

Auteur

TL;DR
Feedback van klanten begrijpen en weten wat uw sterke en zwakke punten zijn, is de sleutel tot elk bedrijf. Tegenwoordig hebben bedrijven toegang tot veel informatie die hen deze inzichten kan geven: websitebeoordelingen, chatinteracties, gesprekstranscripties, reacties op sociale media...
In dit artikel wordt uitgelegd hoe u snel inzichten kunt halen uit tekstuele data, met de beoordelingen van consumenten als voorbeeld. We presenteren 3 verschillende benaderingen:
voorgedefinieerde bedrijfsthema's
(onderwerpmodellering zou een vierde optie kunnen zijn om verder te gaan)
Let op: de data achter dit artikel is kunstmatig gegenereerd om de vertrouwelijkheid van ons oorspronkelijke project te waarborgen.

Analyse van klantbeoordelingen
We proberen inzicht te krijgen in de beoordelingen van onze producten om te begrijpen wat hun belangrijkste problemen / sterke punten zijn. De producten zijn camera-apparaten en accessoires, beoordeeld van 1 (slecht) tot 5 (uitstekend).
We zullen hier drie verschillende benaderingen gebruiken om inzichten uit onze data te verzamelen.
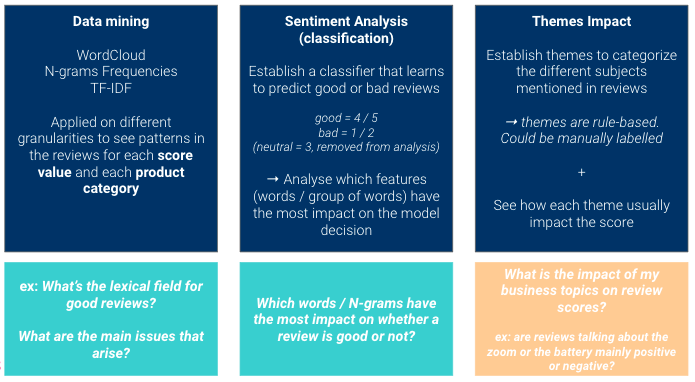
Het punt is om complementaire standpunten te hebben:
Bekijk de verzamelde data in zijn geheel
Wanneer u een nieuw data-project start, is de eerste stap altijd om een globaal beeld te krijgen van de data die u hebt (is het onevenwichtig? is er genoeg data? zijn er veel ontbrekende waarden?).
Hoeveel beoordelingen heb ik voor elke productcategorie?
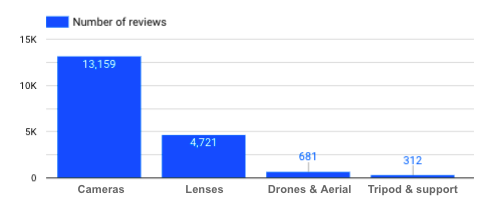
Aantal beoordelingen per productcategorie
→ Het feit dat er niet zoveel reviews over statieven zijn, moeten we in gedachten houden als we de reviews voor deze specifieke productcategorie analyseren. Hoe meer data we hebben, hoe beter, zodat we onbevooroordeelde en relevante conclusies kunnen trekken.
Hoeveel beoordelingen heb ik voor elke classificatie?
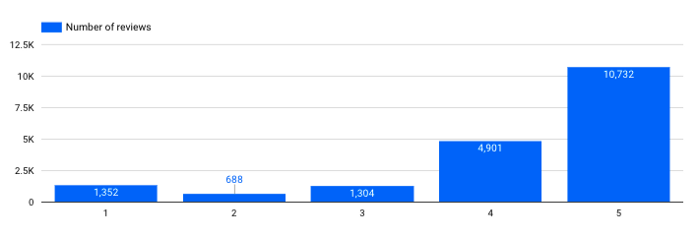
Aantal beoordelingen per score
→ Dit is belangrijk. We zien dat onze dataset behoorlijk onevenwichtig is, we hebben veel meer positieve dan negatieve beoordelingen. Met dit soort informatie moet rekening worden gehouden bij het trainen van speciale modellen (bijv. een classificatiemodel voor sentimentanalyse).
Wat is de ratingverdeling van elke categorie?
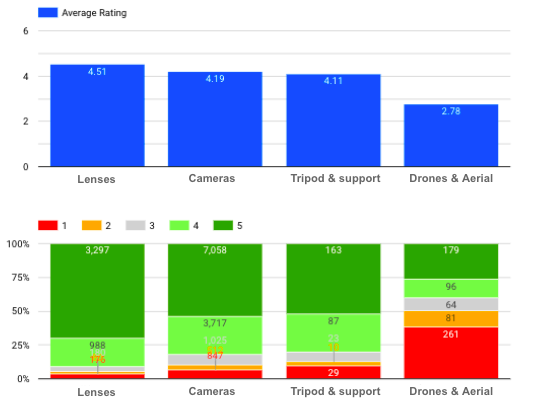
Gemiddelde waardering & verdeling van elke productcategorie
We kunnen hier zien dat Lenzen de hoogste gemiddelde waardering hebben, terwijl er veel negatieve beoordelingen (vooral met een score van 1) zijn voor Drones en Aerial Imaging.
NLP gebruiken om de zorgen van uw klanten te begrijpen
Om nu te begrijpen waar de beoordelingen over gaan, zullen we de verschillende NLP-benaderingen implementeren die eerder zijn genoemd.
Data schoonmaken
Voordat we iets anders doen, moeten we de tekst data opschonen, zodat deze bruikbaar wordt voor de verschillende NLP-methoden (deze stap is niet altijd nodig, afhankelijk van de algoritmen die u wilt gebruiken).
We hebben standaard voorbewerkingsfuncties toegepast die relevant waren voor onze data (verwijderen van HTML, interpunctie, telefoonnummers, ...), en we hebben een aangepaste lijst met stopwoorden geïmplementeerd die we uit beoordelingen verwijderen (het woord “camera” levert bijvoorbeeld niet zoveel informatie op voor onze analyse).
U kunt veel van deze functies vinden in onze NLPretext Github-repository.
Inzichten winnen in een paar regels code
Nu hebben we voor elke beoordeling:
We kunnen beginnen met simpelweg te kijken naar onze meest frequente woorden (losse woorden, bi-grammen, tri-grammen...). Het is een eenvoudige analyse, maar het geeft u meteen een beeld van wat de belangrijkste onderwerpen zijn voor elke score en categorie.
van verzamelingen importeer Teller
importeer matplotlib.pyplot als plt
woordcloud importeren
plt.rcParams[“figure.figsize”] = [16, 9]
def create_ngrams(token_list, nb_elements):
“””
Maak n-grammen voor lijst met tokens
Parameters
----
token_lijst : lijst
lijst van tekenreeksen
nb_elementen :
aantal elementen in het n-gram
Geeft als resultaat
---
Generator
generator van alle n-grammen
“””
ngrammen = zip(*[token_list[index_token:] for index_token in range(nb_elements)])
return (” “.join(ngram) voor ngram in ngrams)
def frequent_words(list_words, ngrams_number=1, number_top_words=10):
“””
Maak n-grammen voor lijst met tokens
Parameters
----
ngrams_number : int
aantal_top_woorden : int
uitgang dataframe lengte
Geeft als resultaat
---
DataFrame
Dataframe met de entiteiten en hun frequenties.
“””
frequent = []
als ngrams_number == 1:
pas
elif ngrams_number >= 2:
lijst_woorden = create_ngrams(lijst_woorden, ngrams_aantal)
anders:
raise ValueError(“aantal n-grammen moet >= 1 zijn”)
teller = teller(lijst_woorden)
frequent = counter.most_common(number_top_words)
regelmatig terugkeren
def make_word_cloud(text_or_counter, stop_words=None):
if isinstance(text_or_counter, str):
woord_cloud = woordcloud.WordCloud(stopwoorden=stop_woorden).genereren(tekst_of_teller)
anders:
als stop_words geen is:
tekst_of_teller = Teller(woord voor woord in tekst_of_teller als woord niet in stop_woorden zit)
word_cloud = wordcloud.WordCloud(stopwoorden=stop_woorden).generate_from_frequencies(text_of_counter)
plt.imshow(word_cloud)
plt.as(“uit”)
plt.show()
WordCloud
Door gebruik te maken van deze functies, kunnen we gemakkelijk een Word Cloud weergeven van de meest voorkomende woorden, aan de hand van beoordelingen voor Camera's met een score tussen 1 en 2:

Geef vervolgens een soortgelijke Word Cloud weer met beoordelingen voor Camera's met een score tussen 4 en 5 :
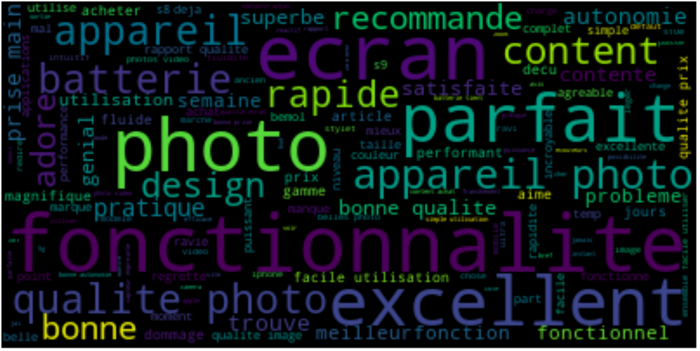
We kunnen de belangrijkste punten die in beide gevallen naar voren worden gebracht gemakkelijk identificeren.
We zouden deze oefening kunnen doen voor elk product dat ons bedrijf heeft, om de specificiteit van elk product te bekijken en conclusies te kunnen trekken op een meer gedetailleerd niveau.
N-grammen Telling
We kunnen ook de frequente_woorden functie om de meest voorkomende woorden, bi-grammen of tri-grammen weer te geven:

Om verder te gaan, zou u dan een functie kunnen instellen die de beoordelingen weergeeft die bij een trefwoord horen, zodat u kunt inzoomen op n-grammen die u interessant vindt. U zou ook kunnen kijken naar n-grammen met de hoogste / laagste TF-IDF (gemakkelijk te berekenen met de sklearn bibliotheek), omdat u hiermee belangrijke woorden kunt zien op basis van een andere metriek dan een eenvoudige frequentieteller.
Sentimentanalyse
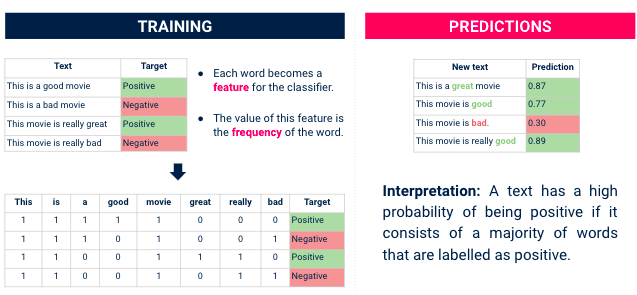
Vervolgens gaan we over naar een benadering voor sentimentanalyse. Meestal wordt deze gebruikt om te voorspellen of een tekst positief of negatief is. In ons geval hebben we deze informatie al (de score tussen 1 en 5 geeft ons het sentiment achter de recensie). Maar door een model te trainen om deze beoordeling te voorspellen, kunnen we ontdekken welke woorden (kenmerken) belangrijk zijn voor klanten.
Wat we kunnen doen is een classifier voor sentimentanalyse trainen op deze data, en gebruik dan bibliotheken zoals SHAP of LIME om het volgende te begrijpen met (= woorden) de meeste impact hebben op een beoordeling die als positief of negatief wordt geclassificeerd.
Classificeerder
Om een classifier te trainen, hebt u een heleboel mogelijke algoritmen die u kunt gebruiken, van de klassieke sklearn LogisticRegression tot ULM-fit modellen (zie dit notitieboekje om een Frans ULM-fit model te trainen, en dit artikel om meer te begrijpen over ULM-fit) of de Ludwig classificator ontwikkeld door Uber.
Misschien wilt u eerst met een eenvoudige beginnen, om te zien of deze al aan uw behoeften voldoet, voordat u complexere algoritmen installeert.
Houd er rekening mee dat uw dataset waarschijnlijk onevenwichtig is (meer positieve dan negatieve beoordelingen, in ons geval).
Belang van kenmerken
Zodra uw classifier geïmplementeerd is, kunt u verdergaan met de belangrijkste stap: inzichten krijgen uit het belang van kenmerken.
In het volgende voorbeeld passen we SHAP toe op ons model (hier een eenvoudige sklearn LogisticRegression):

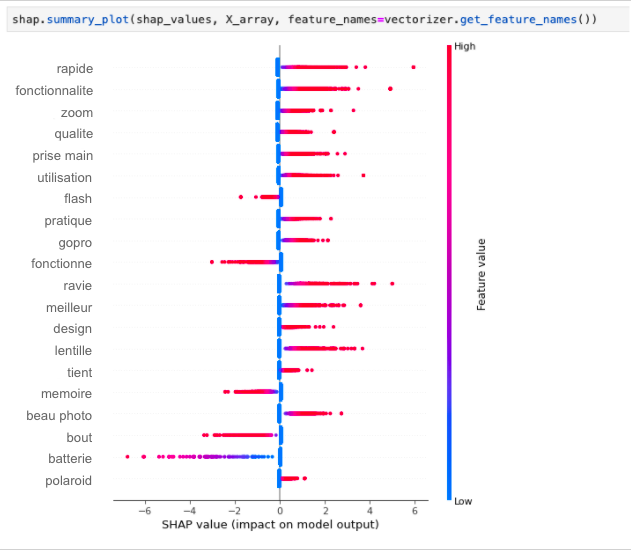
We kunnen hier zien dat de functionaliteiten, fotokwaliteit en zoomfuncties een echt positieve invloed hebben op de tevredenheid van onze klanten, terwijl de flitser, geheugenkaart of batterijen een echt negatieve invloed hebben wanneer ze in een recensie worden genoemd.
Woorden als “uitstekend”, “perfect” of “slecht” werden uit deze analyse verwijderd (voordat de classifier werd getraind), omdat deze als de belangrijkste kenmerken worden beschouwd, terwijl we ons in ons geval willen richten op het vinden van inzichten over onze producten, niet op het verbeteren van de prestaties van onze classifier.
Zie dit notitieboekje voor een voorbeeld van het gebruik van SHAP, met een openbare dataset.
Impact op bedrijfsthema's
Onze derde benadering was een beetje anders dan de vorige, omdat deze uitgaat van bedrijfsgerelateerde thema's die gekozen zijn door iemand met verstand van producten.
Het punt is om te analyseren hoe vooraf gedefinieerde bedrijfsthema's van invloed zijn op productratings, om te begrijpen of ze een bron van kracht zijn of een probleem dat opgelost moet worden.
Thema's bepalen
De eerste stap is het classificeren van de beoordelingen in de thematische categorieën. U kunt dit doen door uw dataset handmatig te labelen (daarna kunt u een classifier trainen als u nieuwe recensies automatisch in thema's wilt indelen), of met een op regels gebaseerd model.
In ons geval hebben we een op regels gebaseerd model gebruikt omdat dit al goede resultaten kan opleveren tegen lage kosten (bijv. als u benieuwd bent naar de kwaliteit van uw lenzen of uw after-sales service, dan kan het eenvoudig zijn om regels op te stellen die bepalen of een recensie deze wel of niet vermeldt).
Thema-impact
In een tweede stap kunt u uw globale gemiddelde score berekenen, en vervolgens de gemiddelde score van beoordelingen over een specifiek thema.
Door beide scores van elkaar af te trekken, kunt u de invloed van uw thema op uw totaalscore afleiden.
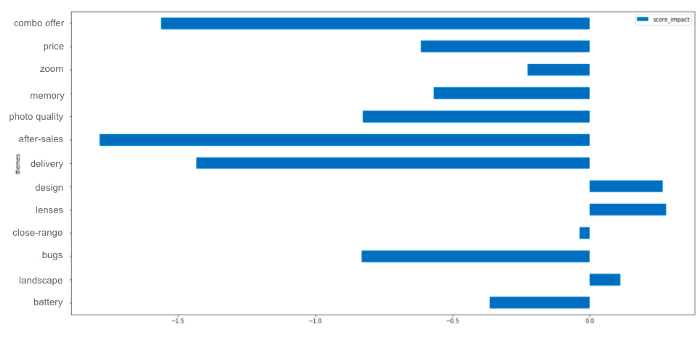
We moeten ons hier zorgen maken over onze after-sales service, omdat deze vaak op een negatieve manier genoemd wordt (hoewel het ook kan komen doordat mensen die contact opnemen met de after-sales service vaak al een probleem hadden. Daarom moet u in detail kijken naar de beoordelingen waarin dit thema wordt genoemd, om echt te begrijpen waarom het naar voren werd gebracht).
→ Ook hier is kennis van zaken essentieel om uw resultaten te begrijpen.
Aan de andere kant, wanneer onze ontwerpen of lenzen worden genoemd, is dat vaak gekoppeld aan een recensie met een hoge score, wat zou kunnen betekenen dat het een van onze sterke punten is.
Zie dit artikel voor meer alternatieve visualisaties voor Wordcloud.
Om verder te gaan
We zouden verder kunnen gaan en proberen om onderwerpen in onze beoordelingen te detecteren: u zou de Top2Vec-bibliotheek kunnen gebruiken om onderwerpen te extraheren en de correlatie tussen onderwerpen en scores te bekijken (elke bibliotheek voor onderwerpmodellering zal werken, maar Top2Vec heeft het voordeel dat het geweldige resultaten oplevert zonder dat er enige voorbewerking of een vooraf gedefinieerd aantal onderwerpen nodig is).
Dit artikel liet zien hoe u klantinzichten kunt verkrijgen uit uw tekstuele data door een pragmatische en eenvoudige analyse te gebruiken. Bedankt voor het lezen tot nu toe en aarzel niet om contact met ons op te nemen als u opmerkingen over dit onderwerp hebt! U kunt onze blog bezoeken hier voor meer informatie over onze projecten voor machinaal leren.
