


Auteur

14 december 2020
Met de introductie van opt-in permissies voor apps, zal iOS 14 het moeilijker maken voor merken om consumenten op individueel niveau te targeten en de resultaten van marketingactiviteiten te meten. Bobby Gray, Hoofd Analytics en Data Marketing bij Artefact, bekijkt de impact en legt uit hoe merken kunnen reageren met behulp van first-party data.
Inleiding
Dit project maakt deel uit van de bijdrage van Artefact aan Tech for Good. Het project is uitgevoerd in samenwerking met het Institut Carnot CALYM, een consortium dat zich richt op partnerschapsonderzoek naar lymfeklierkanker, en Microsoft.
In de herfst van 2019 lanceerde het Institut Carnot CALYM een structureringsprogramma dat gericht is op het opstellen van een routekaart voor het optimaliseren van de valorisatie en exploitatie van data uit het klinische, translationele en preklinische onderzoek dat al meer dan 20 jaar wordt uitgevoerd door de leden van het consortium. Dit project, voorgesteld door Pr Camille Laurent (LYSA, IUCT, CHU Toulouse, Frankrijk) en Pr Christiane Copie (LYSARC, Pierre-Bénite, Frankrijk), beiden lid van het Institut Carnot CALYM, maakt deel uit van dit structureringsprogramma.
De primaire doelstelling van dit onderzoeksproject is het ontwikkelen van een deep-learning algoritme om pathologen te helpen bij het diagnosticeren van folliculair lymfoom. Een secundair doel is het identificeren van informatieve criteria die medische experts kunnen helpen bij het begrijpen van de morfologische verschillen tussen folliculair lymfoom en folliculaire hyperplasie, die hierna FL en FH zullen worden genoemd.
Wat is folliculair lymfoom? Wat zijn de uitdagingen bij de diagnose?
FL is een subtype van Lymfoom, de meest voorkomende bloedkanker ter wereld. Er zijn meer dan 80 soorten Lymfoom en deze diversiteit maakt de diagnose moeilijk, zelfs voor deskundigen. Bovendien lijkt FL erg op FH, dat niet kankerverwekkend is, wat de diagnose nog moeilijker maakt.
In dit artikel beschrijven we onze aanpak bij het bouwen van een classificator voor FL en FH door alleen gelabelde afbeeldingen van hele objectglaasjes te gebruiken. Afbeeldingen van hele objectglaasjes zijn digitale bestanden met een hoge resolutie van gescande microscoopglaasjes. In ons geval bevatten ze extracten van lymfeklieren.
Hoe kan deep learning helpen bij de detectie?
Met behulp van hele-slide beelden van FL en FH trainden we een binaire classificator door middel van een patch-gebaseerde aanpak. Onze modelarchitectuur is een eenvoudige Resnet-18 getraind op een paar epochs (~10).
Na het voorspellen van de klasse van een observatie met de classifier, halen we de laatste activeringslaag eruit om een heatmap boven op de invoerafbeelding te bouwen om delen te markeren die het model ertoe hebben aangezet om een bepaalde klasse te definiëren.
Waarom hebben we een patch-gebaseerde classificatie gebruikt?
Patchgebaseerde classificatie is een classificatietechniek waarbij de klasse van een gegeven waarneming wordt opgebouwd op basis van de samenvoeging van de voorspellingen van de componenten (patches). In ons geval wordt deze techniek gebruikt omdat de afbeeldingen veel te groot zijn om direct op het model gebruikt te worden.
In feite zijn afbeeldingen van hele dia's erg groot (~10⁵ vierkante pixels). Hun grootte maakt het trainen van een deep learning-model bijna onmogelijk met gewone hulpmiddelen. Om dit probleem op te lossen, hebben we ze verdeeld in patches van dezelfde grootte volgens twee belangrijke criteria:
Bij classificatie op basis van patches kan de uitvoer van het model geïnterpreteerd worden als die van een klassieke classificatie, behalve dat de eerste rekenlaag zich op het niveau van de hele glijbaan bevindt. Bijvoorbeeld, bij het voorspellen van de klasse van een glijbaan van FL, zou een score van 98% betekenen dat 98 % van de patches waaruit de glijbaan bestaat, voorspeld zijn als zijnde FL.
Op het niveau dataset wordt deze dia voorspeld met een score van 0,98 voor de FL klasse.
PS: We hebben de hypothese om de afbeeldingen in patches te verdelen gebaseerd op de conclusies van medische experts die stellen dat in een hele FL-afbeelding de follikels naar verwachting overal aanwezig zullen zijn.
Trainingsset
Onze trainingsset bestaat uit 58k willekeurig geselecteerde patches (vierkant van 1024 pixels) van FL en FH geëxtraheerd uit een set van 30 hele-slidebeelden in elk van de 2 klassen.
Validatieset
20% van de patches werd bemonsterd om de modelprestaties tijdens de training te valideren.
Testset
Onze testset bestaat uit 15 afbeeldingen van hele dia's, elk verdeeld in patches. Deze referentieset is gebruikt om de resultaten van verschillende trainingsbenaderingen te vergelijken, die we hieronder nauwkeurig zullen beschrijven.
Modelleren
Onze testset bestaat uit 15 afbeeldingen van hele dia's, elk verdeeld in patches. Deze referentieset is gebruikt om de resultaten van verschillende trainingsbenaderingen te vergelijken, die we hieronder nauwkeurig zullen beschrijven.
Voor het trainen van de deep learning classifier: Beeldvoorbereiding en -verwerking
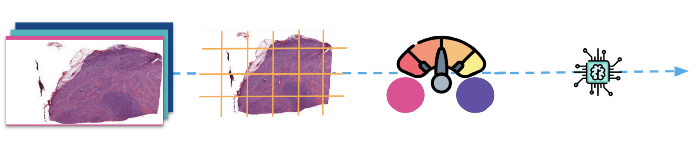
(Hierboven: De beelden worden eerst in patches verdeeld en vervolgens genormaliseerd voordat ze naar het model worden gevoerd om te trainen).
Na de training: Inferentie en interpretatie
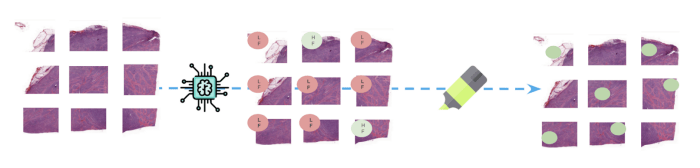
(Hierboven: Tijdens de inferentietijd worden nieuwe hele glijbanen verdeeld in patches voordat het model een klasse voorspelt voor
elk van hen. Delen van afbeeldingen die verantwoordelijk zijn voor het voorspellen van de FL-klasse worden gemarkeerd om te helpen bij het monitoren
de resultaten).
In de onderstaande secties geven we details over deze verschillende stappen van de pijplijn.
Data voorbereiding en verwerking
1 - Betegelen
Zoals eerder vermeld, zijn afbeeldingen van hele dia's erg groot en kunnen ze niet direct naar een classificatiemodel worden gevoerd, tenzij u super galactische hardware gebruikt. Wij gebruikten de bibliotheek openslide om de dia's en de diepzoom ondersteuning om de afbeeldingen te verdelen in relatief kleine tegels met een vierkant formaat van 1024 pixels. Nadat we ze in tiles hadden opgedeeld, hebben we ze door een basiscleaner gehaald die alle tiles wegliet die niet in het midden van het weefsel lagen (randen, gaten, enz.).

2 - Vleknormalisatie
De tweede stap van onze data verwerking, die ook de belangrijkste stap is, is de kleurnormalisatie van de kleuring. Kleuring is het proces waarbij belangrijke kenmerken op objectglaasjes worden gemarkeerd en het contrast ertussen wordt vergroot. Het gebruikte kleursysteem is het gangbare H&E (Hematoxyline en Eosine).
Omdat de afbeeldingen echter van veel verschillende laboratoria komen, hebben we variaties in de kleuring van de objectglaasjes waargenomen. Deze variaties zijn voornamelijk het gevolg van verschillen in het kleurproces tussen laboratoria. Deze verschillen kunnen de prestaties van het model sterk beïnvloeden.
We gebruikten klassieke technieken om de kleuring van de dataset te normaliseren voordat we het model trainden.
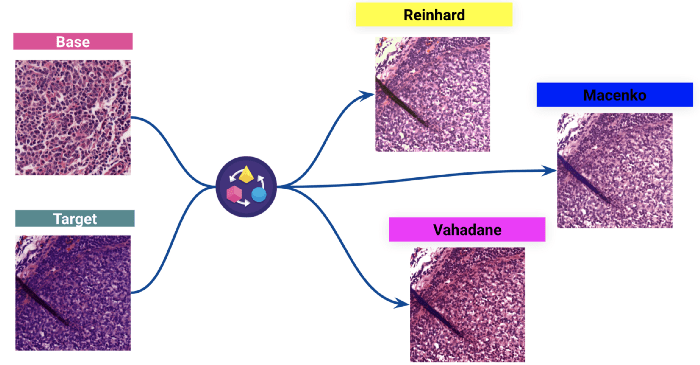
(Hierboven: Resultaten van drie verschillende kleurnormalisaties: een doelbeeldkleuring wordt genormaliseerd naar een basisbeeldkleurverdeling).
We hebben de Reinhard techniek om de impact op het model te zien.
Een Resnet-18 classificator trainen
Na het verwerken van de beelden van de hele dia verliep de training probleemloos (dropout, gewichtsverval, enz..). Niets bijzonders, behalve het toevoegen van mixup in de data augmentatie. We gebruikten een Resnet18 helemaal opnieuw getraind, omdat voorgetrainde modellen onze resultaten niet significant verbeterden. We gaven ook de voorkeur aan Resnet-18 omdat Resnet-34 en Resnet-56 onze prestaties niet verbeterden. Na ~10 epochs was ons model klaar om getest te worden.
We gebruikten het zeer praktische Fastai bibliotheek om onze modellen met weinig moeite te bouwen.
Testen
De resultaten van 3 experimenten zijn het vermelden waard:
De resultaten op de testset voor deze 3 experimenten worden hieronder weergegeven:
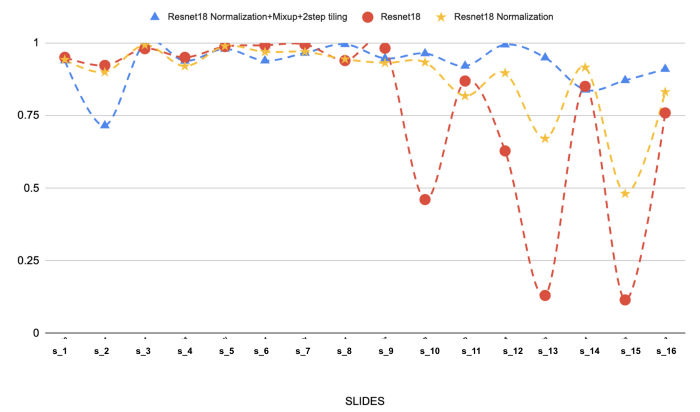
(Hierboven: De resultaten van 3 verschillende modellen op de 16 geselecteerde objectglaasjes van folliculair lymfoom. We kunnen het effect van kleurstofnormalisatie en mixup op de prestaties zien).
De normalisatie van de vlekken is verreweg de belangrijkste stap in onze modelleerbenadering. We hadden last van generalisatieproblemen (rode lijn), maar het helpt zeker bij het oplossen van het probleem. Het toevoegen van mixup en een 2-staps tegelwerk maakt het nog beter.
MixUp is een data augmentatietechniek die bestaat uit het creëren van nieuwe waarnemingen door lineaire interpolatie van vele monsters.
De resultaten van een computer vision classifier interpreteren
Om de resultaten gemakkelijk aan medische experts te kunnen communiceren, voorzagen we afbeeldingen van heatmaps om aan te geven waar de focus van het model lag bij het voorspellen van een bepaald label. Dat deden we door de laatste activatielaag van het convolutienetwerk te extraheren en deze lineair te extrapoleren op de afbeelding waarop we voorspelden.
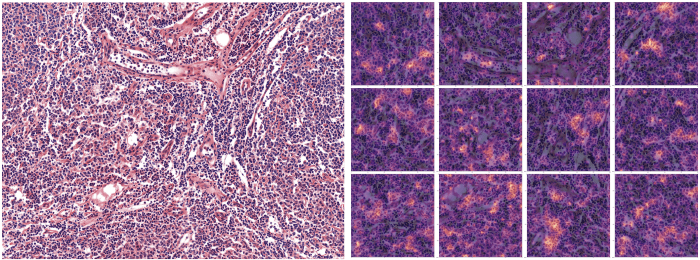
(Hierboven: Delen van de afbeelding die het meest hebben bijgedragen aan de voorspelling van de klasse Folliculair Lymfoom zijn gemarkeerd op de afbeelding aan de rechterkant - 12 patches).
Het interpreteren van de output van het model met heatmaps is erg nuttig geweest bij het aanpassen van de modelbenadering, omdat het experts manieren geeft om te analyseren wat het model nu eigenlijk doet. Door onze uitwisselingen met experts konden wij (data wetenschappers) aanpassen hoe we beter met de dataset konden omgaan en hoe we het model robuuster konden maken (d.w.z. in staat om ons aan te passen aan verschillende soorten invoer). En ook om ervoor te zorgen dat het zijn doel dient. Zo realiseerden we ons dat we de kleuring van de beelden moesten normaliseren.
Conclusie en belangrijkste leerpunten
Het doel van dit onderzoek was het verkennen van het proces voor het creëren van een goede deep learning basisclassificator voor het onderscheiden van folliculair lymfoom en folliculaire hyperplasie. Onze belangrijkste bevindingen staan hieronder:
