: Entidades correctamente identificadas y vinculadas / todas identificadas y vinculadas.
- Recuérdelo: Entidades correctamente identificadas y vinculadas / todas las entidades reales.
- Puntuación F1: Una medida equilibrada de precisión y recuperación.
- Métricas de coincidencia difusa (distancias 1, 2, 3): Puntuamos los errores por su distancia jerárquica respecto a la etiqueta verdadera: distancia 1 para los vecinos directos, distancia 2 para el siguiente nivel, etc. Una predicción errónea sigue “pasando” si se encuentra dentro del radio permitido, capturando de forma más justa los errores cercanos.
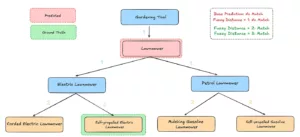
Evaluación mediante una métrica difusa
Evaluación de la RNE: Comparamos las entidades extraídas stemmed con la verdad básica stemmed (sin distinción entre mayúsculas y minúsculas). Nuestro NER sobreextrae intencionadamente para obtener una alta recuperación.
Evaluación de la NEL: Suponiendo un NER perfecto, nos centramos en la precisión del proceso de enlace utilizando las mismas métricas que en el pipeline completo, incluida la concordancia difusa.
Conclusiones clave: Resultados prometedores y áreas de crecimiento
Estas son las métricas de rendimiento de nuestra tubería
Canalización completa (coincidencia exacta)
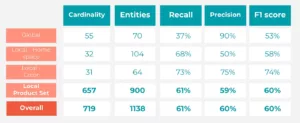
Métricas de rendimiento de la canalización NER/NEL (Coincidencia exacta)
- Entidades globales: Gran precisión, menor recall (F1 equilibrado).
- Entidades locales: Rendimiento variado. ProductSet (categoría clave) mostró un sólido equilibrio (Precisión: 58,9%, Recall: 61,74%, F1: 60,29%). Color también obtuvo buenos resultados. HomeSpace necesita mejorar su precisión.
Canalización completa (coincidencia difusa)
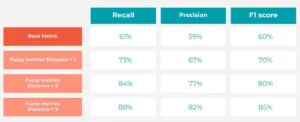
Rendimiento utilizando diferentes métricas difusas
Las métricas difusas mejoran significativamente a medida que aumenta la distancia. Esto muestra claramente que las predicciones consideradas incorrectas en la coincidencia exacta siguen estando relativamente cerca del valor real dentro de la jerarquía del gráfico.
NER:
Como era de esperar, logramos alto recuerdo pero menor precisión debido a nuestra estrategia de sobreextracción.
NEL:
El componente NEL efectivamente vinculación refinada de entidades 🔗 después de la NER.
Conclusiones: Construir un ecosistema de bricolaje más inteligente
Este proyecto supone un paso importante en el uso de la IA para enriquecer la experiencia del bricolaje en el sitio web de Leroy Merlin. Al construir con éxito una canalización para vincular los artículos de bricolaje al Gráfico de conocimiento de Adeo, hemos sentado las bases para una búsqueda más inteligente, recomendaciones personalizadas y contenidos más ricos.
Aunque los resultados iniciales son prometedores (especialmente para ProductSet), hemos identificado áreas de optimización, como la mejora de la precisión de HomeSpace. Nuestra decisión de utilizar LLM para una anotación inicial rápida ha sido una estrategia valiosa, ya que acelera la generación de data para el futuro entrenamiento y mejora de los modelos.
La colaboración en curso entre Adeo, Google y Artefact sigue impulsando la innovación en el sector minorista. Esta iniciativa de enriquecimiento del Gráfico de conocimiento muestra el poder de combinar la experiencia en el dominio con la IA de vanguardia para crear una experiencia más intuitiva y valiosa para los aficionados al bricolaje. A medida que nuestra línea de productos evolucione con nuevos perfeccionamientos y modelos potencialmente más avanzados como Gemini 2.5 Pro, la conexión entre el contenido y el conocimiento no hará sino reforzarse, empoderando aún más a los clientes de Leroy Merlin en sus viajes de mejora del hogar.
