


Einführung
Das Post-Memory-Training war in den letzten Monaten einer meiner Schwerpunkte. Wenn Sie meine jüngsten Beiträge über Kontextmanagement, Speicherarchitekturen und die immer wiederkehrende Frage, warum Agenten nach Vollendung des 50. Lebensjahres abbauen, verfolgt haben, finden Sie in diesem Artikel eine Zusammenfassung dieser Themen.
Das ursprüngliche Muster war klar genug. Acht unabhängige Forschungsteams kamen zu demselben Schluss: Hören Sie auf, Gedächtnissysteme um das Modell herum aufzubauen und trainieren Sie das Modell selbst, um das Gedächtnis als erlernte Fähigkeit zu verwalten. Diese Konvergenz war signifikant.
Sie zeigt auf eine demokratischer Weg zur Skalierung autonomer Agenten. Eine, die keine Feinabstimmung erfordert, ein teurer und technisch anspruchsvoller Prozess, der von knappen Rechenkapazitäten und tiefem ML-Fachwissen abhängt. Post-Memory-Training findet in der Phase nach dem Training statt: dieselbe Optimierungsphase, die uns das Befolgen von Anweisungen und das schlussfolgernde Denken ermöglicht hat, wird nun auf das kognitive Zustandsmanagement angewendet. Und da es auf bestehenden Modellen aufbaut, ist es auch für Teams zugänglich, die es sich niemals leisten könnten, ein Modell von Grund auf zu trainieren.
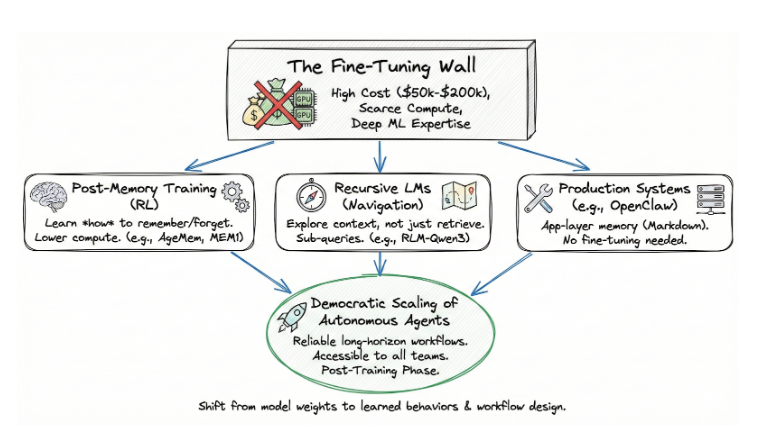
Die Wand zur Feinabstimmung
Die Standardannahme für den größten Teil der jüngeren Geschichte der KI war einfach: Wenn Sie wollen, dass sich ein Modell anders verhält, dann passen Sie es an. Passen Sie die Gewichte an. Optimieren Sie es für Ihren Bereich. Das Problem ist, dass die Feinabstimmung nur noch von einer schrumpfenden Zahl von Unternehmen durchgeführt wird.
Das Training eines 70B-Parameter-Modells erfordert Hunderte von High-End-GPUs, die Tage oder Wochen lang laufen. Ein einziger Feinabstimmungslauf für ein Modell wie Llama 3.1 70B kostet zwischen $50.000 und $200.000 an Rechenleistung, je nach Größe und Dauer des data-Sets. Der Zugang zu diesem Computer ist begrenzt. NVIDIA H100-Cluster sind Monate im Voraus ausgebucht, und das Fachwissen für die Verwaltung verteilter Trainingsaufträge ist rar. Die meisten Unternehmensteams verfügen nicht über ML-Ingenieure, die Reward-Funktionen entwerfen, Gradientenprobleme beheben oder die Wiederherstellung von Checkpoints in Clustern mit mehreren Knoten verwalten können.
Das Ergebnis ist ein zweistufiges System. Eine Handvoll Pionierlaboratorien und gut finanzierte Startups können das Verhalten der Modelle anpassen. Alle anderen verwenden die Modelle so, wie sie sind, und verpacken sie in prompte Engineering- und Retrieval-Pipelines, die an ihre Grenzen stoßen, sobald die Aufgaben lang und komplex werden.
Das Post-Memory-Training durchbricht diese Dynamik. Es verändert die Gewichte des Basismodells für das Domänenwissen nicht. Es trainiert ein Verhalten - die Speicherverwaltung - mit Hilfe von Verstärkungslernen in der Post-Trainingsphase. Die Rechenanforderungen sind um eine Größenordnung geringer. Die gesamte Trainingspipeline von AgeMem läuft auf einem einzigen 8xA100-Knoten. Memory-R1 erzielt seine Ergebnisse mit 152 Trainingsbeispielen. MemAct trainiert ein 14B-Modell und erreicht damit die Genauigkeit von Modellen, die 16 Mal größer sind. Dies sind nicht die Ressourcenanforderungen eines Grenzlabors. Sie sind zugänglich.
Die Konsequenz: Unternehmen, die es sich nie leisten konnten, eine Feinabstimmung des Basismodells vorzunehmen, können jetzt ihre Agenten darin schulen, den Speicher intelligent zu verwalten. Das ist keine schrittweise Verbesserung. Es handelt sich um eine Verschiebung der Zuständigkeit für die Entwicklung von Agenten, die über das Demo-Stadium hinaus funktionieren.
Die Lücke, die Architektur allein nicht schließen kann
Hier ist das Problem in konkreten Worten. Ein einziges Gespräch mit einem KI-Agenten kostet im Durchschnitt etwa $0,14 Token. Skalieren Sie das auf 3.000 Mitarbeiter, die zehnmal am Tag damit arbeiten, und Sie kommen auf $126.000 pro Monat an API-Gebühren. Wenn die Konversationshistorie wächst, steigen die Kosten quadratisch an, da jeder neue Vorgang alle vorherigen Vorgänge erneut verarbeitet. Ein Agent, der einen Workflow mit 100 Abfragen bearbeitet, kostet nicht das 10-fache dessen, was ein Workflow mit 10 Abfragen kostet. Er kostet eher das 100-fache.
Die Branche hat größere Kontextfenster ausprobiert. Wir haben jetzt Modelle, die eine Million Token oder mehr akzeptieren. Aber drei Probleme bleiben bestehen. Die Aufmerksamkeit des Modells nimmt bei langen Sequenzen ab. Der von der UC Berkeley dokumentierte “Lost in the middle”-Effekt zeigt, dass die Leistung sinkt, wenn relevante Informationen in der Nähe der Kontextgrenzen liegen. Die Kosten für das Erzwingen von Kontext sind in Unternehmen nicht tragbar. Und die meisten Arbeitsabläufe in Unternehmen überschreiten selbst bei Berücksichtigung von Tool-Outputs, strukturiertem data und akkumuliertem Status noch immer Millionen-Token-Fenster.
Die Industrie hat es mit Retrieval-Augmented Generation versucht. RAG ist hilfreich, aber es findet nur das, was semantisch ähnlich ist, nicht das, was operativ relevant ist. Eine kritische Einschränkung aus Runde 3 kann semantisch weit von der Abfrage in Runde 47 entfernt sein, aber dennoch für die anstehende Entscheidung wichtig sein.
Die Industrie hat eine heuristische Speicherverwaltung ausprobiert. Regelbasierte Systeme, die den Kontext auf der Grundlage einer vordefinierten Logik zusammenfassen, komprimieren oder filtern. Die Architektur von Mem0 erreicht eine um 26% verbesserte Genauigkeit und eine um 91% geringere Latenzzeit im Vergleich zu Methoden mit vollständigem Kontext. Ein echter Gewinn. Heuristische Systeme haben jedoch eine Einschränkung: Die Regeln werden von Ingenieuren entworfen und nicht aus Erfahrung gelernt. Sie können sich nicht an neue Domänen anpassen, ohne dass sie manuell umgestaltet werden.
Die Lücke: Keiner dieser Ansätze lehrt den Agenten selbst, was er sich merken soll. Und keiner von ihnen lehrt den Agenten, wie er sich in seinem eigenen Kontext zurechtfindet.
Post-Training für das Gedächtnis: die RL-Konvergenz
Der Begriff “Post-Training” bezieht sich auf die Optimierung, die nach der Pre-Trainingsphase des Basismodells erfolgt. Auf diese Weise sind wir von rohen Sprachmodellen zu Assistenten gekommen, die den Anweisungen folgen (über RLHF), von Assistenten zu Denkmodellen (über Prozessbelohnungsmodelle) und jetzt - von Denkmodellen zu Agenten, die ihren eigenen kognitiven Zustand verwalten.
Der Mechanismus ist das Verstärkungslernen. Anstatt die Speicherverwaltung als externes System aufzubauen, fügen Sie Speicheroperationen in den Aktionsraum des Agenten ein und trainieren ihn, sie gut zu nutzen. Der Agent lernt, wann er speichern, löschen, konsolidieren und abrufen soll - alles durch Versuch und Irrtum, optimiert im Hinblick auf die Aufgabenerfüllung. Sie brauchen keine Beispiele für die “richtige” Speicherverwaltung. Nur ein Belohnungssignal: Hat der Agent die Aufgabe schließlich gelöst?
Acht aktuelle Veröffentlichungen zeigen, wie das funktioniert.
Die wichtigsten Architekturen
AgeMem gibt dem Agenten sechs Gedächtniswerkzeuge an die Hand - ADD, UPDATE, DELETE für die langfristige Speicherung und RETRIEVE, SUMMARY, FILTER für den kurzfristigen Kontext. Das Training erfolgt in drei progressiven Stufen. Ergebnisse auf Qwen2.5-7B: +49.59% relative Verbesserung gegenüber den Null-Speicher-Baselines, mit 3-5% weniger verbrauchten Prompt-Tokens als bei den RAG-Varianten. Bessere Leistung bei weniger Kontext.
Speicher-R1 teilt das Problem in zwei spezialisierte Agenten auf: einen Memory Manager, der strukturierte Operationen lernt, und einen Answer Agent, der die Antworten abruft und begründet. Die Belohnung des Memory Managers ergibt sich daraus, ob der Antwort-Agent richtig antworten kann. Ergebnisse: +28% F1 gegenüber der besten Baseline auf LoCoMo, mit nur 152 Trainingsbeispielen. Übertragung von Null auf unbekannte Benchmarks ohne erneutes Training.
MemAct erweitert den Aktionsraum um einen “Prune & Write”-Operator - in jedem Schritt kann der Agent History Turns löschen und eine Speicherzusammenfassung anhängen. MemAct-RL-14B entspricht der Genauigkeit von 16x größeren Modellen und reduziert dabei die durchschnittliche Kontextlänge um 51% und die Inferenzlatenz um ~40%.
MEM1 geht am weitesten und behält eine konstante Speichergröße bei. Bei jedem Schritt erzeugt der Agent einen internen Status, der alles zusammenfasst, was er braucht, und verwirft dann den gesamten vorherigen Kontext. Die Speichernutzung bleibt unabhängig von der Länge der Aufgabe konstant. MEM1-7B übertrifft Qwen2.5-14B bei 16-Ziel-Aufgaben. Das Modell lernte, Unterziele separat zu verfolgen, gelöste Fragen zu überspringen und Abfragen selbst zu korrigieren - alles emergente Verhaltensweisen.
MemAgent nimmt den Extremfall in Angriff: die Verarbeitung von Dokumenten beliebiger Länge mit linearer Komplexität. Trainiert auf 32K Kontextlänge, extrapoliert es auf 3,5 Millionen Token mit weniger als 5% Leistungsverlust.
Das Muster ist bei allen gleich: trainierte Speicherverwaltung schlägt untrainierte Speicherverwaltung und schlägt oft größere Modelle mit untrainiertem Speicher.
Aber Agenten beizubringen, was sie sich merken sollen, ist nur die halbe Miete. Im nächsten Teil dieses Artikels werde ich mich mit einer parallelen Entwicklung befassen, die das Problem völlig neu formuliert: Rekursive Sprachmodelle, die den Kontext nicht als etwas behandeln, das man abrufen kann, sondern als etwas, das man navigieren kann. Ich werde mir auch ansehen, wie Produktionssysteme wie OpenClaw beweisen, dass diese Ideen außerhalb von Benchmarks funktionieren, was diese Konvergenz für die Skalierung von Unternehmen bedeutet und wo die verbleibenden Lücken liegen. Die Agenten, die skalieren, werden sich nicht nur besser erinnern - sie werden auch wissen, wie sie finden können, was sie sich noch nicht gemerkt haben.
