


Introdução
O treinamento pós-memória tem sido meu foco principal nos últimos meses. Se o senhor acompanhou meus escritos recentes sobre gerenciamento de contexto, arquiteturas de memória e a questão recorrente de por que os agentes se degradam depois dos 50 anos, este artigo é o ponto de convergência desses tópicos.
O padrão original era bastante claro. Oito equipes de pesquisa independentes chegaram à mesma conclusão: parar de criar sistemas de memória em torno do modelo e treinar o próprio modelo para gerenciar a memória como uma habilidade aprendida. Essa convergência foi significativa.
Ele aponta para um caminho democrático para o dimensionamento de agentes autônomos. Um que não exija ajuste fino, um processo caro e tecnicamente exigente que depende de computação escassa e profundo conhecimento de ML. O treinamento pós-memória opera na fase pós-treinamento: o mesmo estágio de otimização que nos proporcionou o acompanhamento de instruções e o raciocínio, agora aplicado ao gerenciamento do estado cognitivo. E como funciona com base em modelos existentes, é acessível a equipes que nunca poderiam se dar ao luxo de treinar um modelo do zero.
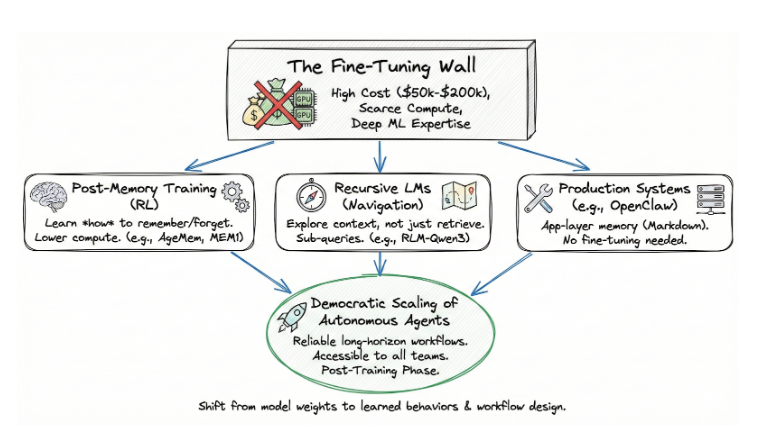
A parede de ajuste fino
O pressuposto padrão para a maior parte da história recente da IA tem sido simples: se o senhor quiser que um modelo se comporte de forma diferente, faça um ajuste fino. Ajuste os pesos. Otimize para seu domínio. O problema é que o ajuste fino tornou-se o domínio de um número cada vez menor de organizações.
O treinamento de um modelo de 70B parâmetros requer centenas de GPUs de ponta em execução por dias ou semanas. Uma única execução de ajuste fino em um modelo como o Llama 3.1 70B custa entre $50.000 e $200.000 em computação, dependendo do tamanho e da duração do dataset. O acesso a esse computador é restrito. Os clusters NVIDIA H100 são reservados com meses de antecedência, e a experiência para gerenciar trabalhos de treinamento distribuídos é escassa. A maioria das equipes empresariais não tem engenheiros de ML que possam projetar funções de recompensa, depurar problemas de gradiente ou gerenciar a recuperação de pontos de verificação em clusters de vários nós.
O resultado é um sistema de duas camadas. Um punhado de laboratórios de ponta e startups bem financiadas podem personalizar o comportamento do modelo. Todos os outros usam os modelos como estão, envolvendo-os em pipelines de engenharia e recuperação rápidos que atingem um teto quando as tarefas se tornam longas e complexas.
O treinamento pós-memória rompe essa dinâmica. Ele não modifica os pesos do modelo básico para o conhecimento do domínio. Ele treina um comportamento - gerenciamento de memória - usando a aprendizagem por reforço na fase pós-treinamento. Os requisitos de computação são uma ordem de magnitude menor. Todo o pipeline de treinamento do AgeMem é executado em um único nó 8xA100. O Memory-R1 obtém seus resultados com 152 amostras de treinamento. O MemAct treina um modelo de 14B para igualar a precisão de modelos 16 vezes maiores. Esses não são requisitos de recursos de laboratório de ponta. Eles são acessíveis.
A implicação: as organizações que nunca puderam se dar ao luxo de ajustar um modelo de base agora podem treinar seus agentes para gerenciar a memória de forma inteligente. Isso não é uma melhoria incremental. É uma mudança em quem pode criar agentes que realmente funcionem após a fase de demonstração.
A lacuna que a arquitetura por si só não pode preencher
Aqui está o problema em termos concretos. Uma única conversa com um agente de IA custa, em média, cerca de $0,14 em custo de token. Aumente esse valor para 3.000 funcionários que o utilizam dez vezes por dia e o senhor terá um custo de $126.000 por mês em taxas de API. À medida que os históricos de conversas aumentam, os custos aumentam quadraticamente, pois cada novo turno reprocessa todos os turnos anteriores. Um agente que lida com um fluxo de trabalho de 100 turnos não custa 10 vezes o custo de um fluxo de trabalho de 10 turnos. Seu custo está próximo de 100 vezes.
O setor tentou janelas de contexto maiores. Agora temos modelos que aceitam um milhão de tokens ou mais. Mas três problemas persistem. A atenção do modelo diminui em sequências longas. O efeito “perdido no meio”, documentado pela UC Berkeley, mostra que o desempenho cai quando as informações relevantes ficam próximas aos limites do contexto. O custo de forçar o contexto de forma bruta é insustentável em escala organizacional. E a maioria dos fluxos de trabalho corporativos ainda excede até mesmo as janelas de milhões de tokens quando o senhor considera as saídas de ferramentas, o data estruturado e o estado acumulado.
O setor tentou a geração aumentada por recuperação. O RAG ajuda, mas recupera o que é semanticamente semelhante, não o que é operacionalmente relevante. Uma restrição crítica do turno 3 pode ser semanticamente distante da consulta do turno 47, mas essencial para a decisão em questão.
O setor tentou o gerenciamento heurístico da memória. Sistemas baseados em regras que resumem, comprimem ou filtram o contexto com base em uma lógica predefinida. A arquitetura do Mem0 alcança melhorias de precisão de 26% e latência 91% menor em comparação com os métodos de contexto completo. Ganhos reais. Mas os sistemas heurísticos têm uma limitação em comum: as regras são projetadas por engenheiros, não aprendidas com a experiência. Eles não podem se adaptar a novos domínios sem um redesenho manual.
A lacuna: nenhuma dessas abordagens ensina ao próprio agente o que lembrar. E nenhuma delas ensina o agente a navegar em seu próprio contexto.
Pós-treinamento para memória: a convergência de RL
O termo “pós-treinamento” refere-se à otimização que ocorre após a fase de pré-treinamento do modelo básico. Foi assim que passamos de modelos de linguagem brutos para assistentes que seguem instruções (via RLHF), de assistentes para modelos de raciocínio (via modelos de recompensa de processo) e agora - de modelos de raciocínio para agentes que gerenciam seu próprio estado cognitivo.
O mecanismo é a aprendizagem por reforço. Em vez de criar o gerenciamento de memória como um sistema externo, o senhor adiciona operações de memória ao espaço de ação do agente e o treina para usá-las bem. O agente aprende quando armazenar, excluir, consolidar e recuperar, tudo por meio de tentativa e erro, otimizado em relação à conclusão da tarefa. Não são necessários exemplos de verdade absoluta do gerenciamento “correto” da memória. Apenas um sinal de recompensa: o agente acabou resolvendo a tarefa?
Oito artigos recentes esclarecem como isso funciona.
As principais arquiteturas
AgeMem oferece ao agente seis ferramentas de memória: ADICIONAR, ATUALIZAR, EXCLUIR para armazenamento de longo prazo e RETRIEVER, RESUMIR, FILTRAR para contexto de curto prazo. O treinamento ocorre em três estágios progressivos. Resultados no Qwen2.5-7B: +49.59% de melhoria relativa em relação às linhas de base sem memória, com 3-5% menos tokens de prompt consumidos do que as variantes RAG. Melhor desempenho com menos contexto.
Memória-R1 separa o problema em dois agentes especializados: um Memory Manager que aprende operações estruturadas e um Answer Agent que recupera e raciocina. A recompensa do Memory Manager vem do fato de o Answer Agent conseguir responder corretamente. Resultados: +28% F1 sobre a melhor linha de base no LoCoMo, usando apenas 152 amostras de treinamento. Transferência de zero shot para benchmarks não vistos sem retreinamento.
MemAct aumenta o espaço de ação com um operador “Prune & Write” - em qualquer etapa, o agente pode excluir turnos do histórico e anexar um resumo da memória. MemAct-RL-14B iguala a precisão de modelos 16 vezes maiores enquanto reduz o comprimento médio do contexto em 51% e a latência da inferência em ~40%.
MEM1 vai mais longe, mantendo um tamanho de memória constante. A cada turno, o agente gera um estado interno que consolida tudo o que precisa e, em seguida, descarta todo o contexto anterior. O uso da memória permanece estável, independentemente da duração da tarefa. MEM1-7B supera o Qwen2.5-14B em tarefas com 16 objetivos. O modelo aprendeu a rastrear sub-objetivos separadamente, pular perguntas resolvidas e autocorrigir consultas - todos comportamentos emergentes.
MemAgent aborda o caso extremo: processamento de documentos de tamanho arbitrário com complexidade linear. Treinado com 32K de comprimento de contexto, ele extrapola para 3,5 milhões de tokens com menos de 5% de perda de desempenho.
O padrão em todos eles: O gerenciamento de memória treinado supera o gerenciamento de memória não treinado e, muitas vezes, supera modelos maiores com memória não treinada.
Mas ensinar aos agentes o que lembrar é apenas metade da história. Na próxima parte deste artigo, vou me aprofundar em um desenvolvimento paralelo que reformula totalmente o problema: Modelos de linguagem recursivos, que tratam o contexto não como algo a ser recuperado, mas como algo a ser navegado. Também analisarei como sistemas de produção como o OpenClaw Os senhores estão provando que essas ideias funcionam fora dos padrões de referência, o que essa convergência significa para o dimensionamento empresarial e onde estão as lacunas restantes. Os agentes que escalam não apenas se lembrarão melhor, mas saberão como encontrar o que ainda não lembraram.
