


Introducción
La formación postmemoria ha sido uno de mis focos de atención en los últimos meses. Si ha seguido mis escritos recientes sobre la gestión del contexto, las arquitecturas de memoria y la pregunta recurrente de por qué los agentes se degradan después de cumplir 50 años, en este artículo convergen esos hilos.
El modelo original era bastante claro. Ocho equipos de investigación independientes llegaron a la misma conclusión: dejar de construir sistemas de memoria alrededor del modelo y entrenar al propio modelo para que gestione la memoria como una habilidad aprendida. Esa convergencia fue significativa.
Señala un vía democrática para la ampliación de agentes autónomos. Uno que no requiera un ajuste fino, un proceso caro y técnicamente exigente que depende de la escasez de computación y de una profunda experiencia en ML. El entrenamiento post-memoria opera en la fase de post-entrenamiento: la misma etapa de optimización que nos dio el seguimiento de instrucciones y el razonamiento, aplicada ahora a la gestión del estado cognitivo. Y como funciona sobre modelos existentes, es accesible a equipos que nunca podrían permitirse entrenar uno desde cero.
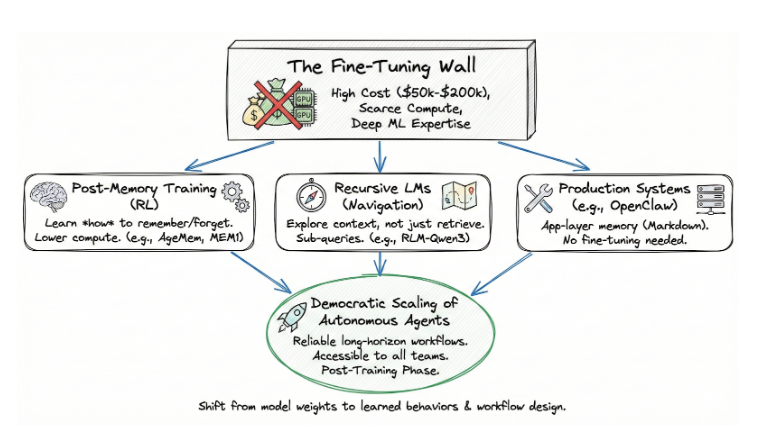
El muro de ajuste
El supuesto por defecto durante la mayor parte de la historia reciente de la IA ha sido sencillo: si quiere que un modelo se comporte de forma diferente, ajústelo. Ajuste los pesos. Optimícelo para su dominio. El problema es que el ajuste fino se ha convertido en la competencia de un número cada vez menor de organizaciones.
Entrenar un modelo de 70B parámetros requiere cientos de GPU de gama alta funcionando durante días o semanas. Una sola ejecución de ajuste fino en un modelo como Llama 3.1 70B cuesta entre $50.000 y $200.000 en computación, dependiendo del tamaño y la duración del dataset. El acceso a ese ordenador está limitado. Los clusters NVIDIA H100 se reservan con meses de antelación y los conocimientos para gestionar los trabajos de formación distribuidos son escasos. La mayoría de los equipos empresariales no cuentan con ingenieros de ML que puedan diseñar funciones de recompensa, depurar problemas de gradiente o gestionar la recuperación de puntos de control en clusters de varios nodos.
El resultado es un sistema de dos niveles. Un puñado de laboratorios de vanguardia y empresas emergentes bien financiadas pueden personalizar el comportamiento de los modelos. Todos los demás utilizan los modelos tal cual, envolviéndolos en conductos de ingeniería y recuperación rápidas que tocan techo una vez que las tareas se hacen largas y complejas.
El entrenamiento post-memoria rompe esta dinámica. No modifica las ponderaciones del modelo base para el conocimiento del dominio. Entrena un comportamiento -la gestión de la memoria- utilizando el aprendizaje por refuerzo en la fase de post-entrenamiento. Los requisitos de cálculo son un orden de magnitud inferiores. Toda la tubería de entrenamiento de AgeMem se ejecuta en un único nodo 8xA100. Memory-R1 logra sus resultados con 152 muestras de entrenamiento. MemAct entrena un modelo 14B para igualar la precisión de modelos 16 veces mayores. Estos no son requisitos de recursos de laboratorio de frontera. Son accesibles.
La implicación: las organizaciones que nunca podrían permitirse afinar un modelo de base pueden ahora entrenar a sus agentes para que gestionen la memoria de forma inteligente. No se trata de una mejora incremental. Es un cambio en quién consigue construir agentes que realmente funcionen más allá de la fase de demostración.
La brecha que la arquitectura por sí sola no puede cerrar
He aquí el problema en términos concretos. Una sola conversación con un agente de IA tiene un coste medio de $0,14 en fichas. Escale eso a 3.000 empleados que lo utilicen diez veces al día, y se encontrará con $126.000 al mes en tarifas API. A medida que crecen los historiales de conversaciones, los costes escalan cuadráticamente porque cada nuevo turno reprocesa todos los turnos anteriores. Un agente que gestione un flujo de trabajo de 100 turnos no cuesta 10 veces lo que cuesta un flujo de trabajo de 10 turnos. Cuesta más bien 100 veces.
La industria probó con ventanas contextuales más grandes. Ahora tenemos modelos que aceptan un millón de fichas o más. Pero persisten tres problemas. La atención de los modelos se degrada en secuencias largas. El efecto “perdido en el medio” documentado por la UC Berkeley muestra que el rendimiento cae cuando la información relevante se sitúa cerca de los límites del contexto. El coste de forzar bruscamente el contexto es insostenible a escala organizativa. Y la mayoría de los flujos de trabajo empresariales siguen superando incluso las ventanas de un millón de tokens cuando se tienen en cuenta las salidas de las herramientas, el data estructurado y el estado acumulado.
La industria probó la generación aumentada por recuperación. La RAG ayuda, pero recupera lo que es semánticamente similar, no lo que es relevante desde el punto de vista operativo. Una restricción crítica del turno 3 puede ser semánticamente distante de la consulta del turno 47, pero esencial para la decisión en cuestión.
La industria probó la gestión heurística de la memoria. Sistemas basados en reglas que resumen, comprimen o filtran el contexto basándose en una lógica predefinida. La arquitectura de Mem0 consigue mejoras de precisión de 26% y una latencia 91% menor en comparación con los métodos de contexto completo. Ganancias reales. Pero los sistemas heurísticos comparten una limitación: las reglas son diseñadas por ingenieros, no aprendidas de la experiencia. No pueden adaptarse a nuevos dominios sin un rediseño manual.
La laguna: ninguno de estos enfoques enseña al propio agente qué debe recordar. Y ninguno de ellos enseña al agente cómo navegar por su propio contexto.
Post-entrenamiento para la memoria: la convergencia RL
El término “post-entrenamiento” se refiere a la optimización que tiene lugar después de la fase de pre-entrenamiento del modelo base. Así es como pasamos de los modelos de lenguaje en bruto a los asistentes de seguimiento de instrucciones (a través de RLHF), de los asistentes a los modelos de razonamiento (a través de los modelos de recompensa de procesos) y, ahora, de los modelos de razonamiento a los agentes que gestionan su propio estado cognitivo.
El mecanismo es el aprendizaje por refuerzo. En lugar de construir la gestión de la memoria como un sistema externo, se añaden operaciones de memoria al espacio de acción del agente y se le entrena para que las utilice bien. El agente aprende cuándo almacenar, borrar, consolidar y recuperar, todo ello mediante ensayo y error, optimizado en función de la finalización de la tarea. No se necesitan ejemplos reales de gestión “correcta” de la memoria. Sólo una señal de recompensa: ¿resolvió finalmente el agente la tarea?
Ocho artículos recientes ilustran cómo funciona esto.
Las arquitecturas clave
AgeMem proporciona al agente seis herramientas de memoria: AÑADIR, ACTUALIZAR, ELIMINAR para el almacenamiento a largo plazo, y RECUPERAR, RESUMIR, FILTRAR para el contexto a corto plazo. El entrenamiento se realiza en tres etapas progresivas. Resultados en Qwen2.5-7B: mejora relativa de +49,59% respecto a las líneas de base sin memoria, con 3-5% menos tokens de prompt consumidos que las variantes RAG. Mejor rendimiento con menos contexto.
Memoria-R1 separa el problema en dos agentes especializados: un Gestor de Memoria que aprende las operaciones estructuradas y un Agente de Respuesta que recupera y razona. La recompensa del Gestor de Memoria proviene de si el Agente de Respuesta puede responder correctamente. Resultados: +28% F1 sobre la mejor línea de base en LoCoMo, utilizando sólo 152 muestras de entrenamiento. Transferencia cero a puntos de referencia no vistos sin reentrenamiento.
MemAct aumenta el espacio de acción con un operador de “poda y escritura”: en cualquier paso, el agente puede borrar los turnos del historial y adjuntar un resumen de memoria. MemAct-RL-14B iguala la precisión de modelos 16 veces mayores reduciendo al mismo tiempo la longitud media del contexto en 51% y la latencia de inferencia en ~40%.
MEM1 va más lejos, manteniendo un tamaño de memoria constante. En cada vuelta, el agente genera un Estado Interno que consolida todo lo que necesita, y luego descarta todo el contexto anterior. El uso de memoria se mantiene plano independientemente de la duración de la tarea. MEM1-7B supera Qwen2.5-14B en tareas de 16 objetivos. El modelo aprendió a seguir subobjetivos por separado, a saltarse preguntas resueltas y a autocorregir consultas, todos ellos comportamientos emergentes.
MemAgent aborda el caso extremo: procesar documentos de longitud arbitraria con una complejidad lineal. Entrenado con una longitud de contexto de 32K, extrapola hasta 3,5 millones de tokens con menos de 5% de pérdida de rendimiento.
El patrón en todos ellos: la gestión de memoria entrenada supera a la gestión de memoria no entrenada, y a menudo supera a los modelos más grandes con memoria no entrenada.
Pero enseñar a los agentes qué deben recordar es sólo la mitad de la historia. En la siguiente parte de este artículo, profundizaré en un desarrollo paralelo que replantea el problema por completo: Modelos lingüísticos recursivos, que tratan el contexto no como algo que recuperar, sino como algo por lo que navegar. También examinaré cómo los sistemas de producción como OpenClaw están demostrando que estas ideas funcionan fuera de los puntos de referencia, qué significa esta convergencia para el escalado empresarial y dónde están las lagunas que quedan. Los agentes que escalen no sólo recordarán mejor, sino que sabrán encontrar lo que aún no han recordado.
