


Autore

14 dicembre 2020
Con l'introduzione delle autorizzazioni opt-in per le app, iOS 14 renderà più difficile per i marchi rivolgersi ai consumatori a livello individuale e misurare i risultati delle attività di marketing. Bobby Gray, responsabile di Analytics e Data Marketing di Artefact, ne analizza l'impatto e spiega come i marchi possono reagire utilizzando dati first-party .
Introduzione
Questo progetto fa parte del contributo di Artefacta Tech for Good. Il progetto è stato condotto in collaborazione con l'Institut Carnot CALYM, un consorzio dedicato alla ricerca in partnership sul linfoma, e con Microsoft.
Nell'autunno 2019, l'Institut Carnot CALYM ha lanciato un programma di strutturazione volto a definire una roadmap per ottimizzare la valorizzazione e lo sfruttamento dei dati provenienti dalla ricerca clinica, traslazionale e preclinica condotta dai membri del consorzio per oltre 20 anni. Questo progetto, proposto da Camille Laurent (LYSA, IUCT, CHU Toulouse, Francia) e Christiane Copie (LYSARC, Pierre-Bénite, Francia), entrambi membri dell'Institut Carnot CALYM, fa parte di questo programma di strutturazione.
L'obiettivo primario di questo progetto di ricerca è sviluppare un algoritmo di deep-learning per assistere i patologi nella diagnosi di linfoma follicolare. Un obiettivo secondario è quello di identificare criteri informativi che possano aiutare i medici esperti a comprendere le differenze morfologiche tra il linfoma follicolare e l'iperplasia follicolare, che di seguito verranno indicati come FL e FH.
Che cos'è il linfoma follicolare? Quali sono le sfide nella diagnosi?
Il FL è un sottotipo di linfoma, il tumore del sangue più frequente al mondo. Esistono più di 80 tipi di linfoma e questa diversità rende difficile la diagnosi, anche per gli esperti. Inoltre, l'FL è molto simile all'FH, che non è canceroso, il che aggiunge difficoltà alla diagnosi.
In questo articolo descriveremo il nostro approccio alla costruzione di un classificatore per FL e FH utilizzando solo immagini di vetrini interi etichettati. Le immagini di vetrini interi sono file digitali ad alta risoluzione di vetrini da microscopio scansionati. Nel nostro caso contengono estratti di linfonodi.
In che modo il deep learning potrebbe aiutare a rilevarlo?
Utilizzando le immagini di FL e FH a schermo intero, abbiamo addestrato un classificatore binario attraverso un approccio basato sulle patch. L'architettura del nostro modello è un semplice Resnet-18 addestrato su poche epoche (~10).
Dopo aver previsto la classe di un'osservazione con il classificatore, si estrae l'ultimo livello di attivazione per costruire una mappa di calore sopra l'immagine di input per evidenziare le parti che hanno spinto il modello a definire una determinata classe.
Perché abbiamo utilizzato una classificazione basata sulle patch?
La classificazione basata sulle patch è una tecnica di classificazione in cui la classe di una data osservazione è costruita sulla base dell'aggregazione delle previsioni dei suoi componenti (patch). Nel nostro caso viene utilizzata perché le immagini sono troppo grandi per essere utilizzate direttamente sul modello.
In effetti, le immagini a scorrimento intero sono molto grandi (~10⁵ pixel quadrati). Le loro dimensioni rendono quasi impossibile l'addestramento di un modello di deep learning con gli strumenti comuni. Per risolvere questo problema, le abbiamo suddivise in patch della stessa dimensione seguendo due importanti criteri:
Nella classificazione basata su patch, il risultato del modello può essere interpretato come quello di una classificazione classica, tranne per il fatto che il primo livello di calcolo è a livello dell'intero vetrino. Ad esempio, nel predire la classe di un vetrino di FL, un punteggio del 98% significherebbe che il 98% delle patch che lo compongono sono state predette come FL.
A livello di dataset, questa diapositiva sarà prevista con un punteggio di 0,98 per la classe FL.
PS: Abbiamo ipotizzato di dividere le immagini in patch sulla base delle conclusioni di esperti medici che affermano che in una lastra intera di FL, i follicoli dovrebbero essere presenti ovunque.
Set di formazione
Il nostro set di addestramento è composto da 58k patch selezionate casualmente (1024 pixel quadrati) di FL e FH estratte da un set di 30 immagini a scorrimento intero in ciascuna delle due classi.
Set di convalida
Il 20% delle patch è stato campionato per convalidare le prestazioni del modello al momento dell'addestramento.
Set di test
Il nostro set di test è composto da 15 immagini a scorrimento intero, ciascuna suddivisa in patch. Questo set di riferimento è stato utilizzato per confrontare i risultati di diversi approcci all'addestramento che illustreremo di seguito.
Modellazione
Il nostro set di test è composto da 15 immagini a scorrimento intero, ciascuna suddivisa in patch. Questo set di riferimento è stato utilizzato per confrontare i risultati di diversi approcci all'addestramento che illustreremo di seguito.
Prima di addestrare il classificatore di deep learning: Preparazione ed elaborazione dell'immagine
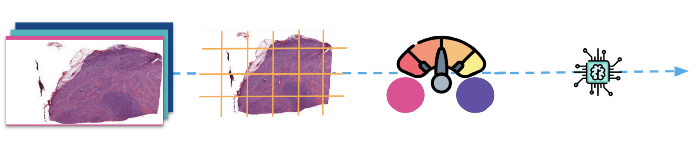
(Sopra: Le immagini vengono prima divise in patch e poi normalizzate prima di essere inviate al modello per l'addestramento).
Dopo la formazione: Inferenza e interpretazione
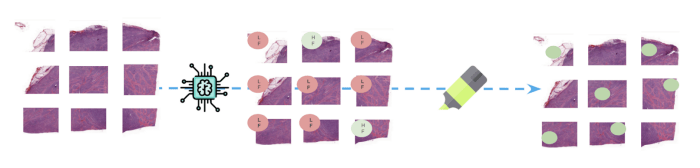
(Sopra: Al momento dell'inferenza, i nuovi fogli interi vengono suddivisi in patch prima che il modello predica una classe per
ciascuna di esse. Le parti delle immagini responsabili della previsione della classe FL sono evidenziate per aiutare a monitorare i risultati.
i risultati).
Nelle sezioni che seguono, forniremo i dettagli di queste diverse fasi della pipeline.
Preparazione ed elaborazione dei dati
1 - Piastrellatura
Come già detto in precedenza, le immagini a schermo intero sono molto grandi e non possono essere alimentate direttamente da un modello di classificazione, a meno che non si utilizzi un hardware super galattico. Abbiamo utilizzato la libreria openslide per leggere le diapositive e il suo supporto deepzoom per dividere le immagini in piastrelle relativamente piccole di 1024 pixel quadrati. Dopo averle suddivise in piastrelle, le abbiamo inserite in un pulitore di base che ha eliminato tutte le piastrelle che non si trovavano al centro del tessuto (bordi, buchi, ecc.).

2 - Normalizzazione delle macchie
La seconda fase dell'elaborazione dei dati, che è anche la più importante, è la normalizzazione del colore delle macchie. La colorazione è il processo di evidenziazione delle caratteristiche importanti sui vetrini e di miglioramento del contrasto tra di esse. Il sistema di colorazione utilizzato è il comune H&E (Ematossilina ed Eosina).
Tuttavia, poiché le immagini provengono da molti laboratori diversi, abbiamo osservato variazioni nella colorazione dei vetrini. Esse derivano principalmente dalle differenze nel processo di colorazione da un laboratorio all'altro. Queste differenze possono influenzare notevolmente le prestazioni del modello.
Abbiamo utilizzato tecniche classiche per normalizzare la colorazione del set di dati prima di addestrare il modello.
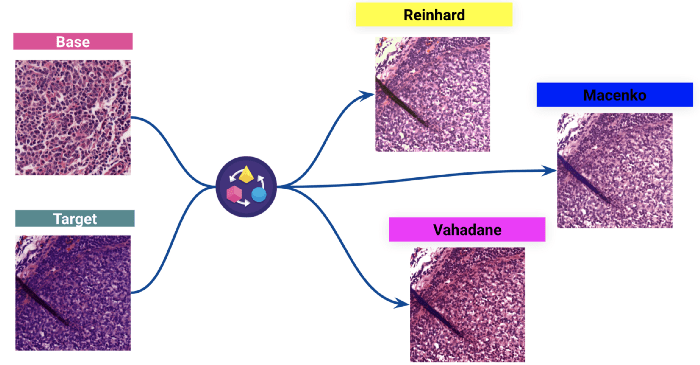
(Sopra: Risultati di tre diverse normalizzazioni delle macchie: la colorazione di un'immagine target viene normalizzata rispetto alla distribuzione dei colori dell'immagine di base).
Abbiamo scelto il Reinhard per vedere l'impatto sul modello.
Formazione di un classificatore Resnet-18
Dopo aver elaborato le immagini a scorrimento intero, l'addestramento si è svolto senza problemi (dropout, decadimento del peso, ecc.). Nulla di particolare, se non l'aggiunta di un mixup nell'incremento dei dati. Abbiamo utilizzato un Resnet18 addestrato da zero, poiché i modelli pre-addestrati non miglioravano significativamente i nostri risultati. Abbiamo preferito Resnet-18 anche perché Resnet-34 e Resnet-56 non miglioravano le nostre prestazioni. Dopo circa 10 epoche, il nostro modello era pronto per essere testato.
Abbiamo utilizzato il praticissimo Fastai per costruire i nostri modelli con pochi sforzi.
Test
I risultati di 3 sperimentazioni meritano di essere menzionati:
I risultati sul set di test per queste 3 sperimentazioni sono mostrati di seguito:
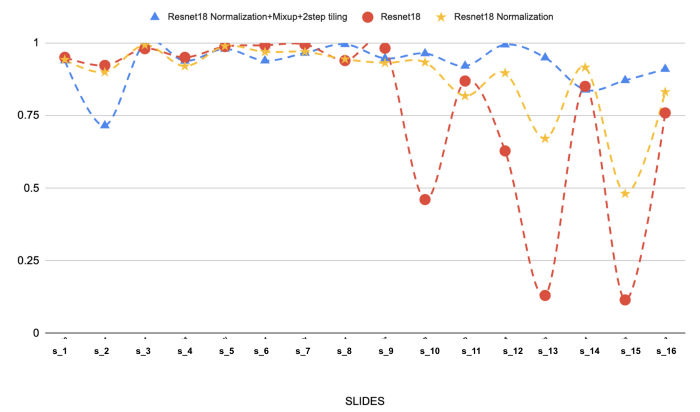
(Sopra: I risultati di 3 diversi modelli sui 16 vetrini selezionati di linfoma follicolare. Si può notare l'effetto della normalizzazione delle macchie e del mixup sulle prestazioni).
La normalizzazione delle macchie è di gran lunga la fase più importante del nostro approccio di modellazione. Avevamo problemi di generalizzazione (linea rossa), ma ha sicuramente aiutato a risolvere il problema. L'aggiunta di un mixup e di una piastrellatura a due fasi migliora ulteriormente la situazione.
MixUp è una tecnica di incremento dei dati che consiste nel creare nuove osservazioni interpolando linearmente molti campioni.
Interpretare i risultati di un classificatore di computer vision
Per comunicare facilmente i risultati agli esperti di medicina, abbiamo fornito immagini con mappe di calore per evidenziare dove si concentrava il modello nel predire una determinata etichetta. Per farlo, abbiamo estratto l'ultimo strato di attivazione della rete convoluzionale ed estrapolato linearmente sull'immagine su cui stavamo facendo la previsione.
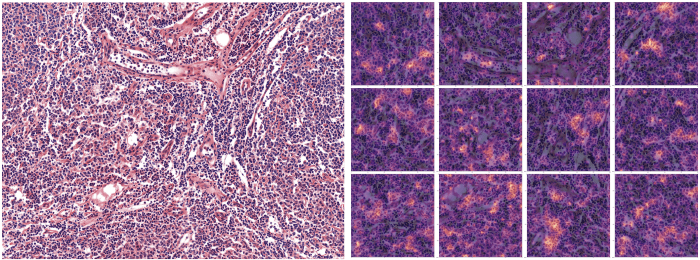
(Sopra: Le parti dell'immagine che hanno contribuito maggiormente alla previsione della classe Linfoma follicolare sono evidenziate sull'immagine di destra - 12 patch)).
L'interpretazione dell'output del modello con le heatmap è stata molto utile per regolare l'approccio alla modellazione, in quanto fornisce agli esperti modi per analizzare ciò che il modello sta effettivamente facendo. Grazie agli scambi con gli esperti, noi (data scientist) siamo stati in grado di regolare il modo in cui gestire meglio il set di dati e rendere il modello più robusto (cioè in grado di adattarsi a diversi tipi di input). E anche per assicurarci che serva allo scopo. È stato infatti così che abbiamo capito la necessità di normalizzare la colorazione delle immagini.
Conclusioni e insegnamenti chiave
L'obiettivo di questo studio è stato quello di esplorare il processo di creazione di un buon classificatore di base di deep learning per differenziare il linfoma follicolare e l'iperplasia follicolare. I nostri principali risultati sono elencati di seguito:
