


Inleiding
Post-memory training is de afgelopen maanden een hyperfocus van mij geweest. Als u mijn recente artikelen over contextbeheer, geheugenarchitecturen en de steeds terugkerende vraag waarom agenten degraderen na hun 50e hebt gevolgd, dan is dit artikel het punt waar deze onderwerpen samenkomen.
Het oorspronkelijke patroon was duidelijk genoeg. Acht onafhankelijke onderzoeksteams kwamen tot dezelfde conclusie: stop met het bouwen van geheugensystemen rond het model en train het model zelf om het geheugen te beheren als een aangeleerde vaardigheid. Die convergentie was significant.
Het wijst naar een democratisch pad voor het schalen van autonome agenten. Eén die geen fijnafstemming vereist, een duur en technisch veeleisend proces dat afhankelijk is van schaarse computers en diepgaande ML-expertise. Post-memory training werkt in de post-training fase: dezelfde optimalisatiefase die ons instructies volgen en redeneren gaf, nu toegepast op cognitief toestandsbeheer. En omdat het bovenop bestaande modellen werkt, is het toegankelijk voor teams die het zich nooit zouden kunnen veroorloven om er een vanaf nul te trainen.
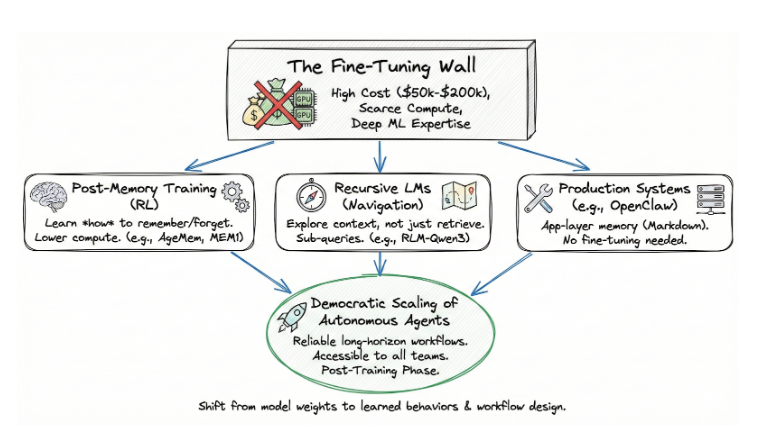
De afstemmingsmuur
De standaardaanname voor het grootste deel van de recente geschiedenis van AI is rechttoe rechtaan geweest: als u wilt dat een model zich anders gedraagt, stelt u het bij. Pas de gewichten aan. Optimaliseer voor uw domein. Het probleem is dat fijnafstelling het terrein is geworden van een krimpend aantal organisaties.
Voor het trainen van een 70B-parameter model zijn honderden high-end GPU's nodig die dagen of weken draaien. Een enkele fijnafstemmingsrun op een model als Llama 3.1 70B kost tussen $50.000 en $200.000 aan rekenkracht, afhankelijk van de datasetgrootte en duur. De toegang tot die computer is beperkt. NVIDIA H100 clusters worden maanden van tevoren gereserveerd en de expertise om gedistribueerde trainingstaken te beheren is schaars. De meeste bedrijfsteams hebben geen ML-ingenieurs die beloningsfuncties kunnen ontwerpen, gradiëntproblemen kunnen debuggen of het herstel van controlepunten op clusters met meerdere knooppunten kunnen beheren.
Het resultaat is een tweeledig systeem. Een handvol geavanceerde laboratoria en goed gefinancierde startups kunnen het gedrag van modellen aanpassen. Alle anderen gebruiken modellen zoals ze zijn en verpakken ze in snelle engineering- en opvraagpijplijnen die tegen een plafond aanlopen zodra de taken lang en complex worden.
Post-memory training doorbreekt deze dynamiek. De gewichten van het basismodel voor domeinkennis worden niet gewijzigd. Het traint een gedrag - geheugenbeheer - met behulp van versterkingsleren in de post-training fase. De rekenvereisten zijn een orde van grootte lager. De volledige trainingslijn van AgeMem draait op een enkele 8xA100 node. Memory-R1 behaalt zijn resultaten met 152 trainingssamples. MemAct traint een 14B model om de nauwkeurigheid van 16x grotere modellen te evenaren. Dit zijn geen grensverleggende labresources. Deze zijn toegankelijk.
De implicatie: organisaties die het zich nooit konden veroorloven om een foundationmodel te verfijnen, kunnen hun agents nu trainen om het geheugen op een intelligente manier te beheren. Dat is geen incrementele verbetering. Het is een verschuiving in wie er agenten mag bouwen die na de demonstratiefase ook echt werken.
De kloof die architectuur alleen niet kan dichten
Hier is het probleem in concrete termen. Een enkele conversatie met een AI-agent kost gemiddeld ongeveer $0,14 aan token. Schaal dat op naar 3.000 werknemers die het tien keer per dag gebruiken, en u kijkt naar $126.000 per maand aan API-kosten. Als de conversatiegeschiedenis groeit, schalen de kosten kwadratisch omdat bij elke nieuwe beurt alle vorige beurten opnieuw verwerkt worden. Een agent die een workflow van 100 beurten afhandelt, kost niet 10x wat een workflow van 10 beurten kost. Het kost eerder 100x.
De industrie probeerde grotere contextvensters. We hebben nu modellen die een miljoen tokens of meer accepteren. Maar er blijven drie problemen bestaan. Modelaandacht verslechtert over lange reeksen. Het “lost in the middle”-effect dat door UC Berkeley is gedocumenteerd, laat zien dat de prestaties afnemen wanneer relevante informatie zich dichtbij de contextgrenzen bevindt. De kosten van het brute-forcen van context zijn onhoudbaar op organisatieniveau. En de meeste bedrijfsworkflows overschrijden nog steeds vensters van zelfs miljoenen tokens als u rekening houdt met uitvoer van tools, gestructureerde data en geaccumuleerde status.
De industrie heeft retrieval-augmented generation geprobeerd. RAG helpt, maar het haalt op wat semantisch vergelijkbaar is, niet wat operationeel relevant is. Een kritieke beperking van beurt 3 kan semantisch ver verwijderd zijn van de query van beurt 47, maar toch essentieel zijn voor de te nemen beslissing.
De industrie probeerde heuristisch geheugenbeheer. Op regels gebaseerde systemen die context samenvatten, comprimeren of filteren op basis van vooraf gedefinieerde logica. De architectuur van Mem0 bereikt 26% nauwkeurigheidsverbeteringen en 91% lagere latentie in vergelijking met methoden met een volledige context. Echte winst. Maar heuristische systemen hebben een beperking: de regels zijn ontworpen door ingenieurs, niet geleerd uit ervaring. Ze kunnen zich niet aanpassen aan nieuwe domeinen zonder handmatig herontwerp.
De kloof: geen van deze benaderingen leert de agent zelf wat hij moet onthouden. En geen enkele leert de agent hoe hij door zijn eigen context moet navigeren.
Nascholing voor het geheugen: de RL-convergentie
De term “post-training” verwijst naar optimalisatie die plaatsvindt na de pre-trainingfase van het basismodel. Dit is hoe we van ruwe taalmodellen naar instructie-volgende assistenten zijn gegaan (via RLHF), van assistenten naar redeneermodellen (via proces-beloningsmodellen), en nu - van redeneermodellen naar agenten die hun eigen cognitieve staat beheren.
Het mechanisme is leren door versterking. In plaats van geheugenbeheer als een extern systeem op te bouwen, voegt u geheugenbewerkingen toe aan de actieruimte van de agent en traint u hem om ze goed te gebruiken. De agent leert wanneer op te slaan, te verwijderen, te consolideren en op te halen - allemaal met vallen en opstaan, geoptimaliseerd voor het voltooien van de taak. Er zijn geen waarheidsgetrouwe voorbeelden van “correct” geheugenbeheer nodig. Alleen een beloningssignaal: heeft de agent de taak uiteindelijk opgelost?
Acht recente artikelen laten zien hoe dit werkt.
De belangrijkste architecturen
AgeMem geeft de agent zes geheugentools - ADD, UPDATE, DELETE voor opslag op lange termijn, en RETRIEVE, SUMMARY, FILTER voor context op korte termijn. Training gebeurt in drie progressieve fasen. Resultaten op Qwen2.5-7B: +49.59% relatieve verbetering ten opzichte van de basislijn zonder geheugen, met 3-5% minder prompttokens verbruikt dan RAG-varianten. Betere prestaties met minder context.
Geheugen-R1 splitst het probleem op in twee gespecialiseerde agenten: een Memory Manager die gestructureerde bewerkingen leert en een Answer Agent die ophaalt en redeneert. De beloning van de Memory Manager is afhankelijk van de vraag of de Answer Agent een correct antwoord kan geven. Resultaten: +28% F1 ten opzichte van de beste basislijn op LoCoMo, met slechts 152 trainingssamples. Nul-op-de-meter overdracht naar ongeziene benchmarks zonder hertraining.
MemAct breidt de actieruimte uit met een “Prune & Write” operator - bij elke stap kan de agent geschiedenisbeurten wissen en een geheugenoverzicht toevoegen. MemAct-RL-14B evenaart de nauwkeurigheid van modellen die 16x groter zijn terwijl de gemiddelde contextlengte met 51% wordt verminderd en de inferentielatentie met ~40%.
MEM1 gaat het verst, waarbij de geheugengrootte constant blijft. Bij elke beurt genereert de agent een Interne Staat die alles consolideert wat hij nodig heeft, en vervolgens alle vorige context weggooit. Het geheugengebruik blijft gelijk, ongeacht de lengte van de taak. MEM1-7B overtreft Qwen2.5-14B op taken met 16 doelstellingen. Het model leerde om subdoelen afzonderlijk te volgen, opgeloste vragen over te slaan en zoekopdrachten zelf te corrigeren - allemaal opkomend gedrag.
MemAgent pakt het extreme geval aan: het verwerken van documenten van willekeurige lengte met lineaire complexiteit. Getraind op 32K contextlengte, extrapoleert het tot 3,5 miljoen tokens met minder dan 5% prestatieverlies.
Het patroon bij allemaal: getraind geheugenbeheer is beter dan ongetraind geheugenbeheer, en is vaak beter dan grotere modellen met ongetraind geheugen.
Maar agenten leren wat ze moeten onthouden is maar de helft van het verhaal. In het volgende deel van dit artikel zal ik dieper ingaan op een parallelle ontwikkeling die het probleem volledig herdefinieert: Recursieve Taalmodellen, die context niet behandelen als iets om op te halen, maar als iets om door te navigeren. Ik zal ook kijken naar hoe productiesystemen zoals OpenClaw bewijzen dat deze ideeën werken buiten benchmarks, wat deze convergentie betekent voor het schalen van ondernemingen, en waar de resterende hiaten zitten. De agenten die opschalen zullen niet alleen beter onthouden - ze zullen ook weten hoe ze moeten vinden wat ze nog niet hebben onthouden.
