

Author

TL;DR
Understanding customers’ feedback and knowing what your strengths and weaknesses are is key to any business. Nowadays, companies have access to a lot of information that could give them those insights: website reviews, chat interactions, conversations transcripts, social media comments…
This article explains how you can quickly extract insights from textual data, leveraging consumers’ reviews as an example. We will present 3 different approaches:
predefined business themes
(topic modeling could be a fourth option to go further)
Please note the data behind this article was artificially generated to ensure confidentiality of our initial project.

Customer Reviews Analysis
We are trying to find insights from our products reviews in order to understand what are their main issues / main strengths. Products are camera devices and accessories, rated from 1 (bad) to 5 (excellent).
We will be using three different approaches here, to gather insights from our data.
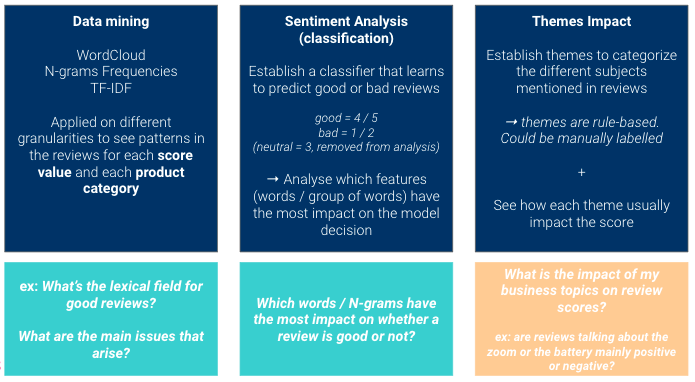
The point is to have complementary views:
Get a global look at the data you have collected
Whenever you’re starting a new data project, the first step is always to get the global picture on the data you have (is it imbalanced? is there enough data? are there lot of missing values?).
How many reviews do I have for each product category?
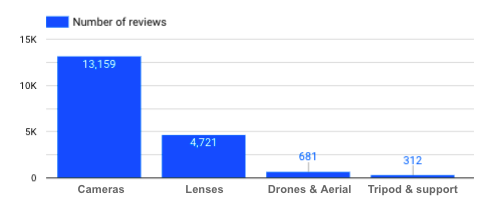
Number of reviews per product category
→ The fact that there are not as many Tripod reviews should be kept in mind if we analyze reviews for this specific category of product. The more data we have, the better, in order to have unbiased and relevant conclusions.
How many reviews do I have for each rating?
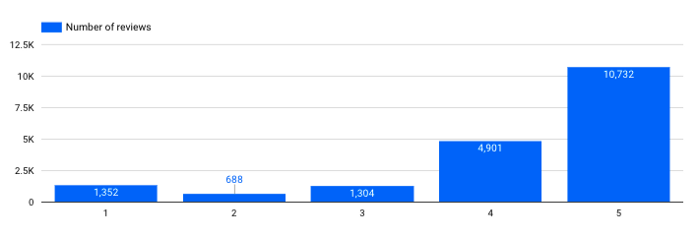
Number of reviews per score
→ This is important. We see that our dataset is quite imbalanced, we have a lot more positive reviews than negative reviews. This kind of information needs to be taken into account when training dedicated models (ex: a classification model for sentiment analysis).
What’s the rating distribution of each category?
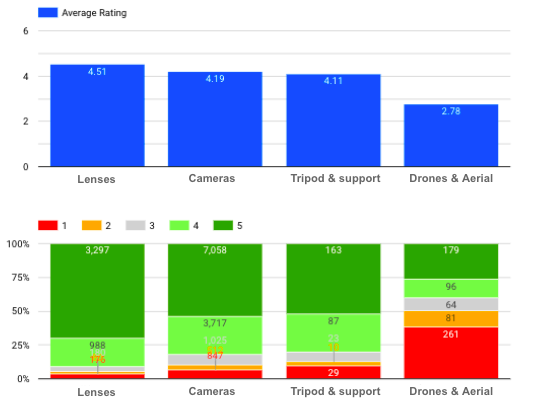
Average rating & distribution of each product category
We can see here that Lenses have the highest average rating, while there are a lot of negative reviews (especially with a score of 1) for Drones and Aerial Imaging.
Using NLP to understand your customers’ concerns
Now, to understand what the reviews are about, we will implement the different NLP approaches mentioned previously.
Data cleaning
Before doing anything else, we need to clean the text data, to make it usable by the different NLP methods (this step is not always required, depending on the algorithms you want to use).
We applied standard pre-processing functions that were relevant to our data (removing HTML, punctuation, phone numbers, …), and we implemented a custom list of stop words that we remove from reviews (for instance the word “camera” does not bring that much information to our analysis).
You can find a lot of these functions in our NLPretext Github repository.
Mining insights in a few lines of code
Now that we have for each review:
We can start by simply looking at our most frequent words (single words, bi-grams, tri-grams…). It’s a simple analysis, but it gives you an immediate vision of what the main topics are for each score and category.
from collections import Counter
import matplotlib.pyplot as plt
import wordcloud
plt.rcParams[“figure.figsize”] = [16, 9]
def create_ngrams(token_list, nb_elements):
“””
Create n-grams for list of tokens
Parameters
———-
token_list : list
list of strings
nb_elements :
number of elements in the n-gram
Returns
——-
Generator
generator of all n-grams
“””
ngrams = zip(*[token_list[index_token:] for index_token in range(nb_elements)])
return (” “.join(ngram) for ngram in ngrams)
def frequent_words(list_words, ngrams_number=1, number_top_words=10):
“””
Create n-grams for list of tokens
Parameters
———-
ngrams_number : int
number_top_words : int
output dataframe length
Returns
——-
DataFrame
Dataframe with the entities and their frequencies.
“””
frequent = []
if ngrams_number == 1:
pass
elif ngrams_number >= 2:
list_words = create_ngrams(list_words, ngrams_number)
else:
raise ValueError(“number of n-grams should be >= 1”)
counter = Counter(list_words)
frequent = counter.most_common(number_top_words)
return frequent
def make_word_cloud(text_or_counter, stop_words=None):
if isinstance(text_or_counter, str):
word_cloud = wordcloud.WordCloud(stopwords=stop_words).generate(text_or_counter)
else:
if stop_words is not None:
text_or_counter = Counter(word for word in text_or_counter if word not in stop_words)
word_cloud = wordcloud.WordCloud(stopwords=stop_words).generate_from_frequencies(text_or_counter)
plt.imshow(word_cloud)
plt.axis(“off”)
plt.show()
WordCloud
Leveraging these functions, we can easily display a Word Cloud of most frequent words, using reviews for Cameras with a score between 1 and 2:

Then display a similar Word Cloud using reviews for Cameras with a score between 4 and 5 :
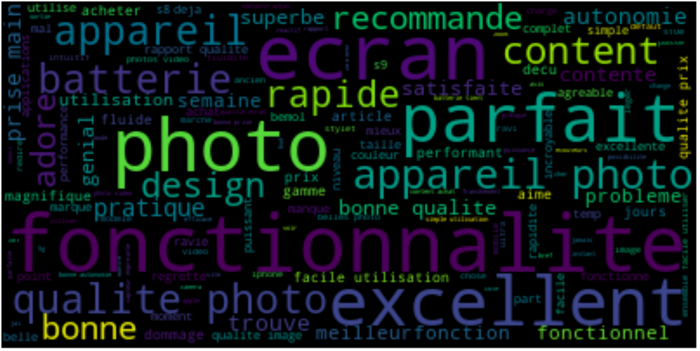
We can easily identify the main points brought up in both cases.
We could do this exercise for each product our company has, in order to see the specificity of each and be able to draw conclusions at a more granular level.
N-grams Count
We can also use the frequent_words function to display the most frequent words, bi-grams or tri-grams:

To go further, you could then put in place a function displaying the reviews associated with a keyword, in order to zoom in on n-grams you find interesting. You could also look at n-grams with the highest / lowest TF-IDF (easy to compute with the sklearn library), since it allows you to see important words based on a different metric than a simple frequency counter.
Sentiment Analysis
Next, we move on to a sentiment analysis approach. Usually, it is used to predict if a text is positive or negative. In our case, we already have this information (the score between 1 and 5 gives us the sentiment behind the review). But training a model to predict this rating will help us find which words (features) are key for customers.
What we can do is to train a sentiment analysis classifier on this data, and then use libraries like SHAP or LIME to understand which features (= words) have the most impact on a review being classified as positive or negative.
Classifier
To train a classifier, you have a lot of possible algorithms you can use, ranging from the classic sklearn LogisticRegression, to ULM-fit models (see this notebook to train a French ULM-fit model, and this article to understand more about ULM-fit) or the Ludwig classifier developed by Uber.
You might want to start with a simple one first, to see if it already answers your needs, before putting in place more complex algorithms.
Make sure to take into consideration the fact that your dataset is probably imbalanced (more positive than negative reviews, in our case).
Feature importance
Once your classifier is implemented, you can move on to the most important step: getting insights from features importance.
In the following example we apply SHAP on our model (here, a simple sklearn LogisticRegression):

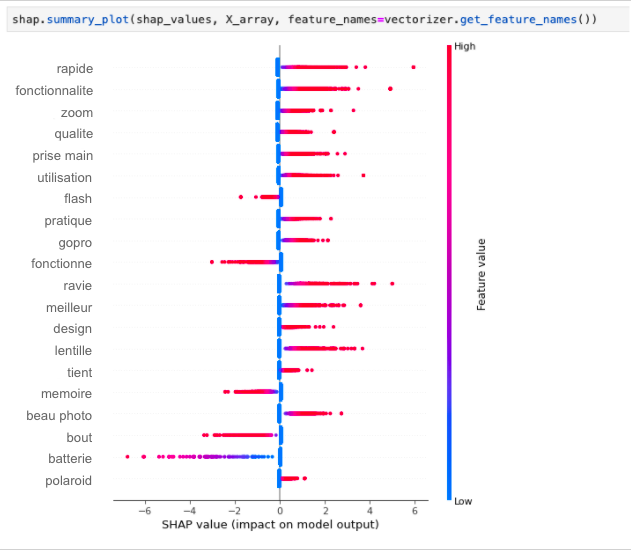
We can see here that the functionalities, photo quality, and zoom features have a really positive impact on our clients’ satisfaction, while the flash, memory card or batteries tend to have a really negative impact when mentioned in a review.
Words like “excellent”, “perfect” or “bad” were removed from this analysis (before training the classifier), because they will be considered as the most important features, while in our case we want to focus on finding insights about our products, not really improve our classifier performance.
See this notebook for an example on how to use SHAP, with a public dataset.
Business themes impact
Our third approach was kind of different from the previous ones, as it starts from business-related themes chosen by someone knowledgeable when it comes to the products.
The point is to analyse how predefined business themes impact products ratings, to understand if they are a source of strength or an issue to solve.
Determining themes
The first step is to classify the reviews into the thematic categories. Either by labelling your dataset manually (then you could train a classifier if you want to automatically classify new review into themes), or with a rule-based model.
In our case we used a rule-based model because it can already bring up good results at low cost (e.g: if you’re curious about your lenses quality or your after-sales services, it can be simple to establish rules that will determine if a review mention those or not).
Theme impact
In a second step you can compute your global average score, then the average score of reviews talking about a specific theme.
By subtracting both scores, you can deduce the impact your theme has on your global score.
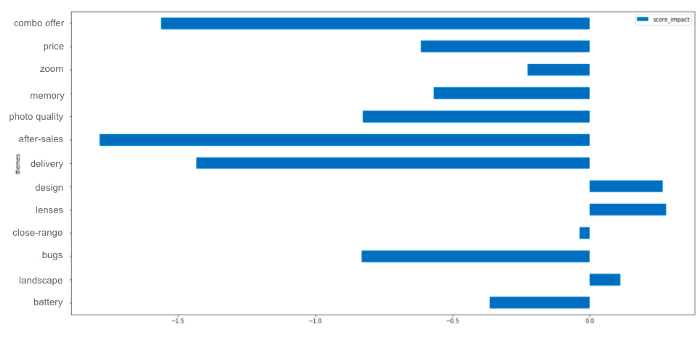
We should here worry about our after-sales service because it is often mentioned in a negative way (though it could also be because people contacting the after-sales service often had an issue in the first place. Which is why, you should then look into detail at the reviews mentioning this theme, to really understand why it was brought up).
→ Here again, business knowledge is essential to make sense of your results.
On the other hand, when our designs or lenses are mentioned, it’s often linked to a review with a high score, which could mean it’s one of our strengths.
See this article for more alternative visualisations to Wordcloud.
To go further
We could go further and try to detect topics in our reviews: you could use the Top2Vec library to extract topics and see the correlation between topics and scores (any topic modeling library will work, but Top2Vec has the advantage of giving great results while not requiring any preprocessing, nor a pre-defined number of topics).
This article showed how to gain customer insights from your textual data by using a pragmatic and simple analysis. Thanks a lot for reading up to now and don’t hesitate to reach out if you have any comment on the topic! You can visit our blog here to learn more about our machine learning projects.
