

Autor

TL;DR
Compreender o feedback dos clientes e saber quais são seus pontos fortes e fracos é fundamental para qualquer empresa. Hoje em dia, as empresas têm acesso a muitas informações que podem fornecer esses insights: avaliações de sites, interações em chats, transcrições de conversas, comentários em mídias sociais...
Este artigo explica como o senhor pode extrair rapidamente insights de data textuais, aproveitando as avaliações dos consumidores como exemplo. Apresentaremos três abordagens diferentes:
temas comerciais predefinidos
(a modelagem de tópicos poderia ser uma quarta opção para ir além)
Observe que o data por trás deste artigo foi gerado artificialmente para garantir a confidencialidade de nosso projeto inicial.

Análise das avaliações dos clientes
Estamos tentando obter insights das avaliações de nossos produtos para entender quais são seus principais problemas/principais pontos fortes. Os produtos são dispositivos de câmera e acessórios, classificados de 1 (ruim) a 5 (excelente).
Usaremos três abordagens diferentes aqui para obter insights do nosso data.
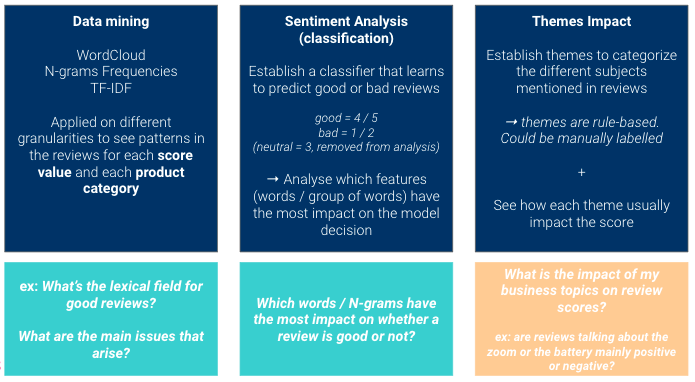
O objetivo é ter visões complementares:
Dê uma olhada geral no data que o senhor coletou
Sempre que o senhor inicia um novo projeto de data, a primeira etapa é sempre obter uma visão geral do data que possui (ele está desequilibrado? há data suficiente? há muitos valores ausentes?).
Quantas avaliações eu tenho para cada categoria de produto?
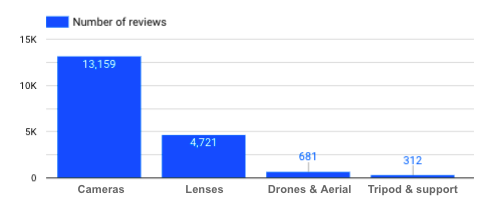
Número de avaliações por categoria de produto
→ O fato de não haver tantas avaliações de tripés deve ser levado em conta quando analisamos as avaliações dessa categoria específica de produto. Quanto mais data tivermos, melhor, para que possamos chegar a conclusões imparciais e relevantes.
Quantas avaliações eu tenho para cada classificação?
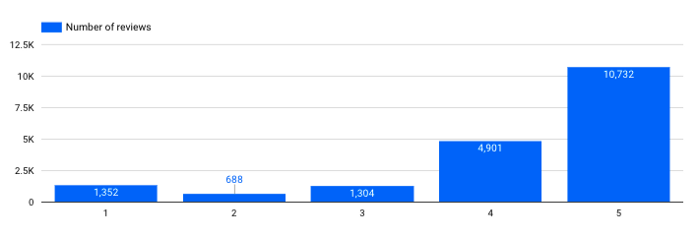
Número de avaliações por pontuação
→ Isso é importante. Vemos que nosso dataset é bastante desequilibrado, temos muito mais avaliações positivas do que negativas. Esse tipo de informação precisa ser levado em conta ao treinar modelos dedicados (por exemplo, um modelo de classificação para análise de sentimentos).
Qual é a distribuição de classificação de cada categoria?
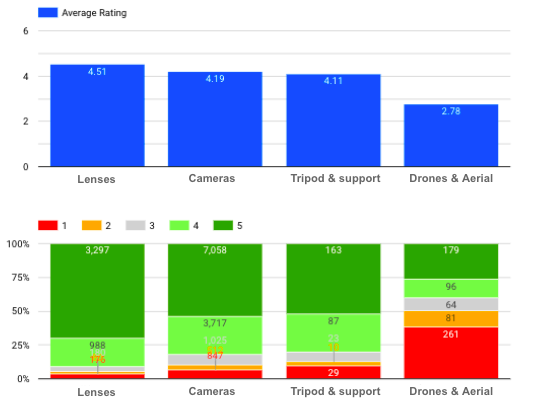
Classificação média e distribuição de cada categoria de produto
Podemos ver aqui que as Lentes têm a classificação média mais alta, enquanto há muitas avaliações negativas (especialmente com uma pontuação de 1) para Drones e Aerial Imaging.
Usar a PNL para entender as preocupações de seus clientes
Agora, para entender do que se tratam as avaliações, vamos implementar as diferentes abordagens de PNL mencionadas anteriormente.
Limpeza Data
Antes de fazer qualquer outra coisa, precisamos limpar o texto data para torná-lo utilizável pelos diferentes métodos de NLP (essa etapa nem sempre é necessária, dependendo dos algoritmos que o senhor deseja usar).
Aplicamos funções de pré-processamento padrão que eram relevantes para o nosso data (remoção de HTML, pontuação, números de telefone, etc.) e implementamos uma lista personalizada de palavras de parada que removemos das avaliações (por exemplo, a palavra “câmera” não traz muitas informações para nossa análise).
O senhor pode encontrar muitas dessas funções em nosso NLPretext Repositório do Github.
Mineração de insights em poucas linhas de código
Agora que temos para cada avaliação:
Podemos começar simplesmente observando as palavras mais frequentes (palavras únicas, bi-gramas, tri-gramas...). É uma análise simples, mas que lhe dá uma visão imediata de quais são os principais tópicos de cada pontuação e categoria.
from collections import Counter
import matplotlib.pyplot as plt
importar wordcloud
plt.rcParams[“figure.figsize”] = [16, 9]
def create_ngrams(token_list, nb_elements):
“””
Criar n-gramas para a lista de tokens
Parâmetros
----
token_list : lista
lista de cadeias de caracteres
nb_elements :
número de elementos no n-grama
Devoluções
---
Gerador
gerador de todos os n-gramas
“””
ngrams = zip(*[token_list[index_token:] for index_token in range(nb_elements)])
return (” “.join(ngram) for ngram in ngrams)
def frequent_words(list_words, ngrams_number=1, number_top_words=10):
“””
Criar n-gramas para a lista de tokens
Parâmetros
----
ngrams_number : int
number_top_words : int
saída datacomprimento do quadro
Devoluções
---
DataFrame
Dataframe com as entidades e suas frequências.
“””
frequent = []
se ngrams_number == 1:
passar
elif ngrams_number >= 2:
list_words = create_ngrams(list_words, ngrams_number)
E mais:
raise ValueError(“number of n-grams should be >= 1”)
counter = Counter(list_words)
frequent = counter.most_common(number_top_words)
retorno frequente
def make_word_cloud(text_or_counter, stop_words=None):
if isinstance(text_or_counter, str):
word_cloud = wordcloud.WordCloud(stopwords=stop_words).generate(text_or_counter)
E mais:
se stop_words não for None:
text_or_counter = Counter(word for word in text_or_counter if word not in stop_words)
word_cloud = wordcloud.WordCloud(stopwords=stop_words).generate_from_frequencies(text_or_counter)
plt.imshow(word_cloud)
plt.axis(“off”)
plt.show()
WordCloud
Aproveitando essas funções, podemos exibir facilmente uma nuvem de palavras mais frequentes, usando avaliações de câmeras com uma pontuação entre 1 e 2:

Em seguida, exiba uma nuvem de palavras semelhante usando avaliações de câmeras com uma pontuação entre 4 e 5:
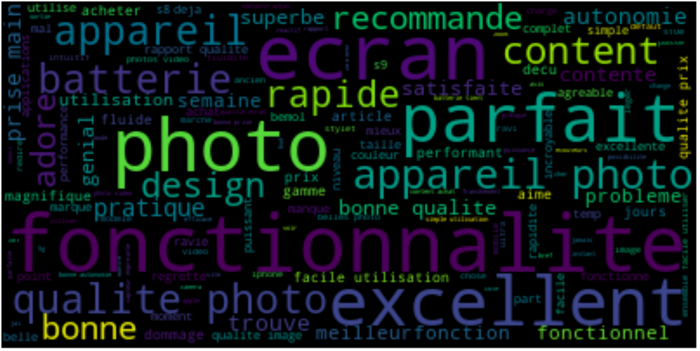
Podemos identificar facilmente os principais pontos levantados em ambos os casos.
Poderíamos fazer esse exercício para cada produto de nossa empresa, a fim de ver a especificidade de cada um e poder tirar conclusões em um nível mais granular.
Contagem de N-gramas
Também podemos usar o palavras_frequentes para exibir as palavras, bi-gramas ou tri-gramas mais frequentes:

Para ir mais longe, o senhor poderia implementar uma função que exibisse as revisões associadas a uma palavra-chave, a fim de ampliar os n-gramas que considerar interessantes. O senhor também poderia examinar os n-gramas com o maior / menor TF-IDF (fácil de calcular com o sklearn ), pois ele permite que o senhor veja palavras importantes com base em uma métrica diferente de um simples contador de frequência.
Análise de sentimento
Em seguida, passamos para uma abordagem de análise de sentimento. Normalmente, ela é usada para prever se um texto é positivo ou negativo. No nosso caso, já temos essa informação (a pontuação entre 1 e 5 nos dá o sentimento por trás da avaliação). Mas treinar um modelo para prever essa classificação nos ajudará a descobrir quais palavras (recursos) são fundamentais para os clientes.
O que podemos fazer é treinar um classificador de análise de sentimentos nesse data, e, em seguida, usar bibliotecas como SHAP ou LIME para entender que apresenta (= palavras) ter o maior impacto em uma avaliação ser classificada como positiva ou negativa.
Classificador
Para treinar um classificador, há vários algoritmos possíveis que podem ser usados, desde o clássico LogisticRegression do sklearn até os modelos ULM-fit (ver este caderno para treinar um modelo francês de ajuste ULM, e este artigo para entender mais sobre o ULM-fit) ou o classificador Ludwig desenvolvido pela Uber.
Talvez o senhor queira começar com um simples primeiro, para ver se ele já atende às suas necessidades, antes de implementar algoritmos mais complexos.
Certifique-se de levar em consideração o fato de que seu dataset provavelmente está desequilibrado (mais avaliações positivas do que negativas, no nosso caso).
Importância do recurso
Quando o classificador estiver implementado, o senhor poderá passar para a etapa mais importante: obter insights sobre a importância dos recursos.
No exemplo a seguir, aplicamos o SHAP em nosso modelo (aqui, uma LogisticRegression simples do sklearn):

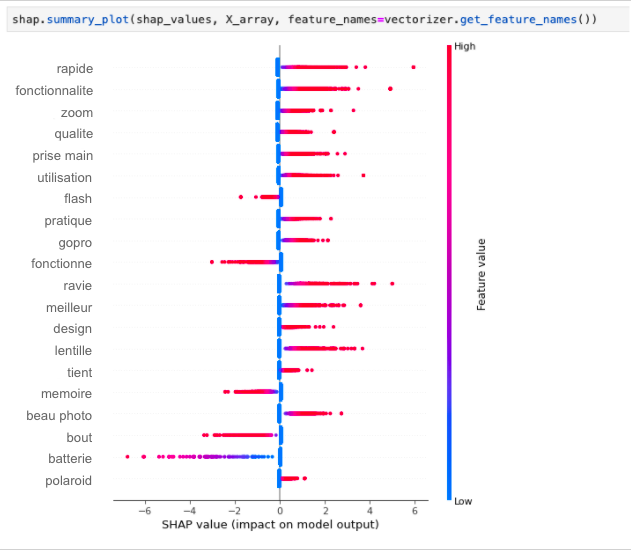
Podemos ver aqui que as funcionalidades, a qualidade da foto e os recursos de zoom têm um impacto realmente positivo na satisfação de nossos clientes, enquanto o flash, o cartão de memória ou as baterias tendem a ter um impacto realmente negativo quando mencionados em uma avaliação.
Palavras como “excellent” (excelente), “perfect” (perfeito) ou “bad” (ruim) foram removidas dessa análise (antes de treinar o classificador), porque serão consideradas como os recursos mais importantes, embora, no nosso caso, queiramos nos concentrar em encontrar insights sobre nossos produtos, e não realmente melhorar o desempenho do classificador.
Veja este caderno para obter um exemplo de como usar o SHAP, com um dataset público.
Impacto dos temas de negócios
Nossa terceira abordagem foi um pouco diferente das anteriores, pois parte de temas relacionados a negócios escolhidos por alguém com conhecimento sobre os produtos.
O objetivo é analisar como os temas comerciais predefinidos afetam as classificações dos produtos, para entender se eles são uma fonte de força ou um problema a ser resolvido.
Determinação de temas
A primeira etapa é classificar as avaliações nas categorias temáticas. O dataset pode ser rotulado manualmente (depois, o senhor pode treinar um classificador se quiser classificar automaticamente as novas avaliações em temas) ou com um modelo baseado em regras.
Em nosso caso, usamos um modelo baseado em regras porque ele já pode trazer bons resultados a baixo custo (por exemplo, se o senhor tiver curiosidade sobre a qualidade de suas lentes ou seus serviços de pós-venda, pode ser simples estabelecer regras que determinarão se uma avaliação menciona isso ou não).
Impacto do tema
Em uma segunda etapa, o senhor pode calcular sua pontuação média global e, em seguida, a pontuação média das avaliações que falam sobre um tema específico.
Ao subtrair as duas pontuações, o senhor pode deduzir o impacto que o tema tem na pontuação global.
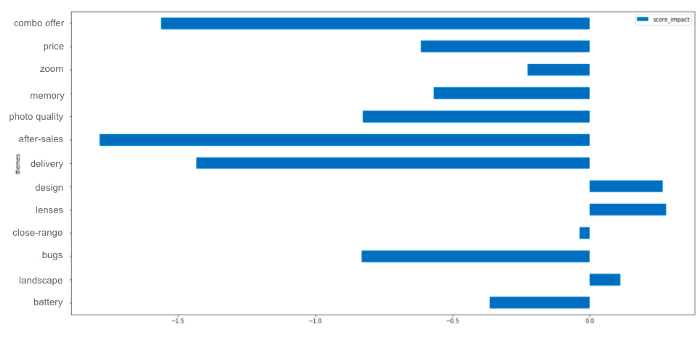
Aqui, devemos nos preocupar com nosso serviço pós-venda porque ele é frequentemente mencionado de forma negativa (embora isso também possa ocorrer porque as pessoas que entram em contato com o serviço pós-venda geralmente têm um problema em primeiro lugar. Por isso, o senhor deve analisar detalhadamente as avaliações que mencionam esse tema, para realmente entender por que ele foi mencionado).
→ Aqui, mais uma vez, o conhecimento do negócio é essencial para que os resultados façam sentido.
Por outro lado, quando nossos designs ou lentes são mencionados, geralmente estão vinculados a uma avaliação com uma pontuação alta, o que pode significar que esse é um de nossos pontos fortes.
Veja este artigo para obter mais visualizações alternativas ao Wordcloud.
Para ir além
Poderíamos ir além e tentar detectar tópicos em nossas avaliações: o senhor poderia usar a biblioteca Top2Vec para extrair tópicos e ver a correlação entre tópicos e pontuações (qualquer biblioteca de modelagem de tópicos funcionará, mas Top2Vec tem a vantagem de fornecer ótimos resultados sem exigir nenhum pré-processamento, nem um número predefinido de tópicos).
Este artigo mostrou como obter insights sobre o cliente a partir de seu data textual usando uma análise pragmática e simples. Muito obrigado pela leitura até agora e não hesite em entrar em contato com o senhor se tiver algum comentário sobre o assunto! O senhor pode visitar nosso blog aqui para saber mais sobre nossos projetos de aprendizado de máquina.
