


Introduction
La formation post-mémoire a été l'un de mes sujets de prédilection au cours des derniers mois. Si vous avez suivi mes récents écrits sur la gestion du contexte, les architectures de mémoire et la question récurrente de savoir pourquoi les agents se dégradent après 50 ans, cet article est le point de convergence de ces sujets.
Le modèle initial était assez clair. Huit équipes de recherche indépendantes sont arrivées à la même conclusion : arrêter de construire des systèmes de mémoire autour du modèle et former le modèle lui-même à gérer la mémoire comme une compétence acquise. Cette convergence est significative.
Il pointe vers un voie démocratique pour la mise à l'échelle des agents autonomes. Il ne nécessite pas de réglage fin, un processus coûteux et techniquement exigeant qui dépend d'un calcul rare et d'une expertise approfondie en ML. La formation post-mémoire opère dans la phase de post-formation : la même étape d'optimisation qui nous a donné le suivi des instructions et le raisonnement, maintenant appliquée à la gestion de l'état cognitif. Et parce qu'il fonctionne au-dessus des modèles existants, il est accessible aux équipes qui ne pourraient jamais se permettre d'en former un à partir de zéro.
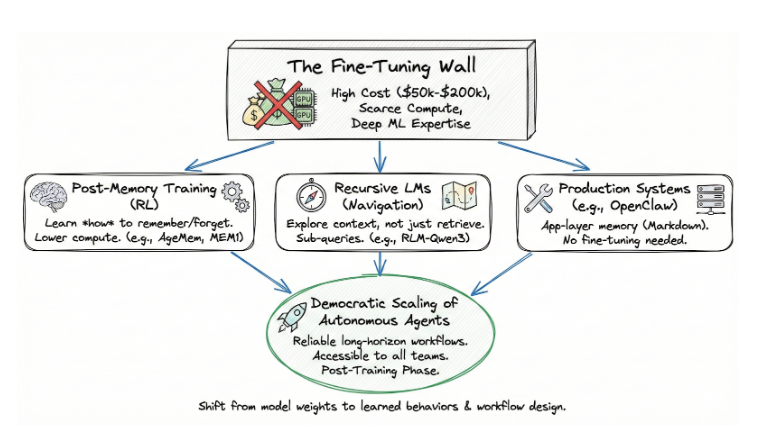
Le mur de réglage
L'hypothèse par défaut pour la majeure partie de l'histoire récente de l'IA a été simple : si vous voulez qu'un modèle se comporte différemment, affinez-le. Ajustez les poids. Optimisez pour votre domaine. Le problème, c'est que le réglage fin est devenu l'apanage d'un nombre de plus en plus restreint d'organisations.
L'entraînement d'un modèle de 70B paramètres nécessite des centaines de GPU haut de gamme fonctionnant pendant des jours ou des semaines. Une seule opération de réglage fin sur un modèle tel que Llama 3.1 70B coûte entre $50 000 et $200 000 en calcul, en fonction de la taille et de la durée de dataset. L'accès à cet ordinateur est limité. Les clusters NVIDIA H100 sont réservés des mois à l'avance et l'expertise nécessaire pour gérer les tâches de formation distribuées est rare. La plupart des équipes d'entreprise n'ont pas d'ingénieurs ML capables de concevoir des fonctions de récompense, de déboguer les problèmes de gradient ou de gérer la récupération des points de contrôle sur des grappes à plusieurs nœuds.
Il en résulte un système à deux vitesses. Une poignée de laboratoires d'avant-garde et de startups bien financées peuvent personnaliser le comportement des modèles. Tous les autres utilisent les modèles tels quels, en les enveloppant dans des pipelines d'ingénierie et de récupération rapides qui atteignent un plafond dès que les tâches deviennent longues et complexes.
La formation post-mémoire rompt cette dynamique. Elle ne modifie pas les poids du modèle de base pour la connaissance du domaine. Il entraîne un comportement - la gestion de la mémoire - en utilisant l'apprentissage par renforcement dans la phase de post-entraînement. Les besoins en calcul sont inférieurs d'un ordre de grandeur. L'ensemble du pipeline de formation d'AgeMem fonctionne sur un seul nœud 8xA100. Memory-R1 obtient ses résultats avec 152 échantillons d'entraînement. MemAct entraîne un modèle de 14B pour atteindre la précision de modèles 16x plus grands. Il ne s'agit pas d'exigences en matière de ressources d'un laboratoire de pointe. Elles sont accessibles.
Conséquence : les organisations qui n'auraient jamais pu se permettre d'affiner un modèle de base peuvent désormais former leurs agents à gérer la mémoire de manière intelligente. Il ne s'agit pas d'une amélioration progressive. Il s'agit d'un changement dans le choix des personnes chargées de créer des agents qui fonctionnent réellement au-delà de la phase de démonstration.
Le fossé que l'architecture seule ne peut combler
Voici le problème en termes concrets. Une seule conversation avec un agent d'IA coûte en moyenne $0,14 en jetons. Adaptez ce chiffre à 3 000 employés qui l'utilisent dix fois par jour, et vous obtiendrez $126 000 par mois en frais d'API. Au fur et à mesure que l'historique des conversations s'allonge, les coûts augmentent de façon quadratique, car chaque nouveau tour traite à nouveau tous les tours précédents. Un agent qui gère un flux de travail de 100 tours ne coûte pas 10 fois le coût d'un flux de travail de 10 tours. Son coût est plus proche de 100x.
Le secteur a essayé d'élargir les fenêtres contextuelles. Nous avons maintenant des modèles qui acceptent un million de jetons ou plus. Mais trois problèmes persistent. L'attention du modèle se dégrade sur de longues séquences. L'effet “lost in the middle” (perdu au milieu), documenté par l'université de Berkeley, montre que les performances chutent lorsque les informations pertinentes se trouvent près des limites du contexte. Le coût du renforcement brutal du contexte est insoutenable à l'échelle d'une organisation. Et la plupart des flux de travail des entreprises dépassent encore les fenêtres d'un million de mots lorsque vous tenez compte des sorties d'outils, des data structurées et de l'état accumulé.
L'industrie a essayé la génération augmentée par récupération. La RAG est utile, mais elle récupère ce qui est sémantiquement similaire, et non ce qui est pertinent d'un point de vue opérationnel. Une contrainte critique du tour 3 peut être sémantiquement éloignée de la requête du tour 47, tout en étant essentielle à la décision à prendre.
L'industrie a essayé la gestion heuristique de la mémoire. Des systèmes basés sur des règles qui résument, compressent ou filtrent le contexte sur la base d'une logique prédéfinie. L'architecture de Mem0 permet d'améliorer la précision de 26% et de réduire le temps de latence de 91% par rapport aux méthodes à contexte complet. Des gains réels. Mais les systèmes heuristiques ont une limite commune : les règles sont conçues par des ingénieurs, et non apprises par l'expérience. Elles ne peuvent pas s'adapter à de nouveaux domaines sans une refonte manuelle.
La lacune : aucune de ces approches n'enseigne à l'agent lui-même ce qu'il doit retenir. Et aucune n'enseigne à l'agent comment naviguer dans son propre contexte.
Post-entraînement à la mémoire : la convergence RL
Le terme “post-entraînement” fait référence à l'optimisation qui a lieu après la phase de pré-entraînement du modèle de base. C'est ainsi que nous sommes passés de modèles de langage brut à des assistants qui suivent des instructions (via RLHF), d'assistants à des modèles de raisonnement (via des modèles de récompense de processus), et maintenant - de modèles de raisonnement à des agents qui gèrent leur propre état cognitif.
Le mécanisme est l'apprentissage par renforcement. Au lieu de concevoir la gestion de la mémoire comme un système externe, vous ajoutez des opérations de mémoire à l'espace d'action de l'agent et vous l'entraînez à les utiliser correctement. L'agent apprend quand stocker, effacer, consolider et récupérer - tout cela par essais et erreurs, optimisés en fonction de l'accomplissement de la tâche. Il n'est pas nécessaire de disposer d'exemples concrets de gestion “correcte” de la mémoire. Il suffit d'un signal de récompense : l'agent a-t-il fini par résoudre la tâche ?
Huit articles récents expliquent comment cela fonctionne.
Les architectures clés
AgeMem donne à l'agent six outils de mémoire - ADD, UPDATE, DELETE pour le stockage à long terme, et RETRIEVE, SUMMARY, FILTER pour le contexte à court terme. La formation se déroule en trois étapes progressives. Résultats sur Qwen2.5-7B : +49.59% amélioration relative par rapport aux lignes de base sans mémoire, avec 3-5% moins de jetons d'invite consommés que les variantes RAG. Meilleure performance avec moins de contexte.
Mémoire-R1 sépare le problème en deux agents spécialisés : un gestionnaire de mémoire qui apprend les opérations structurées et un agent de réponse qui récupère et raisonne. La récompense du gestionnaire de mémoire dépend de la capacité de l'agent de réponse à répondre correctement. Résultats : +28% F1 par rapport à la meilleure référence sur LoCoMo, en utilisant seulement 152 échantillons d'entraînement. Transfert à zéro sur des benchmarks inédits sans réentraînement.
MemAct enrichit l'espace d'action d'un opérateur “Prune & Write” - à chaque étape, l'agent peut supprimer des tours d'histoire et ajouter un résumé de la mémoire. MemAct-RL-14B atteint la précision de modèles 16x plus grands tout en réduisant la longueur moyenne du contexte de 51% et la latence d'inférence de ~40%.
MEM1 va le plus loin, en maintenant une taille de mémoire constante. À chaque tour, l'agent génère un état interne qui consolide tout ce dont il a besoin, puis se débarrasse de tout le contexte précédent. L'utilisation de la mémoire reste constante quelle que soit la durée de la tâche. MEM1-7B dépasse Qwen2.5-14B sur des tâches à 16 objectifs. Le modèle a appris à suivre les sous-objectifs séparément, à sauter les questions résolues et à auto-corriger les requêtes - autant de comportements émergents.
MemAgent s'attaque au cas extrême : le traitement de documents de longueur arbitraire avec une complexité linéaire. Entraîné sur une longueur de contexte de 32K, il extrapole à 3,5 millions de tokens avec une perte de performance inférieure à 5%.
Le même schéma s'applique à tous : la gestion de la mémoire entraînée est supérieure à la gestion de la mémoire non entraînée, et souvent supérieure à des modèles plus importants avec une mémoire non entraînée.
Mais enseigner aux agents ce qu'il faut retenir n'est que la moitié de l'histoire. Dans la prochaine partie de cet article, j'approfondirai un développement parallèle qui recadre entièrement le problème : Modèles linguistiques récursifs, qui traitent le contexte non pas comme un élément à récupérer, mais comme un élément à parcourir. Je me pencherai également sur la manière dont les systèmes de production tels que OpenClaw Les agents qui évoluent ne se contenteront pas de mieux mémoriser - ils sauront comment trouver ce qu'ils n'ont pas encore mémorisé. Les agents qui passeront à l'échelle supérieure ne se contenteront pas de mieux se souvenir - ils sauront comment trouver ce qu'ils n'ont pas encore retenu.
