

Autor

TL;DR
Comprender las opiniones de los clientes y saber cuáles son sus puntos fuertes y débiles es clave para cualquier negocio. Hoy en día, las empresas tienen acceso a mucha información que podría darles esos puntos de vista: reseñas de sitios web, interacciones en chats, transcripciones de conversaciones, comentarios en redes sociales...
Este artículo explica cómo puede extraer rápidamente información de data textual, aprovechando las reseñas de los consumidores como ejemplo. Presentaremos 3 enfoques diferentes:
temas empresariales predefinidos
(el modelado temático podría ser una cuarta opción para ir más lejos)
Tenga en cuenta que el data de este artículo se generó artificialmente para garantizar la confidencialidad de nuestro proyecto inicial.

Análisis de las opiniones de los clientes
Intentamos obtener información de las reseñas de nuestros productos para comprender cuáles son sus principales problemas / puntos fuertes. Los productos son dispositivos y accesorios para cámaras, calificados de 1 (malo) a 5 (excelente).
Aquí utilizaremos tres enfoques diferentes para obtener información de nuestro data.
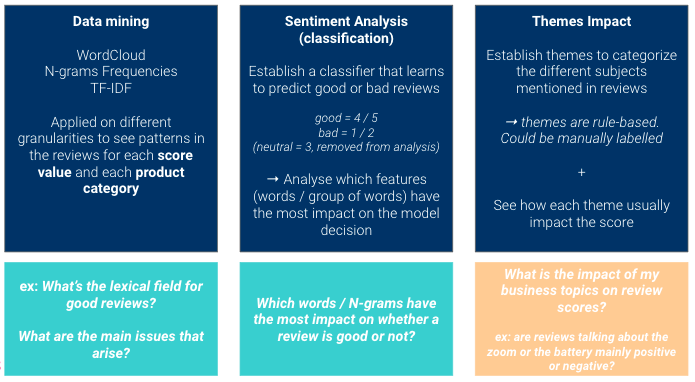
Se trata de tener puntos de vista complementarios:
Eche un vistazo global al data que ha recogido
Siempre que vaya a iniciar un nuevo proyecto de data, el primer paso es obtener la imagen global del data que tiene (¿está desequilibrado? ¿hay suficientes data? ¿faltan muchos valores?).
¿Cuántas reseñas tengo para cada categoría de producto?
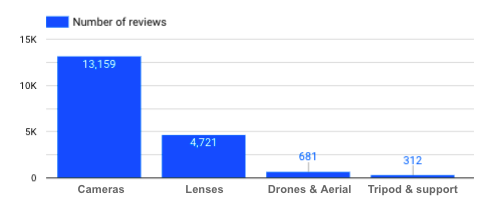
Número de reseñas por categoría de producto
→ El hecho de que no haya tantas reseñas sobre trípodes debe tenerse en cuenta si analizamos las reseñas para esta categoría específica de producto. Cuantas más data tengamos, mejor, para poder tener conclusiones imparciales y relevantes.
¿Cuántas reseñas tengo para cada clasificación?
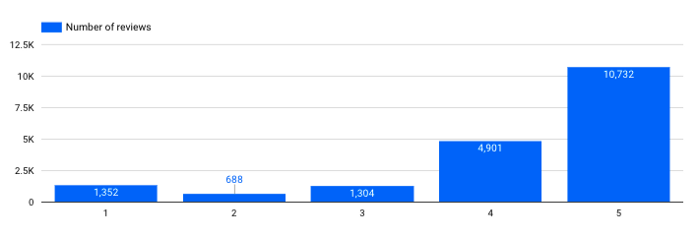
Número de revisiones por puntuación
→ Esto es importante. Vemos que nuestro conjunto data está bastante desequilibrado, tenemos muchas más reseñas positivas que negativas. Este tipo de información debe tenerse en cuenta a la hora de entrenar modelos específicos (por ejemplo, un modelo de clasificación para el análisis del sentimiento).
¿Cuál es la distribución de la puntuación de cada categoría?
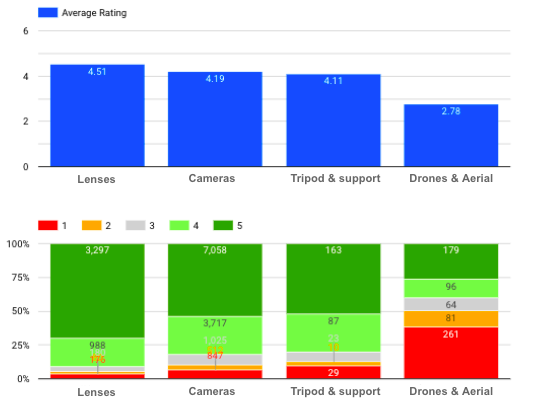
Valoración media y distribución de cada categoría de productos
Podemos ver aquí que las Lentes tienen la valoración media más alta, mientras que hay muchas opiniones negativas (especialmente con una puntuación de 1) para Drones e Imágenes aéreas.
Utilizar la PNL para comprender las preocupaciones de sus clientes
Ahora, para entender de qué tratan las críticas, pondremos en práctica los distintos enfoques de la PNL mencionados anteriormente.
Data limpieza
Antes de hacer nada, tenemos que limpiar el texto data, para hacerlo utilizable por los distintos métodos de PNL (este paso no siempre es necesario, dependiendo de los algoritmos que se quieran utilizar).
Aplicamos funciones estándar de preprocesamiento que eran relevantes para nuestro data (eliminación de HTML, puntuación, números de teléfono, ...), e implementamos una lista personalizada de palabras de parada que eliminamos de las reseñas (por ejemplo, la palabra “cámara” no aporta tanta información a nuestro análisis).
Puede encontrar muchas de estas funciones en nuestro NLPretext Repositorio Github.
Perspectivas mineras en unas pocas líneas de código
Ahora que tenemos para cada revisión:
Podemos empezar por fijarnos simplemente en nuestras palabras más frecuentes (palabras sueltas, bi-gramas, tri-gramas...). Es un análisis sencillo, pero le ofrece una visión inmediata de cuáles son los temas principales para cada puntuación y categoría.
from colecciones import Contador
import matplotlib.pyplot as plt
importar palabracloud
plt.rcParams[“figure.figsize”] = [16, 9]
def crear_ngramas(lista_token, nb_elementos):
“””
Crear n-gramas para la lista de tokens
Parámetros
----
lista_token : lista
lista de cadenas
nb_elements :
número de elementos del n-grama
Devuelve
---
Generador
generador de todos los n-gramas
“””
ngrams = zip(*[lista_token[index_token:] for index_token in range(nb_elements)])
return (” “.join(ngram) for ngram in ngrams)
def palabras_frecuentes(lista_palabras, ngramas_número=1, número_top_palabras=10):
“””
Crear n-gramas para la lista de tokens
Parámetros
----
número_ngramas : int
numero_top_palabras : int
salida dataLongitud de trama
Devuelve
---
DataFrame
Dataframe con las entidades y sus frecuencias.
“””
frecuentes = []
si número_ngramas == 1:
pase
elif ngrams_number >= 2:
lista_palabras = crear_ngramas(lista_palabras, número_ngramas)
si no:
raise ValueError(“el número de n-gramas debe ser >= 1”)
contador = Contador(lista_palabras)
frecuentes = contador.más_comunes(número_palabras_más_comunes)
retorno frecuente
def make_word_cloud(text_or_counter, stop_words=None):
si isinstance(texto_o_contador, str):
palabra_cloud = palabracloud.WordCloud(palabras_de_parada=palabras_de_parada).generate(texto_o_contador)
si no:
si stop_words no es None:
text_or_counter = Counter(palabra para palabra en text_or_counter si palabra no está en stop_palabras)
palabra_cloud = palabracloud.WordCloud(palabras_de_parada=palabras_de_parada).generate_from_frequencies(texto_o_contador)
plt.imshow(palabra_cloud)
plt.axis(“off”)
plt.show()
WordCloud
Aprovechando estas funciones, podemos mostrar fácilmente una Nube de palabras de las palabras más frecuentes, utilizando reseñas para Cámaras con una puntuación entre 1 y 2:

A continuación, muestre una Nube de Palabras similar utilizando reseñas para Cámaras con una puntuación entre 4 y 5 :
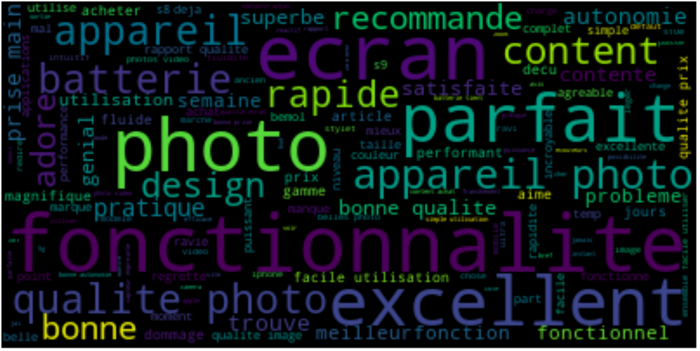
Podemos identificar fácilmente los principales puntos planteados en ambos casos.
Podríamos hacer este ejercicio para cada producto que tiene nuestra empresa, con el fin de ver la especificidad de cada uno y poder sacar conclusiones a un nivel más granular.
Recuento de N-gramas
También podemos utilizar el palabras_frecuentes para mostrar las palabras, bi-gramas o tri-gramas más frecuentes:

Para ir más lejos, podría poner en marcha una función que mostrara las reseñas asociadas a una palabra clave, con el fin de hacer zoom sobre los n-gramas que le resulten interesantes. También podría fijarse en los n-gramas con la mayor / menor TF-IDF (fácil de calcular con el sklearn ), ya que le permite ver las palabras importantes basándose en una métrica diferente a la de un simple contador de frecuencia.
Análisis del sentimiento
A continuación, pasamos a un enfoque de análisis de sentimientos. Normalmente, se utiliza para predecir si un texto es positivo o negativo. En nuestro caso, ya disponemos de esta información (la puntuación entre 1 y 5 nos da el sentimiento que hay detrás de la reseña). Pero entrenar un modelo para predecir esta valoración nos ayudará a encontrar qué palabras (características) son clave para los clientes.
Lo que podemos hacer es entrenar un clasificador de análisis de sentimiento en este data, y luego utilizar bibliotecas como SHAP o LIME para comprender que cuenta con (= palabras) tener el mayor impacto en que una reseña se clasifique como positiva o negativa.
Clasificador
Para entrenar un clasificador, tiene un montón de posibles algoritmos que puede utilizar, que van desde el clásico sklearn LogisticRegression, a los modelos ULM-fit (véase este cuaderno para entrenar un modelo francés de ajuste ULM, y este artículo para saber más sobre ULM-fit) o el clasificador Ludwig desarrollado por Uber.
Quizá le convenga empezar primero con uno sencillo, para ver si ya responde a sus necesidades, antes de poner en marcha algoritmos más complejos.
Asegúrese de tener en cuenta el hecho de que su dataset está probablemente desequilibrado (más reseñas positivas que negativas, en nuestro caso).
Importancia de las características
Una vez implementado su clasificador, puede pasar al paso más importante: obtener información de la importancia de las características.
En el siguiente ejemplo aplicamos SHAP en nuestro modelo (aquí, un simple sklearn LogisticRegression):

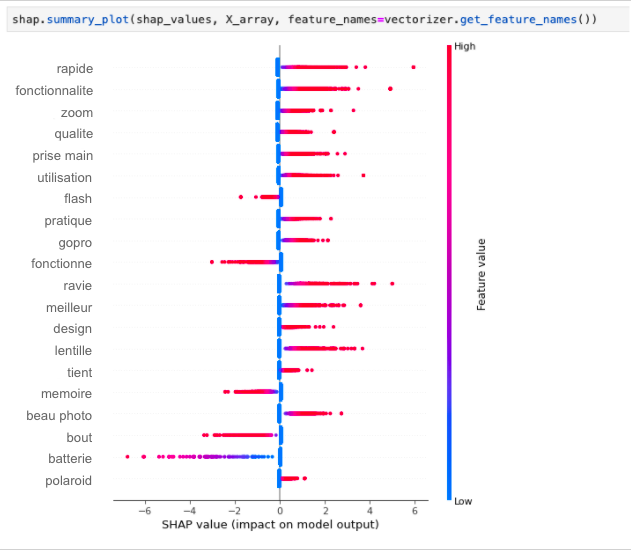
Podemos ver aquí que las funcionalidades, la calidad de las fotos y las características del zoom tienen un impacto realmente positivo en la satisfacción de nuestros clientes, mientras que el flash, la tarjeta de memoria o las baterías tienden a tener un impacto realmente negativo cuando se mencionan en una reseña.
Palabras como “excelente”, “perfecto” o “malo” fueron eliminadas de este análisis (antes de entrenar al clasificador), porque serán consideradas como las características más importantes, mientras que en nuestro caso queremos centrarnos en encontrar información sobre nuestros productos, no en mejorar realmente el rendimiento de nuestro clasificador.
Consulte este cuaderno para ver un ejemplo sobre cómo utilizar SHAP, con un dataset público.
Impacto de los temas empresariales
Nuestro tercer enfoque fue algo diferente de los anteriores, ya que parte de temas relacionados con la empresa elegidos por alguien con conocimientos sobre los productos.
Se trata de analizar cómo influyen los temas empresariales predefinidos en las valoraciones de los productos, para comprender si son una fuente de fortaleza o un problema a resolver.
Determinar los temas
El primer paso consiste en clasificar las reseñas en las categorías temáticas. Puede hacerlo etiquetando manualmente su conjunto data (después podría entrenar un clasificador si desea clasificar automáticamente las nuevas reseñas en temas), o con un modelo basado en reglas.
En nuestro caso utilizamos un modelo basado en reglas porque ya puede dar buenos resultados a bajo coste (por ejemplo: si tiene curiosidad por la calidad de sus lentes o sus servicios posventa, puede ser sencillo establecer reglas que determinen si una reseña los menciona o no).
Impacto del tema
En un segundo paso puede calcular su puntuación media global y, a continuación, la puntuación media de las reseñas que hablan de un tema específico.
Restando ambas puntuaciones, puede deducir el impacto que tiene su tema en su puntuación global.
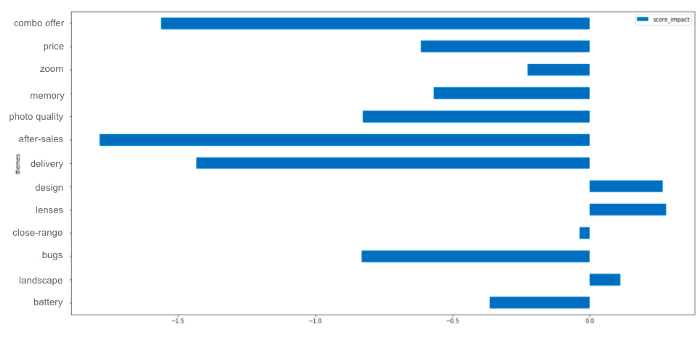
Aquí deberíamos preocuparnos por nuestro servicio posventa porque a menudo se menciona de forma negativa (aunque también podría deberse a que las personas que se ponen en contacto con el servicio posventa suelen tener un problema en primer lugar. Por eso, debería mirar en detalle las reseñas que mencionan este tema, para entender realmente por qué se sacó a colación).
→ También en este caso, el conocimiento del negocio es esencial para dar sentido a sus resultados.
Por otro lado, cuando se mencionan nuestros diseños o lentes, a menudo está vinculado a una reseña con una puntuación alta, lo que podría significar que es uno de nuestros puntos fuertes.
Consulte este artículo para más visualizaciones alternativas a Wordcloud.
Para ir más lejos
Podríamos ir más allá e intentar detectar temas en nuestras reseñas: se podría utilizar la biblioteca Top2Vec para extraer temas y ver la correlación entre temas y puntuaciones (cualquier biblioteca de modelado de temas funcionará, pero Top2Vec tiene la ventaja de dar grandes resultados sin necesidad de preprocesamiento ni de un número predefinido de temas).
Este artículo ha mostrado cómo obtener información sobre los clientes a partir de su data textual mediante un análisis pragmático y sencillo. Muchas gracias por leer hasta aquí y no dude en ponerse en contacto con nosotros si tiene algún comentario sobre el tema. Puede visitar nuestro blog aquí para saber más sobre nuestros proyectos de aprendizaje automático.
