

Auteur

TL;DR
Comprendre les réactions des clients et connaître vos forces et vos faiblesses est essentiel pour toute entreprise. De nos jours, les entreprises ont accès à un grand nombre d'informations susceptibles de leur fournir ces informations : évaluations de sites web, interactions de chat, transcriptions de conversations, commentaires sur les médias sociaux...
Cet article explique comment vous pouvez rapidement extraire des informations à partir de textes data, en prenant pour exemple les avis de consommateurs. Nous présenterons 3 approches différentes :
thèmes professionnels prédéfinis
(la modélisation thématique pourrait être une quatrième option pour aller plus loin)
Veuillez noter que le data à l'origine de cet article a été généré artificiellement afin de garantir la confidentialité de notre projet initial.

Analyse des avis des clients
Nous essayons d'obtenir des informations à partir des commentaires sur nos produits afin de comprendre quels sont leurs principaux problèmes / principaux points forts. Les produits sont des appareils photo et des accessoires, notés de 1 (mauvais) à 5 (excellent).
Nous utiliserons ici trois approches différentes pour recueillir des informations sur notre data.
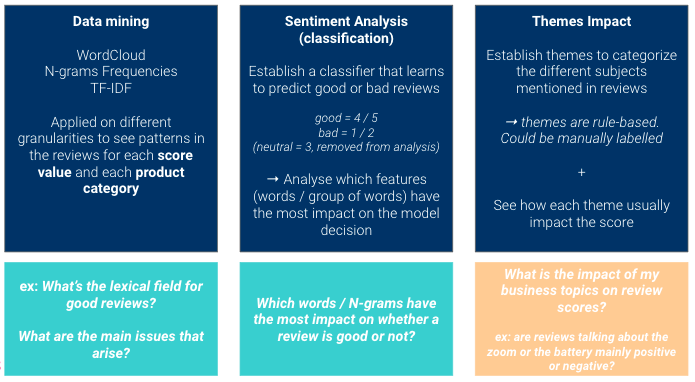
Il s'agit d'avoir des points de vue complémentaires :
Examinez globalement les data que vous avez collectés.
Lorsque vous démarrez un nouveau projet data, la première étape consiste toujours à obtenir une vue d'ensemble du data dont vous disposez (est-il déséquilibré ? y a-t-il suffisamment de data ? y a-t-il beaucoup de valeurs manquantes ?).
Combien de commentaires ai-je pour chaque catégorie de produits ?
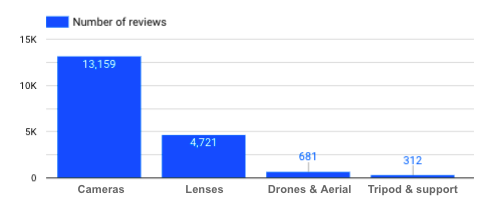
Nombre d'avis par catégorie de produits
→ Le fait qu'il n'y ait pas autant d'avis sur les trépieds doit être gardé à l'esprit lorsque l'on analyse les avis sur cette catégorie spécifique de produits. Plus il y a de data, mieux c'est, afin d'obtenir des conclusions impartiales et pertinentes.
Combien de commentaires puis-je avoir pour chaque note ?
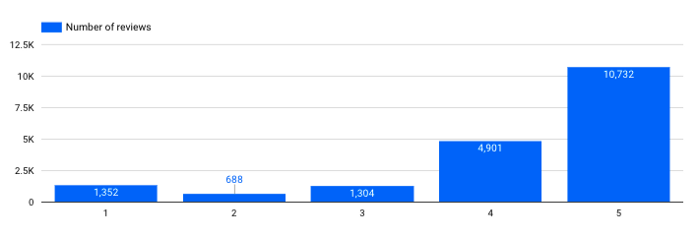
Nombre d'avis par note
→ C'est important. Nous constatons que notre dataset est assez déséquilibré, nous avons beaucoup plus d'avis positifs que d'avis négatifs. Ce type d'information doit être pris en compte lors de l'entraînement de modèles spécialisés (ex : un modèle de classification pour l'analyse des sentiments).
Quelle est la répartition des notes pour chaque catégorie ?
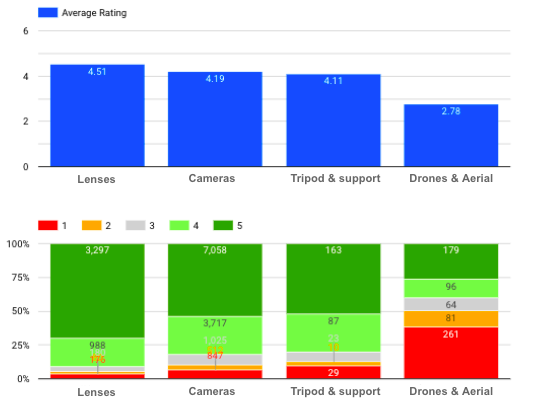
Note moyenne et distribution de chaque catégorie de produits
Nous pouvons voir ici que les objectifs ont la note moyenne la plus élevée, alors qu'il y a beaucoup d'avis négatifs (surtout avec une note de 1) pour les drones et l'imagerie aérienne.
Utiliser la PNL pour comprendre les préoccupations de vos clients
Maintenant, pour comprendre ce qu'il en est des critiques, nous allons mettre en œuvre les différentes approches de la PNL mentionnées précédemment.
Data nettoyage
Avant toute chose, nous devons nettoyer le texte data, afin de le rendre utilisable par les différentes méthodes NLP (cette étape n'est pas toujours nécessaire, en fonction des algorithmes que vous souhaitez utiliser).
Nous avons appliqué les fonctions de prétraitement standard qui étaient pertinentes pour notre data (suppression du HTML, de la ponctuation, des numéros de téléphone, ...), et nous avons mis en place une liste personnalisée de mots vides que nous supprimons des critiques (par exemple, le mot “caméra” n'apporte pas beaucoup d'informations à notre analyse).
Vous trouverez un grand nombre de ces fonctions dans notre NLPretext Dépôt Github.
Extraire des informations en quelques lignes de code
Maintenant que nous avons pour chaque examen :
Nous pouvons commencer par examiner les mots les plus fréquents (mots simples, bi-grammes, tri-grammes...). Il s'agit d'une analyse simple, mais qui vous donne une vision immédiate des thèmes principaux pour chaque score et chaque catégorie.
from collections import Counter
import matplotlib.pyplot as plt
mot d'importationcloud
plt.rcParams[“figure.figsize”] = [16, 9]
def create_ngrams(token_list, nb_elements) :
“””
Créer des n-grammes pour une liste de tokens
Paramètres
----
token_list : liste
liste de chaînes de caractères
nb_éléments :
nombre d'éléments dans le n-gramme
Retours
---
Générateur
générateur de tous les n-grammes
“””
ngrams = zip(*[token_list[index_token :] for index_token in range(nb_elements)])
return (” “.join(ngram) for ngram in ngrams)
def frequent_words(list_words, ngrams_number=1, number_top_words=10) :
“””
Créer des n-grammes pour une liste de tokens
Paramètres
----
ngrams_number : int
number_top_words : int
sortie data Longueur de la trame
Retours
---
DataFrame
Dataframe avec les entités et leurs fréquences.
“””
fréquent = []
si nombre_de_grammes == 1 :
passer
elif ngrams_number >= 2 :
list_words = create_ngrams(list_words, ngrams_number)
autre :
raise ValueError(“le nombre de n-grammes devrait être >= 1”)
counter = Counter(list_words)
frequent = counter.most_common(number_top_words)
retour fréquent
def make_word_cloud(text_ou_counter, stop_words=None) :
if isinstance(text_or_counter, str) :
word_cloud = wordcloud.WordCloud(stopwords=stop_words).generate(text_or_counter)
autre :
si stop_words n'est pas None :
text_or_counter = Counter(word for word in text_or_counter if word not in stop_words)
word_cloud = wordcloud.WordCloud(stopwords=stop_words).generate_from_frequencies(text_or_counter)
plt.imshow(word_cloud)
plt.axis(“off”)
plt.show()
WordCloud
Grâce à ces fonctions, nous pouvons facilement afficher un nuage de mots des mots les plus fréquents, en utilisant les avis sur les appareils photo avec un score entre 1 et 2 :

Affichez ensuite un nuage de mots similaire en utilisant les avis sur les appareils photo avec une note entre 4 et 5 :
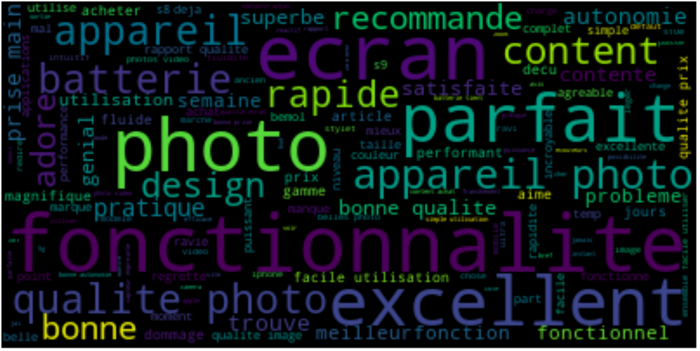
Nous pouvons facilement identifier les principaux points soulevés dans les deux cas.
Nous pourrions faire cet exercice pour chaque produit de notre entreprise, afin de voir la spécificité de chacun et de pouvoir tirer des conclusions à un niveau plus granulaire.
Nombre de N-grammes
Nous pouvons également utiliser la fonction mots_fréquents pour afficher les mots les plus fréquents, les bi-grammes ou les tri-grammes :

Pour aller plus loin, vous pourriez ensuite mettre en place une fonction affichant les critiques associées à un mot-clé, afin de zoomer sur les n-grammes que vous jugez intéressants. Vous pourriez également examiner les n-grammes ayant les taux les plus élevés / les plus bas. TF-IDF (facile à calculer avec le sklearn ), car il vous permet de voir les mots importants sur la base d'une métrique différente de celle d'un simple compteur de fréquence.
Analyse des sentiments
Nous passons ensuite à une approche d'analyse des sentiments. En général, elle est utilisée pour prédire si un texte est positif ou négatif. Dans notre cas, nous disposons déjà de cette information (la note entre 1 et 5 nous donne le sentiment qui se cache derrière l'avis). Mais l'entraînement d'un modèle pour prédire cette note nous aidera à trouver les mots (caractéristiques) qui sont essentiels pour les clients.
Ce que nous pouvons faire, c'est Entraînez un classificateur d'analyse des sentiments sur ce data, et utilisez ensuite des bibliothèques telles que SHAP ou LIME pour comprendre le fonctionnement du système. qui comprend (= mots) ont le plus d'impact qu'un avis soit classé comme positif ou négatif.
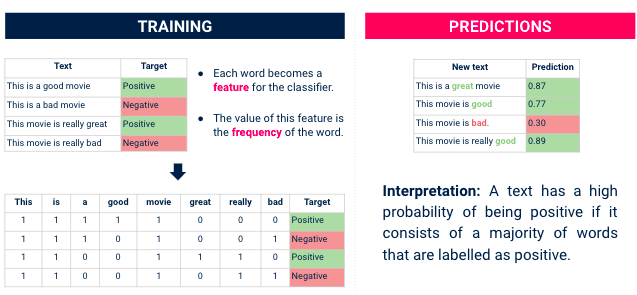
Classificateur
Pour entraîner un classificateur, vous disposez d'un grand nombre d'algorithmes possibles, allant de la régression logistique classique de sklearn aux modèles ULM-fit (voir ce carnet pour former un modèle ULM-fit français, et cet article pour en savoir plus sur ULM-fit) ou le classificateur Ludwig développé par Uber.
Vous pouvez commencer par un algorithme simple, pour voir s'il répond déjà à vos besoins, avant de mettre en place des algorithmes plus complexes.
Veillez à prendre en considération le fait que votre dataset est probablement déséquilibré (plus d'avis positifs que négatifs, dans notre cas).
Importance de la caractéristique
Une fois votre classificateur mis en œuvre, vous pouvez passer à l'étape la plus importante : obtenir des informations sur l'importance des caractéristiques.
Dans l'exemple suivant, nous appliquons SHAP à notre modèle (ici, une simple régression logistique sklearn) :

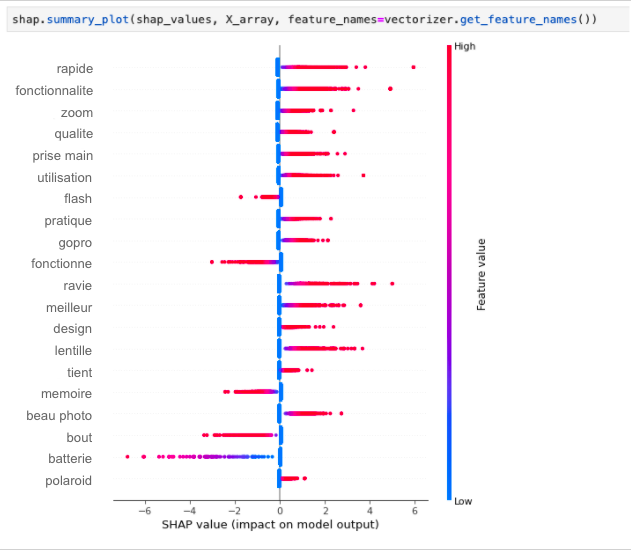
Nous pouvons constater que les fonctionnalités, la qualité des photos et les fonctions de zoom ont un impact très positif sur la satisfaction de nos clients, tandis que le flash, la carte mémoire ou les piles ont tendance à avoir un impact très négatif lorsqu'ils sont mentionnés dans un avis.
Les mots tels que “excellent”, “parfait” ou “mauvais” ont été supprimés de cette analyse (avant l'entraînement du classificateur), car ils seront considérés comme les caractéristiques les plus importantes, alors que dans notre cas, nous voulons nous concentrer sur la recherche d'informations sur nos produits, et non sur l'amélioration des performances de notre classificateur.
Voir ce carnet pour un exemple d'utilisation de SHAP, avec un dataset public.
Impact des thèmes commerciaux
Notre troisième approche était un peu différente des précédentes, car elle partait de thèmes liés à l'entreprise, choisis par une personne connaissant bien les produits.
Il s'agit d'analyser l'impact des thèmes commerciaux prédéfinis sur l'évaluation des produits, afin de comprendre s'ils sont une source de force ou un problème à résoudre.
Détermination des thèmes
La première étape consiste à classer les commentaires dans les catégories thématiques. Vous pouvez étiqueter votre dataset manuellement (vous pourrez ensuite former un classificateur si vous souhaitez classer automatiquement les nouvelles critiques dans les thèmes) ou à l'aide d'un modèle basé sur des règles.
Dans notre cas, nous avons utilisé un modèle basé sur des règles parce qu'il peut déjà donner de bons résultats à peu de frais (par exemple : si vous êtes curieux de la qualité de vos lentilles ou de vos services après-vente, il peut être simple d'établir des règles qui détermineront si un avis mentionne ces éléments ou non).
Impact du thème
Dans un deuxième temps, vous pouvez calculer votre note moyenne globale, puis la note moyenne des avis traitant d'un thème spécifique.
En soustrayant les deux scores, vous pouvez déduire l'impact de votre thème sur votre score global.
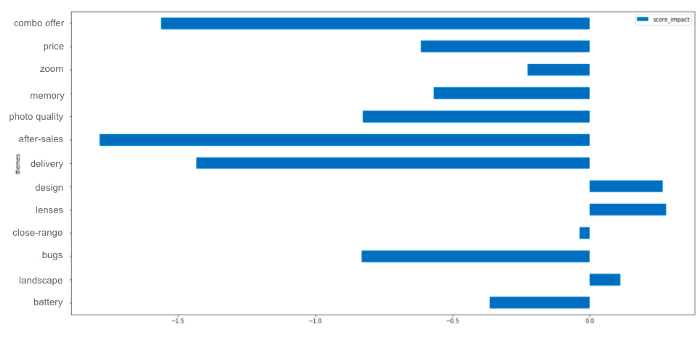
Nous devrions ici nous préoccuper de notre service après-vente car il est souvent mentionné de manière négative (bien que cela puisse également être dû au fait que les personnes qui contactent le service après-vente ont souvent eu un problème au départ. C'est pourquoi vous devriez examiner en détail les avis mentionnant ce thème, pour vraiment comprendre pourquoi il a été abordé).
→ Là encore, la connaissance de l'entreprise est essentielle pour donner un sens à vos résultats.
En revanche, lorsque nos designs ou nos lentilles sont mentionnés, c'est souvent en lien avec un avis bien noté, ce qui peut signifier qu'il s'agit de l'un de nos points forts.
Voir cet article pour d'autres visualisations alternatives à Wordcloud.
Pour aller plus loin
Nous pourrions aller plus loin et essayer de détecter des thèmes dans nos commentaires : vous pourriez utiliser la bibliothèque Top2Vec pour extraire des thèmes et voir la corrélation entre les thèmes et les scores (n'importe quelle bibliothèque de modélisation de thèmes fonctionnera, mais Top2Vec a l'avantage de donner d'excellents résultats sans nécessiter de prétraitement, ni de nombre prédéfini de sujets).
Cet article a montré comment obtenir des informations sur les clients à partir de votre data textuel en utilisant une analyse pragmatique et simple. Merci d'avoir lu cet article et n'hésitez pas à nous contacter si vous avez des commentaires sur le sujet ! Vous pouvez visiter notre blog ici pour en savoir plus sur nos projets d'apprentissage automatique.
