


Introduction
Post-memory training has been a hyperfocus of mine over the past few months. If you have followed my recent writing on context management, memory architectures, and the recurring question of why agents degrade after turn 50, this article is where those threads converge.
The original pattern was clear enough. Eight independent research teams arrived at the same conclusion: stop building memory systems around the model and train the model itself to manage memory as a learned skill. That convergence was significant.
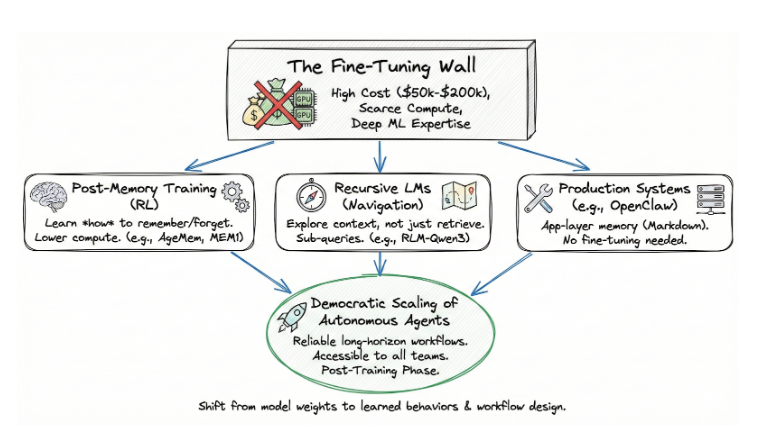
It points to a democratic path for scaling autonomous agents. One that does not require fine-tuning, an expensive and technically demanding process that depends on scarce compute and deep ML expertise. Post-memory training operates in the post-training phase: the same optimization stage that gave us instruction-following and reasoning, now applied to cognitive state management. And because it works on top of existing models, it is accessible to teams that could never afford to train one from scratch.
The fine-tuning wall
The default assumption for most of AI’s recent history has been straightforward: if you want a model to behave differently, fine-tune it. Adjust the weights. Optimize for your domain. The problem is that fine-tuning has become the province of a shrinking number of organizations.
Training a 70B-parameter model requires hundreds of high-end GPUs running for days or weeks. A single fine-tuning run on a model like Llama 3.1 70B costs between $50,000 and $200,000 in compute, depending on dataset size and duration. Access to that computer is constrained. NVIDIA H100 clusters are booked months in advance, and the expertise to manage distributed training jobs is scarce. Most enterprise teams do not have ML engineers who can design reward functions, debug gradient issues, or manage checkpoint recovery across multi-node clusters.
The result is a two-tier system. A handful of frontier labs and well-funded startups can customize model behavior. Everyone else uses models as-is, wrapping them in prompt engineering and retrieval pipelines that hit a ceiling once tasks get long and complex.
Post-memory training breaks this dynamic. It does not modify the base model’s weights for domain knowledge. It trains a behavior — memory management — using reinforcement learning in the post-training phase. The compute requirements are an order of magnitude lower. AgeMem’s entire training pipeline runs on a single 8xA100 node. Memory-R1 achieves its results with 152 training samples. MemAct trains a 14B model to match the accuracy of models 16x larger. These are not frontier-lab resource requirements. These are accessible.
The implication: organizations that could never afford to fine-tune a foundation model can now train their agents to manage memory intelligently. That is not an incremental improvement. It is a shift in who gets to build agents that actually work past the demo stage.
The gap that architecture alone cannot close
Here is the problem in concrete terms. A single conversation with an AI agent averages about $0.14 in token cost. Scale that to 3,000 employees using it ten times a day, and you are looking at $126,000 per month in API fees. As conversation histories grow, costs scale quadratically because every new turn reprocesses all previous turns. An agent handling a 100-turn workflow does not cost 10x what a 10-turn workflow costs. It costs closer to 100x.
The industry tried bigger context windows. We now have models that accept one million tokens or more. But three problems persist. Model attention degrades across long sequences. The “lost in the middle” effect documented by UC Berkeley shows performance drops when relevant information sits near context boundaries. The cost of brute-forcing context is unsustainable at an organizational scale. And most enterprise workflows still exceed even million-token windows when you account for tool outputs, structured data, and accumulated state.
The industry tried retrieval-augmented generation. RAG helps, but it retrieves what is semantically similar, not what is operationally relevant. A critical constraint from turn 3 can be semantically distant from the query at turn 47, yet essential to the decision at hand.
The industry tried heuristic memory management. Rule-based systems that summarize, compress, or filter context based on predefined logic. Mem0’s architecture achieves 26% accuracy improvements and 91% lower latency compared to full-context methods. Real gains. But heuristic systems share a limitation: the rules are designed by engineers, not learned from experience. They cannot adapt to novel domains without manual redesign.
The gap: none of these approaches teaches the agent itself what to remember. And none of them teach the agent how to navigate its own context.
Post-training for memory: the RL convergence
The term “post-training” refers to optimization that happens after the base model’s pre-training phase. It is how we got from raw language models to instruction-following assistants (via RLHF), from assistants to reasoning models (via process reward models), and now — from reasoning models to agents that manage their own cognitive state.
The mechanism is reinforcement learning. Instead of building memory management as an external system, you add memory operations to the agent’s action space and train it to use them well. The agent learns when to store, delete, consolidate, and retrieve — all through trial and error, optimized against task completion. No ground-truth examples of “correct” memory management needed. Just a reward signal: did the agent eventually solve the task?
Eight recent papers illuminate how this works.
The key architectures
AgeMem gives the agent six memory tools — ADD, UPDATE, DELETE for long-term storage, and RETRIEVE, SUMMARY, FILTER for short-term context. Training happens in three progressive stages. Results on Qwen2.5-7B: +49.59% relative improvement over no-memory baselines, with 3–5% fewer prompt tokens consumed than RAG variants. Better performance with less context.
Memory-R1 separates the problem into two specialized agents: a Memory Manager that learns structured operations and an Answer Agent that retrieves and reasons. The Memory Manager’s reward comes from whether the Answer Agent can answer correctly. Results: +28% F1 over the best baseline on LoCoMo, using only 152 training samples. Zero-shot transfer to unseen benchmarks without retraining.
MemAct augments the action space with a “Prune & Write” operator — at any step, the agent can delete history turns and append a memory summary. MemAct-RL-14B matches the accuracy of models 16x larger while reducing average context length by 51% and inference latency by ~40%.
MEM1 goes furthest, maintaining a constant memory size. At every turn, the agent generates an Internal State that consolidates everything it needs, then discards all previous context. Memory usage stays flat regardless of task length. MEM1-7B surpasses Qwen2.5-14B on 16-objective tasks. The model learned to track sub-goals separately, skip solved questions, and self-correct queries — all emergent behaviors.
MemAgent tackles the extreme case: processing documents of arbitrary length with linear complexity. Trained on 32K context length, it extrapolates to 3.5 million tokens with less than 5% performance loss.
The pattern across all of them: trained memory management beats untrained memory management, and often beats larger models with untrained memory.
But teaching agents what to remember is only half the story. In the next part of this article, I will deep-dive into a parallel development that reframes the problem entirely: Recursive Language Models, which treat context not as something to retrieve but as something to navigate. I will also look at how production systems like OpenClaw are proving these ideas work outside benchmarks, what this convergence means for enterprise scaling, and where the remaining gaps are. The agents that scale will not just remember better — they will know how to find what they have not yet remembered.
