


导言
在过去的几个月里,"后内存训练 "一直是我关注的焦点。如果你关注过我最近撰写的关于上下文管理、内存架构以及 "为什么代理在 50 岁之后会退化 "这一反复出现的问题的文章,那么这篇文章就是这些线索的交汇点。.
原来的模式非常清晰。八个独立的研究团队得出了相同的结论:停止围绕模型建立记忆系统,训练模型本身将记忆作为一种学习技能来管理。这一共识意义重大。.
它指向一个 扩大自治代理的民主道路. .它不需要微调,而微调是一个昂贵且技术要求高的过程,依赖于稀缺的计算能力和深厚的人工智能专业知识。记忆后训练在训练后阶段运行:与指令跟踪和推理相同的优化阶段,现在也适用于认知状态管理。而且,由于它是在现有模型的基础上工作的,因此那些没有能力从头开始训练模型的团队也可以使用它。.
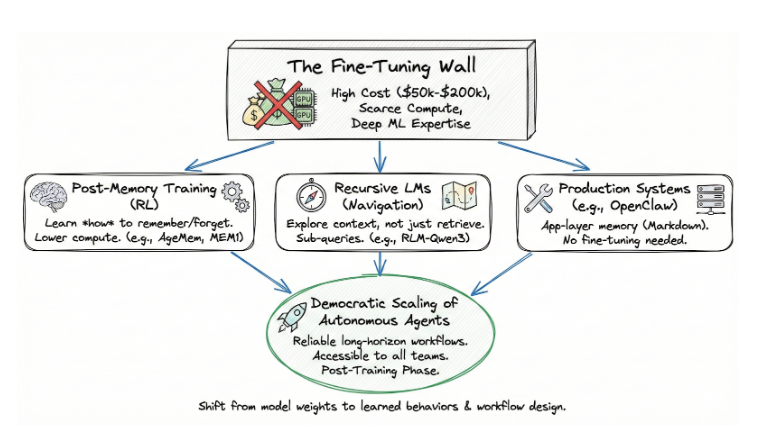
微调墙
在人工智能的近代史上,大多数情况下的默认假设都是简单明了的:如果你想让模型有不同的表现,那就对它进行微调。调整权重。针对你的领域进行优化。问题是,微调已经成为越来越多组织的专利。.
训练一个 70B 参数的模型需要数百个高端 GPU 运行数天或数周。对类似 Llama 3.1 70B 这样的模型进行一次微调运行的计算成本在 $50,000 到 $200,000 之间,具体取决于 dataset 的大小和持续时间。访问该计算机受到限制。英伟达™(NVIDIA®)H100 集群要提前几个月预订,而管理分布式培训工作的专业人才却非常稀缺。大多数企业团队都没有能够设计奖励函数、调试梯度问题或管理多节点集群检查点恢复的 ML 工程师。.
这就形成了一个双层系统。少数前沿实验室和资金雄厚的初创公司可以定制模型行为。其他所有人都是按原样使用模型,将其包裹在及时工程和检索管道中,一旦任务变得冗长复杂,这些管道就会触及天花板。.
后记忆训练打破了这一态势。它不会修改基础模型的领域知识权重。它在后训练阶段使用强化学习来训练一种行为--内存管理。计算要求低了一个数量级。AgeMem 的整个训练流水线在单个 8xA100 节点上运行。Memory-R1 仅用 152 个训练样本就取得了成果。MemAct 对一个 14B 的模型进行训练,其准确度可媲美 16 倍以上的模型。这些并非前沿实验室的资源要求。这些都是可以获得的。.
这意味着:那些从来没有能力对基础模型进行微调的组织,现在可以训练他们的代理智能地管理内存。这不是渐进式的改进。它改变了谁来构建能在演示阶段后真正发挥作用的代理的方式。.
仅靠建筑无法弥补的差距
下面是问题的具体表现。与人工智能代理进行一次对话的平均令牌成本约为 $0.14。如果将其扩大到 3,000 名员工每天使用十次,那么每月的 API 费用将达到 $126,000。随着对话历史的增加,成本也会以四倍的速度递增,因为每一个新回合都要重新处理之前的所有回合。处理 100 转工作流程的代理成本不是 10 转工作流程的 10 倍。它的成本接近 100 倍。.
业界尝试了更大的语境窗口。现在,我们已经有了可以接受 100 万个或更多代币的模型。但三个问题依然存在。在长序列中,模型的注意力会下降。加州大学伯克利分校记录的 “迷失在中间 ”效应表明,当相关信息位于上下文边界附近时,性能就会下降。在组织规模上,强制上下文的成本是不可持续的。如果考虑到工具输出、结构化 data 和累积状态,大多数企业工作流甚至仍会超过百万令牌窗口。.
业界尝试过检索增强生成。RAG 有帮助,但它检索的是语义相似的内容,而不是与操作相关的内容。第 3 步的关键约束条件在语义上可能与第 47 步的查询相去甚远,但对当前的决策却至关重要。.
业界尝试过启发式内存管理。基于规则的系统可根据预定义的逻辑对上下文进行汇总、压缩或过滤。与全上下文方法相比,Mem0 的架构实现了 26% 的精度提升和 91% 的延迟降低。实实在在的收益。但是,启发式系统也有其局限性:规则是由工程师设计的,而不是从经验中总结出来的。如果不进行人工重新设计,它们就无法适应新的领域。.
差距:这些方法都没有教代理本身记住什么。它们都没有教代理如何驾驭自己的上下文。.
记忆的后期训练:RL 收敛
术语 “后训练 ”指的是在基础模型的预训练阶段之后进行的优化。我们就是这样从原始语言模型到指令跟随助手(通过 RLHF),从助手到推理模型(通过过程奖励模型),再到现在--从推理模型到管理自身认知状态的代理。.
这种机制就是强化学习。你不需要将内存管理作为一个外部系统来构建,而是将内存操作添加到代理的行动空间中,并训练它很好地使用这些操作。代理会学习何时存储、删除、合并和检索--所有这些都是通过试错来实现的,并根据任务完成情况进行优化。不需要 “正确 ”内存管理的真实案例。只需一个奖励信号:代理最终解决了任务吗?
最近的八篇论文阐明了这一点。.
关键架构
年龄记忆 为代理提供了六种记忆工具--用于长期存储的 ADD、UPDATE、DELETE 和用于短期语境的 RETRIEVE、SUMMARY、FILTER。训练分三个阶段逐步进行。Qwen2.5-7B 的结果:与无记忆基线相比,相对提高了 +49.59%,与 RAG 变体相比,消耗的提示标记减少了 3-5%。在较少上下文的情况下性能更佳。.
内存-R1 将问题分成两个专门的代理:一个是学习结构化运算的记忆管理器,另一个是检索和推理的答题代理。记忆管理器的奖励来自于回答代理能否正确回答。结果 +28% F1 仅用 152 个训练样本,就超过了 LoCoMo 的最佳基准。无须重新训练,即可实现对未见基准的零点转移。.
MemAct 通过 “剪枝与写入 ”操作符来扩展操作空间--在任何步骤中,代理都可以删除历史记录并附加记忆摘要。MemAct-RL-14B 精度可媲美大 16 倍的模型 同时将平均上下文长度减少 51%,推理延迟减少 ~40%。.
MEM1 最远,内存大小保持不变。代理每次都会生成一个 "内部状态",整合它所需要的一切,然后丢弃之前的所有上下文。无论任务长短,内存使用量都保持不变。MEM1-7B 超过 Qwen2.5-14B 16 个目标任务。该模型学会了分别跟踪子目标、跳过已解决的问题和自我纠正查询--所有这些都是新出现的行为。.
MemAgent 处理极端情况:以线性复杂度处理任意长度的文档。在 32K 上下文长度上进行训练后,它可以推断出 350 万个标记,而性能损失不到 5%。.
所有的模式都是如此: 训练有素的内存管理优于未经训练的内存管理,而且往往优于使用未经训练的内存的大型模型.
但是,教代理记住什么只是故事的一半。在本文的下一部分,我将深入探讨一个完全重构问题的平行发展: 递归语言模型, 这些系统不是将上下文作为检索对象,而是作为导航对象。我还将研究生产系统,如 OpenClaw 在基准之外证明这些想法是可行的,这种融合对企业扩展意味着什么,以及还存在哪些差距。规模化的代理不仅能更好地记忆,还能知道如何找到尚未记忆的内容。.

